






1.请求路径
https://gupiao.baidu.com/api/stocks/stockdaybar?from=pc&os_ver=1&cuid=xxx&vv=100&format=json&stock_code=sh600392&step=3&start=&count=160
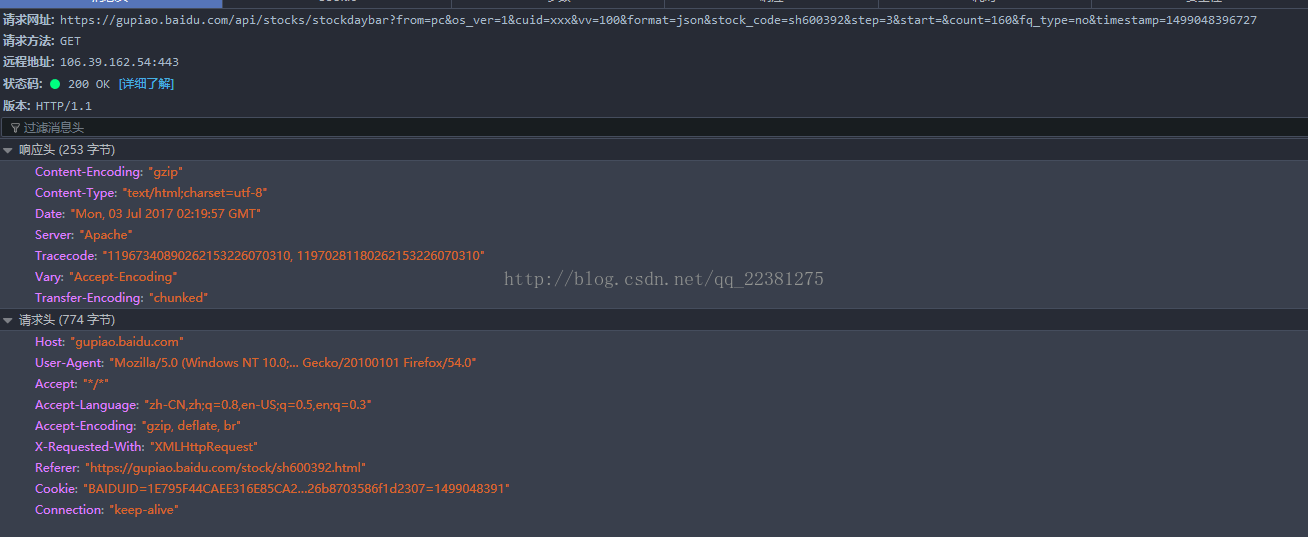
2.url分析
使用过程中需要修改到的请求参数有
stock_code:请求的股票代码(sh/sz000000)
start:开始的日期(20170623)
count:请求几条(2)
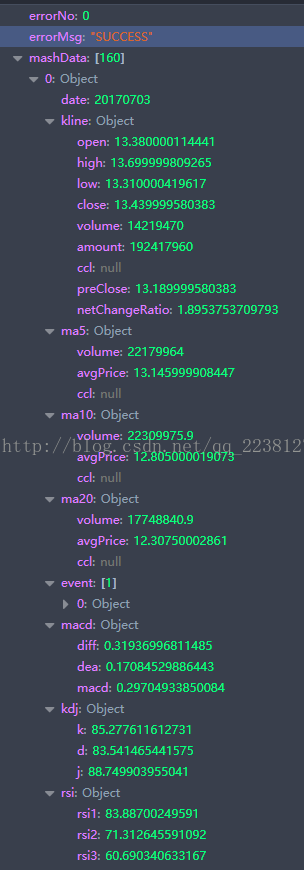
3.返回结果分析
主要获取的数据有mashData=>kline
这里面有 开盘价 收盘价 最好价 最低价 等等

















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









