







Set
Set接口也是Collection的一种扩展
与List不同的是,在Set中的对象元素不能重复,也就是说你不能把同样的东西两次放入同一个Set容器中。它的常用具体实现有HashSet和TreeSet类。HashSet能快速定位一个元素,但是你放到HashSet中的对象需要实现hashCode()方法,它使用了前面说过的哈希码的算法。而TreeSet则将放入其中的元素按序存放,这就要求你放入其中的对象是可排序的,这就用到了集合框架提供的另外两个实用类Comparable和Comparator。一个类是可排序的,它就应该实现Comparable接口。有时多个类具有相同的排序算法,那就不需要在每分别重复定义相同的排序算法,只要实现Comparator接口即可。集合框架中还有两个很实用的公用类:Collections和Arrays。Collections提供了对一个Collection容器进行诸如排序、复制、查找和填充等一些非常有用的方法,Arrays则是对一个数组进行类似的操作。
Set的功能
Set的接口就是Collection的,所以不像那两个List,它没有额外的功能。实际上Set确确实实就是一个Collection--只不过行为方式不同罢了。(这是继承和多态性的完美运用:表达不同地行为。)Set会拒绝持有多个具有相同值的对象的实例(对象的“值”又是由什么决定的呢?这个问题比较复杂,我们以后会讲)。
Set(接口):加入Set的每个元素必须是唯一的;否则,Set是不会把它加进去的。要想加进Set,Object必须定义equals(),这样才能标明对象的唯一性。Set的接口和Collection的一摸一样。Set的接口不保证它会用哪种顺序来存储元素。
HashSet
:为优化查询速度而设计的Set。要放进HashSet里面的Object**还得定义hashCode()。不允许有重复值, 允许有一个null, 它的优点是可以快速的帮我们查找对象, 缺点是我们无法控制对象的顺序**.。(有关hashcode具体参见:http://blog.csdn.net/qq_23473123/article/details/51111323,正是因为hashcode Hashset才可以快速查找对象)
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(…));
HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet的继承关系如下:
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractSet<E>
java.util.HashSet<E>
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable { }HashSet的主要API
boolean add(E object)
void clear()
Object clone()
boolean contains(Object object)
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object object)
int size()代码示例:
package whf.Framework;
import java.util.Iterator;
import java.util.HashSet;
public class HashSetTest {
public static void main(String[] args) {
// HashSet常用API
testHashSetAPIs() ;
}
/*
* HashSet除了iterator()和add()之外的其它常用API
*/
private static void testHashSetAPIs() {
// 新建HashSet
HashSet set = new HashSet();
// 将元素添加到Set中
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
// 打印HashSet的实际大小
System.out.printf("size : %d\n", set.size());
// 判断HashSet是否包含某个值
System.out.printf("HashSet contains a :%s\n", set.contains("a"));
System.out.printf("HashSet contains g :%s\n", set.contains("g"));
// 删除HashSet中的“e”
set.remove("e");
// 将Set转换为数组
String[] arr = (String[])set.toArray(new String[0]);
for (String str:arr)
System.out.printf("for each : %s\n", str);
// 新建一个包含b、c、f的HashSet
HashSet otherset = new HashSet();
otherset.add("b");
otherset.add("c");
otherset.add("f");
// 克隆一个removeset,内容和set一模一样
HashSet removeset = (HashSet)set.clone();
// 删除“removeset中,属于otherSet的元素”
removeset.removeAll(otherset);
// 打印removeset
System.out.printf("removeset : %s\n", removeset);
// 克隆一个retainset,内容和set一模一样
HashSet retainset = (HashSet)set.clone();
// 保留“retainset中,属于otherSet的元素”
retainset.retainAll(otherset);
// 打印retainset
System.out.printf("retainset : %s\n", retainset);
// 遍历HashSet
for(Iterator iterator = set.iterator();
iterator.hasNext(); )
System.out.printf("iterator : %s\n", iterator.next());
// 清空HashSet
set.clear();
// 输出HashSet是否为空
System.out.printf("%s\n", set.isEmpty()?"set is empty":"set is not empty");
}
}TreeSet
:是一个有序的Set,其底层是一颗树。这样你就能从Set里面提取一个有序序列了。因为它要排序, 所以加入它的对象必须实现 Comparable 接口或在创建 TreeSet 时提供比较器(Comparator), 在迭代 TreeSet 时, 我们可以按照升序迭代, 也可以按照降序迭代.
