







Input
引出:
File对象是读取文件的属性数据,如果要读取文件的内容,则需要IO流技术
IO流分类:
按方向:
————输入流
————输出流
按传输单位:
————–字节流: 读取二进制数据,不经过任何处理
————–字符流: 读取二进制数据,并转换成字符
其实就是 字节流+解码
①先复习输入流
所有输入字节流的基类————InputStream(抽象类!!)
———————————-FileInputStream 读取文件数据的输入流
怎么读?
1. 找到目标文件
2. 建立数据的输入通道。
3. 读取文件中的数据。
4. **关闭资源.**
找到JDK中的FileInputStream,发现内容并不多,常用的只有关闭流的close方法和读取流的read方法。。。。。之前真的是莫名恐惧。

对照着文档看见read方法,很容易就可以想出读取文件数据的方式。
即循环缓冲数组读出。注意读取时都是根据读取长度更新覆盖缓冲数组,不清空!!
public class Demo1 {
public static void main(String[] args) throws IOException {
readTest4();
}
//方式4:使用缓冲数组配合循环一起读取。28
public static void readTest4() throws IOException{
long startTime = System.currentTimeMillis();
//找到目标文件
File file = new File("F:\\美女\\1.jpg");
//建立数据的输入通道
FileInputStream fileInputStream = new FileInputStream(file);
//建立缓冲数组配合循环读取文件的数据。
int length = 0; //保存每次读取到的字节个数。
byte[] buf = new byte[1024]; //存储读取到的数据 缓冲数组 的长度一般是1024的倍数,因为与计算机的处理单位。 理论上缓冲数组越大,效率越高
while((length = fileInputStream.read(buf))!=-1){ // read方法如果读取到了文件的末尾,那么会返回-1表示。
System.out.print(new String(buf,0,length));
}
//关闭资源
fileInputStream.close();
long endTime = System.currentTimeMillis();
System.out.println("读取的时间是:"+ (endTime-startTime)); //446
}
//方式3:使用缓冲 数组 读取。 缺点: 无法读取完整一个文件的数据。 12G
public static void readTest3() throws IOException{
//找到目标文件
File file = new File("F:\\a.txt");
//建立数据的输入通道
FileInputStream fileInputStream = new FileInputStream(file);
//建立缓冲字节数组,读取文件的数据。
byte[] buf = new byte[1024]; //相当于超市里面的购物车。
int length = fileInputStream.read(buf); // 如果使用read读取数据传入字节数组,那么数据是存储到字节数组中的,而这时候read方法的返回值是表示的是本次读取了几个字节数据到字节数组中。
System.out.println("length:"+ length);
//使用字节数组构建字符串
String content = new String(buf,0,length);
System.out.println("内容:"+ content);
//关闭资源
fileInputStream.close();
}
//方式2 : 使用循环读取文件的数据
public static void readTest2() throws IOException{
long startTime = System.currentTimeMillis();
//找到目标文件
File file = new File("F:\\美女\\1.jpg");
//建立数据的输入通道
FileInputStream fileInputStream = new FileInputStream(file);
//读取文件的数据
int content = 0; //声明该变量用于存储读取到的数据
while((content = fileInputStream.read())!=-1){
System.out.print((char)content);
}
//关闭资源
fileInputStream.close();
long endTime = System.currentTimeMillis();
System.out.println("读取的时间是:"+ (endTime-startTime)); //446
}
//读取的方式一缺陷: 无法读取完整一个文件 的数据.
public static void readTest1() throws IOException{
//1. 找到目标文件
File file = new File("F:\\a.txt");
//建立数据的输入通道。
FileInputStream fileInputStream = new FileInputStream(file);
//读取文件中的数据
int content = fileInputStream.read(); // read() 读取一个字节的数据,把读取的数据返回。
System.out.println("读到的内容是:"+ (char)content);
//关闭资源 实际上就是释放资源。
fileInputStream.close();
}
}
②后复习输出流
所有输出字节流的基类————OutputStream(抽象类!!)
———————————-FileOutputStream 读取文件数据的输出流
怎么用??

首先注意构造方法, 第二个是追加输出
他本身的方法也很垃圾。。。就是write和close。。

FileOutputStream要注意的细节:
1. 使用FileOutputStream 的时候,如果目标文件不存在,那么会自动创建目标文件对象。
2. 使用FileOutputStream写数据的时候,如果目标文件已经存在,那么会先清空目标文件中的数据,然后再写入数据。
3.使用FileOutputStream写数据的时候, 如果目标文件已经存在,需要在原来数据基础上追加数据的时候应该使用new FileOutputStream(file,true)构造函数,第二参数为true。
4.使用FileOutputStream的write方法写数据的时候,虽然接收的是一个int类型的数据,但是真正写出的只是一个字节的数据,只是把低八位的二进制数据写出,其他二十四位数据全部丢弃。
缓冲流
显然用缓冲数组读取效率高,那么为什么非要用普通的输入输出流配合自己定义的缓冲数组去实现这个过程呢? 于是引出缓冲流
①缓冲输入字节流
BufferInputStream 类, 其实打开源码看到其实就是内部维护了字节数组。
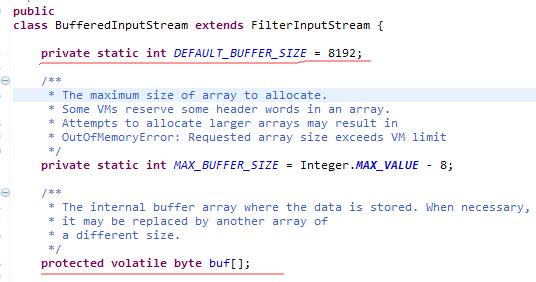
首先看他的构造方法:

显然不是直接创建的缓冲流,不能用一个File类作为参数创建流,而是需要一个普通的输入流作为参数去创建。。显然好傻逼阿 - -为啥不设计成直接传File参数呢- -。。所以其实 缓冲流是不具备读写能力的!!!,他的读写能力都是通过参数的流的读写能力来的。。
注意啊。。InputStream是抽象类。。不能直接创建对象的, 所以要用多态。。传子类进去。。。

好渣。read方法每次只能读一个字节。。但是为什么会比普通的输入流快呢?。。
打开源码看。。原来是先一个个读。。然后把读到的数据存到内部维护的数组中,然后从数组中去取出来打印。。。内部维护的数组什么概念!!是缓冲流这个对象的成员!! 在堆内存中!!! 直接在内存中读取数据,当然比在硬盘中读快了!!!所以其实跟自己创建一个8kb的缓冲数组是差不多的。。。。。。
public synchronized int read() throws IOException {
if (pos >= count) { //pos 是当前取到了缓冲数组的第几个字节, count是读取了多少个字节到缓冲数组
fill(); //没到8kb先一直填充
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff; //一个一个读取数组数据。没读完前不用读了。
}②缓冲输出字节流
使用跟输入流差不多啊。。。也是维护了一个8kb的缓冲数组,写数据的时候就先写到缓冲数组里面。
啥时候写到文件中呢??
① 8kb满了, 自动全写
②调用flush方法! 没满8kb也写到文件去!!
但是注意一下他的方法:
他也是有close方法的!!!坑爹API1.6里面居然没有。。我要立刻换文档!!
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}














 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









