









文章目录
ELK介绍与部署
通俗来讲,ELK 是由 Elasticsearch、Logstash、Kibana 三个开源软件的组成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称为 ELK stack,官方域名为 stactic.co,ELK stack 的主要优点有如下几个:
处理方式灵活:elasticsearch是实时全文索引,具有强大的搜索功能
配置相对简单:elasticsearch全部使用 JSON 接口,logstash 使用模块配置,kibana 的配置文件部分更简单。
检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
集群线性扩展:elasticsearch 和 logstash 都可以灵活线性扩展
前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单ELK使用场景:
日志平台:利用elasticsearch的快速检索功能,在大量的数据当中可以快速查询需要的日志。
订单平台:利用elasticsearch的快速检索功能,在大量的订单当中检索我们所需要的订单。
搜索平台:利用elasticsearch的快速检索功能,在大量的数据中检索出我们所需要的数据。
ELK 常用架构及使用场景介绍:
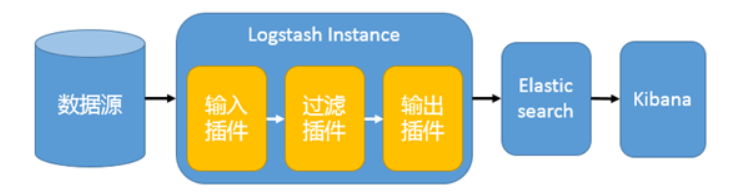
1)简单架构
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作;在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
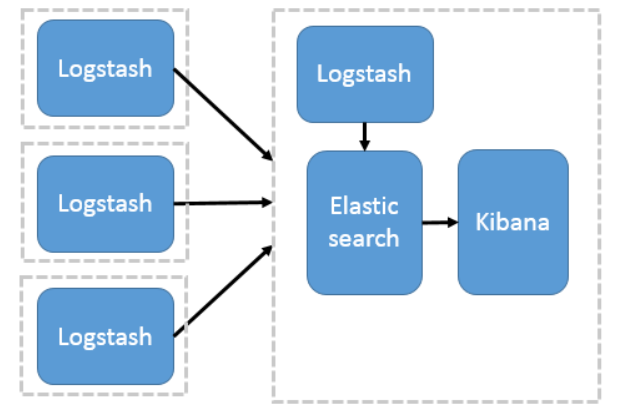
2)以Logstash 作为日志搜集器
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
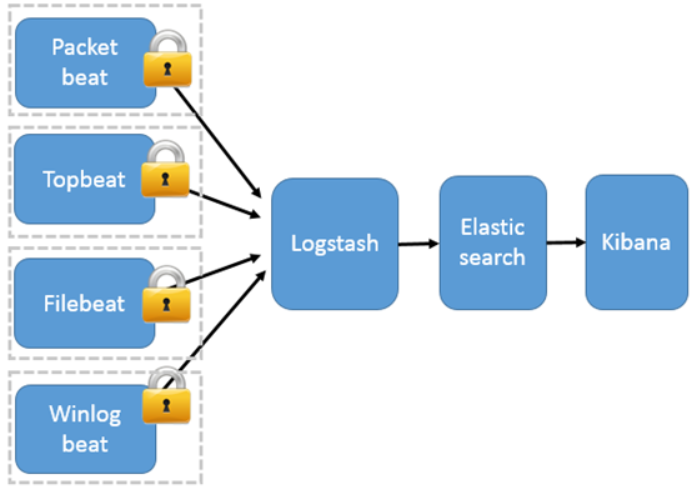
3)以Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
- Packetbeat(搜集网络流量数据);
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
- Filebeat(搜集文件数据);
- Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
4)引入消息队列模式
Beats 还不支持输出到消息队列(新版本除外:5.0版本及以上),所以在消息队列前后两端只能是 Logstash 实例。logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
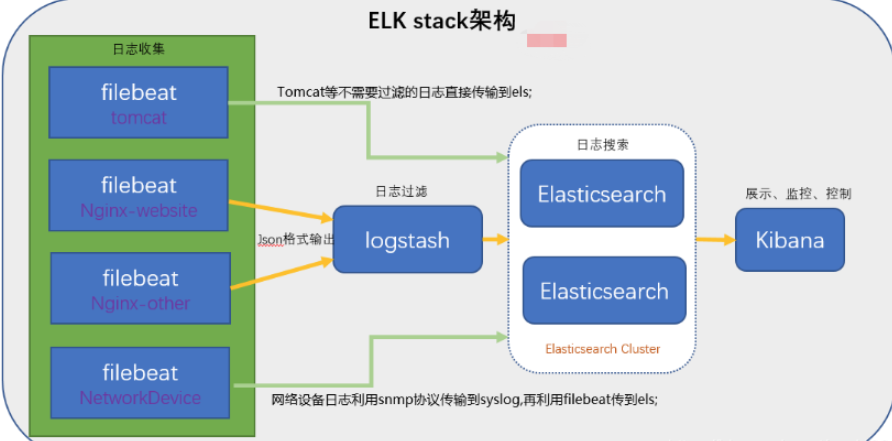
模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题
工作流程:Filebeat采集—> logstash转发到kafka—> logstash处理从kafka缓存的数据进行分析—> 输出到es—> 显示在kibana
Elasticsearch单节点部署
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比如 Nginx、Tomcat、系统日志等功能。
ElasticSearch
ElasticSearch:数据搜索引擎
单节点部署
一般部署elasticsearch有三种方式:
rpm包安装
源码包安装
docker安装
ElasticSearch官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
官网其他版本安装包下载地址 :https://www.elastic.co/cn/downloads/past-releases#elasticsearch
官方文档参考:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
1.安装
- 单节点规划
| 主机名 | 外网IP | 内外IP | 内存 | 硬盘 | |
|---|---|---|---|---|---|
| es-01 | 192.168.15.70 | 172.16.1.70 | 2G及以上 | 30G及以上 | 主节点 |
- 系统优化
# 关闭selinux
getenforce 0
# 关闭防火墙
systemctl disable --now firewalld