TreeSet的接口依赖图:
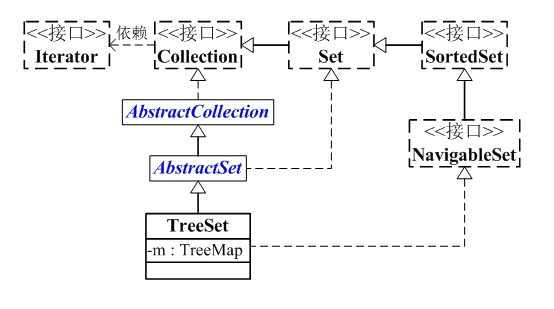
从图中可以看出:
(1)TreeSet继承于AbstractSet,并且实现了NavigableSet接口。
(2)TreeSet是一个包含有序的且没有重复元素的集合,通过TreeMap实现。
方法摘要:http://www.yq1012.com/api/
示例代码:
package whf.Framework;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
testTreeSetAPIs();
}
// 测试TreeSet的api
public static void testTreeSetAPIs() {
String val;
// 新建TreeSet
TreeSet tSet = new TreeSet();
// 将元素添加到TreeSet中
tSet.add("aaa");
// Set中不允许重复元素,所以只会保存一个“aaa”
tSet.add("aaa");
tSet.add("bbb");
tSet.add("eee");
tSet.add("ddd");
tSet.add("ccc");
System.out.println("TreeSet:" + tSet);
// 打印TreeSet的实际大小
System.out.printf("size : %d\n", tSet.size());
// 导航方法
// floor(小于、等于)
System.out.printf("floor bbb: %s\n", tSet.floor("bbb"));
// lower(小于)
System.out.printf("lower bbb: %s\n", tSet.lower("bbb"));
// ceiling(大于、等于)
System.out.printf("ceiling bbb: %s\n", tSet.ceiling("bbb"));
System.out.printf("ceiling eee: %s\n", tSet.ceiling("eee"));
// ceiling(大于)
System.out.printf("higher bbb: %s\n", tSet.higher("bbb"));
// subSet()
System.out.printf("subSet(aaa, true, ccc, true): %s\n", tSet.subSet("aaa", true, "ccc", true));
System.out.printf("subSet(aaa, true, ccc, false): %s\n", tSet.subSet("aaa", true, "ccc", false));
System.out.printf("subSet(aaa, false, ccc, true): %s\n", tSet.subSet("aaa", false, "ccc", true));
System.out.printf("subSet(aaa, false, ccc, false): %s\n", tSet.subSet("aaa", false, "ccc", false));
// headSet()
System.out.printf("headSet(ccc, true): %s\n", tSet.headSet("ccc", true));
System.out.printf("headSet(ccc, false): %s\n", tSet.headSet("ccc", false));
// tailSet()
System.out.printf("tailSet(ccc, true): %s\n", tSet.tailSet("ccc", true));
System.out.printf("tailSet(ccc, false): %s\n", tSet.tailSet("ccc", false));
// 删除“ccc”
tSet.remove("ccc");
// 将Set转换为数组
String[] arr = (String[]) tSet.toArray(new String[0]);
for (String str : arr)
System.out.printf("for each : %s\n", str);
// 打印TreeSet
System.out.printf("TreeSet:%s\n", tSet);
// 遍历TreeSet
for (Iterator iter = tSet.iterator(); iter.hasNext();) {
System.out.printf("iter : %s\n", iter.next());
}
// 删除并返回第一个元素
val = (String) tSet.pollFirst();
System.out.printf("pollFirst=%s, set=%s\n", val, tSet);
// 删除并返回最后一个元素
val = (String) tSet.pollLast();
System.out.printf("pollLast=%s, set=%s\n", val, tSet);
// 清空HashSet
tSet.clear();
// 输出HashSet是否为空
System.out.printf("%s\n", tSet.isEmpty() ? "set is empty" : "set is not empty");
}
}LinkedHashSet(JDK 1.4)
:一个在内部使用链表的Set,既有HashSet的查询速度,又能保存元素被加进去的顺序(插入顺序)。用Iterator遍历Set的时候,它克服了 HashSet 的缺点它是按插入顺序进行访问的。
HashSet保存对象的顺序是和TreeSet和LinkedHashSet不一样的。这是因为它们是用不同的方法来存储和查找元素的。(TreeSet用了一种叫红黑树的数据结构【red-black tree data structure】来为元素排序,而HashSet则用了“专为快速查找而设计”的散列函数。LinkedHashSet在内部用散列来提高查询速度,但是它看上去像是用链表来保存元素的插入顺序的。)你写自己的类的时候,一定要记住,Set要有一个判断以什么顺序来存储元素的标准,也就是说你必须实现Comparable接口,并且定义compareTo()方法。
**
SortedSet(只有TreeSet这一个实现可用)中的元素一定是有序的。这使得SortedSet接口多了一些方法:
Comparator comparator():返回Set所使用的Comparator对象,或者用null表示它使用Object自有的排序方法。
Object first():返回最小的元素。
Object last():返回最大的元素。
SortedSet subSet(fromElement, toElement):返回Set的子集,其中的元素从fromElement开始到toElement为止(包括fromElement,不包括toElement)。
SortedSet headSet(toElement):返回Set的子集,其中的元素都应小于toElement。
SortedSet headSet(toElement):返回Set的子集,其中的元素都应大于fromElement。
注意,SortedSet意思是“根据对象的比较顺序”,而不是“插入顺序”进行排序.















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









