







结构图:

实现的效果,请求资源,返回html页面:


以下是代码结构:

实现了对请求处理,读取输入流,并按照http格式进行解析,获取请求方法行、请求头、请求体的解析,解析完后进行对应方法分析,并按照请求资源返回。通过设置respose对象返回内容,包括相应状态码、响应头、响应体。在网络监听的时候利用线程池进行处理,提高服务的并行度。
具体代码实现如下:
1、监听网络请求
package com.webserver.core;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* WebServer主类
* @author ta
*
*/
public class WebServer {
private ServerSocket server;
private ExecutorService threadPool;
public WebServer() {
try {
System.out.println("正在启动服务端...");
//新建一个socket进行监听网络请求
server = new ServerSocket(8089);
//创建一个线程池提高并发度
threadPool = Executors.newFixedThreadPool(8);
System.out.println("服务端启动完毕!");
} catch (Exception e) {
e.printStackTrace();
}
}
public void start() {
try {
while(true) {
System.out.println("等待客户端连接...");
//socket监听请求
Socket socket = server.accept();
//接收到一个请求后,将socket传到ClientHandler中进行处理
System.out.println("一个客户端连接了!");
ClientHandler handler
= new ClientHandler(socket);
//放到线程池中
threadPool.execute(handler);
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
WebServer server = new WebServer();
server.start();
}
}
2、对网络请求进行处理
package com.webserver.core;
import java.io.File;
import java.io.IOException;
import java.net.Socket;
import com.webserver.exception.EmptyRequestException;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
import com.webserver.servlet.HttpServlet;
import com.webserver.servlet.RegServlet;
/**
* 客户端处理器,负责处理与客户端的交互工作
* @author ta
*
*/
public class ClientHandler implements Runnable{
private Socket socket;
public ClientHandler(Socket socket) {
this.socket = socket;
}
public void run() {
try {
//1解析请求
HttpRequest request = new HttpRequest(socket);
HttpResponse response = new HttpResponse(socket);
//2处理请求
//2.1:根据request获取资源的抽象路径
String path = request.getRequestURI();
//2.2:根据请求路径判断是否为请求一个业务操作
HttpServlet servlet
= ServerContext.getServlet(path);
if(servlet!=null) {
servlet.service(request, response);
}else {
//2.3:根据该抽象路径从webapps下寻找该资源
File file = new File("./webapps"+path);
if(file.exists()) {
System.out.println("该资源已找到!");
//发送一个标准的HTTP响应给客户端回应该资源
//将响应的资源设置到response中
response.setEntity(file);
}else {
System.out.println("该资源不存在!");
response.setStatusCode(404);
response.setStatusReason("NOT FOUND");
response.setEntity(
new File("./webapps/root/404.html"));
}
}
//3响应客户端
response.flush();
System.out.println("响应完毕!");
} catch(EmptyRequestException e) {
System.out.println("空请求...");
} catch (Exception e) {
e.printStackTrace();
} finally {
/*
* 处理完请求并响应客户端后与其断开连接
*/
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
3、对Servlet的实现支持,通过ServerContext将请求与对应的servlet进行映射。
package com.webserver.core;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import com.webserver.servlet.HttpServlet;
/**
* 服务端相关配置信息
* @author ta
*
*/
public class ServerContext {
/**
* 请求与对应Servlet的关系
* key:请求路径
* value:对应的Servlet实例
*/
private static Map<String,HttpServlet> servletMapping = new HashMap<>();
static {
initServletMapping();
}
private static void initServletMapping() {
// servletMapping.put("/myweb/reg", new RegServlet());
// servletMapping.put("/myweb/login", new LoginServlet());
// servletMapping.put("/myweb/showAllUser", new ShowAllUserServlet());
/*
* 解析conf/servlets.xml文件,将根标签
* 下所有名为<servlet>的子标签得到,然后
