







软件测试微信群:https://bbs.csdn.net/topics/618423372 有兴趣的可以扫码加入
1.简介
在日常的自动化测试工作中进行断言的时候,我们可能经常遇到的场景。从一个字符串中找出一组数字或者其中的某些关键字,而不是将这一串字符串作为结果进行断言。这个时候就需要我们对字符串进行操作,宏哥这里介绍两种方法:正则和字符串切片函数split()。
2.测试场景
宏哥在这里说一下,自己的胡诌的测试场景哈,仅供学习和参考。然后按照宏哥说的进行自动化测试,测试场景:在度娘或者其他搜索引擎中搜索“北京宏哥”,然后搜索完毕,会返回搜索结果,告诉你搜索到多少个“北京宏哥”。宏哥这里分别用搜狗和必应搜索,然后对比她俩谁所搜到的“北京宏哥”多,然后通过对比说明谁的搜索能力强大(搜索结果多说明搜索能力强大)。
3.字符串正则操作
关于这个字符串通过正则提取关键字,正则的这个概念宏哥就在这里赘述一下或许不是很全面,,有兴趣的可以自己查一下。但是宏哥上边说的测试场景就需要用到这一操作(re.sub)。
3.1正则表达式
什么是正则表达式?
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式可以干什么?
- 快速高效的查找与分析字符串
- 进行有规律查找比对字符串,也叫:模式匹配
- 具有查找、比对、匹配、替换、插入、添加、删除等能力。
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如我们编写爬虫收集数据,首先都得到网页源码,但是我们要如何提取有效数据呢,这时候我们就需要使用正则表达式来进行匹配了。
