









本文主要简单的介绍了zookeeper的相关操作,比如zookeeper基本操作,分布式锁实现,leader选举机制,有错误的地方,欢迎大家指正。
文章目录
一、zookeeper 概述:
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是常见的Hadopp和Hbase框架的重要组件。ZooKeeper提供了一系列的功能,比如:数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
二、zookeeper 数据结构:
ZooKeeper的数据结构很类似一个标准的linux文件系统。它文件路劲为:/+节点名称。比如:/zookeeper

三、CAP理论:
一个分布式系统应该基于以下三点来设计,但是只能同时满足其中的两点:
- 一致性(Consistency):一个分布式系统应该在多个副本上保持数据一致。也就是说,无论客户端访问哪个副本,得到的数据应该是一致的。一致性分为强一致性、弱一致性、最终一致性,而zookeeper在数据一致性上选择的是最终一致性。
- 可用性(Availability):保证客户端的每一次请求都得到响应,并且拿到数据,但是不保证每次拿到的数据都是最新的。
- 分区容错性(Partition tolerance):分布式系统中部分系统出现网络出现故障时,也要能保障剩余的服务对外提供正常的一致性服务,除非整个网络故障,或者整个集群崩溃。
对于分布式系统来说,P是必须的,所以只能是保证CP或者AP,zookeeper保证的是CP。
四、session原理
客户端和服务端基于TCP协议进行长连接,客户端默认连接服务端的2181端口,也就是session会话。从第一次连接开始,session生命周期就开始,服务端开始维护这个session会话。
1、session的创建:
-
sessionID:session的每一次创建都会产生一个sessionID,用来唯一标示这个session会话。
-
Timeout:客户端在连接服务端的时候可以向服务端传递一个会话超时时间,服务端会根据会话限制确定最终的会话超时时间。
-
TickTime:下次会话超时时间点,默认 2000 毫秒。可在 zoo.cfg 配置文件中配置,便于 server 端对 session 会话实行分桶策略管理。
-
isClosing:该属性标记一个会话是否已经被关闭,当 server 端检测到会话已经超时失效,该会话标记为"已关闭",不再处理该会话的新请求。
2、session的状态:
- connecting:连接中,session 一旦建立,状态就是 connecting 状态,时间很短。
- connected:已连接,连接成功之后的状态。
- closed:已关闭,发生在 session 过期,一般由于网络故障客户端重连失败,服务器宕机或者客户端主动断开。
五、zookeeper 分桶策略管理和会话激活
1、分桶策略:
zookeeper中将session过期时间在某一时间段的session放在同一个集合中,实际上是一个ConcurrentHashMap,key为时间段的最大的session过期时间,当currentTime达到这个最大的session过期时间时,就执行一次会话过期处理任务,然后将这个最大的session过期时间下的所有的会话设置为过期。
2、会话激活
客户端会在过期时间范围内,对服务端发送请求或者ping请求,从而保持会话的有效性。这个过程又称心跳检测。
六、zookeeper 基本命令
- create [-s|-e] /test/test “test” acl:创建test,并设置节点 test 的值为 test 。-s 代表顺序节点, -e 代表临时节点,注意其中 -s 和 -e 可以同时使用的,并且临时节点不能再创建子节点。acl 访问权限相关,默认是 world,相当于全世界都能访问
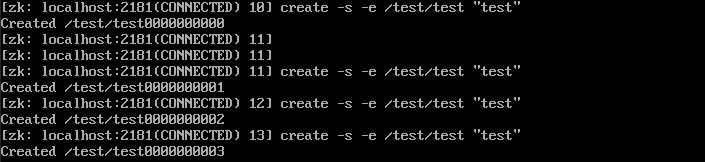
- ls /test:查看目录 test ,查看的是目录下的子目录的信息。

- set /test/test “210221” [version]:设置test目录下的值。version 为数据版本,可选。

- get [-s|-w] /test:获取 test 目录下设置的值。并监听这个目录进行监听。 [-s|-w]参数可选。

- delete /test [version]:删除节点 test ,version 为数据版本,可选。

七、节点特性
节点特性
1、同级节点key唯一:
2、 创建节点时,必须要带上全路径:
3、 session 关闭,临时节点清除:
4、 自动创建顺序节点:
5、 watch 机制,监听节点变化:
6、 delete 命令只能一层一层删除,deleteall 可以做到递归删除:
特别说明节点的字段附带信息含义:
| cZxid | 创建节点时的事务ID |
|---|---|
| ctime | 创建节点时的时间 |
| mZxid | 最后修改节点时的事务ID |
| mtime | 最后修改节点时的时间 |
| pZxid | 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID**(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid)** |
| cversion | 子节点版本号,子节点每次修改版本号加1 |
| dataversion | 数据版本号,数据每次修改该版本号加1 |
| aclversion | 权限版本号,权限每次修改该版本号加1 |