* 将每个servlet子标签中的属性path作为key
* 将属性className的值得到后利用反射加载
* 这个类的类对象并进行实例化,将实例化的
* 对象作为value保存到servletMapping这个
* Map中完成初始化。
*/
try {
//读取xml配置文件
SAXReader reader = new SAXReader();
Document doc = reader.read(
new File("./conf/servlets.xml"));
Element root = doc.getRootElement();
List<Element> servlets = root.elements();
for(Element servletEle : servlets) {
String key
= servletEle.attributeValue("path");
//通过反射获取对应的servlet实例对象
String className
= servletEle.attributeValue("className");
Class cls = Class.forName(className);
HttpServlet servlet = (HttpServlet)cls.newInstance();
//放进servletMapping中
servletMapping.put(key, servlet);
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 根据请求获取对应的Servlet
* @param path
* @return
*/
public static HttpServlet getServlet(String path) {
return servletMapping.get(path);
}
}
4、对request的处理
package com.webserver.http;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.Socket;
import java.net.URLDecoder;
import java.util.HashMap;
import java.util.Map;
import com.webserver.exception.EmptyRequestException;
/**
* 请求对象
* 请求对象的每一个实例用于表示客户端(浏览器)发送过来
* 的一个标准HTTP请求内容
*
* 一个请求由三部分构成:请求行,消息头,消息正文
* @author ta
*
*/
public class HttpRequest {
/*
* 请求行相关信息定义
*/
//请求方式
private String method;
//请求的抽象路径部分
private String url;
//请求使用的HTTP协议版本
private String protocol;
/*
* 由于请求行中抽象路径部分因客户端请求方式
* 不同会有不同内容:
* 1:不带参数的抽象路径,如:
* /myweb/index.html
* 2:form表单GET形式提交,抽象路径就带参数,如:
* /myweb/reg?username=xxx&password=xxx&...
*/
//抽象路径中的请求部分。"?"左侧内容
private String requestURI;
//抽象路径中的参数部分。"?"右侧内容
private String queryString;
//保存具体的每一组参数
private Map<String,String> parameters = new HashMap<>();
/*
* 消息头相关信息定义
*/
//key:消息头的名字 value:消息头对应的值
private Map<String,String> headers = new HashMap<>();
/*
* 消息正文相关信息定义
*/
/*
* 与连接相关的属性
*/
private Socket socket;
private InputStream in;
/**
* 构造方法,用来初始化请求对象
* 初始化的过程就是解析请求的过程。
* @throws EmptyRequestException
*/
public HttpRequest(Socket socket) throws EmptyRequestException {
try {
this.socket = socket;
/*
* 通过socket获取输入流,用于读取客户端
* 发送过来的请求内容
*/
this.in = socket.getInputStream();
/*
* 解析请求分为三步
* 1:解析请求行内容
* 2:解析消息头内容
* 3:解析消息正文内容
*/
parseRequestLine();
parseHeaders();
parseContent();
}catch(EmptyRequestException e) {
throw e;
}catch(Exception e) {
e.printStackTrace();
}
}
/**
* 解析请求行
* @throws EmptyRequestException
*/
private void parseRequestLine() throws EmptyRequestException {
System.out.println("开始解析请求行...");
try {
String line = readLine();
//是否为空请求
if("".equals(line)) {
//抛出空请求异常
throw new EmptyRequestException();
}
System.out.println("请求行:"+line);
/*
* 将请求行的内容按照空格拆分为三部分,
* 并分别设置到属性:method,url,protocol上
*/
String[] data = line.split("\\s");
method = data[0];
url = data[1];
protocol = data[2];
//进一步解析抽象路径部分
parseURL();
System.out.println("method:"+method);
System.out.println("url:"+url);
System.out.println("protocol:"+protocol);
} catch(EmptyRequestException e) {
throw e;
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("解析请求行完毕");
}
/**
* 进一步解析请求行中的抽象路径部分
*/
private void parseURL() {
System.out.println("进一步解析抽象路径部分...");
/*
* 在解析url时,首先判断该抽象路径是否
* 含有参数,标志就是有没有"?"。
* 如果没有则说明没有参数,那么直接将当前
* 抽象路径url的值赋值给requestURI即可
*
* 如果有则说明有参数,那么首先按照"?"
* 将抽象路径拆分为两部分,第一部分就是
* 请求部分,赋值给requestURI,第二部分
* 就是参数部分赋值给queryString.