3.2re模块
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
由于Python的字符串本身也用\转义,所以要特别注意:
s = 'ABC\\-001' # Python的字符串 # 对应的正则表达式字符串变成: # 'ABC\-001'
因此建议使用Python的r前缀,就不用考虑转义的问题了:
s = r'ABC\-001' # Python的字符串 # 对应的正则表达式字符串不变: # 'ABC\-001'
3.3re模块符号大全
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
注意:表中re指的是表达式而不是字面的re这两个字母
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
-
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
3.4re模常用方法
3.4.1re.match()
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见上方可选标志表格 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
实例及输出:
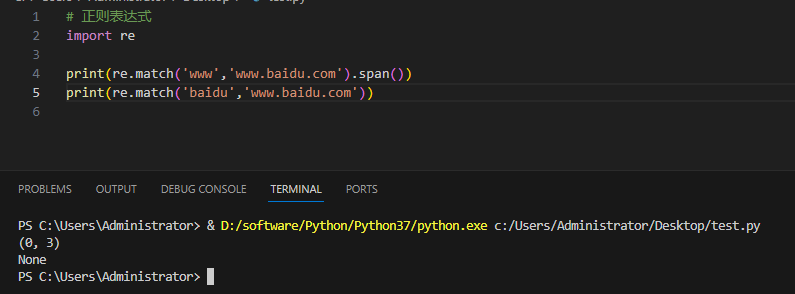
