









一、磁盘IO性能指标

- 使用率
- 饱和度
- IOPS
- 吞吐量
- 响应时间
这五个指标,是衡量磁盘性能的基本指标。
- 磁盘使用率%util,是指磁盘处理 I/O 的时间百分比。如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷;
- 饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O请求。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。
- 响应时间await,是指 I/O 请求从发出到收到响应的间隔时间(平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)。
这些指标,我们在看的时候, 不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。
二、磁盘IO性能分析

1、分析思路和步骤
(1)通过top查看系统整体情况,如果wa过大,详细分析磁盘IO瓶颈;
(2)使用 iostat 分析磁盘I/O使用率,磁盘I/O响应时间,磁盘I/O队列长度,查看这3个指标;
(3)如果磁盘I/O使用率过高,或磁盘I/O响应时间过长,或磁盘I/O队列长度过大,再借助 pidstat ,定位出导致瓶颈的进程;
(4)通过strace来定位进程的所有系统调用,随后分析进程的 I/O 行为;
(5)最后通过lsof分析这些 I/O 的来源既进程操作的文件;

2、工具使用

3、操作演示
(1)通过top查看系统整体情况
命令:top
结果分析:
CPU0空闲id%只有0.7,wa%占92.7,这说明 CPU0 上,可能正在运行 I/O 密集型的进程,磁盘IO可能存在瓶颈,需要进一步分析。

(2)使用 iostat 分析磁盘I/O使用率,磁盘I/O响应时间,磁盘I/O队列长度
命令:iostat -x -d 1
结果分析:
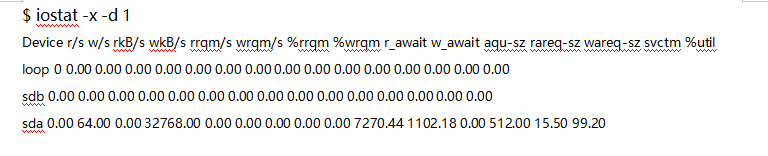
观察 iostat 的最后一列,你会看到,磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接近 I/O 饱和。
再看前面的各个指标,每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。
超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。此时,sda 磁盘已经遇到了严重的性能瓶颈。
(3)如果磁盘I/O使用率过高,或磁盘I/O响应时间过长,或磁盘I/O队列长度过大,再借助 pidstat进一步分析
命令:pidstat -d 1
结果分析:
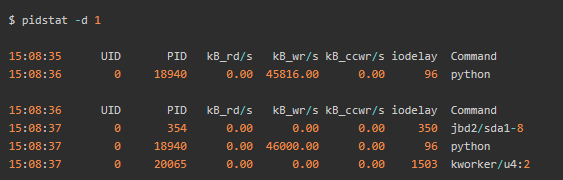
python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大.
python 进程的 PID 号18940,正是top查看时 CPU 使用率最高的进程。
(4)通过strace来定位进程的所有系统调用,随后分析进程的 I/O 行为;
命令:strace -f -T -tt -o strace.log -p 【pid】
结果分析:
系统调用来看, epoll_pwait、read、write、fdatasync 这些系统调用都比较频繁。
刚才观察到的写磁盘,应该是 write 或者 fdatasync 导致。

