







第 1 章Doris简介
1.1、 Doris 概述
Apache Doris由百度大数据部研发(之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris),在百度内部,有超过200个产品线在使用,部署机器超过1000台,单一业务最大可达到上百 TB。
Apache Doris是一个现代化的MPP (Massively Parallel Processing,即大规模并行处理)分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
1.2、 Doris 使用场景
数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive,Iceberg,Hudi 中),Apache Doris 被广泛应用在以下场景中。
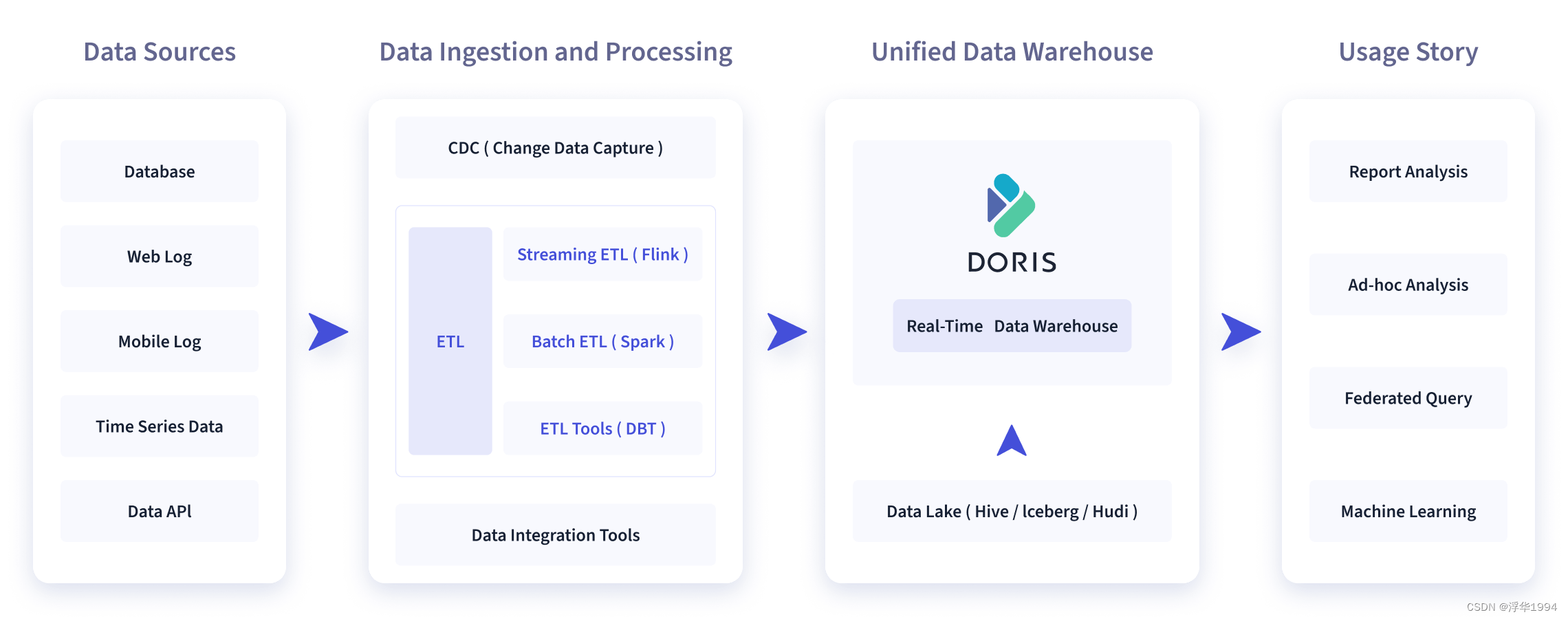
1)报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的QPS,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris,每天写入100亿行数据,查询并发 QPS上万,99分位的查询延时150ms。
2)即席查询(Ad-hoc Query)
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于Doris构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95分位的查询延时30s以内,每天的SQL查询量为数万条。
3)统一数仓构建
面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于Doris构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95分位的查询延时30s以内,每天的SQL查询量为数万条。
4)数据湖联邦查询
通过外表的方式联邦分析位于 Hive、Iceberg、Hudi中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
1.3、Doris 架构
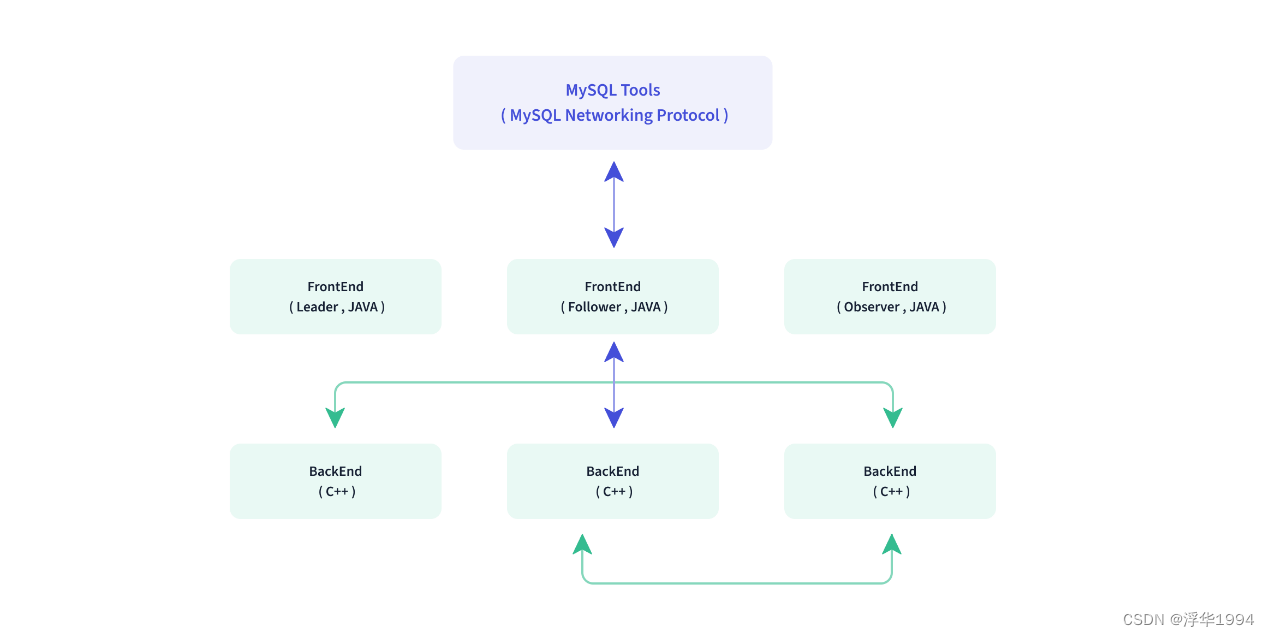
Doris整体架构如图所示,非常简单,只有两类进程:
1)Frontend(FE)
主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
主要有三个角色:
(1)Leader 和Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
(2)Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
2)Backend(BE)
主要负责数据存储、查询计划的执行。
数据的可靠性由BE保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
3)MySQL Client
Doris借助MySQL协议,用户使用任意MySQL的ODBC/JDBC以及MySQL的客户端,都可以直接访问Doris。
4)Broker
Broker是Doris集群中一种可选进程,主要用于支持Doris读写远端存储上的文件和目录,如 HDFS、BOS和AFS等。
第 2 章Doris安装和部署
2.1、 安装要求
2.1.1、 Linux操作系统要求
| linux系统 | 版本 |
|---|---|
| Centos | 7.1及以上 |
| Ubuntu | 16.04及以上 |
2.1.2 、软件需求
| 软件 | 版本 |
|---|---|
| Java | 1.8及以上 |
| GCC | 4.8.2及以上 |
2.1.3、 开发测试环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| Frontend | 8核+ | 8GB | SSD 或 SATA,10GB+ * | 千兆网卡 | 1 |
| Backend | 8核+ | 16GB | SSD 或 SATA,50GB+ * | 千兆网卡 | 1-3* |
2.1.4、 生产环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| rontend | 16核+ | 64GB | SSD 或 SATA,100GB+ * | 万兆网卡 | 1-5* |
| Backend | 16核+ | 64GB | SSD 或 SATA,100GB+ * | 万兆网卡 | 10-100* |
2.1.5、 注意事项
(1)FE的磁盘空间主要用于存储元数据,包括日志和image。通常从几百MB到几个GB不等。
(2)BE的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量 * 3(3副本)计算,然后再预留额外40%的空间用作后台compaction以及一些中间数据的存放。(如果为节省磁盘空间)
(3)一台机器上可以部署多个BE实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个BE实例(而不是1台机器部署3个BE实例)。多个FE所在服务器的时钟必须保持一致(允许最多5秒的时钟偏差)
(4)测试环境也可以仅适用一个BE进行测试。实际生产环境,BE实例数量直接决定了整体查询延迟。
(5)所有部署节点关闭Swap。
(6)FE节点数据至少为1(1个Follower)。当部署1个Follower和1个Observer时,可以实现读高可用。当部署3个Follower时,可以实现读写高可用(HA)。
(7)Follower的数量必须为奇数,Observer 数量随意。
(8)根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署3个 Follower和1-3个Observer。如果是离线业务,建议部署1个Follower和1-3个Observer。
(9)Broker是用于访问外部数据源(如HDFS)的进程。通常,在每台机器上部署一个 broker实例即可。
2.1.6、 内部端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_prot | 9060 | FE–>BE | BE上thrift server的端口用于接收来自FE 的请求 |
| BE | webserver_port | 8040 | BE<–>FE | BE上的http server端口 |
| BE | heartbeat_service_port | 9050 | FE–>BE | BE上心跳服务端口用于接收来自FE的心跳 |
| BE | brpc_prot* | 8060 | FE<–>BEBE<–>BE | BE上的brpc端口用于BE之间通信 |
| FE | http_port | 8030 | FE<–>FE用户<–> FE | FE上的http_server端口 |
| FE | rpc_port | 9020 | BE–>FEFE<–>FE | FE上thirt server端口号 |
| FE | query_port | 9030 | 用户<–> FE | FE上的mysql server端口 |
