







有一个更加详细的讲解: http://www.cnblogs.com/skywang12345/p/3308807.html
先对LinkedList的特性进行一个概述:
(1)LinkedList底层实现为双向循环链表。链表的特点就是插入删除数据快,而查询数据慢。
(2)因为使用链表的原因,所以不存在容量不足的问题,没有扩容机制。
(3)从后面的源码分析中我们也可以看出,LinkedList支持null并且LinkedList没有同步机制。
(4)LinkedList直接继承于AbstractSequentialList,同时实现了List接口,也实现了Deque接口。
AbstractSequentialList为顺序访问的数据存储结构提供了一个骨架类实现,如果要支持随机访问,则优先选择AbstractList类继承。LinkedList 基于链表实现,因此它继承了AbstractSequentialList。本文原创,转载请注明出处:http://blog.csdn.net/seu_calvin/article/details/53012654
1. LinkedList数据存储格式
上面也提到了,LinkedList底层实现为双向链表,下面是某个Node节点的存储模型,包含上一个节点,下一个节点,以及自己的信息。
下面我们分析一个LinkedList的add()操作,可以帮助我们理解LinkedList的双向链表的实现原理。
2. LinkedList的add操作
上面是根据index进行的LinkedList的add操作,首先会判断index是否合法,再判断是不是将该节点插入到链表的最后,最后才是进行链表的中间插入操作。
2.1 链表尾部add
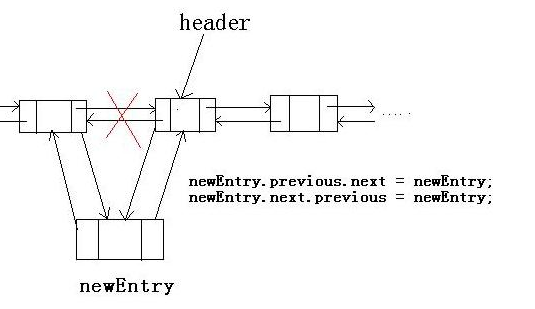
在linkLast()方法中,首先会生成一个新的Node节点,然后将这个新的末尾节点赋值给last节点,如果l为null,说明是第一次加入数据,就将这个节点置为first节点,代表链表中第一个有数据的节点,否则将上一个节点的next指向这个节点。
说到第一个节点和最后一个节点,LinkedList提供给了我们具体的方法进行这两个特殊位置的数据获取:
2.2 链表中间add
中间插入节点调用了linkBefore(element,node(index))方法,那么首先分析一下node(index)的逻辑:
首先判断index值是不是小于整个链表长度的一半,整个if/else逻辑是在判断要插入的位置是距离链表头近还是链表尾近,目的更快的找到原来index处的节点并返回。接下来就是linkBefore()方法:
pred 是当前要插入位置节点的上一个节点,即图中的第一个节点。newNode 将要插入的对象包装成node节点(指定上一个节点为pred,下一个节点为node()返回值succ)。
接着将succ节点的上一个节点指定为我们的新节点newNode。那么肯定会有逻辑将pred的next设置为newNode。
果然,最后做了一个判断,如果pred为null,说明succ节点为第一个有数据的节点,就将生成的新节点newNode置为first节点,否则指定上个节点的下一个节点为生成的新节点,即pred.next = newNode。
这样就完成了整个链表数据插入过程。显然是不同于ArrayList那样地进行数组复制。
3. LinkedList的get操作
get操作就比较简单了,对链表进行遍历,直接找到node节点,返回item数据即可。
4. ArrayList和LinkedList的比较
4.1 ArrayList和LinkedList的相同点
(1)两者均不是线程安全的。
(2)两者都支持null值。
(3)都实现了List接口。
4.2 ArrayList和LinkedList的不同点
(1)LinkedList 基于链表实现,便于顺序访问,它继承了AbstractSequentialList。而ArrayList支持随机访问,继承了AbstractList类。
(2)因为LinkedList 是基于链表的,因此不像ArrayList需要扩容机制。
(3)各种操作的性能对比:对于ArrayList来说,得益于快速随机访问的特性,获取任意位置元素是比较有效率的。如果是add或者remove操作,要分两种情况,如果是在ArrayList尾部做add,是不需要移动其他元素,耗时是O(1)。但如果在中间插入新元素的话,耗时是O(n-index)。另外,当ArrayList扩容时,会自动生成一个新的array(长度是之前的1.5倍),再将旧的array移值上去,耗时是O(n)。为了确保本文正确性,博主会在发现某部分有不妥描述时及时修改,请确保您看到的是原文,原文链接为SEU_Calvin的博客。
因此,ArrayList的get操作快一些,而add操作,若add的位置为List中间,肯定是LinkedList要快一些,尾部的话两者差不多。具体使用哪个需要分场景选择最合适的。















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