# 关闭NetworkManager
systemctl disable --now NetworkManager
# 设置一下时区
timedatectl set-timezone Asia/Shanghai
# 同步时间
ntpdate time.nist.gpv
# 设置程序可以打开的文件数,可清空后再新加
cat > /etc/security/limits.conf <<EOF
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 131072
* hard nofile 131072
EOF
# 需重启系统
reboot
- 以下有三中安装方式
1)rpm安装
# 下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.1-x86_64.rpm
yum localinstall -y elasticsearch-7.12.1-x86_64.rpm
# elasticsearch是依赖于Java
yum install java-1.8.0* -y
# 验证Java
[root@es-01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
2)源码包安装
# 下载源码包
wget https://github.com/elastic/elasticsearch/archive/refs/tags/elasticsearch-7.12.1-linux-x86_64.tar.gz
# 解压
tar xf elasticsearch-7.12.1-linux-x86_64.tar.gz -C /usr/local/
# elasticsearch是依赖于Java
yum install java-1.8.0* -y
# 验证Java
[root@es-01 ~]# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
3)docker安装
- cluster.name:集群名
docker run -p 9200:9200 -p 9300:9300 -e "cluster.name=[集群名]" docker.elastic.co/elasticsearch/elasticsearch:7.12.1
2.配置
1)开启内存锁定
- elastcsearch设置内存锁定
vim /usr/lib/systemd/system/elasticsearch.service
# 在 [Service] 下面增加
LimitMEMLOCK=infinity
# 重载
systemctl daemon-reload
- 查看完整配置文件内容(源码包安装的默认没有)
[root@es-01 ~]# cat /usr/lib/systemd/system/elasticsearch.service
[Unit]
Description=Elasticsearch
Documentation=https://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
LimitMEMLOCK=infinity
Type=notify
RuntimeDirectory=elasticsearch
PrivateTmp=true
Environment=ES_HOME=/usr/share/elasticsearch
Environment=ES_PATH_CONF=/etc/elasticsearch
Environment=PID_DIR=/var/run/elasticsearch
Environment=ES_SD_NOTIFY=true
EnvironmentFile=-/etc/sysconfig/elasticsearch
WorkingDirectory=/usr/share/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStart=/usr/share/elasticsearch/bin/systemd-entrypoint -p ${PID_DIR}/elasticsearch.pid --quiet
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65535
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