第一个匹配成功,第二个则失败
3.4.2re.search()
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见上方可选标志表格 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
实例及输出:
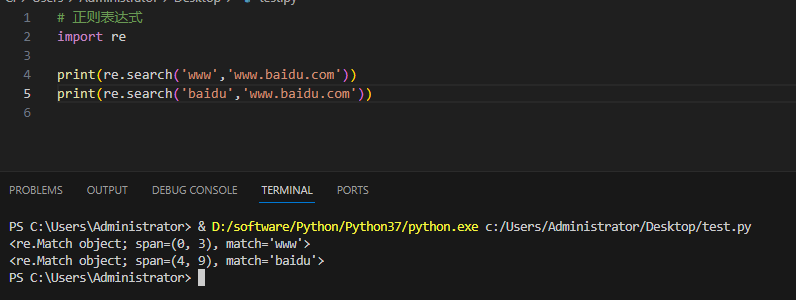
3.4.3compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,re函数使用。
提前编译可减少多次正则匹配的运行时间
语法格式为:
re.compile(pattern[, flags])
参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式
3.4.4re.findall()
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
用法1
直接使用的语法格式为:
re.findall(pattern, string, flags)
参数:
- pattern 正则表达式
- string 待匹配的字符串
- flags re的一些flag,可不写
实例及输出:
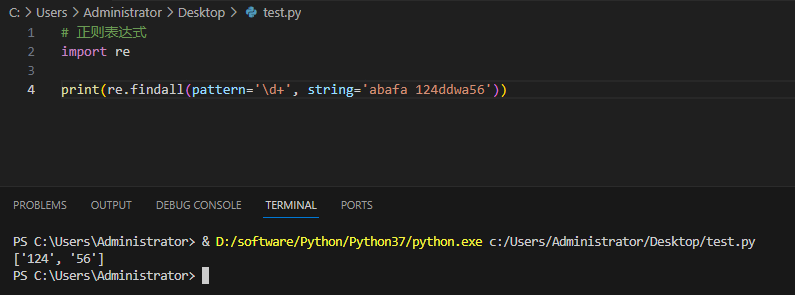
用法2
compile后使用findall的语法格式为:
re.findall(string, pos, endpos)
参数:
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
实例及输出:
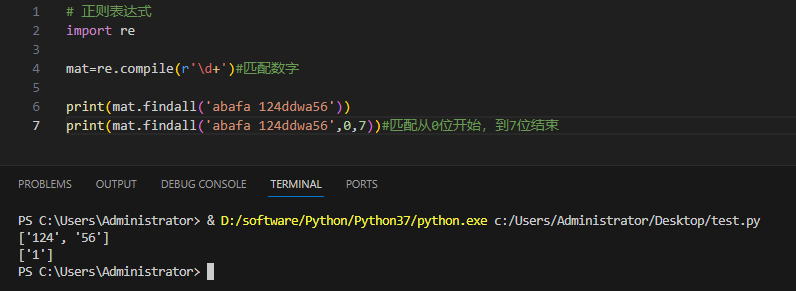
3.4.5re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
实例及输出:
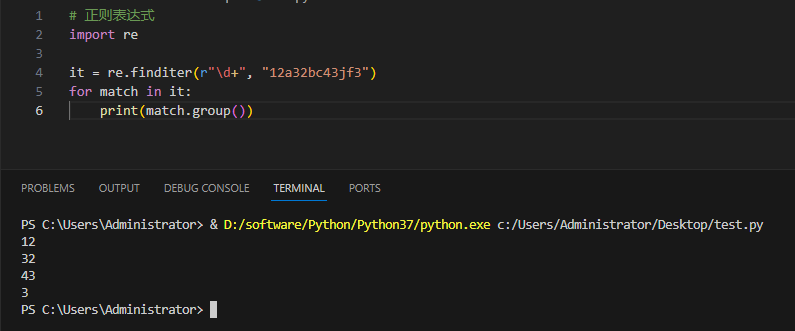
3.4.6re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
参数:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见上方可选标志表格 |
实例:
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']
发现无法识别连续的空格,用正则表达式试试:
>>> re.split(r'\s+', 'a b c') ['a', 'b', 'c']
无论多少个空格都可以正常分割。加入,试试:
>>> re.split(r'[\s\,]+', 'a,b, c d') ['a', 'b', 'c', 'd']
再加入;试试:
>>> re.split(r'[\s\,\;]+', 'a,b;; c d') ['a', 'b', 'c', 'd']
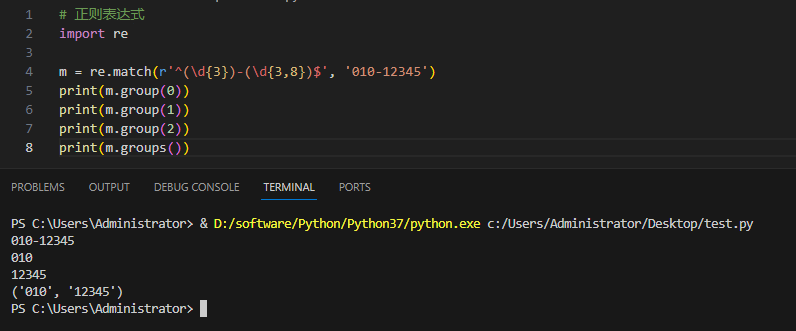