| FE | edit_log_port | 9010 | FE<–>FE | FE上bdbje之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE–>BROKERBE–>BROKER | Broker上的thrift server用于接收请求 |
当部署多个FE实例时,要保证FE的http_port配置相同。
部署前请确保各个端口在应有方向上的访问权限。
2.2、集群部署
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| FE(LEADER) | FE(FOLLOWER) | FE(FOLLOWER) |
| BE | BE | BE |
生产环境建议FE和BE分开。
2.2.1、 操作系统安装要求
设置系统最大打开文件句柄数(注意这里的*不要去掉)。
sudo vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
设置最大虚拟块的大小。
sudo vim /etc/sysctl.conf
vm.max_map_count=2000000
重启生效。
2.2.2、下载安装包
根据自己的需要,下载合适的安装包。
https://doris.apache.org/download/
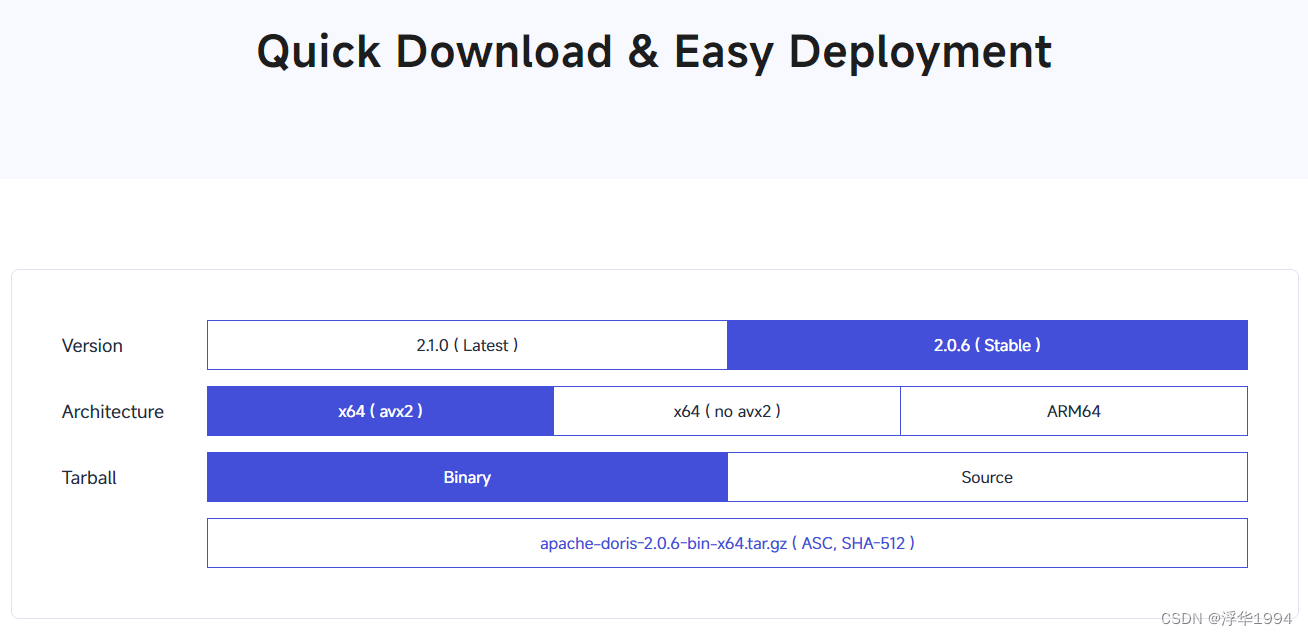
x86_64架构 cpu(intel,amd),执行命令:
cat /proc/cpuinfo | grep avx2
如果能看到avx2 字样选择带 avx2 的包,否则选择不带 avx2。
arm64 架构 cpu(apple),选择 arm64 的安装包下载。
2.2.3、解压
新版本的be,fe的包在一起,直接使用即可
[sunfeng@hadoop102 software]$ tar -zxvf apache-doris-2.0.6-bin-x64.tar.gz -C /opt/module/
[sunfeng@hadoop102 module]$ cd /opt/module/
[sunfeng@hadoop102 module]$ mv apache-doris-2.0.6-bin-x64/ doris/
[sunfeng@hadoop102 module]$ cd doris/
[sunfeng@hadoop102 doris]$ ll
总用量 0
drwxr-xr-x 11 sunfeng sunfeng 163 3月 12 19:10 be
drwxr-xr-x 4 sunfeng sunfeng 52 3月 12 19:10 extensions
drwxr-xr-x 13 sunfeng sunfeng 227 3月 20 19:09 fe
2.2.4、配置FE
1)修改FE配置文件
vim /opt/module/doris/fe/conf/fe.conf
# web 页面访问端口
http_port = 7030
# 配置文件中指定元数据路径:默认在 fe 的根目录下,可以不配
# meta_dir = /opt/module/doris/fe/doris-meta
# 修改绑定 ip
priority_networks = 192.168.254.102/24
Ø 生产环境强烈建议单独指定目录不要放在Doris安装目录下,最好是单独的磁盘(如果有SSD最好)。
Ø 如果机器有多个IP,比如内网外网, 虚拟机docker等,需要进行IP绑定,才能正确识别。
Ø JAVA_OPTS 默认Java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。
2)启动FE
/opt/module/doris/fe/bin/start_fe.sh --daemon
3)登录 FE Web页面
地址:http://hadoop102:7030/login
用户:root
密码:无
2.2.5、配置 BE
1)修改BE配置文件
vim /opt/module/doris/be/conf/be.conf
webserver_port = 7040
# 不配置存储目录, 则会使用默认的存储目录
#storage_root_path = /opt/module/doris/doris-storage1;/opt/module/doris/doris-storage2.SSD,10
priority_networks = 192.168.254.102/24
mem_limit=40%
注意:
Ø storage_root_path默认在be/storage下,需要手动创建该目录。多个路径之间使用英文状态的分号;分隔(最后一个目录后不要加)。
Ø 可以通过路径区别存储目录的介质,HDD或SSD。可以添加容量限制在每个路径的末尾,通过英文状态逗号,隔开,如:
storage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris
说明:
/home/disk1/doris.HDD,50,表示存储限制为50GB,HDD;
/home/disk2/doris.SSD,10,存储限制为10GB,SSD;
/home/disk2/doris,存储限制为磁盘最大容量,默认为HDD。
Ø 如果是 hdd,sdd 混合存储,则直接写目录即可。
Ø 如果机器有多个IP, 比如内网外网, 虚拟机docker等, 需要进行IP绑定,才能正确识别。
2)分发doris
[sunfeng@hadoop102 module]$ xsync doris/
2.2.6、添加 BE
BE节点需要先在FE中添加,才可加入集群。可以使用mysql-client连接到FE。
1)安装 Mysql 客户端
略
2)使用 Mysql 客户端连接到 FE
mysql -hhadoop102 -P9030 -uroot
Ø -P 指定端口(注意这里 P 是大写,小写 p 用来指定密码)
Ø FE 默认没有密码
Ø 设置密码:SET PASSWORD FOR ‘root’ = PASSWORD(‘sunfeng’);
[sunfeng@hadoop102 ~]$ mysql -hhadoop102 -P9030 -uroot -psunfeng
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 5.7.99 Doris version doris-2.0.6-d75ba6ef4e
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
3)添加 BE
##注意 IP最好直接写192.168.254.102 而不是hadoop102 会有问题
mysql> ALTER SYSTEM ADD BACKEND "192.168.254.102:9050";
Query OK, 0 rows affected (0.00 sec)
mysql> ALTER SYSTEM ADD BACKEND "192.168.254.103:9050";
Query OK, 0 rows affected (0.01 sec)
mysql> ALTER SYSTEM ADD BACKEND "192.168.254.104:9050";
Query OK, 0 rows affected (0.00 sec)
4)查看 BE状态
mysql> SHOW PROC '/backends'\G
*************************** 1. row ***************************
BackendId: 11035
Host: 192.168.254.102