# Allow a slow startup before the systemd notifier module kicks in to extend the timeout
TimeoutStartSec=75
[Install]
WantedBy=multi-user.target
# Built for packages-7.12.1 (packages)
2)定义内存大小值
- 修改elasticsearch锁定内存大小
- 最大锁定内存与最小锁定内存一般设为一致
vim /etc/elasticsearch/jvm.options
# 最大锁定内存
-Xms1g
# 最大锁定内存
-Xmx1g
3)修改es配置文件
- 清空文件,copy即可,注意节点名称需要修改~
[root@es-01 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es-01 ~]# grep -E '^[^#]' /etc/elasticsearch/elasticsearch.yml
# # 设置集群名称
cluster.name: Peng-by-es
# # 设置集群节点名称(节点名称在集群中唯一)
node.name: Peng-node-01
# # 设置数据存放目录
path.data: /var/lib/elasticsearch
# # 设置日志存放目录
path.logs: /var/log/elasticsearch
# # 设置内存锁定
bootstrap.memory_lock: true
# # 设置监听的IP,可监听所有
network.host: 0.0.0.0
# # 设置监听的端口
http.port: 9200
# # 开启跨域功能
http.cors.enabled: true
http.cors.allow-origin: "*"
# # 设置主节点(单台可不设置)
cluster.initial_master_nodes: ["172.16.1.71"]
# # 设置参与选举master的策略
discovery.zen.minimum_master_nodes: 2
# # 设置节点(所有)
discovery.zen.ping.unicast.hosts: ["172.16.1.70","172.16.1.71"]
# # 是否具备参与选举为master节点的资格
node.master: true
- 不同节点需修改的内容
# 设置集群节点名称(节点名称在集群中唯一)
node.name: Peng-node-01
4)配置图形化管理界面
- 此小结仅需主节点执行即可,可通过一个容器来管理多个节点
- 需利用docker配置安装集群head插件,此步骤需在第5步测试访问后执行
- docker安装,可配置安装集群head插件,主要是有图形化elastic search
# 安装docker
yum remove docker docker-common docker-selinux docker-engine -y
sudo yum install -y gcc gcc-c++ yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum clean all
yum makecache
yum install docker-ce -y
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xj6uu5rz.mirror.aliyuncs.com"]
}
EOF
# 启动docker
systemctl start --now docker
# 拉取运行图形化管理界面镜像
docker run -d -p 9100:9100 alvinos/elasticsearch-head
# 可通过图形界面访问了,添加主从后,可通过它来管理
http://192.168.12.71:9100 # 图形化管理界面
4.启动
# 启动
systemctl start elasticsearch.service
# 可监控启动日志
[root@es-01 ~]# tailf /var/log/elasticsearch/Peng-by-es.log
# 检测启动端口
[root@es-01 ~]# netstat -lntp | grep java
tcp6 0 0 :::9200 :::* LISTEN 2865/java
tcp6 0 0 :::9300 :::* LISTEN 2865/java
5.测试访问
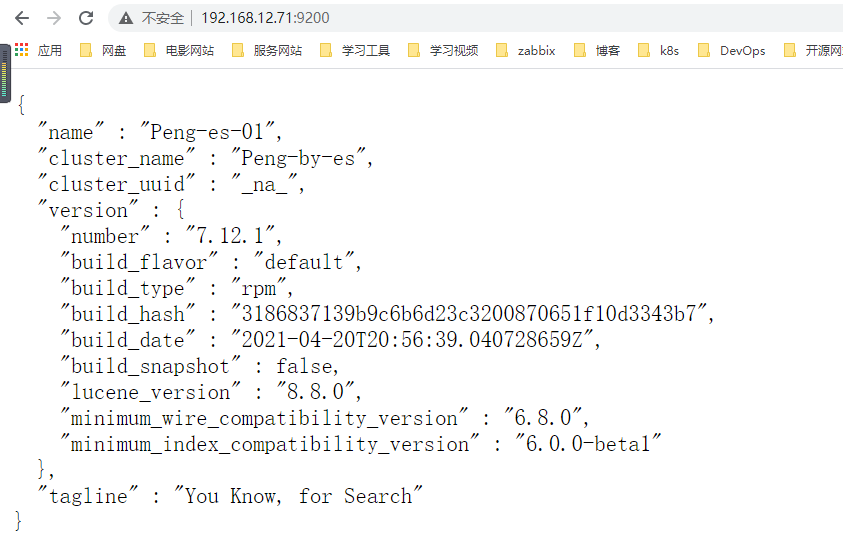
- 测试是否能够正常对外提供服务,通过IP+9200端口访问
http://192.168.12.71:9200