* 然后在对queryString部分进行进一步拆分
* 按照"&"先拆分出每一个参数,然后每个参数
* 再按照"="拆分为参数名与参数值,只有将
* 参数名作为key,参数值作为value保存到
* 属性parameters这个Map中完成解析工作
*/
if(url.indexOf("?")==-1) {
//没有参数
requestURI = url;
}else {
//有参数
String[] data = url.split("\\?");
requestURI = data[0];
//判断"?"右侧确实包含参数部分
if(data.length>1) {
queryString = data[1];
//对queryString解码
try {
/*
* String decode(String str,String enc)
* 将给定的字符串中含有"%XX"的内容按照指定
* 的字符集还原为对应字符串并替换这些"%XX",
* 然后将替换后的字符串返回。
*/
queryString = URLDecoder.decode(queryString, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//拆分每一个参数
parseParameters(queryString);
}
}
System.out.println("requestURI:"+requestURI);
System.out.println("queryString:"+queryString);
System.out.println("parameters:"+parameters);
System.out.println("解析抽象路径部分完毕!");
}
/**
* 解释参数
* 参数的格式应当为:name=value&name=value&...
* @param line
*/
private void parseParameters(String line) {
String[] data = line.split("&");
for(String para : data) {
//每个参数按照"="拆分
String[] arr = para.split("=");
if(arr.length>1) {
parameters.put(arr[0], arr[1]);
}else {
parameters.put(arr[0], null);
}
}
}
/**
* 解析消息头
*/
private void parseHeaders(){
System.out.println("开始解析消息头...");
try {
/*
* 消息头有若干行,因此我们应当循环调用
* readLine方法读取每一个消息头。但是
* 如果调用readLine方法返回值为""(空字
* 符串)时则说明单独读取到了CRLF,此时
* 表示消息头全部解析完毕,应当停止读取
* 工作。
* 每个消息头读取到以后,按照冒号空格(: )
* 进行拆分,并将拆分的第一项作为消息头的
* 名字,第二项作为消息头的值并以key,value
* 形式保存到属性headers这个Map中完成消息
* 头的解析工作
*/
String line = null;
while(!"".equals(line = readLine())) {
String[] data = line.split(": ");
headers.put(data[0], data[1]);
}
System.out.println("headers:" +headers);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("解析消息头完毕");
}
/**
* 解析消息正文
*/
private void parseContent() {
System.out.println("开始解析消息正文...");
/*
* 一个请求是否包含消息正文可以根据这个请求
* 发送过来的消息头中是否包含:
* Content-Length来判定。如果包含这个头
* 就说明是含有正文的,并且指定了正文的长度
*
* Content-Type头是客户端告知服务端消息
* 正文的内容是什么类型的数据。
*
* Content-Type的值若为:
* application/x-www-form-urlencoded
* 则表明该正文是一个字符串,内容是页面表单
* 提交上来的用户输入的内容,格式与GET请求
* 中在url的"?"右侧内容一致。如:
* username=zhangsan&password=123456
*
*
* 1:首先在解析消息正文时先判断本次请求的
* 消息头中是否含有Content-Length
* 如果含有则说明包含消息正文,没有则忽略
* 解析消息正文的工作
* 2:获取消息头Content-Length的值,这是一个
* 数字,用来得知消息正文的长度(字节量)
* 3:通过输入流读取Content-Length指定的字节
* 量将消息正文数据读取出来。
* 4:在获取Content-Type头的值,根据这个值来
* 判定消息正文的数据类型,这里只判断一种:
* application/x-www-form-urlencoded
* 若是上述的值,则说明这个正文内容是页面表单
* 提交上来的用户数据,将其转换为字符串,字符
* 集使用ISO8859-1。
* 5:转换后的字符串就可以进行拆分参数了,将
* 拆分后的参数再次存入parameters这个Map中
*
*/
try {
if(headers.containsKey("Content-Length")) {
int length = Integer.parseInt(
headers.get("Content-Length"));
byte[] data = new byte[length];
//读取所有正文内容的字节
in.read(data);
//获取正文类型
String type = headers.get("Content-Type");
//判断是否为form表单数据
if("application/x-www-form-urlencoded".equals(type)) {
String line = new String(data,"ISO8859-1");
//转码
line = URLDecoder.decode(line,"UTF-8");
//拆分出每一个参数
parseParameters(line);
}
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("解析消息正文完毕");
}
/**
* 通过输入流读取客户端发送过来的一行字符串
* 一行结束的标志为CR,LF
* @return
* @throws IOException
*/
private String readLine() throws IOException {
StringBuilder builder = new StringBuilder();
//c1表示上次读取到的字符,c2表示本次读取到的字符
int c1=-1,c2=-1;
while((c2 = in.read())!=-1) {