HeartbeatPort: 9050
BePort: 9060
HttpPort: 7040
BrpcPort: 8060
LastStartTime: 2024-03-20 19:43:42
LastHeartbeat: 2024-03-21 18:57:02
Alive: false
SystemDecommissioned: false
TabletNum: 14
DataUsedCapacity: 0.000
TrashUsedCapcacity: 0.000
AvailCapacity: 23.317 GB
TotalCapacity: 44.974 GB
UsedPct: 48.15 %
MaxDiskUsedPct: 48.15 %
RemoteUsedCapacity: 0.000
Tag: {"location" : "default"}
ErrMsg: java.net.ConnectException: 拒绝连接 (Connection refused)
Version:
Status: {"lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false}
HeartbeatFailureCounter: 16
NodeRole:
*************************** 2. row ***************************
5)启动 BE
我这里配置了环境变量 所以可以执行 start_be.sh --daemon
#doris fe
export DORIS_FE_HOME=/opt/module/doris/fe
export PATH=$PATH:$DORIS_FE_HOME/bin
#doris be
export DORIS_BE_HOME=/opt/module/doris/be
export PATH=$PATH:$DORIS_BE_HOME/bin
分别在三个节点执行如下命令。
[sunfeng@hadoop102 doris]$ start_be.sh --daemon
[sunfeng@hadoop103 doris]$ start_be.sh --daemon
[sunfeng@hadoop104 doris]$ start_be.sh --daemon
6)查询 BE 状态
Alive: true 说明添加成功
mysql> SHOW PROC '/backends'\G
*************************** 1. row ***************************
BackendId: 11035
Host: 192.168.254.102
HeartbeatPort: 9050
BePort: 9060
HttpPort: 7040
BrpcPort: 8060
LastStartTime: 2024-03-21 19:07:28
LastHeartbeat: 2024-03-21 19:07:40
Alive: true # true
SystemDecommissioned: false
TabletNum: 14
DataUsedCapacity: 0.000
TrashUsedCapcacity: 0.000
AvailCapacity: 23.387 GB
TotalCapacity: 44.974 GB
UsedPct: 48.00 %
MaxDiskUsedPct: 48.00 %
RemoteUsedCapacity: 0.000
Tag: {"location" : "default"}
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
Status: {"lastSuccessReportTabletsTime":"2024-03-21 19:07:31","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false}
HeartbeatFailureCounter: 0
NodeRole: mix
*************************** 2. row ***************************
BackendId: 11036
Host: 192.168.254.103
HeartbeatPort: 9050
BePort: 9060
HttpPort: 7040
BrpcPort: 8060
LastStartTime: 2024-03-21 19:07:33
LastHeartbeat: 2024-03-21 19:07:40
Alive: true
SystemDecommissioned: false
TabletNum: 14
DataUsedCapacity: 0.000
TrashUsedCapcacity: 0.000
AvailCapacity: 31.713 GB
TotalCapacity: 44.974 GB
UsedPct: 29.49 %
MaxDiskUsedPct: 29.49 %
RemoteUsedCapacity: 0.000
Tag: {"location" : "default"}
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
Status: {"lastSuccessReportTabletsTime":"2024-03-21 19:07:40","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false}
HeartbeatFailureCounter: 0
NodeRole: mix
*************************** 3. row ***************************
2.3、扩容和缩容
2.3.1、FE 扩容和缩容
可以通过将FE扩容至3个以上节点(必须是奇数)来实现FE的高可用。
2.3.2、查看 FE 状态
[sunfeng@hadoop102 ~]$ mysql -hhadoop102 -P9030 -uroot -psunfeng
mysql> show proc '/frontends'\G;
*************************** 1. row ***************************
Name: fe_02c92eb6_af49_4c97_bebc_0d93cd945b37
Host: 192.168.254.102
EditLogPort: 9010
HttpPort: 7030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 449227781
Join: true
Alive: true
ReplayedJournalId: 213
LastHeartbeat: 2024-03-21 21:35:42
IsHelper: true
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
CurrentConnected: Yes
1 row in set (0.04 sec)
ERROR:
No query specified
目前只有一个 FE。
1)增加FE节点
FE分为Leader,Follower和Observer三种角色。 默认一个集群只能有一个Leader,可以有多个Follower和Observer。其中Leader和Follower组成一个Paxos选择组,如果 Leader宕机,则剩下的Follower 会自动选出新的Leader,保证写入高可用。Observer 同步 Leader的数据,但是不参加选举。