http://192.168.12.71:9100 # 图形化管理界面

多节点部署(部署主从)
elasticsearch是主从数据节点分离的,按照节点还可以分为热数据节点和冷数据节点。
- 集群节点规划
| 主机名 | 外网IP | 内外IP | 内存 | 硬盘 | |
|---|---|---|---|---|---|
| es-01 | 192.168.15.70 | 172.16.1.70 | 2G及以上 | 30G及以上 | 主节点 |
| es-02 | 192.168.15.71 | 172.16.1.71 | 2G及以上 | 30G及以上 | 从节点 |
部署主节点es01
- 参考上述单节点部署(包括优化),略 ~
部署从节点es-02
- 参考上述单节点部署(包括优化),略 ~
- 修改配置文件
1.把主节点的拉过来,进行以下修改(主节点也也要修改部分内容)
scp 192.168.12.71:/etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/
2.设置集群节点名称(节点名称在集群中唯一)
node.name: Peng-node-02
================================================================================
解释:
node.name: es-01 # 不参与选举为master节点
node.data: true # 不会存储数据
生产中环境中参考配置:
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求;
生产中建议集群中设置3台以上的节点作为master节点【node.master: true node.data: false】;
这些节点只负责成为主节点,维护整个集群的状态;
再根据数据量设置一批data节点【node.master: false node.data: true】。
启动
systemctl start elasticsearch.service
PS:
做到这一步极其容易出现数据不一致的问题,反应到登录网页上就上明明好像能正常访问,其实它的的UUTD是错误的,中间若启动错误,并检查配置文件是否配置错误,进行重启。
解决方法:
rm -rf /var/lib/elasticsearch/*
systemctl restart elasticsearch.service
- 测试访问
http://192.168.12.71:9200
http://192.168.12.72:9200
http://192.168.12.71:9100 # 图形化管理界面
Peng-node-01 # 主节点
Peng-node-01 # 从节点
- 出现此页面即为添加索引成功
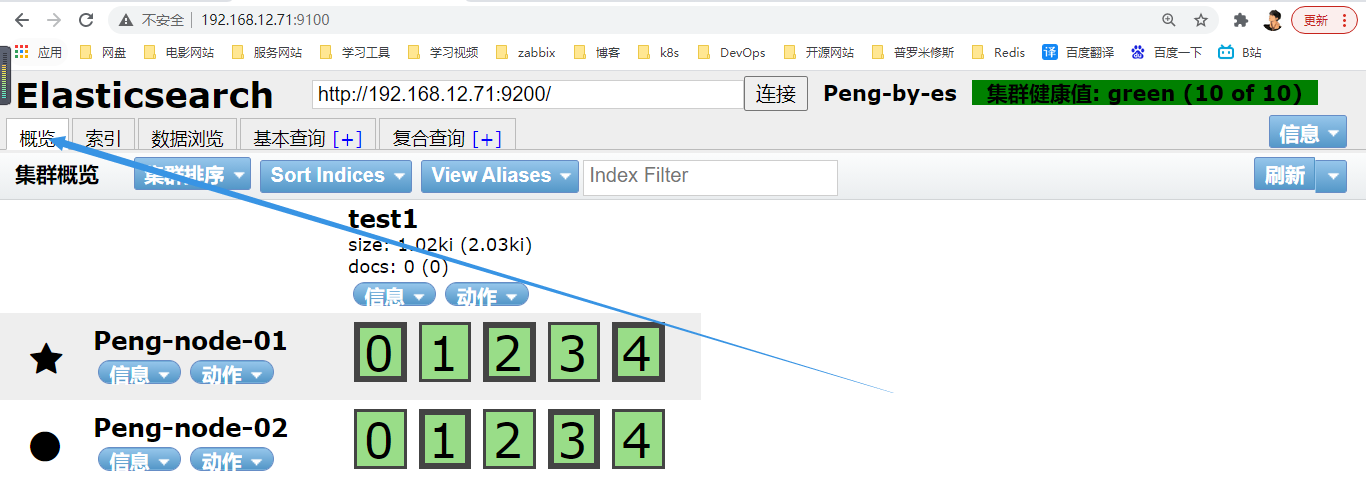
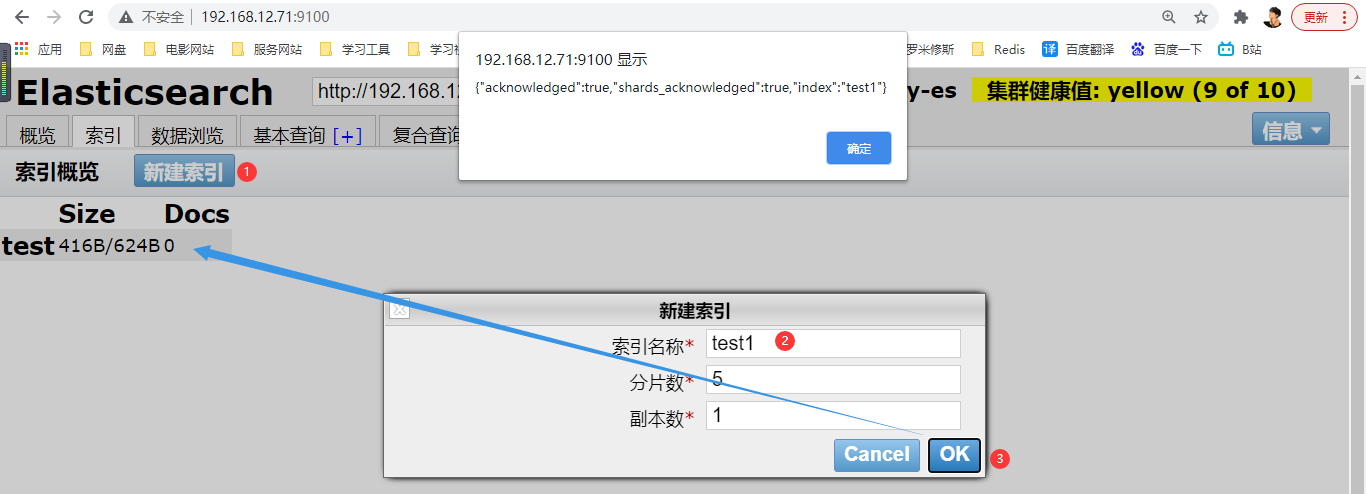
- 若要追加索引信息,可点击复合查询继续编辑、提交(别忘记勾选POST)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gGzMji29-1632278713442)(https://i.loli.net/2021/05/09/dtXCgF1umcj7WOS.png)]
- 测试集群性能(已经创建一个索引)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2UndyNuK-1632278713443)(1620443366552.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dXg7Y6Mw-1632278713444)(D:%5C@%E4%B8%AA%E4%BA%BA%E8%B5%84%E6%96%99%5CLinux%5C%E5%AD%A6%E4%B9%A0%5C10-ELK-%E9%99%88%E9%98%B3%5Cday01%5C%E7%AC%94%E8%AE%B0%5C1620443389847.png)]
-
Elasticsearch监控分析
-
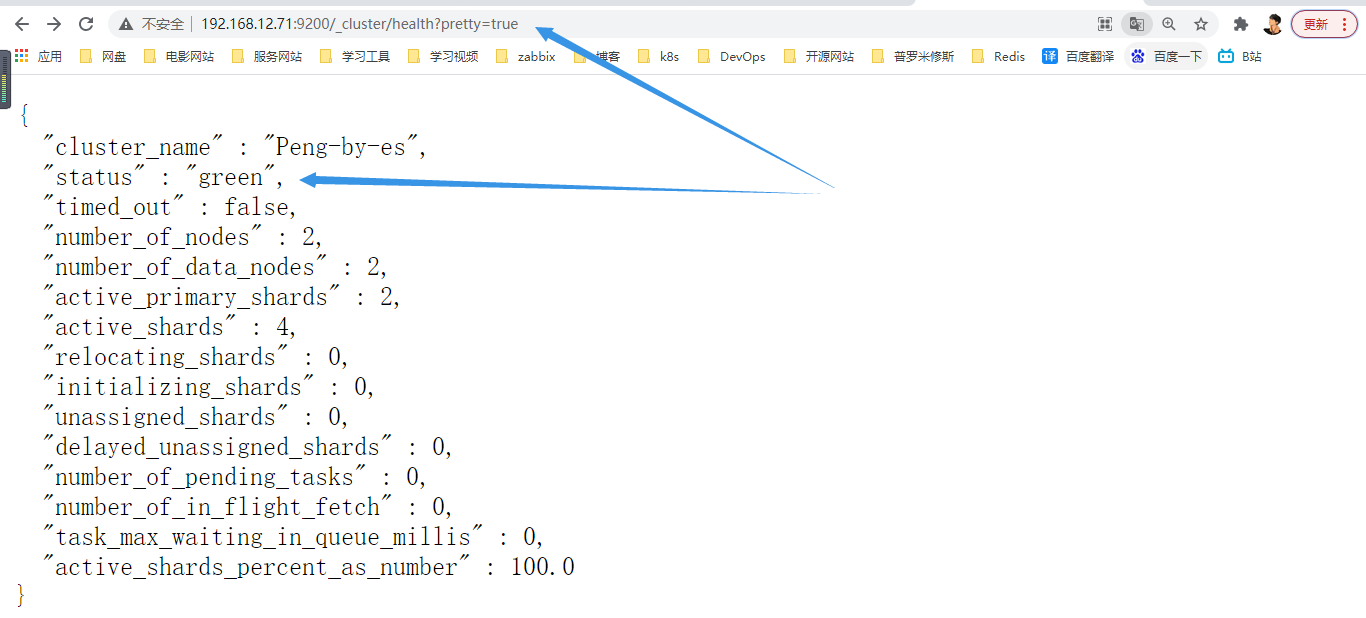
通过浏览器访问:http://192.168.12.72:9200/_cluster/health?pretty=true,例如对 status 进行分析:
- green(绿色)就是运行在正常
- yellow(黄色)表示副本分片丢失
- red(红色)表示主分片丢失
LogStach