| ephemeralOwner | 创建该临时节点的会话的sessionID。**(**如果该节点是持久节点,那么这个属性值为0) |
| dataLength | 该节点的数据长度 |
| numChildren | 该节点拥有子节点的数量**(只统计直接子节点的数量)** |
Zab协议下 节点有三种状态
- Following:当前节点是跟随者,服从 Leader 节点的命令。
- Leading:当前节点是 Leader,负责协调事务。
- Election/Looking:节点处于选举状态,正在寻找 Leader。
- Observing : Zookeeper 引入 Observer ,Observer 不参与选举,是只读节点,跟 Zab 协议没有关系。
基于以上特性,如下场景可以应运zookeeper
- 数据发布/订阅
- 负载均衡
- 分布式协调/通知
- 集群管理
- master 管理
- 分布式锁
- 分布式队列
八、权限控制 ACL
ACL是zookeeper的权限控制表,ACL可以针对节点设置访问权限,保障数据的安全性。
1、ACL构成:
acl 通过**[scheme🆔permissions]** 来构成权限列表。
- scheme:代表采用的某种权限机制,包括 world、auth、digest、ip、super 几种。
- id:代表允许访问的用户。
- permissions:权限组合字符串,由 cdrwa 组成,其中每个字母代表支持不同权限, 创建权限 create©、删除权限 delete(d)、读权限 read®、写权限 write(w)、管理权限admin(a)。
2、ACL命令:
- getAcl 命令:获取某个节点的 acl 权限信息。

- setAcl 命令:设置某个节点的 acl 权限信息。
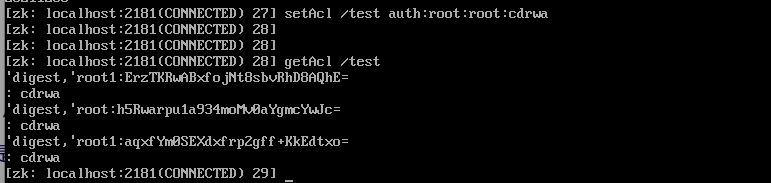
- addauth 命令:输入认证授权信息,注册时输入明文密码,加密形式保存。

九、watcher事件原理
两种方式添加watch:一种在new Zookeeper的时候,默认的watcher,这种watcher是全局性的,另外一种是使用getData等api添加watch。zookeeper下的watch实现是采用观察者模式,客户端维护着一个ZKWatchManager,服务端维护着一个WathcManager。
客户端的watcher会被存放在客户端的ZKWatchManager集合中,服务端接收到请求的时候判断需不需要注册watcher,如果需要注册watcher,又会将watcher事件存放在服务端的WathcManager集合中,当服务端处理完请求的时候,就通知客户端,客户端拿到服务端的请求的时候,通过路径查找这个watcher,然后执行相应的方法。
客户端注册watcher:
以getData为例,客户端通过getData注册的watcher,该watcher暂时被封装到WatchRegistration中,通过path和watcher建立对应关系,并且该请求会被标识成使用watcher监听的请求。后续这个WatchRegistration继续被封装成packet,packet会被添加到队列中,最终客户端和服务端就是通过packet进行传输。
ZooKeeper:
public byte[] getData(String path, Watcher watcher, Stat stat) throws KeeperException, InterruptedException {
PathUtils.validatePath(path);
ZooKeeper.WatchRegistration wcb = null;
if (watcher != null) {
wcb = new ZooKeeper.DataWatchRegistration(watcher, path); // 将watcher事件包装成WatchRegistration
}
…………省略其他代码…………
}
ClientCnxn:
public ClientCnxn.Packet queuePacket(RequestHeader h, ReplyHeader r, Record request, Record response, AsyncCallback cb, String clientPath, String serverPath, Object ctx, WatchRegistration watchRegistration, WatchDeregistration watchDeregistration) {
…………省略其他代码…………
this.outgoingQueue.add(packet); // 客户端最终将请求封装成packet,添加到队列中
…………省略其他代码…………
}
this.sendThread.getClientCnxnSocket().packetAdded();
return packet;
}
客户端通过getData注册的watcher,那么每次都需要重新创建watcher,那么这些watcher并不是直接发送到服务端的,packet的封装并没有将客户端的wacher封装到packet中,只是将header和request封装到了packet中。
ClientCnxn.Packet类:
public void createBB() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
boa.writeInt(-1, "len");
if (this.requestHeader != null) {
