







目录
2. 左外连接(LEFT JOIN / LEFT OUTER JOIN)
3. 右外连接(RIGHT JOIN / RIGHT OUTER JOIN)
4. 全外连接(FULL JOIN / FULL OUTER JOIN)
1.SQL
SQL(Structured Query Language)是一种用于管理和处理关系型数据库的标准语言。它包括了一系列用于查询、操作、定义和控制数据库的语句。以下是 SQL 的基本组成部分和常用操作:
基本组成部分
-
数据定义语言 (DDL)用于创建、修改和删除数据库对象(如表、视图、索引、存储过程等)。
CREATE TABLE: 创建表。ALTER TABLE: 修改表结构。DROP TABLE: 删除表。CREATE INDEX: 创建索引。DROP INDEX: 删除索引。CREATE VIEW: 创建视图。DROP VIEW: 删除视图。CREATE DATABASE: 创建数据库。ALTER DATABASE: 修改数据库属性。DROP DATABASE: 删除数据库。
-
数据操纵语言 (DML):用于查询、插入、更新和删除表中的数据。
SELECT: 从表中检索数据。INSERT INTO: 向表中插入新数据。UPDATE: 修改表中已存在的数据。DELETE FROM: 从表中删除数据。
-
数据控制语言 (DCL):用于管理数据库用户的访问权限和安全。
GRANT: 授予用户访问权限。REVOKE: 撤销用户访问权限。DENY: 拒绝用户访问特定资源。
-
事务控制语言 (TCL):用于管理事务的开始、提交、回滚等操作。
BEGIN TRANSACTION: 开始一个事务。COMMIT: 提交事务,永久保存对数据库的更改。ROLLBACK: 回滚事务,撤销对数据库的所有未提交更改。
常用操作示例
创建表
CREATE TABLE Employees (
EmployeeID int NOT NULL,
FirstName varchar(255) NOT NULL,
LastName varchar(255) NOT NULL,
DepartmentID int,
Salary decimal(10, 2),
PRIMARY KEY (EmployeeID),
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);插入数据
INSERT INTO Employees (EmployeeID, FirstName, LastName, DepartmentID, Salary)
VALUES (1, 'John', 'Doe', 101, 50000.00),
(2, 'Jane', 'Smith', 102, 60000.00);查询数据
SELECT EmployeeID, CONCAT(FirstName, ' ', LastName) AS FullName, DepartmentID, Salary
FROM Employees
WHERE DepartmentID = 101
ORDER BY Salary DESC;更新数据
UPDATE Employees
SET Salary = Salary * 1.05
WHERE DepartmentID = 101;删除数据
DELETE FROM Employees
WHERE EmployeeID = 1;创建索引
CREATE INDEX idx_Employees_FirstName ON Employees (FirstName);授予用户权限
GRANT SELECT, INSERT, UPDATE, DELETE ON Employees TO 'user1'@'localhost';以上只是 SQL 语言的一部分基础内容。实际使用中,SQL 还包括更多高级特性,如子查询、联接查询、聚合函数、窗口函数、存储过程、触发器等,可以根据实际需求灵活运用。
2.常见的聚合查询
SQL 中的聚合函数对一组数据进行统计、计算或汇总的操作。以下列举了一些常用的聚合查询示例:
1. 计数(COUNT)
-
计算表中总行数:
SELECT COUNT(*) FROM Employees; -
计算某一列非空值的数量:
SELECT COUNT(EmployeeID) FROM Employees;