LogStach:数据收集引擎
Logstash 是一个开源的数据收集引擎,可以水平伸缩,而且 logstash 整个 ELK 当中拥有最多插件的一个组件,其可以接收来自不同来源的数据并统一输出到指定的且可以是多个不同目的地。
部署LogStach
- 所有节点
部署logstach分别有三种方式:
1、rpm包安装
2、源码包安装
3、docker安装
rpm安装
# 下载安装包
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-x86_64.rpm
yum localinstall -y logstash-7.12.1-x86_64.rpm
# 对数据目录设置权限
chown -R logstash. /usr/share/logstash/
使用logstach
输出
- 输入输出到shell控制台
[root@es-01 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug }}'
# 执行上述命令后,会打印出此内容,输入什么,则会打印什么
[INFO ] 2021-05-10 15:51:49.483 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
你好啊 # 输入一个你好啊,则会标准输出到屏幕
{
"@timestamp" => 2021-05-10T07:52:15.881Z,
"host" => "es-01",
"@version" => "1",
"message" => "你好啊"
}
# 使用json,
{"message":"","@version":"1","@timestamp":"2021-05-10T07:55:07.833Z","host":"es-01"}hello
{"message":"hello","@version":"1","@timestamp":"2021-05-10T07:55:09.632Z","host":"es-01"}
- logstach输出到文件当中
[root@es-01 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { file { path => "/tmp/log-%{+YYYY.MM.dd}-messages.log"}}'
pipelines=>[:main], :non_running_pipelines=>[]}
你好呀
# 查看文件内容
[root@es-01 ~]# cat /tmp/log-2021.05.10-messages.log
{"@version":"1","message":"你好呀","@timestamp":"2021-05-10T08:20:21.816Z","host":"es-01"}
- logstach输出到elasticsearch当中
[root@es-01 ~
]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch {hosts => ["172.16.1.71:9200"] index => "mytest-%{+YYYY.MM.dd}" }}'
The stdin plugin is now waiting for input:
;[INFO ] 2021-05-12 18:53:47.182 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
你好,Elasticsearch!
qq
你好,Elasticsearch!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B1b018LY-1632278713445)(https://i.loli.net/2021/05/12/x6rkl92IWAaLSzP.png)]
- logstach输出到redis当中
[root@es-01 ~]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output {redis { host => "172.16.1.71" port => "6379" data_type => "list" key => "logstash-%{type}" }}'
The stdin plugin is now waiting for input:
[INFO ] 2021-05-12 18:06:37.744 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
hello redis!