this.requestHeader.serialize(boa, "header"); // 封装请求头
}
if (this.request instanceof ConnectRequest) {
this.request.serialize(boa, "connect");
boa.writeBool(this.readOnly, "readOnly");
} else if (this.request != null) {
this.request.serialize(boa, "request"); // 封装请求
}
baos.close();
this.bb = ByteBuffer.wrap(baos.toByteArray());
this.bb.putInt(this.bb.capacity() - 4);
this.bb.rewind();
} catch (IOException var3) {
ClientCnxn.LOG.warn("Ignoring unexpected exception", var3);
}
}
服务端处理watcher:
在STEW的逻辑处理处理中,首先会判断是不是需要注册watcher监听。如果需要,服务端就会将path和对应请求的serverxcnx添加到WathcManager中。
服务端将读取到的请求封装并存储到对列中,等待异步线程处理,对于读请求,将本机数据返回给客户端,对于写请求,就将事务写入本机,并最终调用cnxn.sendResponse将相应结果发送到客户端。
ServerCnxn:
public void sendResponse(ReplyHeader h, Record r, String tag) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive bos = BinaryOutputArchive.getArchive(baos);
try {
baos.write(fourBytes);
bos.writeRecord(h, "header");
if (r != null) {
bos.writeRecord(r, tag);
}
baos.close();
} catch (IOException var8) {
LOG.error("Error serializing response");
}
byte[] b = baos.toByteArray();
this.serverStats().updateClientResponseSize(b.length - 4);
ByteBuffer bb = ByteBuffer.wrap(b);
bb.putInt(b.length - 4).rewind();
this.sendBuffer(bb);
}
客户端读取响应:
客户端通过
客户端最终会调用SendThread线程读取服务端响应结果。拿到响应结果之后,将watcher从结果中获取出来注册到客户端的ZKWatchManager中,并且还会确定事件类型,并将watcher从datawatcher中删除,这就是说明,getData注册的wathcher是一次性的。
SendThread:
void readResponse(ByteBuffer incomingBuffer) throws IOException { // SendThread.readResponse读取服务端的响应
…………省略其他代码…………
} finally {
ClientCnxn.this.finishPacket(packet); // 从所有的watcher事件中分离本次的watcher事件
}
}
}
客户端将watcher分离出来之后,EventThread又会将这些watcher添加到waitingEvents这个队列中,EventThread是一个线程,会不断从waitingEvents对列中获取watcher执行其中的process方法,这个时候,就能执行到我们客户端注册watcher时自定义的process方法了。
ClientCnxn:
public void queuePacket(ClientCnxn.Packet packet) {
if (this.wasKilled) {
synchronized(this.waitingEvents) {
if (this.isRunning) {
this.waitingEvents.add(packet);
} else {
this.processEvent(packet);
}
}
} else {
this.waitingEvents.add(packet); // 客户端继续封装,将服务端的packet添加到waitingEvents这个队列
}
}
EventThread:
private void processEvent(Object event) {
try {
if (event instanceof ClientCnxn.WatcherSetEventPair) {
ClientCnxn.WatcherSetEventPair pair = (ClientCnxn.WatcherSetEventPair)event;
Iterator var3 = pair.watchers.iterator();
while(var3.hasNext()) { // 遍历所有的watcher
Watcher watcher = (Watcher)var3.next();
try {
if (watcher != null && pair.event != null) {