3.4.7groups()
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例及输出:
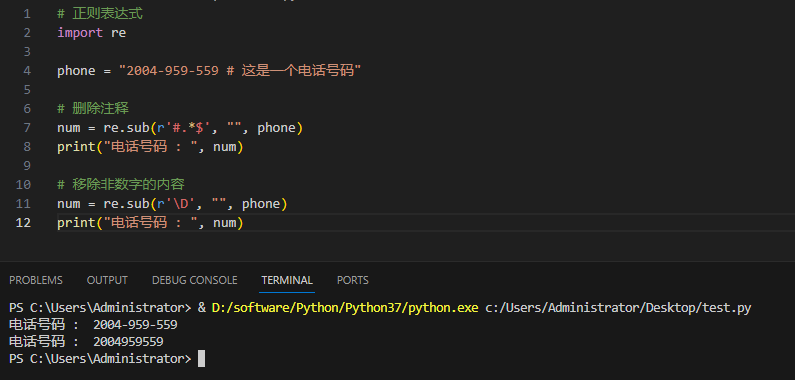
3.4.8re.sub
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数。
实例及输出:
repl 参数可以是一个函数
以下实例中将字符串中的匹配的数字乘于 2:
实例及输出:
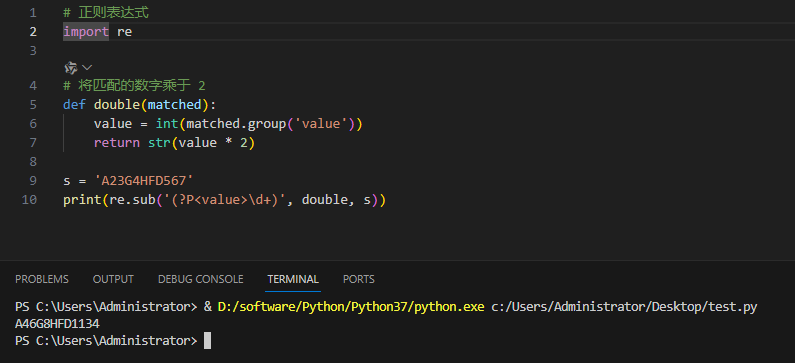
3.5贪婪匹配
需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')
由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')
3.6正则表达式实例
3.6.1字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
3.6.2字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
3.6.3特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
4.项目实战
4.1测试用例
首先宏哥根据测试场景进行测试用例的设计,如下:
1.分别在搜狗和必应搜索框“北京宏哥”
2.分别点击查询,观察查询结果