如果只部署一个FE,则FE 默认就是Leader。在此基础上,可以添加若干Follower和 Observer。
mysql> ALTER SYSTEM ADD OBSERVER "192.168.254.103:9010";
Query OK, 0 rows affected (0.01 sec)
mysql> ALTER SYSTEM ADD OBSERVER "192.168.254.104:9010";
Query OK, 0 rows affected (0.01 sec)
2)配置Follower和Observer
(1)上面我们已经完成了分发
注意:需要去 hadoop103 和 hadoop104 删除 hadoop102 发过来的元数据。
[sunfeng@hadoop103 be]$ rm -rf /opt/module/doris/fe/doris-meta/*
[sunfeng@hadoop104 be]$ rm -rf /opt/module/doris/fe/doris-meta/*
(2)在 hadoop103和 hadoop104 启动 FE
第一次启动时,启动命令需要添加参 --helper leader主机: edit_log_port
分别在hadoop103和 hadoop104 执行:
[sunfeng@hadoop103 be]$ start_fe.sh --daemon --helper 192.168.254.102:9010
[sunfeng@hadoop104 be]$ start_fe.sh --daemon --helper 192.168.254.102:9010
(3)在 mysql 客户端查看 FE 状态
mysql> show proc '/frontends'\G
*************************** 1. row ***************************
Name: fe_02c92eb6_af49_4c97_bebc_0d93cd945b37
Host: 192.168.254.102
EditLogPort: 9010
HttpPort: 7030
QueryPort: 9030
RpcPort: 9020
Role: FOLLOWER
IsMaster: true
ClusterId: 449227781
Join: true
Alive: true
ReplayedJournalId: 427
LastHeartbeat: 2024-03-21 21:47:28
IsHelper: true
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
CurrentConnected: Yes
*************************** 2. row ***************************
Name: fe_af585cf5_8b62_44fa_90a0_a095fe6ccc7b
Host: 192.168.254.103
EditLogPort: 9010
HttpPort: 7030
QueryPort: 9030
RpcPort: 9020
Role: OBSERVER
IsMaster: false
ClusterId: 449227781
Join: true
Alive: true
ReplayedJournalId: 426
LastHeartbeat: 2024-03-21 21:47:28
IsHelper: false
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
CurrentConnected: No
*************************** 3. row ***************************
Name: fe_5c6cc355_a611_4142_8c5c_c7c1b975c6b7
Host: 192.168.254.104
EditLogPort: 9010
HttpPort: 7030
QueryPort: 9030
RpcPort: 9020
Role: OBSERVER
IsMaster: false
ClusterId: 449227781
Join: true
Alive: true
ReplayedJournalId: 426
LastHeartbeat: 2024-03-21 21:47:28
IsHelper: false
ErrMsg:
Version: doris-2.0.6-d75ba6ef4e
CurrentConnected: No
3 rows in set (0.04 sec)
3)删除 FE 节点(缩容)
ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port";
注意:删除 Follower FE 时,确保最终剩余的 Follower(包括 Leader)节点为奇数。
2.3.3、BE 扩容和缩容
1)增加BE节点
在MySQL客户端,通过 ALTER SYSTEM ADD BACKEND 命令增加BE节点。
2)DROP方式删除BE节点(不推荐)
ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port";
注意:DROP BACKEND 会直接删除该BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除BE节点。当你使用这个语句时,会有对应的防误操作提示。
3)DECOMMISSION 方式删除BE节点(推荐)
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
Ø 该命令用于安全删除BE节点。命令下发后,Doris 会尝试将该BE上的数据向其他BE节点迁移,当所有数据都迁移完成后,Doris会自动删除该节点。
Ø 该命令是一个异步操作。执行后,可以通过 SHOW PROC ‘/backends’; 看到该 BE 节点的isDecommission状态为true。表示该节点正在进行下线。
Ø 该命令不一定执行成功。比如剩余BE存储空间不足以容纳下线BE上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且BE会一直处于 isDecommission为true的状态。
Ø DECOMMISSION的进度,可以通过SHOW PROC ‘/backends’; 中的TabletNum查看,如果正在进行,TabletNum将不断减少。
Ø 该操作可以通过如下命令取消:
CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
取消后,该BE上的数据将维持当前剩余的数据量。后续Doris重新进行负载均衡。
2.4、Doris 集群群起脚本
#!/bin/bash
case $1 in
"start")
for host in hadoop102 hadoop103 hadoop104 ; do
echo "========== 在 $host 上启动 fe ========="
ssh $host "source /etc/profile; /opt/module/doris/fe/bin/start_fe.sh --daemon"
done
for host in hadoop102 hadoop103 hadoop104 ; do