watcher.process(pair.event); // 循环执行每个watcher的process方法,这里实际上执行的就是自定义的process方法。
}
} catch (Throwable var11) {
ClientCnxn.LOG.error("Error while calling watcher ", var11);
}
}
}
十、数据同步原理
1、ZAB协议
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。ZAB协议可以实现的前提ZK集群可以正常对外提供服务。Zookeeper就是根据Za协议来保证数据最终一致性。Zab协议提供两种模式:崩溃恢复和消息广播。当zk集群启动时或者leader服务器出现崩溃时,根据Zab协议,zk集群会进入崩溃恢复模式,选举出新的leader,当选举出新的leader,并且有超过集群一半数量的服务器完成和该leader数据同步的后,zk集群退出崩溃恢复模式,进入消息广播模式,整个zk集群正常对外提供服务。如果此时,加入一台服务器,则这台服务器直接进入崩溃恢复模式,和leader进行数据同步,之后,整个集群正常提供服务。
2、数据同步过程
2.1、崩溃恢复—数据恢复
Zab协议的消息广播是原子性的,在一般情况下是不会有任何问题的,但是一旦leader出现崩溃的情况或者leader和超过集群数量一半的服务器失去了联系,那么这个leader的存在就没有意义了。此时集群进入崩溃恢复模式,重新选举leader。重新选举leader需要解决以下几个问题:
-
已经处理的消息不能被丢失。
如果leader接收到客户端请求生成了proposal并发送给了其他follower节点后,在发送commit命令之后,突然就崩溃了,而此时,follower1节点刚好处理完了commit请求,follower2节点还没处理完commit请求。这种情况下,这条消息是不能丢弃的,那么Zab协议就必须保证选举出zxid最大的一个节点为leader,也就是follower1节点,从而保证整个集群在恢复后能从follower1节点恢复数据。
-
已经丢弃的消息不能再次出现。
如果leader接收到客户端请求生成了proposal之后就崩溃了,因为其他的节点没有接受到请求,那么在重新选举leader之后,这条消息是被跳过的。而原leader节点恢复后注册成了follower节点,但是发现自己的状态和整个集群的状态不一致,那么此时它需要删除。
2.2、消息广播—原子广播
消息广播实际上是一个简化版的2PC的过程:
(1)leader接收到客户端请求后,将请求转化成一个事务 proposal 提议并先持久化在自己的服务器上,并且分配一个64位的自增的全局唯一的id,叫做zxid。
(2)因为leader和每个follower之间都维护着一个FIFO的队列。leader将proposal处理完后,就会将proposal发送到各个follower节点上。
(3)follower节点接收到proposal后,会以事物的方式进行持久化,成功之后,会向leader发送一个响应,也就是ack。
(4)当leader接收到超过集群数量一半的follower的ack之后,就认为这个消息已经处理完成。此时,leader就可以发送commit命令。
(5)leader向所有的follower节点发送commit命令,同时自身也进行事物提交,即将此次消息写入内存,并向发起响应。
这里可以看出,leader在接收到半数以上的ack之后就会发送commit 命令,之后,不再关注follower节点是不是commit事物成功,从而得出,zk保证的是数据最终一致性。
十一、Leader选举机制
选举条件:
3.1、zxid最新的选择leader,事物id,自增,处理 proposal的时候生成。
一个 zxid 是64位,高 32 是纪元(epoch)编号,每经过一次 leader 选举产生一个新的 leader,新 leader 会将 epoch 号 +1。低 32 位是消息计数器,每接收到一条消息这个值 +1,新 leader 选举后这个值重置为 0。
3.2、myid大的选择leader。
注意:3台机器的集群中,如果先启动的两台机器已经完成了选举工作,那么第三台启动后再不会参与竞争选举,即使它的myid是更大的或者zxid最新,而是会将zxid同步成leader的zxid,源码位置:Follower.java(followLeader())。
总结:
- 新选举出来的 Leader 不能包含未提交的 Proposal 。
- 新选举的 Leader 节点中含有最大的 zxid。
十二、2PC
4.1、预提交:leader本地自己先持久化数据,并将请求发送给所有的follower,其他的follower收到命令后,也进行持久化,成功后,向leader响应一个ack。如果这一步发送的时候,发现无法连接到其他的节点,那么说明集群服务基本瘫痪,leader会自己shurdown,因为它自存在的已经没有意义了。
4.2、收到回复(源码位置:Leader.java(processAck()):leader接收follower的ack,如果成功的接收到超过半数的ack,那就说明消息处理完成,此时,leader需要再次发送commit命令给所有的follower,告诉所有的follower本次事务可以进行最终的提交了。但是,却不再关注follower是否最终提交成功。
- 过半机制: 3台机器的集群中,如果两台成功的回复了ack,当然也包含leader自身的ack,那么leader就认为请求已经处理OK。源码位置QuorumMaj.java(containsQuorum())