不错哦~
[root@es-01 ~]# redis-cli --raw
127.0.0.1:6379> KEYS *
logstash-%{type}
127.0.0.1:6379> lrange logstash-%{type} 0 -1
{"@timestamp":"2021-05-12T10:06:51.509Z","@version":"1","host":"es-01","message":"hello redis!"}
{"@timestamp":"2021-05-12T10:08:38.769Z","@version":"1","host":"es-01","message":"不错哦~"}
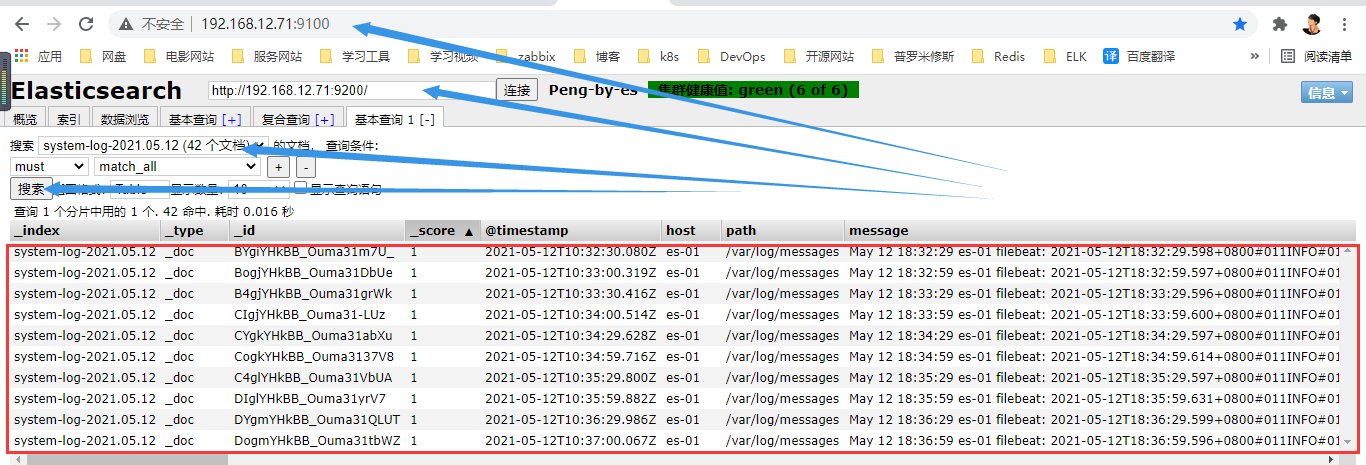
读取
- logstach读取日志文件
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { file { path => "/var/log/messages" } } output { elasticsearch {hosts => ["172.16.1.70:9200"] index => "system-log-%{+YYYY.MM.dd}" }}'
- 在标准输出中读取
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch {hosts => ["172.16.1.70:9200"] index => "system-stdin-%{+YYYY.MM.dd}" }}'
分类
- 从多个文件中读取文件
path => "/var/log/messages" #日志路径
type => "systemlog" #事件的唯一类型
start_position => "beginning" #第一次收集日志的位置
stat_interval => "3" #日志收集的间隔时间
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e 'input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { elasticsearch {hosts => ["172.16.1.70:9200"] index => "system-stdin-%{+YYYY.MM.dd}" }}'