echo "========== 在 $host 上启动 be ========="
ssh $host "source /etc/profile; /opt/module/doris/be/bin/start_be.sh --daemon"
done
;;
"stop")
for host in hadoop102 hadoop103 hadoop104 ; do
echo "========== 在 $host 上停止 fe ========="
ssh $host "source /etc/profile; /opt/module/doris/fe/bin/stop_fe.sh "
done
for host in hadoop102 hadoop103 hadoop104 ; do
echo "========== 在 $host 上停止 be ========="
ssh $host "source /etc/profile; /opt/module/doris/be/bin/stop_be.sh "
done
;;
*)
echo "你启动的姿势不对"
echo " start 启动doris集群"
echo " stop 停止stop集群"
;;
esac
2.5、帮助
mysql> HELP CREATE TABLE
Name: ‘CREATE TABLE’
Description:
该命令用于创建一张表。本文档主要介绍创建 Doris 自维护的表的语法。外部表语法请参阅 CREATE-EXTERNAL-TABLE文档。
CREATE TABLE [IF NOT EXISTS] [database.]table
(
column_definition_list
[, index_definition_list]
)
[engine_type]
[keys_type]
[table_comment]
[partition_info]
distribution_desc
[rollup_list]
[properties]
[extra_properties]
column_definition_list
列定义列表:
column_definition[, column_definition]
-
column_definition
列定义:column_name column_type [KEY] [aggr_type] [NULL] [AUTO_INCREMENT] [default_value] [column_comment]-
column_type
列类型,支持以下类型:TINYINT(1字节) 范围:-2^7 + 1 ~ 2^7 - 1 SMALLINT(2字节) 范围:-2^15 + 1 ~ 2^15 - 1 INT(4字节) 范围:-2^31 + 1 ~ 2^31 - 1 BIGINT(8字节) 范围:-2^63 + 1 ~ 2^63 - 1 LARGEINT(16字节) 范围:-2^127 + 1 ~ 2^127 - 1 FLOAT(4字节) 支持科学计数法 DOUBLE(12字节) 支持科学计数法 DECIMAL[(precision, scale)] (16字节) 保证精度的小数类型。默认是 DECIMAL(9, 0) precision: 1 ~ 27 scale: 0 ~ 9 其中整数部分为 1 ~ 18 不支持科学计数法 DATE(3字节) 范围:0000-01-01 ~ 9999-12-31 DATETIME(8字节) 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 CHAR[(length)] 定长字符串。长度范围:1 ~ 255。默认为1 VARCHAR[(length)] 变长字符串。长度范围:1 ~ 65533。默认为65533 HLL (1~16385个字节) HyperLogLog 列类型,不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。 必须配合 HLL_UNION 聚合类型使用。 BITMAP bitmap 列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到2^64 - 1。 必须配合 BITMAP_UNION 聚合类型使用。 -
aggr_type
聚合类型,支持以下聚合类型:SUM:求和。适用数值类型。 MIN:求最小值。适合数值类型。 MAX:求最大值。适合数值类型。 REPLACE:替换。对于维度列相同的行,指标列会按照导入的先后顺序,后导入的替换先导入的。 REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于null值,不做替换。这里要注意的是字段默认值要给NULL,而不能是空字符串,如果是空字符串,会给你替换成空字符串。 HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。 BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。 -
AUTO_INCREMENT(仅在master分支可用)是否为自增列,自增列可以用来为新插入的行生成一个唯一标识。在插入表数据时如果没有指定自增列的值,则会自动生成一个合法的值。当自增列被显示地插入NULL时,其值也会被替换为生成的合法值。需要注意的是,处于性能考虑,BE会在内存中缓存部分自增列的值,所以自增列自动生成的值只能保证单调性和唯一性,无法保证严格的连续性。
一张表中至多有一个列是自增列,自增列必须是BIGINT类型,且必须为NOT NULL。
Duplicate模型表和Unique模型表均支持自增列。 -
default_value
列默认值,当导入数据未指定该列的值时,系统将赋予该列default_value。语法为`default default_value`。 当前default_value支持两种形式: 1. 用户指定固定值,如: ```SQL k1 INT DEFAULT '1', k2 CHAR(10) DEFAULT 'aaaa' ``` 2. 系统提供的关键字,目前支持以下关键字: ```SQL // 只用于DATETIME类型,导入数据缺失该值时系统将赋予当前时间 dt DATETIME DEFAULT CURRENT_TIMESTAMP ```
示例:
k1 TINYINT, k2 DECIMAL(10,2) DEFAULT "10.5", k4 BIGINT NULL DEFAULT "1000" COMMENT "This is column k4", v1 VARCHAR(10) REPLACE NOT NULL, v2 BITMAP BITMAP_UNION, v3 HLL HLL_UNION, v4 INT SUM NOT NULL DEFAULT "1" COMMENT "This is column v4" -
index_definition_list
索引列表定义:
index_definition[, index_definition]
-
index_definition索引定义:
INDEX index_name (col_name) [USING INVERTED] COMMENT 'xxxxxx'示例:
INDEX idx1 (k1) USING INVERTED COMMENT "This is a inverted index1", INDEX idx2 (k2) USING INVERTED COMMENT "This is a inverted index2", ...