//是否连读读取到了CR,LF
if(c1==13&&c2==10) {
break;
}
builder.append((char)c2);
c1 = c2;
}
return builder.toString().trim();
}
public String getMethod() {
return method;
}
public String getUrl() {
return url;
}
public String getProtocol() {
return protocol;
}
/**
* 根据消息头的名字获取消息头对应的值
* @param name
* @return
*/
public String getHeaders(String name) {
/*
* 这里的设计没有直接将headers这个Map对外
* 范围,避免外界拿到这个Map后可以任意操作,
* 这样破坏了当前属性的封装性。
* 实际开发中,很多这种集合,Map的属性都不
* 对外直接返回。
*/
return headers.get(name);
}
public String getRequestURI() {
return requestURI;
}
public String getQueryString() {
return queryString;
}
/**
* 获取指定参数对应的值
* @param name
* @return
*/
public String getParameter(String name) {
return parameters.get(name);
}
}
5、对文件的mime类型的处理
package com.webserver.http;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* HTTP协议相关定义
* @author ta
*
*/
public class HttpContext {
/**
* Content-Type的值与资源后缀名的对应关系
* key:资源后缀名
* value:对应的Content-Type值
*/
private static Map<String,String> mime_mapping = new HashMap<>();
static {
initMimeMapping();
}
/**
* 初始化资源类型
* 读取conf/web.xml中资源类型列表,添加到mime_mapping中
* 可以解决大部分市面上常见文件类型与资源类型的映射关系
*
* 异常处理原则:能处理尽量处理,处理不了抛出去
*/
private static void initMimeMapping() {
try {
SAXReader reader=new SAXReader();
Document doc = reader.read(
new File("conf/web.xml"));
Element root=doc.getRootElement();
List<Element> list=
root.elements("mime-mapping");
for (Element e : list) {
String ext=e.elementTextTrim("extension");
String type=e.elementTextTrim("mime-type");
mime_mapping.put(ext, type);
}
//System.out.println(mime_mapping);
}catch(Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
/**
* 根据资源后缀名获取对应的Content-Type的值
* @param ext
* @return
*/
public static String getMimeType(String ext) {
return mime_mapping.get(ext);
}
public static void main(String[] args) {
String fileName = "header.css";
String ext = fileName.substring(
fileName.lastIndexOf(".")+1);
System.out.println(getMimeType(ext));
}
}
6、对空请求的处理
package com.webserver.exception;
/**
* 空请求异常
* @author ta
*
*/
public class EmptyRequestException extends Exception{
private static final long serialVersionUID = 1L;
public EmptyRequestException() {
super();
// TODO Auto-generated constructor stub
}
public EmptyRequestException(String message, Throwable cause, boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
// TODO Auto-generated constructor stub
}
public EmptyRequestException(String message, Throwable cause) {
super(message, cause);
// TODO Auto-generated constructor stub
}
public EmptyRequestException(String message) {
super(message);
// TODO Auto-generated constructor stub
}
public EmptyRequestException(Throwable cause) {
super(cause);
// TODO Auto-generated constructor stub
}
}
7、对servlet的实现
package com.webserver.servlet;
import java.io.File;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 所有Servlet的超类
* @author ta
*
*/
public abstract class HttpServlet {
/**
* 用于处理请求的方法。ClientHandler在调用
* 某请求对应的处理类(某Servlet)时,会调用
* 其service方法。
* @param request
* @param response
*/
public abstract void service(HttpRequest request,HttpResponse response);
/**
* 跳转到指定页面
* @param path 从webapps之后开始指定路径,
* 如"/myweb/xxx.html"
* @param request
