









场景
最近在工作中经常使用到gpu资源,传统环境下我们一般在宿主机上部署算法程序,但是这样无法形成快速交付,并且维护成本会非常高。所以nvidia其实也考虑到这一点 通过docker调用宿主机的gpu资源。一般情况下我们需要部署gpu-container-runtime或者nvidia-docker去调用宿主机的gpu资源。那么既然docker可以使用gpu资源,我们是不是可以在kubernetes环境去使用gpu资源呢?答案是肯定的,接下来我这边会分享在kubernetes如何使用device plugin实现调度gpu资源。
设计
其实在kubernetes1.11版本之前社区给出的解决方案是加入了alpha.kubernetes.io/nvidia-gpu去使用gpu资源但是这个特性在1.11版本之后就已经下线了。取而代之的是通过Extended Resource+ Device Plugin两个Kubernetes的内置模块,外加由设备提供商实现的相应Device Plugin, 完成从设备的集群级别调度至工作节点,到设备与容器的实际绑定。
首先思考的第一个问题是为什么进入alpha.kubernetes.io/nvidia-gpu主干一年之久的GPU功能彻底移除?
-
Kubernetes有一个核心理念:OutOfTree是一个很好的理念,简单来讲就是专注于自身核心和通用能力 将像GPU,InfiniBand,FPGA和公共云能力的工作完全交给社区和领域专家。这样一方面可以降低软件自身使用的复杂度,减小稳定性风险,另外OutOfTree分开迭代也能够更灵活实现的功能升级。
Device Plugin的设计:
实际上Device plugins实际上是简单的grpc server,需要实现以下两个方法 ListAndWatch和Allocate,并监听在/var/lib/kubelet/device-plugins/目录下的Unix Socket,比如/var/lib/kubelet/device-plugins/nvidia.sock。
type DevicePluginServer interface {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
GetDevicePluginOptions(context.Context, *Empty) (*DevicePluginOptions, error)
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disapears, ListAndWatch
// returns the new list
ListAndWatch(*Empty, DevicePlugin_ListAndWatchServer) error
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
Allocate(context.Context, *AllocateRequest) (*AllocateResponse, error)
// PreStartContainer is called, if indicated by Device Plugin during
// registeration phase,
// before each container start. Device plugin can run device specific
// operations
// such as reseting the device before making devices available to the container
PreStartContainer(context.Context, *PreStartContainerRequest) (*PreStartContainerResponse, error)
}其中:
- ListAndWatch: Kubelet会调用该API做设备发现和状态更新(比如设备变得不健康)
- Allocate: 当Kubelet创建要使用该设备的容器时, Kubelet会调用该API执行设备相应的操作并且通知Kubelet初始化容器所需的device,volume和环境变量的配置。
ListAndWatch函数(register 时候会调用一次,而且仅仅就这一次,因为 ListAndWatch 是个 GRPC 长连接,DP 可以通过这个长连接不停的反馈。):
func (m *NvidiaDevicePlugin) ListAndWatch(e *pluginapi.Empty, s pluginapi.DevicePlugin_ListAndWatchServer) error {
s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
for {
select {