engine_type
表引擎类型。本文档中类型皆为 OLAP。其他外部表引擎类型见 CREATE EXTERNAL TABLE 文档。示例:
`ENGINE=olap`
keys_type
数据模型。
key_type(col1, col2, ...)
key_type 支持以下模型:
- DUPLICATE KEY(默认):其后指定的列为排序列。
- AGGREGATE KEY:其后指定的列为维度列。
- UNIQUE KEY:其后指定的列为主键列。
示例:
DUPLICATE KEY(col1, col2),
AGGREGATE KEY(k1, k2, k3),
UNIQUE KEY(k1, k2)
table_comment
表注释。示例:
COMMENT "This is my first DORIS table"
partition_info
分区信息,支持三种写法:
-
LESS THAN:仅定义分区上界。下界由上一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...]) ( PARTITION partition_name1 VALUES LESS THAN MAXVALUE|("value1", "value2", ...), PARTITION partition_name2 VALUES LESS THAN MAXVALUE|("value1", "value2", ...) ) -
FIXED RANGE:定义分区的左闭右开区间。
PARTITION BY RANGE(col1[, col2, ...]) ( PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)), PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, )) ) -
MULTI RANGE:批量创建RANGE分区,定义分区的左闭右开区间,设定时间单位和步长,时间单位支持年、月、日、周和小时。
PARTITION BY RANGE(col) ( FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR, FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH, FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK, FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY ) -
MULTI RANGE:批量创建数字类型的RANGE分区,定义分区的左闭右开区间,设定步长。
PARTITION BY RANGE(int_col) ( FROM (1) TO (100) INTERVAL 10 )
distribution_desc
定义数据分桶方式。
- Hash 分桶
语法:
DISTRIBUTED BY HASH (k1[,k2 ...]) [BUCKETS num|auto]
说明:
使用指定的 key 列进行哈希分桶。 - Random 分桶
语法:
DISTRIBUTED BY RANDOM [BUCKETS num|auto]
说明:
使用随机数进行分桶。
rollup_list
建表的同时可以创建多个物化视图(ROLLUP)。
ROLLUP (rollup_definition[, rollup_definition, ...])
-
rollup_definitionrollup_name (col1[, col2, ...]) [DUPLICATE KEY(col1[, col2, ...])] [PROPERTIES("key" = "value")]示例:
ROLLUP ( r1 (k1, k3, v1, v2), r2 (k1, v1) )
properties
设置表属性。目前支持以下属性:
-
replication_num副本数。默认副本数为3。如果 BE 节点数量小于3,则需指定副本数小于等于 BE 节点数量。
在 0.15 版本后,该属性将自动转换成
replication_allocation属性,如:"replication_num" = "3"会自动转换成"replication_allocation" = "tag.location.default:3" -
replication_allocation根据 Tag 设置副本分布情况。该属性可以完全覆盖
replication_num属性的功能。 -
is_being_synced用于标识此表是否是被CCR复制而来并且正在被syncer同步,默认为
false。如果设置为
true:
colocate_with,storage_policy属性将被擦除
dynamic partition,auto bucket功能将会失效,即在show create table中显示开启状态,但不会实际生效。当is_being_synced被设置为false时,这些功能将会恢复生效。这个属性仅供CCR外围模块使用,在CCR同步的过程中不要手动设置。
-
storage_medium/storage_cooldown_time数据存储介质。
storage_medium用于声明表数据的初始存储介质,而storage_cooldown_time用于设定到期时间。示例:"storage_medium" = "SSD", "storage_cooldown_time" = "2020-11-20 00:00:00"这个示例表示数据存放在 SSD 中,并且在 2020-11-20 00:00:00 到期后,会自动迁移到 HDD 存储上。
-
colocate_with当需要使用 Colocation Join 功能时,使用这个参数设置 Colocation Group。
"colocate_with" = "group1" -
bloom_filter_columns用户指定需要添加 Bloom Filter 索引的列名称列表。各个列的 Bloom Filter 索引是独立的,并不是组合索引。
"bloom_filter_columns" = "k1, k2, k3" -
in_memory已弃用。只支持设置为’false’。
-
compressionDoris 表的默认压缩方式是 LZ4。1.1版本后,支持将压缩方式指定为ZSTD以获得更高的压缩比。
"compression"="zstd" -
function_column.sequence_col当使用 UNIQUE KEY 模型时,可以指定一个sequence列,当KEY列相同时,将按照 sequence 列进行 REPLACE(较大值替换较小值,否则无法替换)
function_column.sequence_col用来指定sequence列到表中某一列的映射,该列可以为整型和时间类型(DATE、DATETIME),创建后不能更改该列的类型。如果设置了function_column.sequence_col,function_column.sequence_type将被忽略。"function_column.sequence_col" = 'column_name' -
function_column.sequence_type当使用 UNIQUE KEY 模型时,可以指定一个sequence列,当KEY列相同时,将按照 sequence 列进行 REPLACE(较大值替换较小值,否则无法替换)
这里我们仅需指定顺序列的类型,支持时间类型或整型。Doris 会创建一个隐藏的顺序列。
"function_column.sequence_type" = 'Date' -
light_schema_change是否使用light schema change优化。
如果设置成
true, 对于值列的加减操作,可以更快地,同步地完成。"light_schema_change" = 'true'该功能在 2.0.0 及之后版本默认开启。
-
disable_auto_compaction是否对这个表禁用自动compaction。
如果这个属性设置成
true, 后台的自动compaction进程会跳过这个表的所有tablet。"disable_auto_compaction" = "false" -
enable_single_replica_compaction是否对这个表开启单副本 compaction。
如果这个属性设置成
true, 这个表的 tablet 的所有副本只有一个 do compaction,其他的从该副本拉取 rowset"enable_single_replica_compaction" = "false" -
enable_duplicate_without_keys_by_default当配置为
true时,如果创建表的时候没有指定Unique、Aggregate或Duplicate时,会默认创建一个没有排序列和前缀索引的Duplicate模型的表。"enable_duplicate_without_keys_by_default" = "false" -
skip_write_index_on_load是否对这个表开启数据导入时不写索引.