3.分别将查询结果取到
4.提取结果中的数字,保存在变量中
5.对比两个数字的大小
4.2代码设计
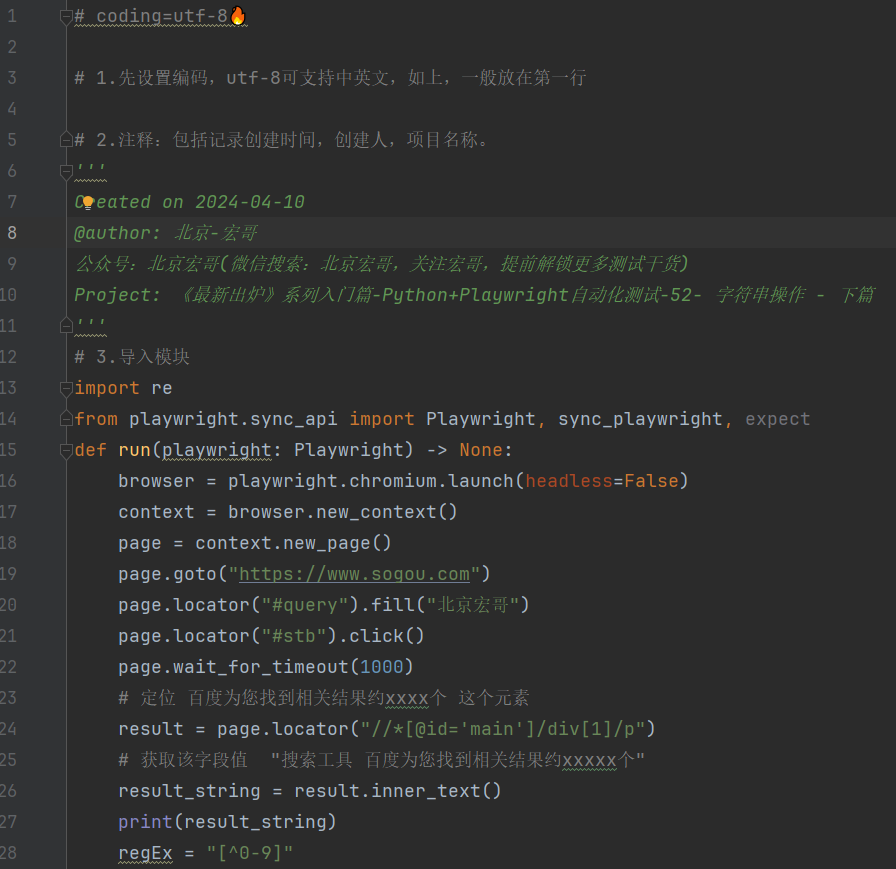
4.3参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2024-04-10
@author: 北京-宏哥
公众号:北京宏哥(微信搜索:北京宏哥,关注宏哥,提前解锁更多测试干货)
Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-52- 字符串操作 - 下篇
'''
# 3.导入模块
import re
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.sogou.com")
page.locator("#query").fill("北京宏哥")
page.locator("#stb").click()
page.wait_for_timeout(1000)
# 定位 搜狗为您找到相关结果约xxxx个 这个元素
result = page.locator("//*[@id='main']/div[1]/p")
# 获取该字段值 "搜索工具 搜狗为您找到相关结果约xxxxx个"
result_string = result.inner_text()
print(result_string)
regEx = "[^0-9]"
search_number = re.sub(regEx,"", result_string)