case <-m.stop:
return nil
case d := <-m.health:
// FIXME: there is no way to recover from the Unhealthy state.
d.Health = pluginapi.Unhealthy
s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
}
}
}简阅Allocate函数主要的作用是分配相应的device资源:
// Allocate which return list of devices.
func (m *NvidiaDevicePlugin) Allocate(ctx context.Context,
reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
responses := pluginapi.AllocateResponse{}
log.Infoln("----Allocating GPU for gpu mem is started----")
var (
podReqGPU uint
found bool
assumePod *v1.Pod
)
// podReqGPU = uint(0)
for _, req := range reqs.ContainerRequests {
podReqGPU += uint(len(req.DevicesIDs))
}
log.Infof("RequestPodGPUs: %d", podReqGPU)
........类似阿里云的gpu share基本在这里加入了很多自定义逻辑实现了多卡gpu调度
大致的逻辑就是通过Annotations 标签选择合适的gpu device。这里就不详细说明了 感兴趣的同学可以去看下源码。
之后我们来看下device plugin 工作流程
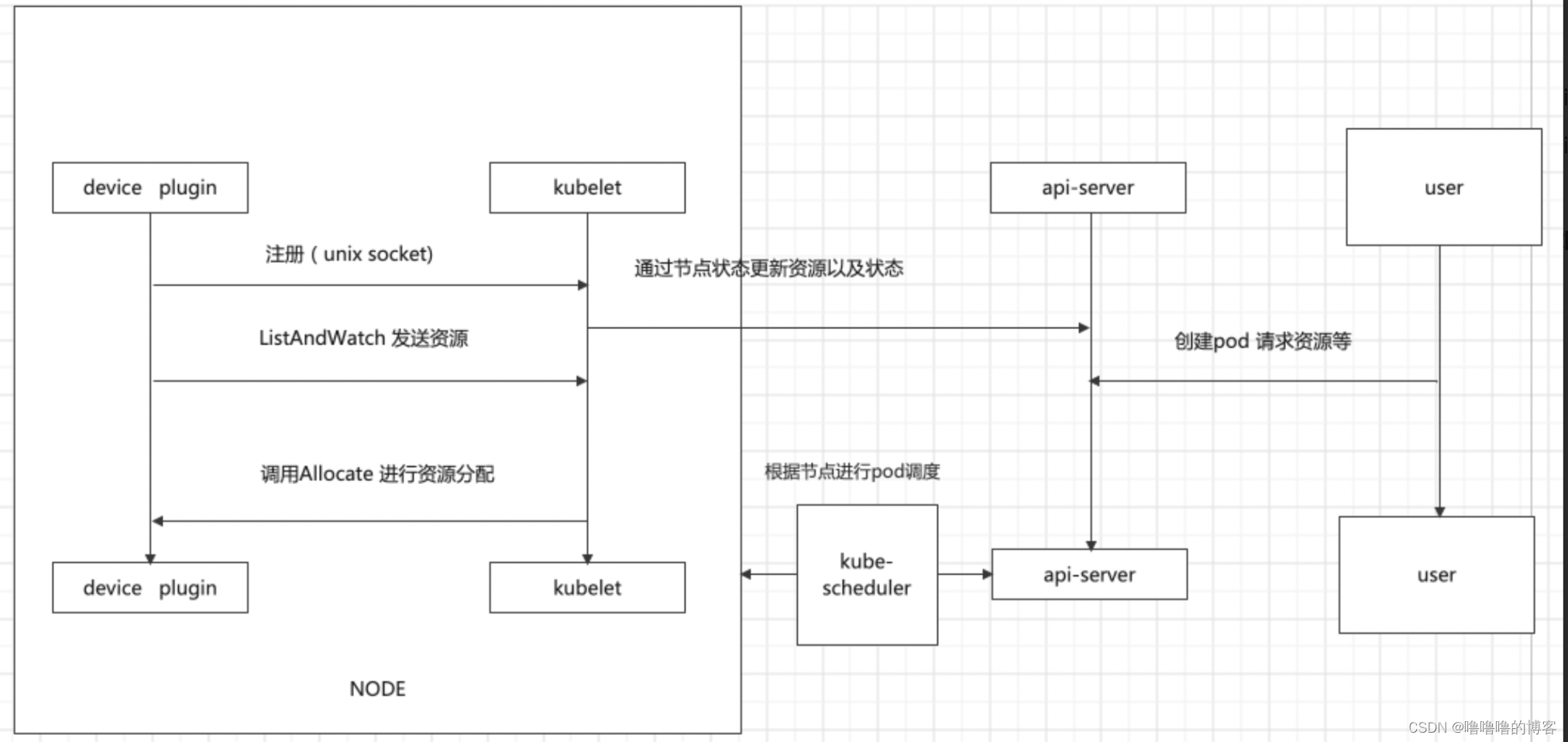
shareGPUManager ---run()---> NvidiaDevicePlugin ----Serve()----> Start GRPC server and Register那么整个Kubernetes调度GPU的过程如下:
1. GPU Device plugin 部署到GPU节点上,通过 ListAndWatch 接口,上报注册节点的GPU信息和对应的DeviceID。
2. 当有声明 nvidia.com/gpu 的GPU Pod创建出现,调度器会综合考虑GPU设备的空闲情况,将Pod调度到有充足GPU设备的节点上。
3. 节点上的kubelet 启动Pod时,根据request中的声明调用各个Device plugin 的 allocate接口, 由于容器声明了GPU。 kubelet 根据之前 ListAndWatch 接口收到的Device信息,选取合适的设备,DeviceID 作为参数,调用GPU DevicePlugin的 Allocate 接口,GPU DevicePlugin ,接收到调用,将DeviceID 转换为 NVIDIA_VISIBLE_DEVICES 环境变量,返回kubelet
4. kubelet将环境变量注入到Pod, 启动容器容器启动时, gpu-container-runtime 调用 gpu-containers-runtime-hookgpu-containers-runtime-hook 根据容器的 NVIDIA_VISIBLE_DEVICES 环境变量,转换为 --devices 参数,调用 nvidia-container-cli prestart,nvidia-container-cli 根据 --devices ,将GPU设备映射到容器中。 并且将宿主机的Nvidia Driver Lib 的so文件也映射到容器中。 此时容器可以通过这些so文件,调用宿主机的Nvidia Driver。
整体架构图:
总结
Kubernetes的生态地位已经确立,可扩展性将是其发力的主战场。异构计算作为非常重要的新战场,Kubernetes非常重视。而异构计算需要强大的计算力和高性能网络,需要提供一种统一的方式与GPU、FPGA、NIC、InfiniBand等高性能硬件集成。这也就是为什么淘汰了alpha.kubernetes.io/nvidia-gpu改用了Extended Resource+ Device Plugin的原因。
当然在我司也修改了部分逻辑,我们没有沿用gpu plugin默认device规则,我们在device的基础上新增了逻辑device的概念在逻辑层限制了每个应用可以申请的gpu显存。当然没办法硬性隔离,这部分目前需要依赖device底层实现。















 6579
6579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