如果这个属性设置成
true, 数据导入的时候不写索引(目前仅对倒排索引生效),而是在compaction的时候延迟写索引。这样可以避免首次写入和compaction
重复写索引的CPU和IO资源消耗,提升高吞吐导入的性能。"skip_write_index_on_load" = "false" -
compaction_policy配置这个表的 compaction 的合并策略,仅支持配置为 time_series 或者 size_based
time_series: 当 rowset 的磁盘体积积攒到一定大小时进行版本合并。合并后的 rowset 直接晋升到 base compaction 阶段。在时序场景持续导入的情况下有效降低 compact 的写入放大率
此策略将使用 time_series_compaction 为前缀的参数调整 compaction 的执行
"compaction_policy" = "" -
time_series_compaction_goal_size_mbytescompaction 的合并策略为 time_series 时,将使用此参数来调整每次 compaction 输入的文件的大小,输出的文件大小和输入相当
"time_series_compaction_goal_size_mbytes" = "1024" -
time_series_compaction_file_count_thresholdcompaction 的合并策略为 time_series 时,将使用此参数来调整每次 compaction 输入的文件数量的最小值
一个 tablet 中,文件数超过该配置,就会触发 compaction
"time_series_compaction_file_count_threshold" = "2000" -
time_series_compaction_time_threshold_secondscompaction 的合并策略为 time_series 时,将使用此参数来调整 compaction 的最长时间间隔,即长时间未执行过 compaction 时,就会触发一次 compaction,单位为秒
"time_series_compaction_time_threshold_seconds" = "3600" -
time_series_compaction_level_thresholdcompaction 的合并策略为 time_series 时,此参数默认为1,当设置为2时用来控住对于合并过一次的段再合并一层,保证段大小达到time_series_compaction_goal_size_mbytes,
能达到段数量减少的效果。
"time_series_compaction_level_threshold" = "2" -
动态分区相关
动态分区相关参数如下:
dynamic_partition.enable: 用于指定表级别的动态分区功能是否开启。默认为 true。dynamic_partition.time_unit:用于指定动态添加分区的时间单位,可选择为DAY(天),WEEK(周),MONTH(月),YEAR(年),HOUR(时)。dynamic_partition.start: 用于指定向前删除多少个分区。值必须小于0。默认为 Integer.MIN_VALUE。dynamic_partition.end: 用于指定提前创建的分区数量。值必须大于0。dynamic_partition.prefix: 用于指定创建的分区名前缀,例如分区名前缀为p,则自动创建分区名为p20200108。dynamic_partition.buckets: 用于指定自动创建的分区分桶数量。dynamic_partition.create_history_partition: 是否创建历史分区。dynamic_partition.history_partition_num: 指定创建历史分区的数量。dynamic_partition.reserved_history_periods: 用于指定保留的历史分区的时间段。
Examples:
-
创建一个明细模型的表
CREATE TABLE example_db.table_hash ( k1 TINYINT, k2 DECIMAL(10, 2) DEFAULT "10.5", k3 CHAR(10) COMMENT "string column", k4 INT NOT NULL DEFAULT "1" COMMENT "int column" ) COMMENT "my first table" DISTRIBUTED BY HASH(k1) BUCKETS 32 -
创建一个明细模型的表,分区,指定排序列,设置副本数为1
CREATE TABLE example_db.table_hash ( k1 DATE, k2 DECIMAL(10, 2) DEFAULT "10.5", k3 CHAR(10) COMMENT "string column", k4 INT NOT NULL DEFAULT "1" COMMENT "int column" ) DUPLICATE KEY(k1, k2) COMMENT "my first table" PARTITION BY RANGE(k1) ( PARTITION p1 VALUES LESS THAN ("2020-02-01"), PARTITION p2 VALUES LESS THAN ("2020-03-01"), PARTITION p3 VALUES LESS THAN ("2020-04-01") ) DISTRIBUTED BY HASH(k1) BUCKETS 32 PROPERTIES ( "replication_num" = "1" ); -
创建一个主键唯一模型的表,设置初始存储介质和冷却时间
CREATE TABLE example_db.table_hash ( k1 BIGINT, k2 LARGEINT, v1 VARCHAR(2048), v2 SMALLINT DEFAULT "10" ) UNIQUE KEY(k1, k2) DISTRIBUTED BY HASH (k1, k2) BUCKETS 32 PROPERTIES( "storage_medium" = "SSD", "storage_cooldown_time" = "2015-06-04 00:00:00" ); -
创建一个聚合模型表,使用固定范围分区描述
CREATE TABLE table_range ( k1 DATE, k2 INT, k3 SMALLINT, v1 VARCHAR(2048) REPLACE, v2 INT SUM DEFAULT "1" ) AGGREGATE KEY(k1, k2, k3) PARTITION BY RANGE (k1, k2, k3) ( PARTITION p1 VALUES [("2014-01-01", "10", "200"), ("2014-01-01", "20", "300")), PARTITION p2 VALUES [("2014-06-01", "100", "200"), ("2014-07-01", "100", "300")) ) DISTRIBUTED BY HASH(k2) BUCKETS 32 -
创建一个包含 HLL 和 BITMAP 列类型的聚合模型表
CREATE TABLE example_db.example_table ( k1 TINYINT, k2 DECIMAL(10, 2) DEFAULT "10.5", v1 HLL HLL_UNION, v2 BITMAP BITMAP_UNION ) ENGINE=olap AGGREGATE KEY(k1, k2) DISTRIBUTED BY HASH(k1) BUCKETS 32 -
创建两张同一个 Colocation Group 自维护的表。
CREATE TABLE t1 ( id int(11) COMMENT "", value varchar(8) COMMENT "" ) DUPLICATE KEY(id) DISTRIBUTED BY HASH(id) BUCKETS 10 PROPERTIES ( "colocate_with" = "group1" ); CREATE TABLE t2 ( id int(11) COMMENT "", value1 varchar(8) COMMENT "", value2 varchar(8) COMMENT "" ) DUPLICATE KEY(`id`) DISTRIBUTED BY HASH(`id`) BUCKETS 10 PROPERTIES ( "colocate_with" = "group1" ); -
创建一个带有倒排索引以及 bloom filter 索引的表
CREATE TABLE example_db.table_hash ( k1 TINYINT, k2 DECIMAL(10, 2) DEFAULT "10.5", v1 CHAR(10) REPLACE, v2 INT SUM, INDEX k1_idx (k1) USING INVERTED COMMENT 'my first index' ) AGGREGATE KEY(k1, k2) DISTRIBUTED BY HASH(k1) BUCKETS 32 PROPERTIES ( "bloom_filter_columns" = "k2" ); -
创建一个动态分区表。
该表每天提前创建3天的分区,并删除3天前的分区。例如今天为