2. 求和(SUM)
-
计算某列数值之和:
SELECT SUM(Salary) FROM Employees;
3. 平均值(AVG)
-
计算某列数值的平均值:
SELECT AVG(Salary) FROM Employees;
4. 最大值(MAX)
-
找出某列的最大值:
SELECT MAX(Salary) FROM Employees;
5. 最小值(MIN)
-
找出某列的最小值:
SELECT MIN(Salary) FROM Employees;
6. 分组统计(GROUP BY)
-
按部门分组,计算各组员工人数:
SELECT DepartmentID, COUNT(*) AS EmployeeCount FROM Employees GROUP BY DepartmentID;
7. 分组后的条件筛选(HAVING)
-
按部门分组,筛选出员工人数大于 10 的部门:
SELECT DepartmentID, COUNT(*) AS EmployeeCount FROM Employees GROUP BY DepartmentID HAVING COUNT(*) > 10;
8. 多列聚合
-
同时计算员工总数、薪资总和、平均薪资:
SELECT COUNT(*), SUM(Salary), AVG(Salary) FROM Employees;
9. 聚合函数与列别名
-
使用列别名使查询结果更易读:
SELECT COUNT(*) AS TotalEmployees, SUM(Salary) AS TotalSalary, AVG(Salary) AS AverageSalary FROM Employees;
10. 分组后的条件筛选与聚合函数结合
-
按部门分组,计算各组员工的最高薪资:
SELECT DepartmentID, MAX(Salary) AS MaxSalary FROM Employees GROUP BY DepartmentID;
以上就是常见的聚合查询示例,涵盖了基本的计数、求和、平均值、最大值、最小值计算,以及与分组、条件筛选、多列聚合和列别名的组合使用。实际应用中,可根据业务需求灵活运用这些聚合查询,对数据进行各种统计分析。
3.关联查询
关联查询是 SQL 中用来从多个相关表中检索数据的重要手段。
1. 内连接(INNER JOIN)
内连接返回两个(或更多)表中存在匹配关系的行。只有当两个表中的相关列值相等时,才会在结果集中包含对应的行。如果没有匹配项,则该行不会出现在结果集中。
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;2. 左外连接(LEFT JOIN / LEFT OUTER JOIN)
左外连接返回左表(在 LEFT JOIN 语句中写在前面的表)的所有行,以及右表与左表匹配的行。如果右表中没有匹配项,则结果中对应的右表列值为 NULL。
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
LEFT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;3. 右外连接(RIGHT JOIN / RIGHT OUTER JOIN)
右外连接返回右表(在 RIGHT JOIN 语句中写在后面的表)的所有行,以及左表与右表匹配的行。如果左表中没有匹配项,则结果中对应的左表列值为 NULL。
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID;4. 全外连接(FULL JOIN / FULL OUTER JOIN)
全外连接返回左表和右表中所有行的组合。如果某一方没有匹配项,则结果中对应的一方列值为 NULL。MySQL 不直接支持 FULL OUTER JOIN,但可以通过 UNION 左外连接和右外连接的结果来模拟。
-- MySQL 模拟全外连接
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
LEFT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID
UNION ALL