* @param response
*/
public void forward(String path,HttpRequest request,HttpResponse response) {
File file = new File("./webapps"+path);
response.setEntity(file);
}
}
package com.webserver.servlet;
import java.io.File;
import java.io.RandomAccessFile;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理登录业务
* @author ta
*
*/
public class LoginServlet extends HttpServlet{
public void service(HttpRequest request,HttpResponse response) {
System.out.println("LoginServlet:开始处理登录...");
//1获取用户登录信息
String username = request.getParameter("username");
String password = request.getParameter("password");
System.out.println("username:"+username);
System.out.println("password:"+password);
//2验证登录
try (
RandomAccessFile raf
= new RandomAccessFile("user.dat","r");
){
for(int i=0;i<raf.length()/100;i++) {
raf.seek(i*100);
//读取用户名
byte[] data = new byte[32];
raf.read(data);
String name = new String(data,"UTF-8").trim();
if(name.equals(username)) {
raf.read(data);
String pwd = new String(data,"UTF-8").trim();
if(pwd.equals(password)) {
//登录成功
forward("/myweb/login_success.html",request,response);
return;
}
/*
* 只要用户名对了,无论密码是否匹配,都
* 应当停止后续读取工作。因为user.dat
* 文件中不存在重复的用户名,减少没有必要
* 的读取操作,提高性能。
*/
break;
}
}//for循环结束
//登录失败
forward("/myweb/login_fail.html", request, response);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("LoginServlet:处理登录完毕!");
}
}
package com.webserver.servlet;
import java.io.File;
import java.io.RandomAccessFile;
import java.util.Arrays;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 处理用户注册业务
* @author ta
*
*/
public class RegServlet extends HttpServlet {
public void service(HttpRequest request,HttpResponse response) {
System.out.println("RegServlet:开始处理注册...");
//1通过request获取用户的注册信息
String username = request.getParameter("username");
String password = request.getParameter("password");
String nickname = request.getParameter("nickname");
int age = Integer.parseInt(request.getParameter("age"));
System.out.println("username:"+username);
System.out.println("password:"+password);
System.out.println("nickname:"+nickname);
System.out.println("age:"+age);
//2将注册信息写入文件user.dat
try (
RandomAccessFile raf
= new RandomAccessFile("user.dat","rw");
){
/*
* 首先判断user.dat文件中是否已经存在该
* 用户,若存在则响应用户注册提示页面,
* 提示该用户已存在,否则才将该用户信息
* 写入user.dat文件
*
* 注册提示页面:reg_have_user.html
* 提示也中显示一行字,内容为:该用户已存在,请重写注册!
*/
for(int i=0;i<raf.length()/100;i++) {
raf.seek(i*100);
byte[] data = new byte[32];
raf.read(data);
String name = new String(data,"UTF-8").trim();
if(name.equals(username)) {
//该用户已存在
forward("/myweb/reg_have_user.html", request, response);
return;
}
}
//先将指针移动到文件末尾
raf.seek(raf.length());
//写用户名
byte[] data = username.getBytes("UTF-8");
//将字节数组扩容至32字节
data = Arrays.copyOf(data, 32);
//将32字节一次性写入文件
raf.write(data);
//写密码
data = password.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写昵称
data = nickname.getBytes("UTF-8");
data = Arrays.copyOf(data, 32);
raf.write(data);
//写年龄
raf.writeInt(age);
//注册完毕,响应注册成功页面给客户端
forward("/myweb/reg_success.html", request, response);
} catch (Exception e) {
e.printStackTrace();
}
//3设置response响应客户端注册结果
System.out.println("RegServlet:处理注册完毕!");