(5)最后通过lsof分析这些 I/O 的来源既进程操作的文件;
命令:lsof -p 【pid】
结果分析:
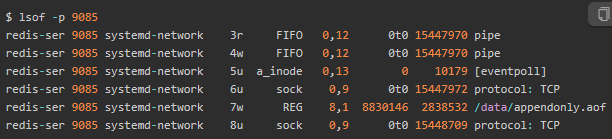
描述符编号为 3 的是一个 pipe 管道,5 号是 eventpoll,7 号是一个普通文件,而 8 号是一个 TCP socket,读写对应标准的“请求 - 响应”格式。
只有 7 号普通文件才会产生磁盘写,而它操作的文件路径是 /data/appendonly.aof,相应的系统调用包括 write 和 fdatasync。
这个文件路径以及 fdatasync 的系统调用都与redis持久化有关。
[5.1]详细确认磁盘IO瓶颈
命令:strace -f -p 【pid】-T -e 【expr】
结果分析:
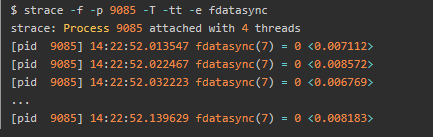
每隔10ms 左右,就会有一次 fdatasync 调用,并且每次调用本身也要消耗 7~8ms。当前IO写较多,是由于redis配置为总是持久化(appendfsync为always )导致的。
三、磁盘IO优化
1、优化思路
(1)确认优化指标;
(2)获取优化指标数据;
(3)进行模拟测试时,需要注意测试工具不能和实验机在一个主机上。保证优化前后实验主机为同一个;
(4)通过数据确认优化可以带来较大提升的指标进行优化;
(5)对于这些指标进行优化,注意优化这些指标的双面性,带来的损失会不会比优化带来的效益更大。配合资源情况,做出合适的调整;
(6)测试优化结果;
2、优化操作
【2.1】常用优化操作
- 如果服务器用来做日志分析,注意随机读和顺序写,避免定期的压缩、解压大日志。
- 如果是前端应用服务器,要避免程序频繁打本地日志、或者异常日志
- 如果是存储服务(mysql、nosql),尽量将服务部署在单独的节点上,做读写分离降低压力。
【2.2】详细优化操作
优化总结起来分为三个方向:一个是应用程序优化,一个是文件系统优化,最后一个是磁盘优化;
应用程序优化
(1)可以用追加写(顺序写)代替随机写,减少寻址开销,加快 I/O 写的速度。
(2)可以借助缓存 I/O ,充分利用系统缓存,降低实际 I/O 的次数。
(3)可以在应用程序内部构建自己的缓存,或者用 Redis 这类外部缓存系统。这样,一方面,能在应用程序内部,控制缓存的数据和生命周期,并且推荐采用自身方式缓存数据,而不是利用系统缓存;另一方面,也能降低其他应用程序使用缓存对自身的影响。如:C 标准库的 fopen、fread 等库函数,都会利用标准库的缓存,减少磁盘的操作;而使用 open、read 等系统调用时,就能利用操作系统提供的页缓存和缓冲区等,而没有库函数的缓存可用。
(4)在需要频繁读写同一块磁盘空间时,可以用 mmap 代替 read/write,减少内存的拷贝次数。
(5)在需要同步写的场景中,尽量将写请求合并,而不是让每个请求都同步写入磁盘,即可以用 fsync() 取代 O_SYNC。
(6)在多个应用程序共享相同磁盘时,为了保证 I/O 不被某个应用完全占用,推荐你使用 cgroups 的 I/O 子系统,来限制进程 / 进程组的 IOPS 以及吞吐量。
(7)在使用 CFQ 调度器时,可以用 ionice 来调整进程的 I/O 调度优先级,特别是提高核心应用的 I/O 优先级。ionice 支持三个优先级类:Idle、Best-effort 和 Realtime。其中, Best-effort 和 Realtime 还分别支持 0-7 的级别,数值越小,则表示优先级别越高。
文件系统优化
(1)你可以根据实际负载场景的不同,选择最适合的文件系统。比如 Ubuntu 默认使用 ext4 文件系统,而 CentOS 7 默认使用 xfs 文件系统。相比于 ext4 ,xfs 支持更大的磁盘分区和更大的文件数量,如 xfs 支持大于 16TB 的磁盘,但是 xfs 文件系统的缺点在于无法收缩,而 ext4 则可以。
(2)在选好文件系统后,还可以进一步优化文件系统的配置选项,包括文件系统的特性(如 ext_attr、dir_index)、日志模式(如 journal、ordered、writeback)、挂载选项(如 noatime)等等。比如, 使用 tune2fs 这个工具,可以调整文件系统的特性(tune2fs 也常用来查看文件系统超级块的内容)。 而通过 /etc/fstab ,或者 mount 命令行参数,我们可以调整文件系统的日志模式和挂载选项等。
(3)可以优化文件系统的缓存。比如,你可以优化 pdflush 脏页的刷新频率(比如设置 dirty_expire_centisecs 和 dirty_writeback_centisecs)以及脏页的限额(比如调整 dirty_background_ratio 和 dirty_ratio 等)。再如,你还可以优化内核回收目录项缓存和索引节点缓存的倾向,即调整 vfs_cache_pressure(/proc/sys/vm/vfs_cache_pressure,默认值 100),数值越大,就表示越容易回收。
(4)在不需要持久化时,你还可以用内存文件系统 tmpfs,以获得更好的 I/O 性能 。tmpfs 把数据直接保存在内存中,而不是磁盘中。比如 /dev/shm/ ,就是大多数 Linux 默认配置的一个内存文件系统,它的大小默认为总内存的一半。
磁盘优化
(1)最简单有效的优化方法,就是换用性能更好的磁盘,比如用 SSD 替代 HDD。
(2)我们可以使用 RAID ,把多块磁盘组合成一个逻辑磁盘,构成冗余独立磁盘阵列。这样做既可以提高数据的可靠性,又可以提升数据的访问性能。
(3)针对磁盘和应用程序 I/O 模式的特征,我们可以选择最适合的 I/O 调度算法。比如,SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法。而数据库应用,我更推荐使用 deadline 算法。
(4)我们可以对应用程序的数据,进行磁盘级别的隔离。比如,我们可以为日志、数据库等 I/O 压力比较重的应用,配置单独的磁盘。
(5)在顺序读比较多的场景中,我们可以增大磁盘的预读数据。比如,你可以通过下面两种方法,调整 /dev/sdb 的预读大小。① 调整内核选项 /sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。
② 使用 blockdev 工具设置,比如 blockdev --setra 8192 /dev/sdb,注意这里的单位是 512B(0.5KB),所以它的数值总是 read_ahead_kb 的两倍。
(6)我们可以优化内核块设备 I/O 的选项。比如,可以调整磁盘队列的长度 /sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量(当然也会导致 I/O 延迟增大)。
(7)磁盘本身可能出现硬件错误,也会导致 I/O 性能急剧下降,所以发现磁盘性能急剧下降时,你还需要确认,磁盘本身是不是出现了硬件错误。比如,你可以查看 dmesg 中是否有硬件 I/O 故障的日志。 还可以使用 badblocks、smartctl 等工具,检测磁盘的硬件问题,或用 e2fsck 等来检测文件系统的错误。如果发现问题,你可以使用 fsck 等工具来修复。
说明
QQ群:775460627,欢迎对于测试志同道合的人加入,大家一起沟通交流!
















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











