







论文阅读:A BETTER AND FASTER END-TO-END MODEL FOR STREAMING ASR
下载链接:https://arxiv.org/abs/2011.10798
主要内容:
本篇文章主要是想在解决end-2-end网络的延时问题的同时保持网络的解码效果。文章提出了一种conformer+Cascaded Encoders的网络框架,以保证网络的解码效果。同时提出了一些降低延时的方法,并对每种方法进行了实验验证
模型主要结构:
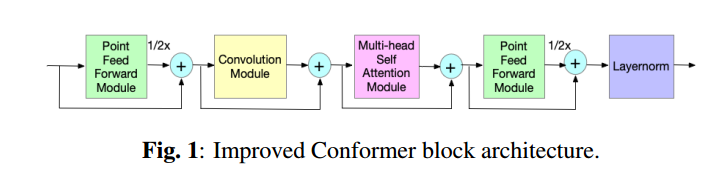
1、conformer
文章中使用了一种改进了的conformer结构,主要做了以下一些改进
- 在做self-attention的时候只使用 the previous context(为了进行流式解码)
- 将长度接近的音频放在同一个batch里面进行训练(为了提高效率)
- 用group normalization 代替 bctch normalization (避免有偏估计)
- 不再使用相对位置编码,通过使用交换卷积个multihead 顺序的方式提供相对位置信息(加快训练速度)
下图为改进后的conformer结构:
2、Two-pass with Cascaded Encoders
本文提出了一种两阶段的级联encoder,以解决基于attention的算法对于长音频的解码效果不佳的问题。
第一阶段:causal encoder+RNNT decoder;
第二阶段:将第一阶段 encoder 的输出作为第二阶段non causal encoder的输入,然后再输入相同的decoder。
在降低延时方面做得一些工作
1、首先介绍了三种度量延时的指标,然后提出了一些相应的降低延时的方法。
- Endpointer Latency:说话人完成说话到系统预测出最终结果的时间
- Prefetch Latency:系统第一次正确的预载入到说话人完成说话的时间(可以使用 E2E prefetching)
- Partial Latency:系统第一次给出正确的中间结果到说话人完成说话的时间(可以使用constrained alignment,fast-emit)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









