









 本文探讨了如何处理Python中带有特殊unicode转义序列的字符串。通过实例演示了解码和编码的过程,并介绍了一种有效的处理unicode存储的方法,即使用unicode-escape进行编码存储,在读取时再进行转换。
本文探讨了如何处理Python中带有特殊unicode转义序列的字符串。通过实例演示了解码和编码的过程,并介绍了一种有效的处理unicode存储的方法,即使用unicode-escape进行编码存储,在读取时再进行转换。
有一串编码如下:
s='\u871c\u7c89/\u6563\u7c89'
查看类型,为str:
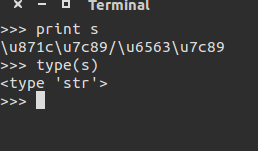
按utf-8先解码在编码依然不行。
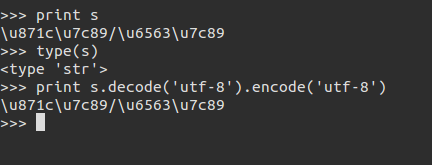
最后,参考水木清华的一篇帖子
可以这么做:
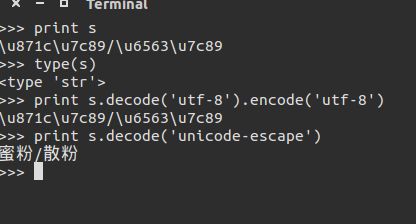
那么问题来了,这个unicode-escape什么来的呢
在python中,对于unicode存储时,可以采用另一种方法:
将unicode的内存编码值进行存储,读取文件时在反向转换回来。这里就采用了unicode-escape的方式
对string存储,python也可以采用相类似的方式,详细的见下面的
这个博文

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