print(search_number)
page.goto("https://cn.bing.com")
page.locator("#sb_form_q").fill("北京宏哥")
page.locator("#search_icon").click()
page.wait_for_timeout(1000)
# 定位 必应为xxxx条结果 这个元素
result1 = page.locator("//*[@id='b_tween_searchResults']/span")
# 获取该字段值 "约 xxx 个结果"
result_string1 = result1.inner_text()
print(result_string1)
st2 = re.sub(regEx, "",result_string1)
print(st2)
# 首先将两个数都转换为int 数据
a_N = int(search_number)
b_N = int(st2)
# 搜狗和必应的搜索结果对比
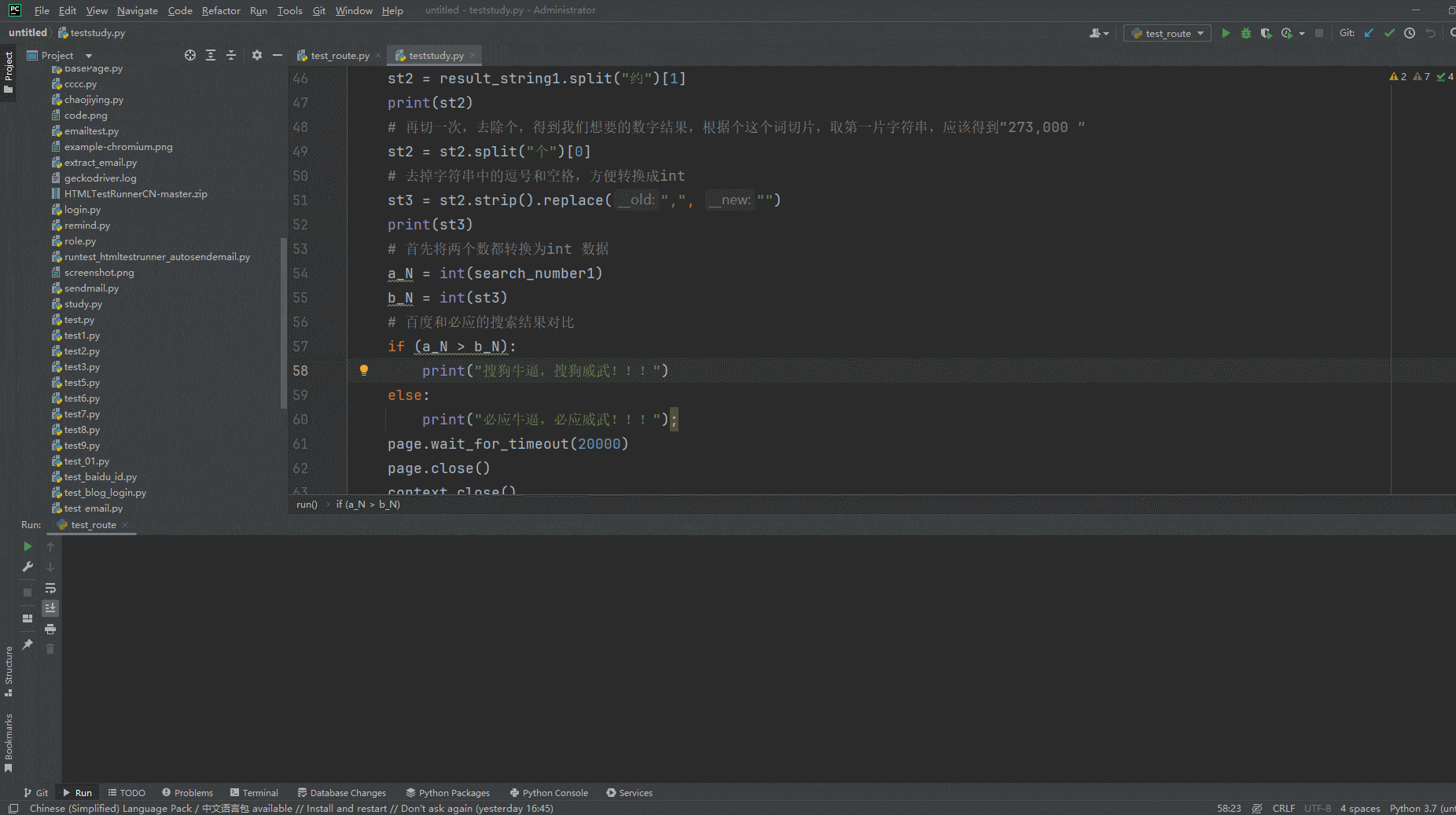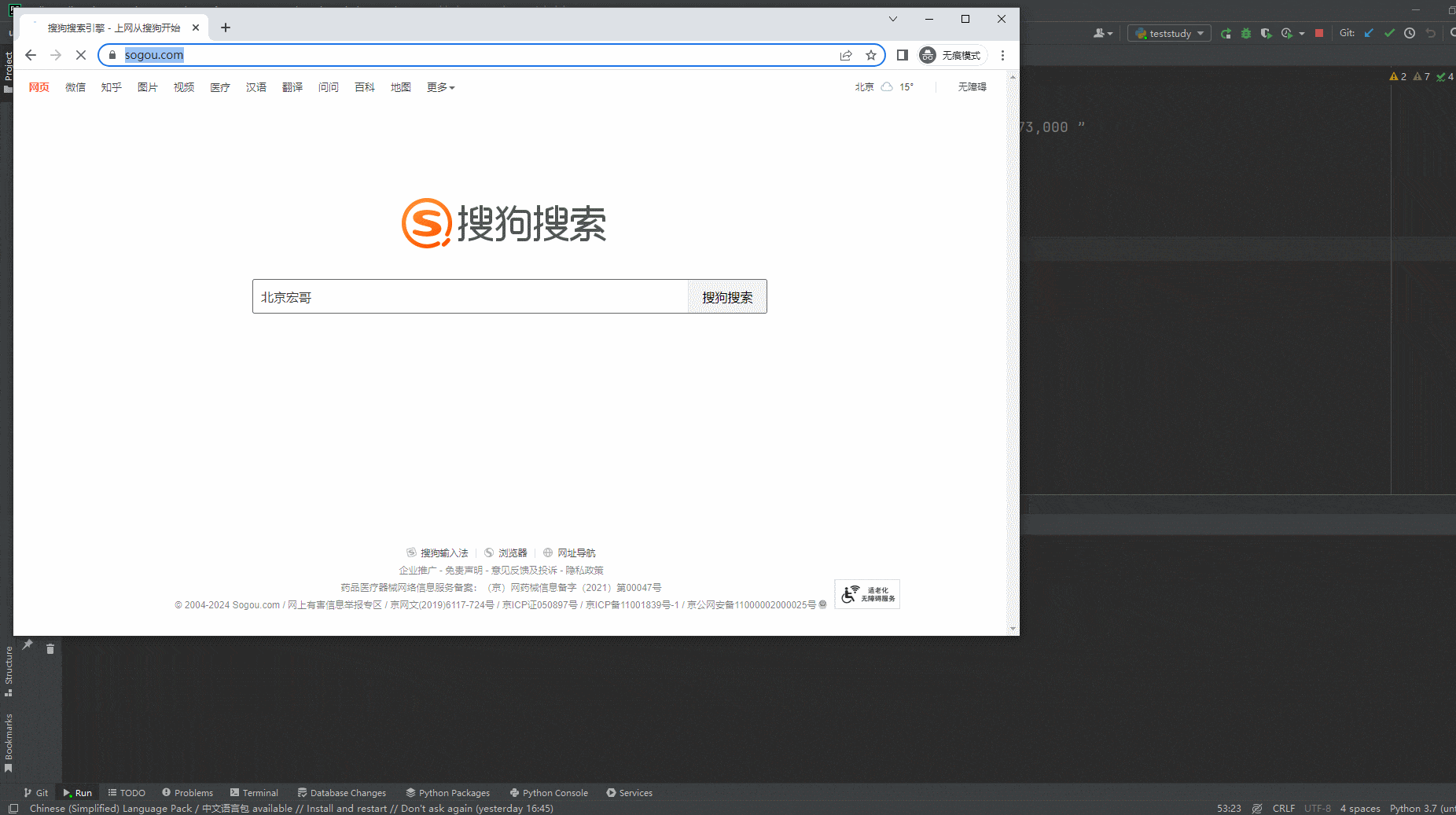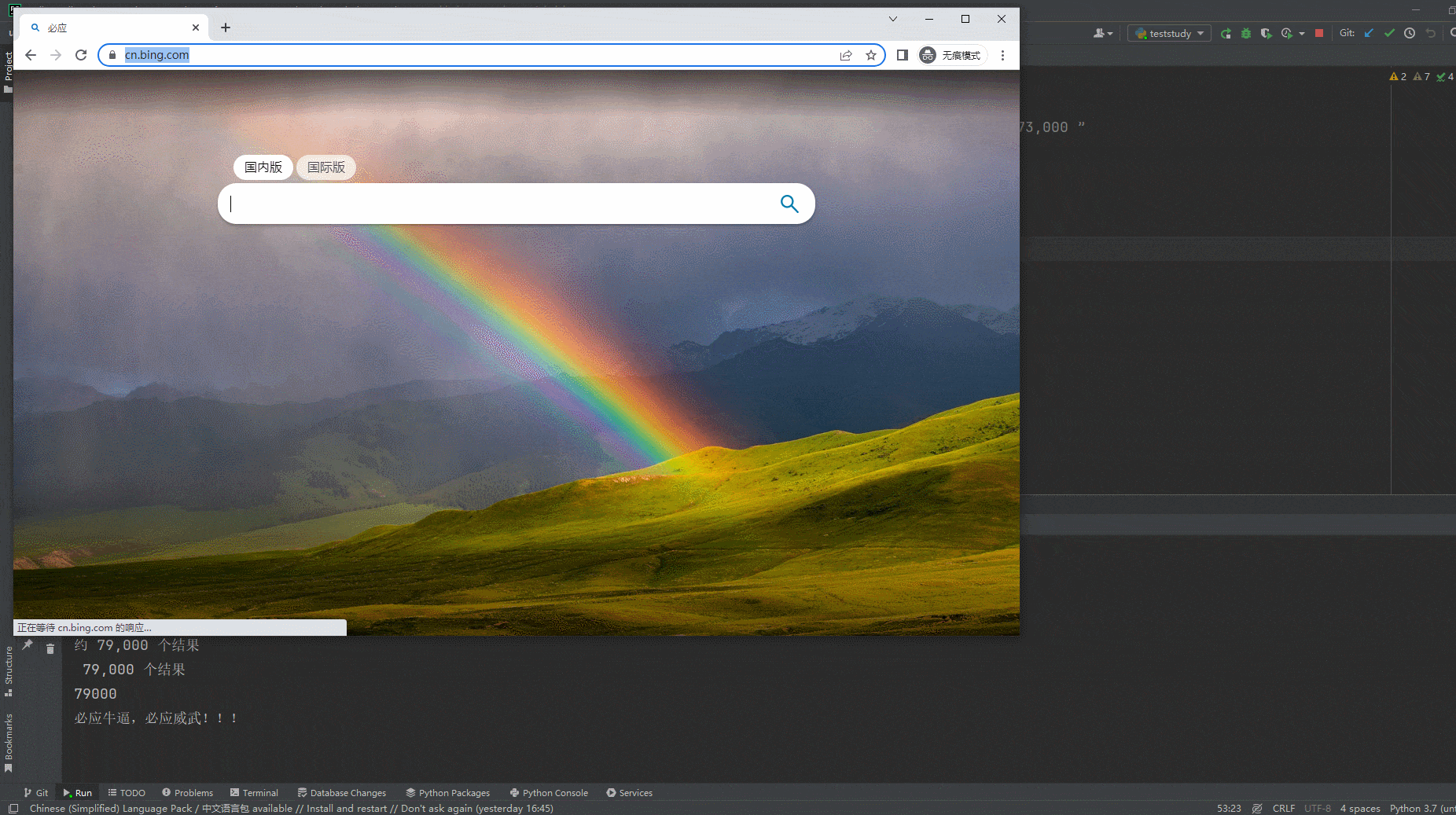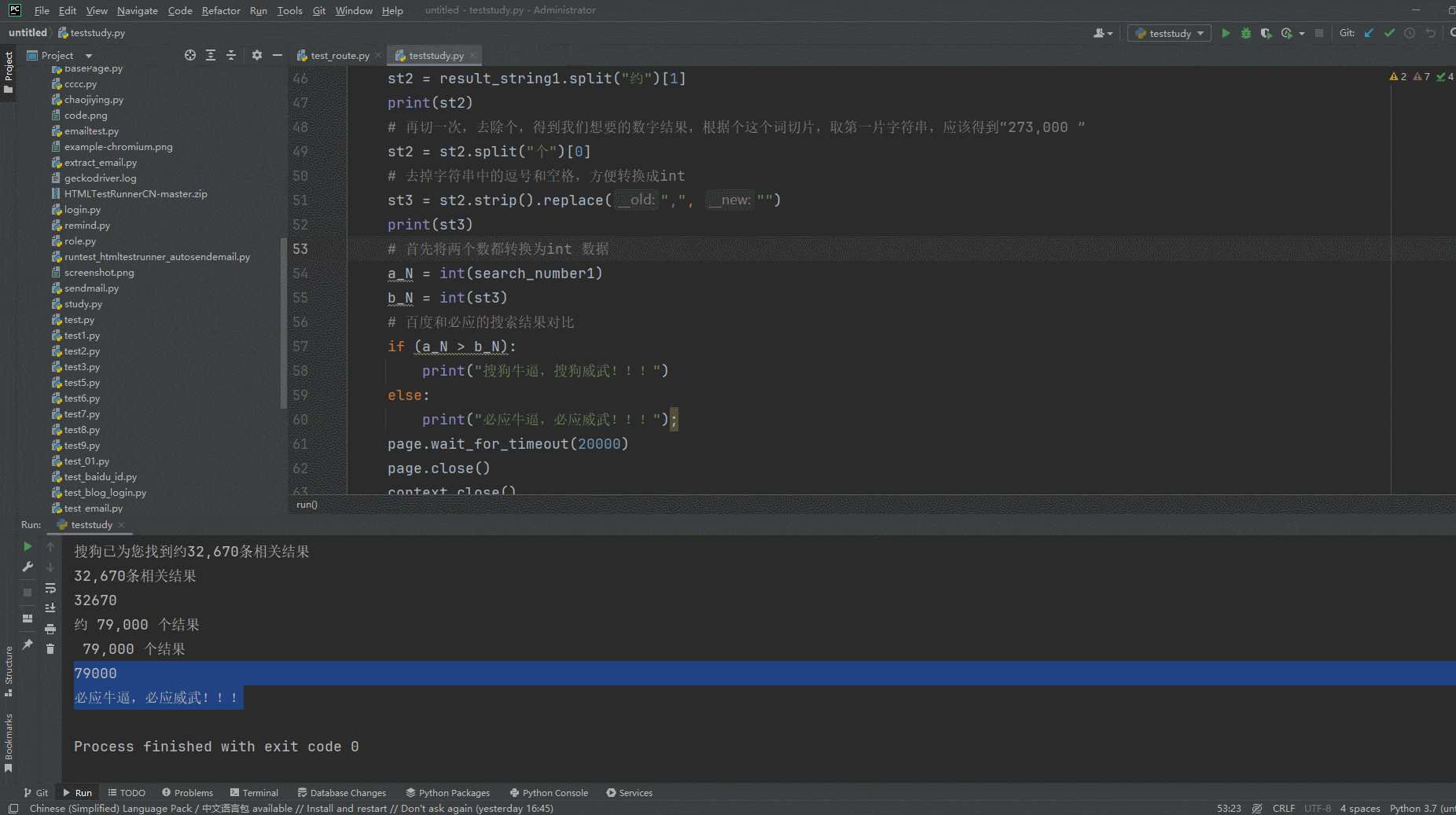
if (a_N > b_N):
print("搜狗牛逼,搜狗威武!!!")