4.3、提交/回滚:follower收到commit命令后,对本次事务进行最终的提交,也就是将数据写入内存。但是ZK中没有回滚机制。
- 同步机制:所有的zk服务器,都应该以leader服务器的状态和数据为准。
十三、Zookeeper 集群 处理请求的过程
5.1、当一个服zk服务器leader接收到写请求时:
(1)leader接收到客户端请求后,将请求转化成一个事务 proposal 提议并先持久化在自己的服务器上,并且分配一个64位的自增的全局唯一的id,叫做zxid。
(2)因为leader和每个follower之间都维护着一个FIFO的队列。leader将proposal处理完后,就会将proposal发送到各个follower节点上。
(3)follower节点接收到proposal后,会以事物的方式进行持久化,成功之后,会向leader发送一个响应,也就是ack。
(4)当leader接收到超过集群数量一半的follower的ack之后,就认为这个消息已经处理完成。此时,leader就可以发送commit命令。
(5)leader向所有的follower节点发送commit命令,同时自身也进行事物提交,即将此次消息写入内存,并向发起响应。
5.2、当一个zk服务器中的follower接收到写请求时:
(1)follower会将请求直接发送给leader,因为follower没有写请求的权限。之后的处理流程和5.1一样。
5.3、zk服务器中的observe接收到写请求时:执行5.2的流程。
十四、Zookeeper 分布式锁实现原理
分布式锁的总结:分布式锁就是将多个进程间并行的操作转化成串行的操作。Zookeeper能实现分布式锁有一下三主要因素::
1、create -s -e /locks/lock:
2、规定序号最小的获取锁。每个节点都去监听比自己小的节点的,挡比自己小的节点消失时,判断自身是不是变成了最小的节点,如果是,那么就获取锁。
Zookeeper API实现分布式锁:
/**
* 用来获取客户端链接
*/
public class ZKApiClient {
/**
* 定义临时有序节点的父节点
*/
private static final String locks = "/api_lock";
/**
* 获取客户端链接
*
* @return 客户端链接实例
*/
public static ZooKeeper getZk() throws IOException, InterruptedException, KeeperException {
ZooKeeper zk = new ZooKeeper("192.168.93.227:2181", 20000, watchedEvent -> {
});
/**
* 直到客户端链接成功之后才去创建父节点
*/
while (!zk.getState().isConnected()) {
/**
* 如果父节点没有创建,则去创建
*/
if (zk.getState().isConnected()) {
Stat stat = zk.exists(locks, false);
if (stat == null) {
zk.create(locks, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
}
return zk;
}
}
public class ZKApiLock {
/**
* 存放线程实例
*/
private static final ThreadLocal<String> threadLocal = new ThreadLocal<>();
/**
* 模拟库存,库存增减必须保证原子性
*/
private static final AtomicInteger count = new AtomicInteger(2);
/**
* 定义临时有序节点的父节点
*/
private static final String locks = "/lock";
/**
* 主方法入口
*
* @param args 参数
*/
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(5);
/**
* 定义5个线程,模拟客户端去对库存进行竞争操作。
*/
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
process(ZKApiClient.getZk());
} catch (IOException | InterruptedException | KeeperException e) {
e.printStackTrace();
}
}, "thread" + i).start();
countDownLatch.countDown();
}
}
/**
* 尝试加锁
*
* @param zk 客户端链接
* @return 是否加锁成功
*/
private static boolean tryLock(ZooKeeper zk) throws KeeperException, InterruptedException {
try {
/**
* 支付的时候,必须保证线程安全。
*/
if (lock(zk)) {
System.out.println(Thread.currentThread().getName() + "-" + threadLocal.get() + "获取到了锁");
pay();
return true;
}
} finally {
unlock(zk);
}
return false;