}
}
package com.webserver.servlet;
import java.io.RandomAccessFile;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.thymeleaf.TemplateEngine;
import org.thymeleaf.context.Context;
import org.thymeleaf.templateresolver.FileTemplateResolver;
import com.webserver.http.HttpRequest;
import com.webserver.http.HttpResponse;
/**
* 展示用户列表
* @author ta
*
*/
public class ShowAllUserServlet extends HttpServlet{
public void service(HttpRequest request, HttpResponse response) {
/*
* 1:读取user.dat文件,将所有用户读取出来
* 其中每个用户用一个Map保存,key保存
* 属性名,value保存该属性的值。
* 再将这些Map实例存入一个List集合备用
*
* 2:利用thymeleaf将List集合的数据绑定到
* showAllUser.html页面上。
* 页面上要对应的添加thymeleaf需要的属性
* 否则thymeleaf不知道如何绑定。
*/
try (
RandomAccessFile raf
= new RandomAccessFile("user.dat","r");
){
List<Map<String,String>> userList = new ArrayList<>();
for(int i=0;i<raf.length()/100;i++) {
byte[] data = new byte[32];
raf.read(data);
String username
= new String(data,"UTF-8").trim();
raf.read(data);
String password = new String(data,"UTF-8").trim();
raf.read(data);
String nickname = new String(data,"UTF-8").trim();
int age = raf.readInt();
//用一个Map保存一个用户信息
Map<String,String> user = new HashMap<>();
user.put("username", username);
user.put("password", password);
user.put("nickname", nickname);
user.put("age", age+"");
//将该用户信息存入list集合
userList.add(user);
}//for循环结束
/*
* thtmeleaf模板引擎,用来将数据绑定到
* 静态页面的核心组件
*/
TemplateEngine eng = new TemplateEngine();
FileTemplateResolver resolver
= new FileTemplateResolver();
//设置字符集,告知引擎静态页面的字符集
resolver.setCharacterEncoding("UTF-8");
//将解析器设置到引擎上,使得引擎知道如何处理静态页面
eng.setTemplateResolver(resolver);
//Context用来存储所有要在页面上显示的数据
Context context = new Context();
//将保存所有用户的list集合存入context
context.setVariable("list", userList);
/*
* 调用引擎的process处理方法,该方法就是将指定
* 的数据与指定的页面进行绑定。
* 参数1:静态页面的路径
* 参数2:需要在静态页面上显示的动态数据
* 该方法返回值为一个字符串,内容就是绑定了动态
* 数据的静态页面所对应的HTML代码
*/
String html = eng.process("./webapps/myweb/showAllUser.html", context);
//将生成的页面设置到response中响应给客户端
response.setContentData(html.getBytes("UTF-8"));
response.putHeader("Content-Type", "text/html");
} catch (Exception e) {
e.printStackTrace();
}
}
}
8、对文件的读写test
package com.webserver.test;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 显示所有员工信息
* @author ta
*
*/
public class ShowAllUserDemo {
public static void main(String[] args) throws IOException {
/*
* 使用RAF读取user.dat文件
* 循环读取该文件,循环次数应当是文件长度/100
* 每条记录读取时:
* 首先读取32字节,这是用户名,将该字节按照
* UTF-8编码转换为字符串,注意,转换后要trim,
* 因为这个字符串含有空白字符。
* 依次类推读取密码,昵称。
* 之后再读取一个int值,这个是年龄。
*
* 输出格式例如:
* 张三,123456,阿三,22
*/
RandomAccessFile raf
= new RandomAccessFile("user.dat","r");
for(int i=0;i<raf.length()/100;i++) {
//读取用户名
byte[] data = new byte[32];
raf.read(data);
String username = new String(data,"UTF-8").trim();
raf.read(data);
String password = new String(data,"UTF-8").trim();
raf.read(data);
String nickname = new String(data,"UTF-8").trim();
int age = raf.readInt();
System.out.println("pos:"+raf.getFilePointer());
System.out.println(username+","+password+","+nickname+","+age);
}
raf.close();
}
}
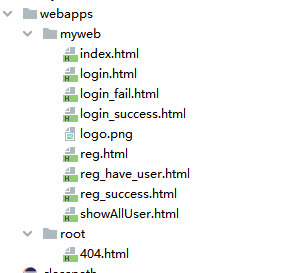
9、资源文件结构
代码链接
















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











