







nio-Buffer笔记
文章目录
Buffer
属性
- mark:一个标记值,和reset()方法配合使用,将position切换至make的位置可按照意图进行读写操作
- position:读写的起始位置,get/put都会更新position的值,但是put(int,byte)不会改变position的位置
- limit:限定读写操作的最大位置,超过该位置,不可读写操作
- capacity:buffer(是一个数组)的长度
注意:mark <= position <= limit <= capacity
那么问题来了mark为啥是最小的?
个人是这么理解的,mark设计初衷就是一个备忘位置,在读写操作后,可以回到之前标记的位置,那么这个位置一定比当前的position小,因为position后面的index,还没有操作到。那么position <= limit <= capacity,这就很好理解了,position和limit共同标识了读写的操作区间,一个头一个尾,capacity是buffer的容量,自然最大。
ByteBuffer(重要)
SocketChannel只支持传输byte,那么ByteBuffer对于我个人而言就显得非常重要。
基本数据类型字节
bool虽然是1字节,但是一个字节有8位,拥有256个不同的值,会有歧义,NIO没有支持bool
| 类型 | 字节数 |
|---|---|
| byte | 1 |
| char | 2 |
| short | 2 |
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
字节顺序(字节在内存中保存的顺序)
例如:99999999(0x05f5e0ff)
- BIG_ENDIAN 大端字节顺序,基本数据类型(byte除外),最高字节(05)位于低位地址。在内存的位置就是05 f5 e0 ff
- LITTLE_ENDIAN 小端字节顺序,基本数据类型(byte除外),最低字节(ff)会位于低位地址,即会最先保存至内存。在内存中的位置 ff e0 f5 05
ByteOrder
ByteOrder LITTLE_ENDIAN;//小端字节顺序
ByteOrder BIG_ENDIAN; //大端字节顺序
ByteOrder nativeOrder(){ return Bits.byteOrder();} //返回系统硬件的字节顺序
order就是一个保存字节顺序的VO,只有一个字段name,标识字节顺序。
ByteBuffer.order(ByteOrder order)
ByteBuffer可以设置该顺序,默认是BIG_ENDIA,通过order(ByteOrder
order)方法来设置,当数据写入buffer后,在去调用该方法,那么字节保存的顺序将不会改变。统一字节顺序有利于夸平台,适应不同环境的硬件。如果字节顺序和系统硬件一致的话,读写性能将大大提升。
直接缓冲区(DirectBuffer)
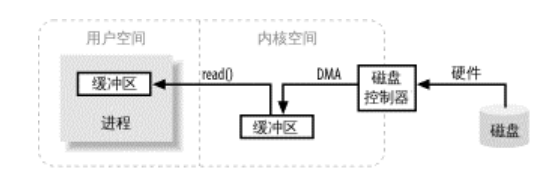
直接缓冲区由本地操作系统分配的,不有JVM分配,系统直接填满或排空直接缓冲区(0拷贝)。
如果使用非直接缓冲区(堆缓冲区),那么性能会降低一些,可能会有以下步骤:
- 创建一个临时直接缓冲区ByteBuffer对象
- 将非直接缓冲区的对象复制到直接缓冲区中
- 使用临时缓冲区去执行底层的I/O操作
- 临时缓冲区对象离开作用域,最终被回收。
视图缓冲区
ByteBuffer可以生成char、short、int、long、float、double的缓冲区视图。
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(20);
byteBuffer.order(ByteOrder.LITTLE_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer();
byteBuffer.putChar('a');
byteBuffer.putChar('b');
byteBuffer.putChar('c');
byteBuffer.put((byte) 0);
charBuffer.put(0, 'd');
System.out.println(byteBuffer);
System.out.println(byteBuffer.getChar(0));
System.out.println("pos=" + charBuffer.position() + " lim=" + charBuffer.limit() + " cap=" + charBuffer.capacity());
System.out.println("isDirect:" + charBuffer.isDirect());
System.out.println(charBuffer.order());
System.out.println(charBuffer);
System.out.println("pos=" + charBuffer.position() + " lim=" + charBuffer.limit() + " cap=" + charBuffer.capacity());
结果
