







目前正在学习《自然语言处理入门》这本书,第二章 词典分词部分涉及字典树的内容较多,在字典树的基础上又介绍了首字散列其余二分的字典树、双数组字典树、AC自动机,越往后难度越大越难理解,因此理解字典树非常重要,所以参考原书代码和网上代码,敲了一遍首字散列其余二分的字典树的python实现代码,目的在于加深对字典树的理解。
算法和概念部分可学习参考资料2,此处不再赘述。
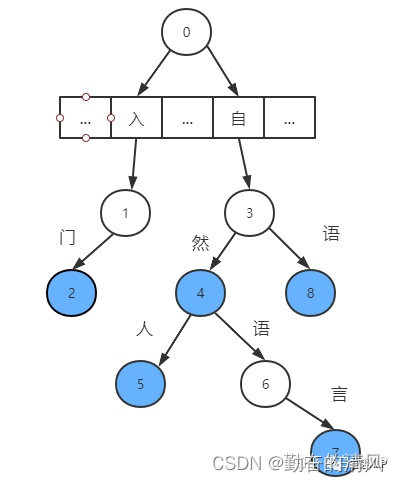
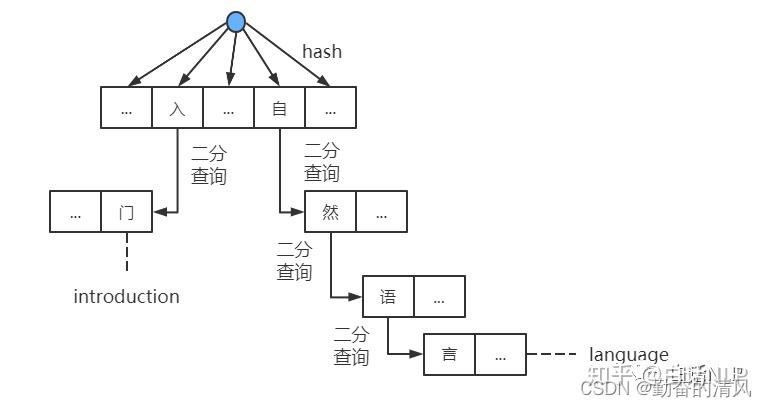
首字散列其余二分的字典树结构示意图:
# Author: 勤奋的清风
# Date: 2022-05-18
# BinTrie.py
def char_hash(char, length=5):
# 由于python没有字符类型,而字符串hash code长度为64位,将其截取五位
return abs(hash(char)) % (10 ** length)
class Node(object):
def __init__(self, key, value=None):
self._children = [] # 子节点为数组
self._key = key # 节点代表的值
self._value = value # 节点值
def __getitem__(self, key):
if not self._children:
return None
idx = self.binary_search(self._children, key)
if idx < 0:
return None
return self._children[idx]
def compareTo(self, other):
"""比较字符hash值大小"""
if type(other) != str:
other = other._key
if self._key < other:
return -1
elif self._key > other:
return 1
return 0
@staticmethod
def binary_search(branches, node):
"""
二分查询
:param branches: 子节点数组
:param node: 节点或字符
:return: 返回节点位置
"""
high = len(branches) - 1
if high < 0:
return high
low = 0
while low <= high:
mid = (low + high) >> 1
cmp = branches[mid].compareTo(node)
if cmp < 0:
low = mid + 1
elif cmp > 0:
high = mid - 1
else:
return mid
return -(low + 1)
def _add_child(self, node):
idx = self.binary_search(self._children, node)
if idx >= 0:
# 找到相同节点
target = self._children[idx]
target._value = node._value
return target
else:
# 未找到相同节点
insert = -(idx + 1)
self._children = self._children[:insert] + [node] + self._children[insert:]
return self._children[insert]
class BinTrie(object):
def __init__(self):
self._size = 0
self._children = [None] * 100000
def __setitem__(self, key, value):
state = self
for i, char in enumerate(key):
if i == 0: # 第一层:hash查询
idx = char_hash(char)
if i < len(key) - 1: # 不是词语的最后一个字
target = state._children[idx]
if target is None: # 该位置不存在节点,需创建新节点
node = Node(char, None)
self._children[idx] = node
state = node
else: # 该位置存在节点,直接返回
state = target
else: # 词语最后一个字
node = Node(char, None)
self._children[idx] = node
state = node
else: # 非第一层:二分查询
if i < len(key) - 1: # 不是词语的最后一个字
target = state[char]
if target is None: # 该位置不存在节点,需创建新节点
state = state._add_child(Node(char, None))
else: # 该位置存在节点,直接返回
state = target
else: # 词语最后一个字
state = state._add_child(Node(char, value))
def __getitem__(self, key):
state = self
for i, char in enumerate(key):
if i == 0: # 首层:hash查询
state = state._children[char_hash(char)]
else:
state = state[char]
if state is None:
return None
return state._value
def __contains__(self, key):
return self[key] is not None
if __name__ == '__main__':
trie = BinTrie()
# 增
trie['自然'] = 'nature'
trie['自然人'] = 'human'
trie['自然语言'] = 'language'
trie['自语'] = 'talk to oneself'
trie['入门'] = 'introduction'
assert '自然' in trie
print(trie['自然'])
# 删
trie['自然'] = None
print(trie['自然'])
assert '自然' not in trie
# 改
trie['自然语言'] = 'human language'
assert trie['自然语言'] == 'human language'
print(trie['自然语言'])
# 查
assert trie['入门'] == 'introduction'
print(trie['入门'])
参考资料:
[1] 《自然语言处理入门》——何晗 著
[2] 手把手教学 | 双数组字典树
以上,欢迎批评、指正、交流~















 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