2020-01-08,则会创建分区名为p20200108,p20200109,p20200110,p20200111的分区. 分区范围分别为:[types: [DATE]; keys: [2020-01-08]; ‥types: [DATE]; keys: [2020-01-09]; ) [types: [DATE]; keys: [2020-01-09]; ‥types: [DATE]; keys: [2020-01-10]; ) [types: [DATE]; keys: [2020-01-10]; ‥types: [DATE]; keys: [2020-01-11]; ) [types: [DATE]; keys: [2020-01-11]; ‥types: [DATE]; keys: [2020-01-12]; )CREATE TABLE example_db.dynamic_partition ( k1 DATE, k2 INT, k3 SMALLINT, v1 VARCHAR(2048), v2 DATETIME DEFAULT "2014-02-04 15:36:00" ) DUPLICATE KEY(k1, k2, k3) PARTITION BY RANGE (k1) () DISTRIBUTED BY HASH(k2) BUCKETS 32 PROPERTIES( "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-3", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "32" ); -
创建一个带有物化视图(ROLLUP)的表。
CREATE TABLE example_db.rolup_index_table ( event_day DATE, siteid INT DEFAULT '10', citycode SMALLINT, username VARCHAR(32) DEFAULT '', pv BIGINT SUM DEFAULT '0' ) AGGREGATE KEY(event_day, siteid, citycode, username) DISTRIBUTED BY HASH(siteid) BUCKETS 10 ROLLUP ( r1(event_day,siteid), r2(event_day,citycode), r3(event_day) ) PROPERTIES("replication_num" = "3"); -
通过
replication_allocation属性设置表的副本。CREATE TABLE example_db.table_hash ( k1 TINYINT, k2 DECIMAL(10, 2) DEFAULT "10.5" ) DISTRIBUTED BY HASH(k1) BUCKETS 32 PROPERTIES ( "replication_allocation"="tag.location.group_a:1, tag.location.group_b:2" );CREATE TABLE example_db.dynamic_partition ( k1 DATE, k2 INT, k3 SMALLINT, v1 VARCHAR(2048), v2 DATETIME DEFAULT "2014-02-04 15:36:00" ) PARTITION BY RANGE (k1) () DISTRIBUTED BY HASH(k2) BUCKETS 32 PROPERTIES( "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-3", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "32", "dynamic_partition.replication_allocation" = "tag.location.group_a:3" ); -
通过
storage_policy属性设置表的冷热分层数据迁移策略CREATE TABLE IF NOT EXISTS create_table_use_created_policy ( k1 BIGINT, k2 LARGEINT, v1 VARCHAR(2048) ) UNIQUE KEY(k1) DISTRIBUTED BY HASH (k1) BUCKETS 3 PROPERTIES( "storage_policy" = "test_create_table_use_policy", "replication_num" = "1" );注:需要先创建s3 resource 和 storage policy,表才能关联迁移策略成功
-
为表的分区添加冷热分层数据迁移策略
CREATE TABLE create_table_partion_use_created_policy ( k1 DATE, k2 INT, V1 VARCHAR(2048) REPLACE ) PARTITION BY RANGE (k1) ( PARTITION p1 VALUES LESS THAN ("2022-01-01") ("storage_policy" = "test_create_table_partition_use_policy_1" ,"replication_num"="1"), PARTITION p2 VALUES LESS THAN ("2022-02-01") ("storage_policy" = "test_create_table_partition_use_policy_2" ,"replication_num"="1") ) DISTRIBUTED BY HASH(k2) BUCKETS 1;注:需要先创建s3 resource 和 storage policy,表才能关联迁移策略成功
-
批量创建分区
CREATE TABLE create_table_multi_partion_date ( k1 DATE, k2 INT, V1 VARCHAR(20) ) PARTITION BY RANGE (k1) ( FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR, FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH, FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK, FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY, PARTITION p_20230114 VALUES [('2023-01-14'), ('2023-01-15')) ) DISTRIBUTED BY HASH(k2) BUCKETS 1 PROPERTIES( "replication_num" = "1" );CREATE TABLE create_table_multi_partion_date_hour ( k1 DATETIME, k2 INT, V1 VARCHAR(20) ) PARTITION BY RANGE (k1) ( FROM ("2023-01-03 12") TO ("2023-01-14 22") INTERVAL 1 HOUR ) DISTRIBUTED BY HASH(k2) BUCKETS 1 PROPERTIES( "replication_num" = "1" );CREATE TABLE create_table_multi_partion_integer ( k1 BIGINT, k2 INT, V1 VARCHAR(20) ) PARTITION BY RANGE (k1) ( FROM (1) TO (100) INTERVAL 10 ) DISTRIBUTED BY HASH(k2) BUCKETS 1 PROPERTIES( "replication_num" = "1" );
注:批量创建分区可以和常规手动创建分区混用,使用时需要限制分区列只能有一个,批量创建分区实际创建默认最大数量为4096,这个参数可以在fe配置项 max_multi_partition_num 调整
-
批量无排序列Duplicate表
CREATE TABLE example_db.table_hash ( k1 DATE, k2 DECIMAL(10, 2) DEFAULT "10.5", k3 CHAR(10) COMMENT "string column", k4 INT NOT NULL DEFAULT "1" COMMENT "int column" ) COMMENT "duplicate without keys" PARTITION BY RANGE(k1) ( PARTITION p1 VALUES LESS THAN ("2020-02-01"), PARTITION p2 VALUES LESS THAN ("2020-03-01"), PARTITION p3 VALUES LESS THAN ("2020-04-01") ) DISTRIBUTED BY HASH(k1) BUCKETS 32 PROPERTIES ( "replication_num" = "1", "enable_duplicate_without_keys_by_default" = "true" );















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