java.nio.DirectByteBuffer[pos=7 lim=20 cap=20]
d
pos=0 lim=10 cap=10
isDirect:true
LITTLE_ENDIAN
dbc
pos=0 lim=10 cap=10
总结
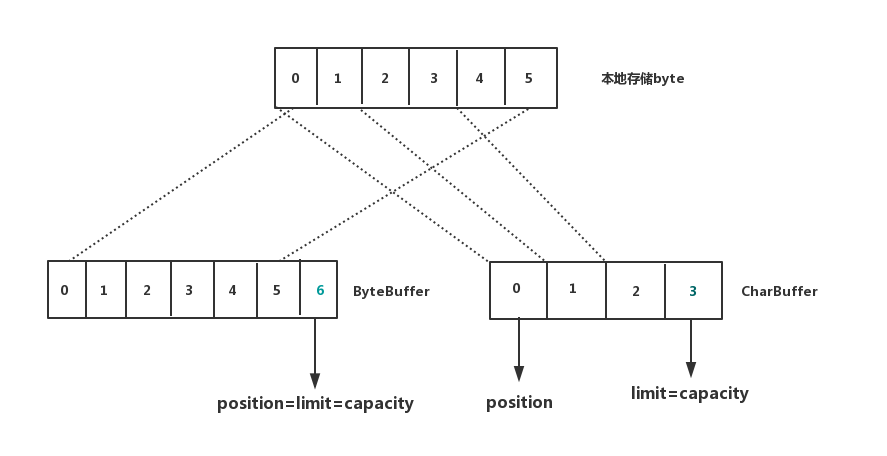
- 视图和ByteBuffer共同引用同一个byte[]
- view和ByteBuffer的映射关系,是将ByteBuffer的总长度进行映射,得到的view的长度 length = byteBuffer的cap/view占用的字节数,这里就是20/2=10,如果是ByteBuffer.allocateDirect(7)的话,得到view的cap为7/2=3
- 视图修改了byte数组,本体ByteBuffer的值也会改变
- 视图和本体ByteBuffer的类型是一样的,ByteBuffer是直接内存,那么视图也是。
- 视图映射的position=0,limit=capacity
数据元素视图
ByteBuffer支持在现有的字节顺序上,按照需要将字节打乱组合成char、short、int、long、float、double。
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4);
byteBuffer.order(ByteOrder.BIG_ENDIAN);
byteBuffer.putInt(0x96c1bfcf);
byteBuffer.flip();
System.out.println(Integer.toHexString(byteBuffer.order(ByteOrder.LITTLE_ENDIAN).getInt()));
- 初始化DirectByteBuffer的字节顺序为大端字节顺序 内存中的顺序是 96 c1 bf cf(16进制)
JDK的Buffer有两种读取字节实现方式:
1.1. 第一种是系统指令架构支持的情况下,在当前字节顺序和系统的字节排序一致的情况下,直接操作底层代码存储所有的自己长度,如果不一样,则通过jdk对字节序列进行反转,然后再去一次性存储。
1.2. 第二种就是系统不支持的情况下,那么就需要一个字节一个字节的去写入,根据当前Buffer的字节顺序,获取到相应的每一个字节,然后写入内存。
//获取内存index
private long ix(int i) {
return address + ((long)i << 0);
}
public ByteBuffer putInt(int x) {
//获取下一个要插入的index,再计算出下一个连续的内存地址index
putInt(ix(nextPutIndex((1 << 2))), x);
return this;
}
private ByteBuffer putInt(long a, int x) {
if (unaligned) {
int y = (x);
unsafe.putInt(a, (nativeByteOrder ? y : Bits.swap(y)));
} else {
//存
Bits.putInt(a, x, bigEndian);
}
return this;
}
static void putInt(long a, int x, boolean bigEndian) {
if (bigEndian)
putIntB(a, x);
else
putIntL(a, x);
}
//高字节位存在低内存地址 大端字节顺序
static void putIntB(long a, int x) {
_put(a , int3(x));
_put(a + 1, int2(x));
_put(a + 2, int1(x));
_put(a + 3, int0(x));
}
//高字节位存在高内存地址,小端顺序
static void putIntL(long a, int x) {
_put(a + 3, int3(x));
_put(a + 2, int2(x));
_put(a + 1, int1(x));
_put(a , int0(x));
}
- 设置为小端字节顺序,接下来存取都会依照小端顺序
- 在getInt的时候,内存的顺序是96 c1 bf cf,现在变换为小端顺序去取,依次会取(16进制) cf(byte) bf(byte) c1(byte) 96(byte)
//
static int getIntB(long a) {
return makeInt(_get(a ),
_get(a + 1),
_get(a + 2),
_get(a + 3));
}
//
static int getIntL(long a) {
return makeInt(_get(a + 3),
_get(a + 2),
_get(a + 1),
_get(a ));
}
- 在将四个字节转化为int,得到0xcfbfc196
总结
Buffer是nio的数据传输介质(端点),网络I/O中通过ByteBuffer来进行传输,直接缓冲区,操作系统内核空间可以直接填满和排空该缓冲区,减少了拷贝次数。















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