else:
print("必应牛逼,必应威武!!!");
page.wait_for_timeout(20000)
page.close()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
4.4运行代码
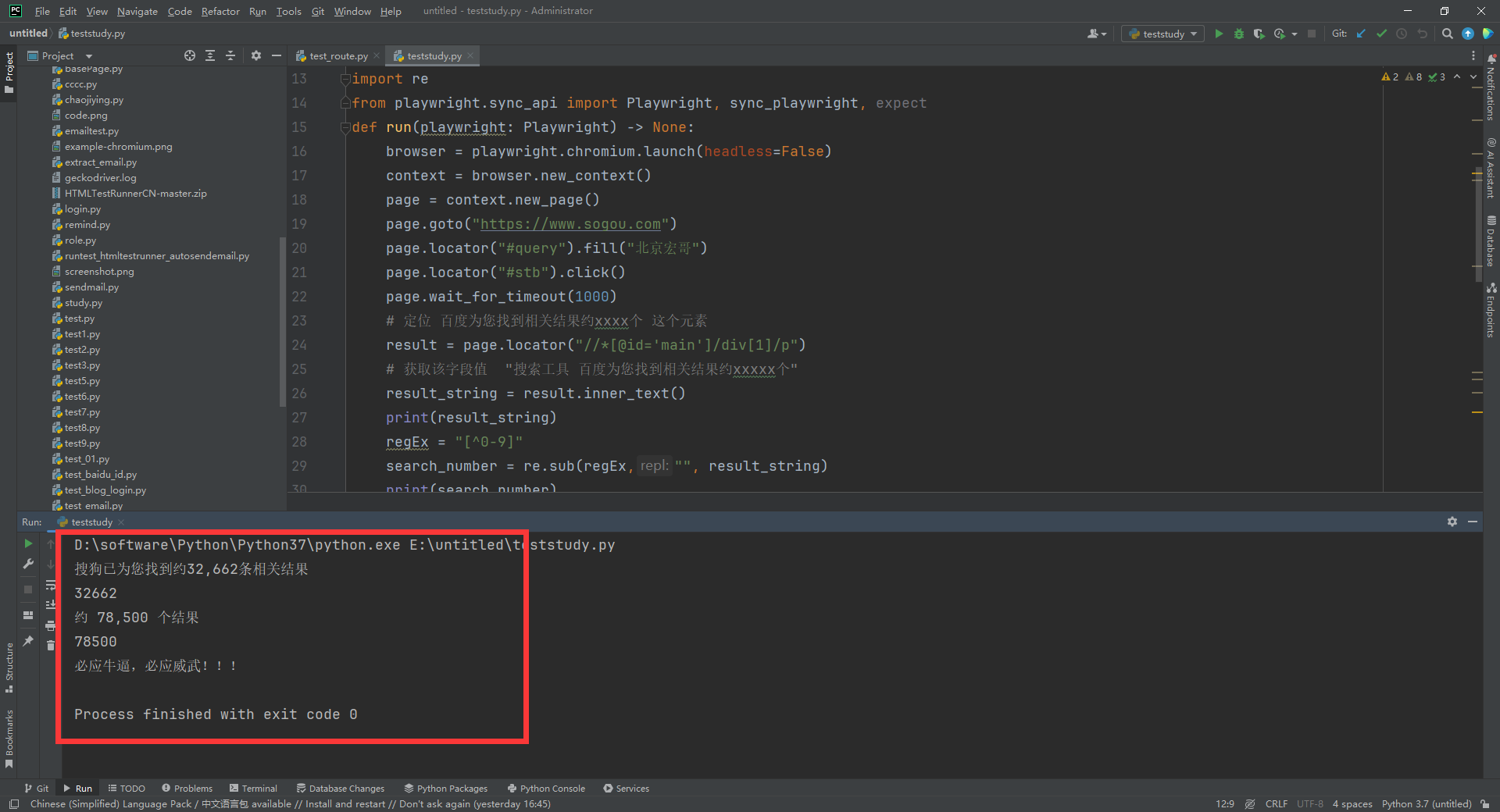
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作。如下图所示:
5.小结
好了,关于字符串的操作,宏哥就介绍到这里,其实两种方法各有千秋,如果其中一种不太合适或者不好用,不妨换另一种方法试一下,没准就成功了。不要钻牛角尖,一条道走到黑哈。还有就是正则表达式的语法,自己去查一下,看一下,半个小时就可以掌握的差不多了,然后要注意实践啊,不然吃一顿饭就忘记了。
每天学习一点,今后必成大神-
往期推荐(由于跳转参数丢失了,所有建议选中要访问的右键,在新标签页中打开链接即可访问)或者微信搜索: 北京宏哥 公众号提前解锁更多干货。
Appium自动化系列,耗时80天打造的从搭建环境到实际应用精品教程测试
Python接口自动化测试教程,熬夜87天整理出这一份上万字的超全学习指南
Python+Selenium自动化系列,通宵700天从无到有搭建一个自动化测试框架
Java+Selenium自动化系列,仿照Python趁热打铁呕心沥血317天搭建价值好几K的自动化测试框架
Jmeter工具从基础->进阶->高级,费时2年多整理出这一份全网超详细的入门到精通教程

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