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
RIGHT JOIN Customers
ON Orders.CustomerID = Customers.CustomerID
WHERE Orders.OrderID IS NULL;5. 自连接(Self Join)
自连接是指同一个表与其自身进行关联查询,通常用于处理具有层级关系或自引用关系的数据。
SELECT e1.EmployeeID, e1.ManagerID, e2.FirstName AS ManagerName
FROM Employees e1
JOIN Employees e2
ON e1.ManagerID = e2.EmployeeID;6. 交叉连接(CROSS JOIN)
交叉连接返回两个表所有行的笛卡尔积,即第一个表的每一行与第二个表的每一行进行组合。如果没有指定连接条件,则默认为交叉连接。
SELECT Customers.CustomerName, Products.ProductName
FROM Customers
CROSS JOIN Products;7. 自然连接(NATURAL JOIN)
自然连接基于两个表中具有相同名称的列进行自动关联,去除重复列,并隐式地添加连接条件。MySQL 支持自然连接,但使用较少,因为它依赖于列名的匹配,不够明确且容易受表结构变化影响。
SELECT *
FROM Orders
NATURAL JOIN Customers;以上就是几种常见的关联查询类型,根据实际数据模型和查询需求,可以选择适当的关联类型来实现所需的数据检索。在使用关联查询时,要注意优化连接条件,避免全表扫描,合理使用索引来提升查询性能。
4.Where 和 Having 的区别
WHERE 和 HAVING 都是 SQL 语句中用于筛选数据的子句,但它们在查询处理阶段、作用对象以及使用场景上有明显的区别:
WHERE 子句
-
位置与作用阶段:
WHERE子句出现在FROM之后,GROUP BY之前(如果存在的话),用于对查询结果集进行初步筛选,过滤出满足特定条件的行。WHERE子句在数据分组前对单行记录进行过滤。 -
作用对象:
WHERE子句应用于原始表数据或连接结果,筛选基于单行记录的列值。它可以使用列名、表达式、常量、比较运算符、逻辑运算符等进行条件判断。 -
使用条件:
WHERE子句可以使用所有类型的列,包括普通列和计算列(如表达式结果),但不能直接使用聚合函数。
HAVING 子句
-
位置与作用阶段:
HAVING子句出现在GROUP BY之后(如果存在的话),ORDER BY之前(如果存在的话)。它对已经经过GROUP BY子句分组后的结果集进行筛选,过滤掉不满足条件的组。HAVING子句在数据分组后对组进行过滤。 -
作用对象:
HAVING子句应用于分组后的结果,筛选基于整个组的聚合值。它通常与聚合函数(如COUNT(),SUM(),AVG(),MAX(),MIN()等)一起使用,判断组级别的条件是否成立。 -
使用条件:
HAVING子句可以使用聚合函数以及在GROUP BY子句中列出的列。如果需要基于非聚合列进行过滤,必须确保这些列也在GROUP BY子句中。
区别总结
-
执行阶段:
WHERE在数据分组前进行行级筛选,HAVING在数据分组后进行组级筛选。 -
作用对象:
WHERE对单行记录进行条件判断,HAVING对分组结果进行条件判断,通常涉及聚合函数。 -
适用场景:
WHERE用于过滤查询结果中的单行记录,适用于基于单行数据的筛选条件。HAVING用于过滤分组后的结果集,适用于基于组汇总数据的筛选条件,常用于含有GROUP BY的查询中。
简单来说,WHERE 子句用于筛选单行记录,而 HAVING 子句用于筛选分组后的数据。在需要对分组结果进行进一步条件筛选时,应使用 HAVING,而在查询开始阶段就需要过滤掉不符合条件的单行记录时,应使用 WHERE。两者可以结合使用,先用 WHERE 过滤单行,再用 HAVING 过滤分组结果。
5.SQL 关键字的执行顺序
SQL 关键字的执行顺序是指在解析和执行一条 SQL 查询语句时,各个关键字(如 SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY、LIMIT 等)按照特定的逻辑顺序进行处理。尽管实际的查询优化器可能会对执行计划进行优化,但按照标准的解析逻辑,SQL 关键字的大致执行顺序如下:
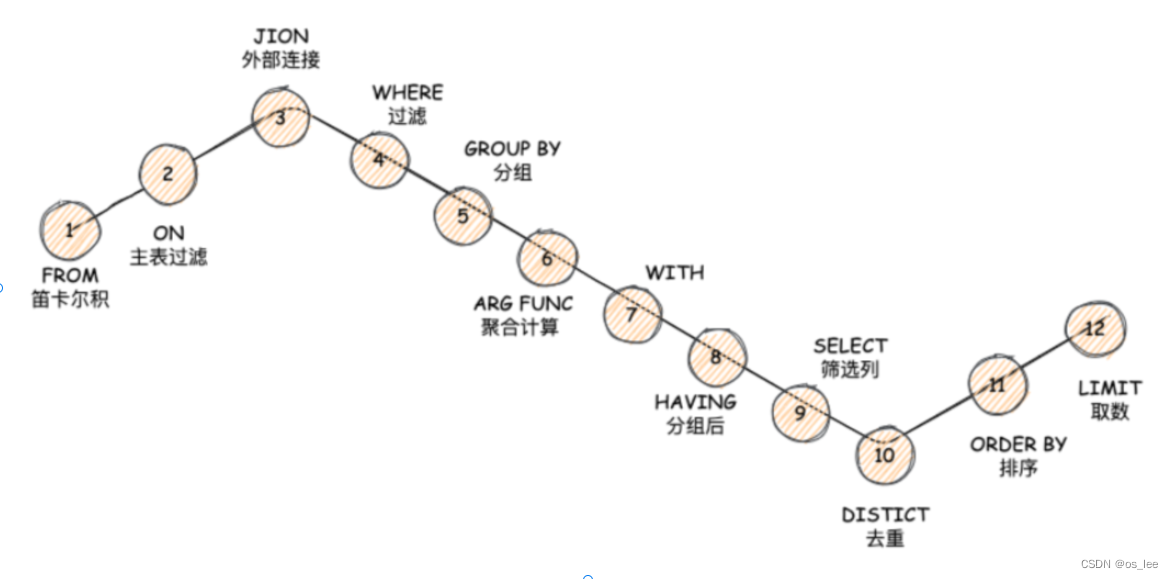
-
FROM
- 作用:指定查询的数据来源,即从哪些表(或视图)中获取数据。
- 顺序:SQL 解析的第一步通常是从
FROM子句开始,识别参与查询的表和它们之间的连接关系。
-
JOIN(如果存在)
- 作用:定义表之间的连接条件,如
INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。 - 顺序:在
FROM子句识别出参与查询的表后,接下来处理JOIN子句,确定如何将这些表连接起来。
- 作用:定义表之间的连接条件,如
-
ON(如果存在)
- 作用:提供连接条件的具体细节,指定如何匹配参与连接的表之间的相关列。
- 顺序:在
JOIN子句之后,解析器会处理ON子句中的连接条件。
-
WHERE
- 作用:对初步连接后的结果集进行行级筛选,丢弃不符合条件的行。
- 顺序:在完成表连接后,
WHERE子句的条件会被应用于每一行数据,过滤掉不符合条件的记录。
-
GROUP BY(如果存在)
- 作用:将结果集按照一个或多个列进行分组,对每个组进行聚合计算。
- 顺序:在行级筛选完成后,数据会被按照
GROUP BY子句指定的列进行分组。
-
HAVING(如果存在)
- 作用:对分组后的结果集进行组级筛选,丢弃不符合条件的组。
- 顺序:在分组完成后,
HAVING子句的条件会被应用于每个组,过滤掉不符合条件的组。
-
SELECT
- 作用:指定查询结果中要返回的列或表达式,包括列名、聚合函数、别名等。
- 顺序:在完成行级筛选、分组和组级筛选后,确定最终返回给用户的列和数据。
-
DISTINCT(如果存在)
- 作用:去除结果集中重复的行,确保返回唯一行。
- 顺序:通常与
SELECT子句关联,在确定了返回的列之后,去除重复行。
-
ORDER BY(如果存在)
- 作用:对查询结果按照一个或多个列进行排序。
- 顺序:在确定了返回的唯一行之后,对结果集进行排序。
-
LIMIT(如果存在)
- 作用:限制查询结果返回的行数,可以指定返回的起始位置和行数。
- 顺序:作为查询处理的最后一步,从已排序的结果集中选取指定数量的行返回给用户。
需要注意的是,虽然上述顺序描述了 SQL 关键字在解析阶段的逻辑处理流程,但在实际执行时,数据库查询优化器可能会根据成本估算和执行计划对这些操作进行重排和优化,以提高查询性能。不过,理解标准的执行顺序有助于编写正确的 SQL 查询语句,并对查询优化有一定指导意义。
6.IN 和 EXISTS的使用和区别
IN 和 EXISTS 是 SQL 中用于处理子查询条件判断的两种关键字。它们都可以用来检查主查询中的行是否与子查询结果中的某一行相匹配,但实现机制、性能表现和适用场景上存在一些区别:
IN 使用
SELECT Customers.CustomerName
FROM Customers
WHERE Customers.Country IN (SELECT Countries.CountryName FROM Countries WHERE Countries.Region = 'Europe');
SELECT Orders.OrderID
FROM Orders
WHERE Orders.CustomerID IN (100, 101, 102);说明:
IN后面可以跟一个子查询或一个值列表。- 对于子查询,它会执行子查询并获取结果集,然后检查主查询中的指定列值是否与子查询结果集中任何一个值相等。如果相等,则该行满足条件,被纳入结果集。
- 对于值列表,直接检查列值是否与列表中的任何一个值相等。
适用场景:
- 当需要查询主表中与子查询结果集中的特定值相等的行时,使用
IN。 - 当需要查询主表中与一个已知的固定值集合相等的行时,直接使用值列表形式的
IN。
EXISTS 使用
SELECT Customers.CustomerName
FROM Customers
WHERE EXISTS (SELECT 1 FROM Orders WHERE Orders.CustomerID = Customers.CustomerID);