}
/**
* 加锁逻辑
*
* @param zk
* @return 是否加锁成功
*/
private static boolean lock(ZooKeeper zk) {
try {
/**
* 每个线程先去创建属于自己的临时顺序节点
*/
String selfNode = zk
.create(locks + "/", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
/**
* 保存线程自己创建的临时节点
*/
threadLocal.set(selfNode);
/**
* 休眠一会,保证拿到了所有的线程创建的临时顺序节点
*/
Thread.sleep(4);
/**
* 查询所有的节点信息
*/
List<String> children = zk.getChildren(locks, false);
/**
* 对节点信息进行排序,排序号,第一个节点就是序号最小的
*/
Collections.sort(children);
System.out.println(Thread.currentThread().getName() + "创建节点为" + selfNode + ":所有的节点信息为" + children);
String s = children.get(0);
/**
* 如果自己创建的临时顺序节点就是最小的那个节点,便获得锁
*/
if (threadLocal.get().equals(locks + "/" + s)) {
return true;
}
NumberFormat formatter = NumberFormat.getNumberInstance();
formatter.setMinimumIntegerDigits(10);
formatter.setGroupingUsed(false);
int index = threadLocal.get().indexOf("/", 2) + 1;
String self = threadLocal.get().substring(index, 16);
/**
* 如果自己创建的临时顺序节点不是最小的那个节点,便获取比他自己小1的那个节点,
* 并监听那个节点的变化。
*/
String prvNode = formatter.format(Integer.parseInt(self) - 1);
final CountDownLatch countDownLatch = new CountDownLatch(1);
/**
* 监听比他自己小1那个节点的变化,当那个节点别删除的时候,比他自己小1那个节点
* 就会通知他继续竞争锁。
*/
Stat exists = zk.exists(locks + "/" + prvNode, watchedEvent -> {
if (Watcher.Event.EventType.NodeDeleted.equals(watchedEvent.getType())) {
System.out.println(
"前一个节点 " + prvNode + " 被删除了 -" + Thread.currentThread().getName() + "被唤醒!唤醒节点信息为:" + self);
countDownLatch.countDown();
}
});
/**
* 如果存在比他自己小1那个节点,就等待那个节点被删除时通知他继续竞争锁。
*/
if (exists != null) {
System.out.println(Thread.currentThread().getName() + "-" + threadLocal.get() + "等待锁!开始监听" + prvNode + "节点变化");
countDownLatch.await();
}
} catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
return true;
}
/**
* 解锁逻辑。删除自己创建的那个节点信息,删除自己创建的链接
*
* @param zk
*/
private static void unlock(ZooKeeper zk) throws InterruptedException, KeeperException {
zk.delete(String.valueOf(threadLocal.get()), -1);
zk.close();
}
/**
* 逻辑入口
*
* @param zk 客户端链接
*/
static void process(ZooKeeper zk) {
try {
/**
* 5个线程可以在不保证线程安全的情况下,去查询库存,
* 有点类似抢票的时候,明明看到有余票,但是下单支付的时候,却提示无余票,支付失败。
*/
System.out.println(Thread.currentThread().getName() + "查询库存:" + getInventory());
tryLock(zk);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取当前剩余库存
*
* @return 剩余库存
*/
private static int getInventory() {
return count.get();
}
/**
* 订单支付
*/
private static void pay() {
/**
* 支付的时候,再次判断下是否还有余票。无余票则支付失败。
*/
if (getInventory() == 0) {
