







 本文详细探讨了MySQL中避免使用NULL值的原因,包括对查询性能的影响、存储空间占用和代码可维护性。通过实例展示了NOTIN子查询、空值查询、字段拼接和统计行为的变化,并强调了使用有意义的值替代NULL的重要性。
本文详细探讨了MySQL中避免使用NULL值的原因,包括对查询性能的影响、存储空间占用和代码可维护性。通过实例展示了NOTIN子查询、空值查询、字段拼接和统计行为的变化,并强调了使用有意义的值替代NULL的重要性。
【Mysql】数据库系列
文章目录
前言
在表设计字段时,不推荐使用可空值,推荐使用一个有意义的值去代替NULL,这样有利于代码的可读性和可维护性,并能从约束上增强业务数据的规范性。《高性能mysql》中给出的理由是:
Mysql难以优化引用可空列查询,它会使索引、索引统计和值更加复杂。可空列需要更多的存储空间,还需要mysql内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致MYisam 中固定大小的索引变成可变大小的索引。
下面举例子说明。
一、表和数据准备
创建表:student-01(name可以为NULL)、student-02(name不可以为NULL)
DDL:
-- `student-01` definition
CREATE TABLE `student-01` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键id',
`age` int DEFAULT '0' COMMENT '年龄',
`name` varchar(50) DEFAULT NULL COMMENT '名字',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生表01';
-- `student-02` definition
CREATE TABLE `student-02` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键id',
`age` int DEFAULT '0' COMMENT '年龄',
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '名字',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生表';
数据:
INSERT INTO `student-01` (id, age, name) VALUES(1, 12, '小米1');
INSERT INTO `student-01` (id, age, name) VALUES(2, 23, '小rose1');
INSERT INTO `student-01` (id, age, name) VALUES(3, 12, '小jeck1');
INSERT INTO `student-01` (id, age, name) VALUES(4, 8, '小ming');
INSERT INTO `student-01` (id, age, name) VALUES(5, 11, '');
INSERT INTO `student-01` (id, age, name) VALUES(6, 46, 'NULL1');
INSERT INTO `student-01` (id, age, name) VALUES(7, 14, '小xu');
INSERT INTO `student-01` (id, age, name) VALUES(8, 11, NULL);
INSERT INTO `student-02` (id, age, name) VALUES(1, 12, '小米');
INSERT INTO `student-02` (id, age, name) VALUES(2, 23, '小rose');
INSERT INTO `student-02` (id, age, name) VALUES(3, 12, '小jeck');
INSERT INTO `student-02` (id, age, name) VALUES(4, 8, '');
INSERT INTO `student-02` (id, age, name) VALUES(5, 11, '');
INSERT INTO `student-02` (id, age, name) VALUES(6, 46, '小xiong');
INSERT INTO `student-02` (id, age, name) VALUES(7, 14, '小xu');
二、验证
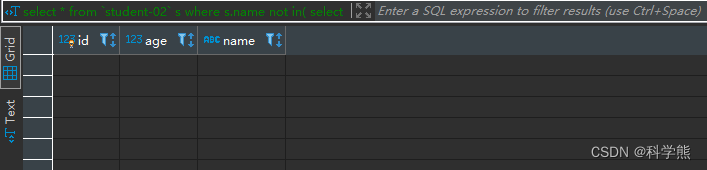
1.NOT IN子查询在有NULL值的情况下返回永远为空结果
查询student-02中名字不存在student-01中的,推测的结果中应该有:小米、小rose、小jeck、小xiong,这几个只存在student-02。
select
*
from
`student-02` s
where
s.name not in(
select
s2.name
from
`student-01` s2 )
运行结果:空,什么多没有。
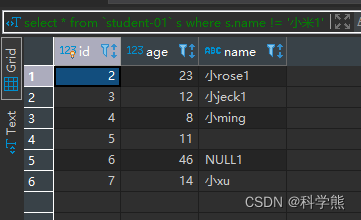
2.使用!=去查询可空值字段时,数据中存在NULL,NULL记录查询不到
查询student-01中名字不等“小米1”的:
select * from `student-01` s where s.name != '小米1'
输出结果:NULL值不包含在其中,id=8的记录没有包含进去。
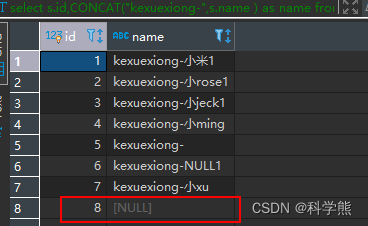
3.如果在两个字段进行拼接:比如前缀+名字,字段为空会造成拼接的结果为NULL
将student-01表中name值加上“kexuexiong-”前缀:
select s.id,CONCAT("kexuexiong-",s.name ) as name from `student-01` s
输出结果:
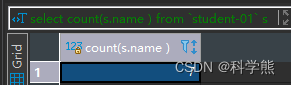
4.如果有 Null column 存在的情况下,count(Null column),null 值不会参与统计
统计名字有多少个:
select count(s.name ) from `student-01` s
输出结果:
5. Null 字段的判断方式
使用!=NULL
select * from `student-01` s where s.name != null
输出结果;
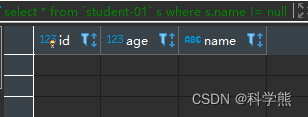
使用=NULL
select * from `student-01` s where s.name = null
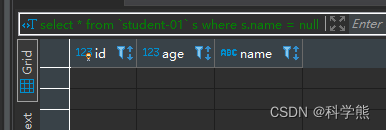
上面这两种方式是新手经常犯的错误,正确的方式应该是:
使用is not null
select * from `student-01` s where s.name is not null
使用is null
select * from `student-01` s where s.name is null
6.可空字段索引,会增加额外的空间
给student-01的name增加索引:
CREATE INDEX student_01_name_IDX USING BTREE ON `student-01` (name);
给student-02的name增加索引:
CREATE INDEX student_02_name_IDX USING BTREE ON `student-02` (name);
使用explain分析sql:
explain select * from `student-01` s where s.name = '小米1'
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s | ref | student_01_name_IDX | student_01_name_IDX | 203 | const | 1 | 100.0 |
explain select * from `student-02` s where s.name = '小米'
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s | ref | student_02_name_IDX | student_02_name_IDX | 202 | const | 1 | 100.0 |
两条查询语句都走name索引,但是key_len(索引字段的长度)不同。可空值得student-01(203)中比不可空值的student-02(202)多了1,两者类型都为varchar(50),编码集:utf8mb4。
key_len 的计算规则和三个因素有关:数据类型、字符编码、是否为 NULL
-
key_len 202 == 50*4(utf8 4字节) + 2 (存储 varchar 变长字符长度 2字节,定长字段无需额外的字节)
-
key_len 203== 20*4(utf8mb4 4字节) + 1 (是否为 Null 的标识) + 2 (存储 varchar 变长字符长度 2字节,定长字段无需额外的字节)
总结
综合以上的案列分析,不建议字段设计时使用可空值。推荐使用一个有意义的值去代替NULL,这样有利于代码的可读性和可维护性,并能从约束上增强业务数据的规范性。


















 2594
2594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