SELECT Orders.OrderID
FROM Orders
WHERE EXISTS (SELECT 1 FROM OrderDetails WHERE OrderDetails.OrderID = Orders.OrderID AND OrderDetails.Quantity > 10);说明:
EXISTS后面只能跟一个子查询。- 它会逐行检查主查询表中的数据,对于每一行,执行子查询。如果子查询返回至少一行结果,则
EXISTS条件为真,该行满足条件,被纳入结果集。一旦子查询找到了一个匹配项,EXISTS条件即得到满足,无需继续检查剩余行。 EXISTS仅关心子查询是否存在匹配的行,而不关心具体的匹配值。因此,子查询通常只需返回一个固定值(如SELECT 1)即可。
适用场景:
- 当需要查询主表中存在与子查询结果相匹配的行时,使用
EXISTS。 - 当子查询较复杂,尤其是包含聚合函数、多表连接等操作,或者子查询表较大但有高效索引时,使用
EXISTS可能更利于优化器进行查询优化。
区别
- 关注点:
IN关注的是主查询列值与子查询结果集中具体值的匹配,而EXISTS关注的是主查询行是否存在与子查询结果相匹配的行,不关心具体的匹配值。 - 性能:
IN和EXISTS的性能表现取决于主查询表和子查询表的大小、数据分布、索引情况以及查询的具体条件。一般来说,当子查询结果集小且主查询表大时,IN可能更高效;当主查询表小且子查询复杂或子查询表大但有高效索引时,EXISTS可能更高效。 - NULL 值处理:如果子查询结果集中包含
NULL值,IN的行为可能会变得不可预测,因为NULL与其他任何值的比较结果都是未知(NULL),这可能导致预期之外的结果。而EXISTS不受此影响。 - 适用场景:
IN适用于查询主表中与子查询结果集中的特定值相等的行,或与固定值集合相等的行;EXISTS适用于查询主表中存在与子查询结果相匹配的行,特别是当子查询复杂或子查询表有高效索引时。
7.Union 和 Union All 的区别
UNION 和 UNION ALL 是 SQL 中用于合并两个或多个 SELECT 语句结果集的集合操作符。虽然它们的基本功能都是将多个查询结果合并为一个结果集,但它们在处理重复数据和执行效率方面存在显著区别:
UNION
特点:
- 去重:
UNION在合并结果集时会自动去除重复的行。这意味着在最终结果集中,任何两行具有完全相同的列值(在所有列上都相同)的行只会出现一次。 - 排序:为了实现去重,
UNION操作在内部通常会对结果集进行排序(尽管结果集返回给用户时不一定保持排序)。排序操作会消耗额外的时间和资源。 - 性能:由于需要进行去重和可能的排序操作,
UNION的执行效率通常低于UNION ALL。
使用示例:
SELECT CustomerName FROM Customers WHERE Country = 'USA'
UNION
SELECT CustomerName FROM Customers WHERE Country = 'Canada';UNION ALL
特点:
- 保留重复:
UNION ALL不会去除重复行,它直接将所有查询结果拼接到一起,即使有完全相同的行也会在结果集中重复出现。 - 无需排序:由于不进行去重,
UNION ALL不需要对结果集进行排序,因此它的执行效率通常高于UNION。 - 节省资源:由于省去了去重操作,
UNION ALL在处理大数据集时尤其高效,尤其是在源数据中重复行很少或不存在时。
使用示例:
SELECT CustomerName FROM Customers WHERE Country = 'USA'
UNION ALL
SELECT CustomerName FROM Customers WHERE Country = 'Canada';何时使用
- 使用
UNION:当需要合并多个查询结果并确保结果集中没有重复行时,例如在提取唯一客户列表、合并多个数据源的不重复记录等场景下使用UNION。 - 使用
UNION ALL:当合并的查询结果中重复行是可以接受的,或者确信源数据中没有重复行,或者为了提高查询性能而愿意牺牲结果集的唯一性时,应使用UNION ALL。例如,当合并包含完全相同数据的表副本、累积统计数据等场景下使用UNION ALL。
总结
