







Deecamp夏令营需要用到CartoonGAN,所以对于CartoonGAN进行代码以及文章分析。
首先分析了preTrain的VGG19如下
input VGG19 提取feature
input generator VGG199提取feature 使两者相似来提取结构信息。
如果在实现时效果不明显或者出现模型崩塌,加大pre_train的epoch,这样可以使得后面训练更容易,当然加大pre_train的epoch 之后 后面训练的epoch就可能出现
对于github上面2个cartoonGAN进行复现,发现问题。
https://github.com/taki0112/CartoonGAN-Tensorflow
问题1 图片文件夹错误 trainA 真实世界,trainB卡通世界
问题2 进行迭代后效果不明显
解决方案:分析有可能是pretrain不够 增加pretrain次数然后进行train
https://github.com/SystemErrorWang/CartoonGAN
问题1 未对如何运行进行详细描述
问题2 未对test进行描述
解决方案 查看代码,在oldcode文件目录下创建
celeba
cartoon
分别存放卡通图像以及真实的名人图像
CartonnGAN 理解
cartonnGAN的贡献:
1.generate high-quality stylized cartoons 提出的GAN模型能生成高质量的图像
2.We propose two simple yet effective loss functions in GAN-based architecture. In the generative network, to cope
with substantial style variation between photos and cartoons, we introduce a semantic loss defined as an ℓ1 sparse
regularization in the high-level feature maps of the VGG network [30]. In the discriminator network, we propose an edge-promoting adversarial loss for preserving clear edges 提出两种有效的loss函数,一个loss 是VGGloss对于图像的conv4_4的更高级的特征进行pretrain与discriminator提出一种边缘损失有益于保留清晰的边界。
3.We further introduce an initialization phase to improve the convergence of the network to the target manifold.
Our method is much more efficient to train than existing methods. 如图是经过pretrain后的图像。

Loss函数
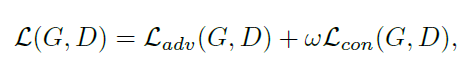
loss分为两部分组成,第一部分对内容进行流行转换,第二部分保留卡通的内容。
第一部分
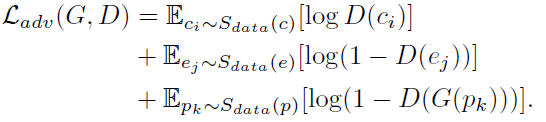
其中 S(c)为卡通 S(e) 为模糊边界卡通 ,p为图像。

第二部分
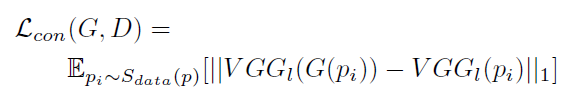
内容损失,保留卡通的内容。















 4151
4151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