System.out.println(Thread.currentThread().getName() + "库存为0,支付失败.");
return;
}
System.out.println(Thread.currentThread().getName() + "库存为," + count + "支付成功");
/**
* 支付成功后,库存减1
*/
count.decrementAndGet();
}
}
Zookeeper Curator框架实现分布式锁:
/**
* 用来获取客户端链接
*/
public class ZKCuratorClient {
private static final String CONNECT_STRING = "192.168.93.227:2181";
/**
* 获取客户端链接
*
* @return 客户端链接实例
*/
public static CuratorFramework getZk() {
CuratorFramework client = CuratorFrameworkFactory.builder().connectString(CONNECT_STRING)
.sessionTimeoutMs(100 * 1000)
.retryPolicy(new RetryNTimes(10, 2 * 1000))
.build();
client.start();
return client;
}
}
public class ZKCuratorLock {
/**
* 定义临时有序节点的父节点
*/
private static final String LOCK_PATH = "/curator_lock";
/**
* 模拟库存,库存增减必须保证原子性
*/
private static final AtomicInteger count = new AtomicInteger(2);
/**
* 主方法入口
*
* @param args 参数
*/
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(5);
/**
* 定义5个线程,模拟客户端去对库存进行竞争操作。
*/
for (int i = 0; i < 5; i++) {
new Thread(() -> process(ZKCuratorClient.getZk()), "thread" + i).start();
countDownLatch.countDown();
}
}
/**
* 逻辑入口
*
* @param client 客户端链接
*/
private static void process(CuratorFramework client) {
/**
* 5个线程可以在不保证线程安全的情况下,去查询库存,
* 有点类似抢票的时候,明明看到有余票,但是下单支付的时候,却提示无余票,支付失败。
*/
System.out.println(Thread.currentThread().getName() + "查询库存:" + getInventory());
tryLock(client);
}
/**
* 获取当前剩余库存
*
* @return 剩余库存
*/
private static int getInventory() {
return count.get();
}
/**
* 订单支付
*/
private static void pay() {
/**
* 支付的时候,再次判断下是否还有余票。无余票则支付失败。
*/
if (getInventory() <= 0) {
System.out.println(Thread.currentThread().getName() + "库存为0,支付失败.");
return;
}
System.out.println(Thread.currentThread().getName() + "库存为," + count + "支付成功");
/**
* 支付成功后,库存减1
*/
count.decrementAndGet();
}
private static boolean tryLock(CuratorFramework client) {
try {
return lock(client);
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
private static boolean lock(CuratorFramework client) throws Exception {
InterProcessLock processLock = new InterProcessMutex(client, LOCK_PATH);
try {
if (processLock.acquire(10 * 1000, TimeUnit.SECONDS)) {
pay();
return true;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
unlock(processLock);
}
return false;
}
private static void unlock(InterProcessLock processLock) throws Exception {
processLock.release();
}
}
总结
本文主要是针对zookeeper做了一些简单的学籍总结,适合初学者参考。
















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