- UNION:合并结果集时自动去除重复行,执行效率较低,适用于需要唯一结果集的场景。
- UNION ALL:合并结果集时不进行去重,执行效率较高,适用于允许重复行或追求查询性能的场景。
选择使用 UNION 还是 UNION ALL,应根据实际业务需求、数据特性和对查询性能的要求来决定。如果对结果集的唯一性要求严格且源数据中的重复数据不多,UNION 是合适的选择;如果允许结果集中存在重复行,或者知道源数据中没有重复,或者更关注查询速度,那么应使用 UNION ALL。在实际应用中,如果不确定是否存在重复数据,可以先尝试使用 UNION ALL,如果发现结果中有不必要的重复,再改用 UNION 并进行必要的性能评估。
8.Drop、Delete 和 Truncate 的区别
DROP、DELETE 和 TRUNCATE 都是 SQL 中用于删除数据的语句,但它们各自针对的对象、操作方式以及对数据和元数据的影响存在显著差异:
DROP(属于DDL)
特点:
- 删除对象:
DROP语句用于删除整个数据库对象,如表、视图、索引、触发器、存储过程等。 - 数据与元数据:
DROP不仅删除表中的所有数据,还删除与该对象相关的元数据(如表结构、约束、索引等)。 - 不可恢复:执行
DROP操作后,除非事先有数据库备份,否则被删除的对象及其数据无法恢复。 - 权限:执行
DROP通常需要具有足够的权限,如DROP TABLE需要对表拥有DROP权限。
语法:
DROP DATABASE database_name;
DROP TABLE table_name;
DROP VIEW view_name;
DROP INDEX index_name;
DROP PROCEDURE procedure_name;
-- 其他对象类型的 DROP 语句...DELETE(属于DML)
特点:
- 删除数据:
DELETE语句用于删除表中的部分或全部数据,但保留表结构及其相关元数据(如约束、索引等)。 - 条件删除:
DELETE可以带WHERE子句,根据指定的条件删除满足条件的行。如果不指定WHERE子句,将删除表中的所有数据。 - 可恢复:执行
DELETE操作后,如果数据库开启了事务支持且操作在事务中,可以通过事务回滚恢复数据。另外,如果有相应的备份或日志记录,也可通过还原操作恢复数据。 - 触发器:
DELETE操作会触发定义在表上的ON DELETE触发器。
语法:
DELETE FROM table_name [WHERE condition];TRUNCATE(属于DDL)
特点:
- 删除数据:
TRUNCATE语句用于快速删除表中的所有数据,但保留表结构及其相关元数据(如约束、索引等)。 - 不可恢复:
TRUNCATE操作通常不可通过事务回滚恢复,因为它是DDL操作(在某些数据库中可能视为DML操作,如MySQL)。同样,如果没有备份或日志记录,被删除的数据也无法恢复。 - 效率:相对于
DELETE(特别是带有WHERE子句的DELETE),TRUNCATE操作通常更快,因为它不记录每条被删除行的详细信息,也不触发ON DELETE触发器。 - 权限:执行
TRUNCATE通常需要与DELETE类似的权限,但某些数据库系统可能要求更严格的权限,如TRUNCATE TABLE需要对表拥有TRUNCATE或DROP权限。
语法:
TRUNCATE TABLE table_name;总结
- DROP:删除整个数据库对象及其所有数据和元数据,不可恢复,需要较高权限。
- DELETE:删除表中满足条件的部分或全部数据,可恢复(在事务支持下或有备份/日志),触发触发器。
- TRUNCATE:快速删除表中所有数据,保留表结构,不可恢复(通常),不触发触发器,效率高。
选择使用 DROP、DELETE 或 TRUNCATE 应根据实际需求来决定:
- 如果要彻底移除一个数据库对象及其所有数据和元数据,使用
DROP。 - 如果要删除表中的部分数据并希望触发触发器或需要事务支持,使用
DELETE。 - 如果要快速删除表中的所有数据且不需要恢复或触发触发器,使用
TRUNCATE。















 1980
1980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