- 分类输出多个数据仓库
[root@es-01 /opt]# /usr/share/logstash/bin/logstash -e '`input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { if [type] == "systemlog" { elasticsearch {hosts => ["172.16.1.71:9200"] index => "system-systemlog-%{+YYYY.MM.dd}" }} if [type] == "systemcron" { elasticsearch {hosts => ["172.16.1.71:9200"] index => "system-systemcron-%{+YYYY.MM.dd}" } } }`'
- 使用配置文件
# 将单引号内的数据拷贝到test.conf内
[root@es-01 ~]# cat test.conf
input { file{ path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "3" } file{ path => "/var/log/cron" type => "systemcron" start_position => "beginning" stat_interval => "3" } } output { if [type] == "systemlog" { elasticsearch {hosts => ["172.16.1.71:9200"] index => "system-systemlog-%{+YYYY.MM.dd}" }} if [type] == "systemcron" { elasticsearch {hosts => ["172.16.1.71:9200"] index => "system-systemcron-%{+YYYY.MM.dd}" } } }
# 测试配置文件
[root@es-01 ~]# /usr/share/logstash/bin/logstash -f test.conf -t

# 使用配置文件
[root@es-01 ~]# /usr/share/logstash/bin/logstash -f test.conf
# 测试OK
[INFO ] 2021-05-12 22:22:20.822 [LogStash::Runner] runner - Using config.test_and_exit mode. Config Validation Result: OK. Exiting Logstash
kibana
Kibana 是一个通过调用 elasticsearch 服务器进行图形化展示搜索结果的开源项目。
部署kibana
1.下载安装
# 下载安装包
[root@es-01 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.12.1-x86_64.rpm
[root@es-01 ~]# yum localinstall kibana-7.12.1-x86_64.rpm
2.配置启动
#修改配置
[root@es-01 ~]# vim /etc/kibana/kibana.yml
# 打开注释并修改
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://172.16.2.71:9200"]
# 启动
[root@es-01 ~]# systemctl start --now kibana.service
[root@es-01 ~]# netstat -lntp | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 18230/node
访问:192.168.12.71:5601
# 若访问报错:Kibana server is not ready yet
# 报错原因:可能是修改配置文件错误,重启后产生了kibana索引数据,需删除后重启
解决方法:
1. 停止kibana
systemctl stop kibana
2. 删除kibana索引
curl -XDELETE http://localhost:9200/.kibana*
3. 启动kibana
systemctl start kibana
3.新增数据源
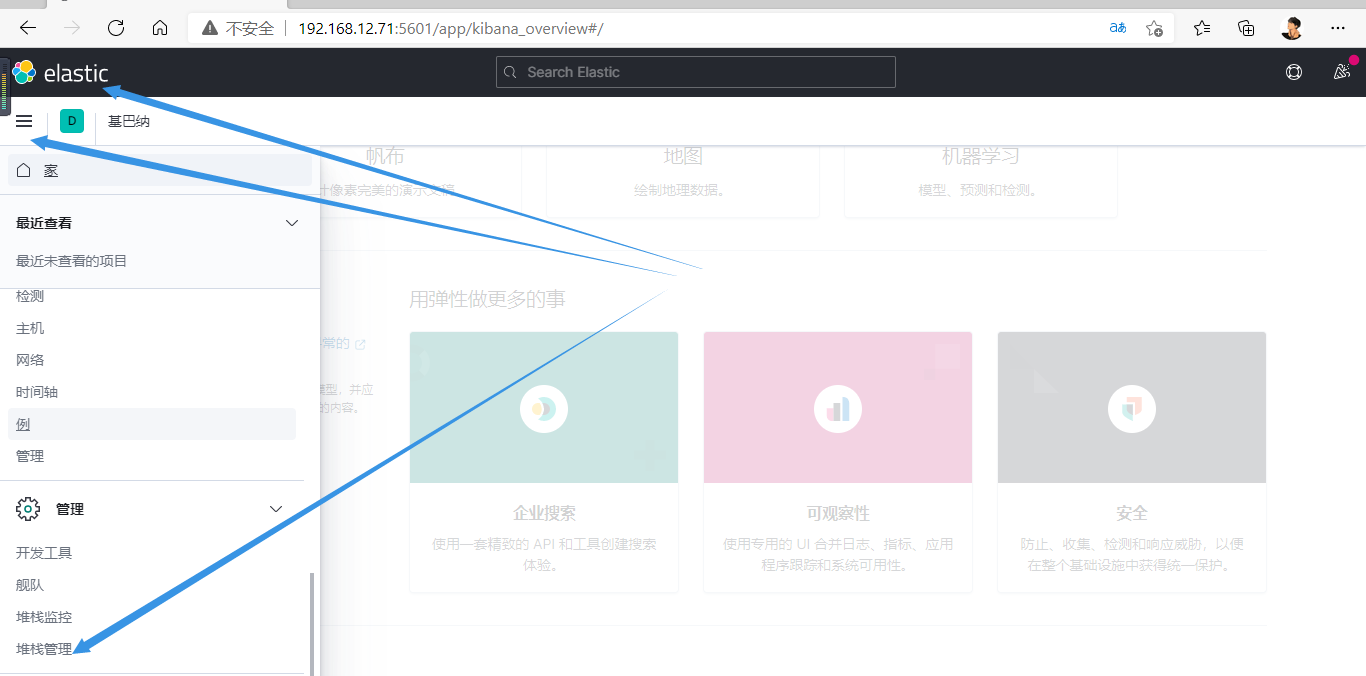
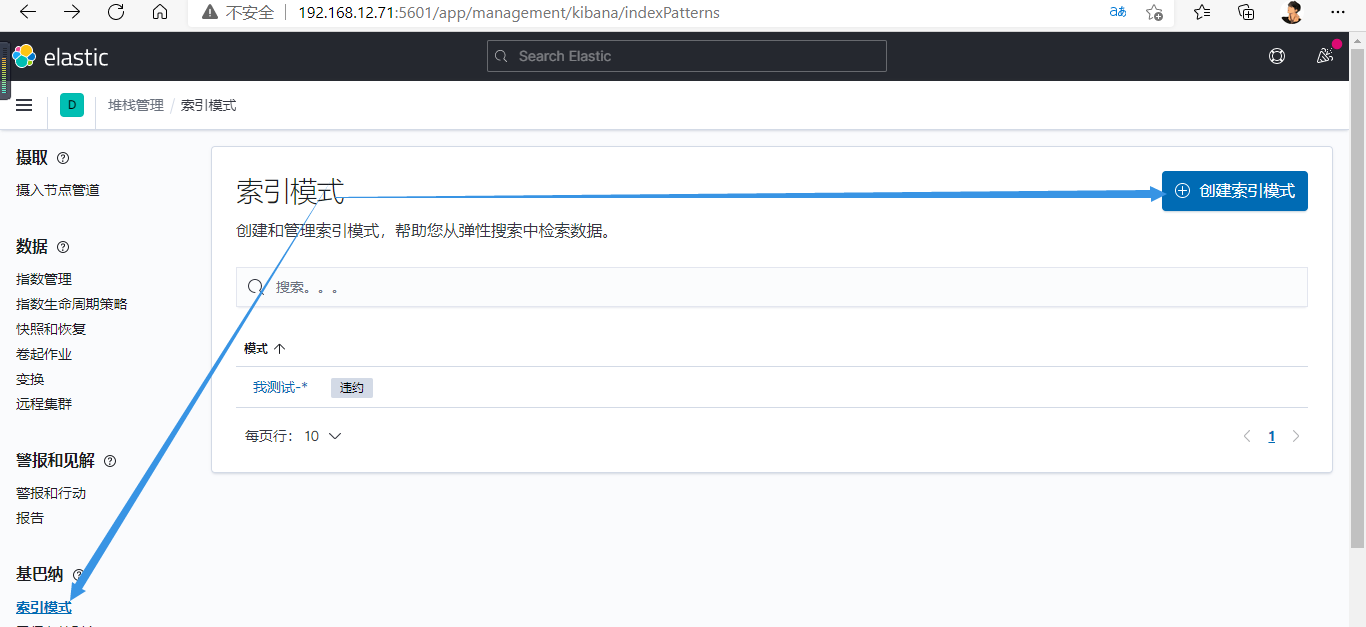
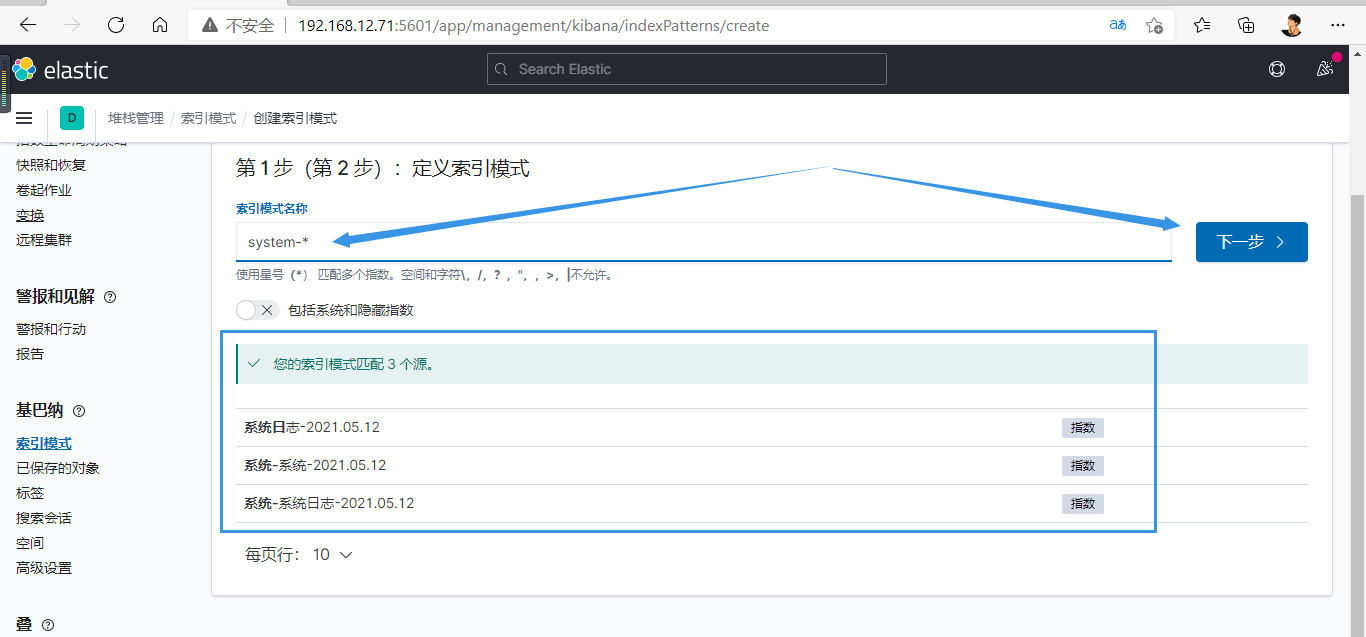
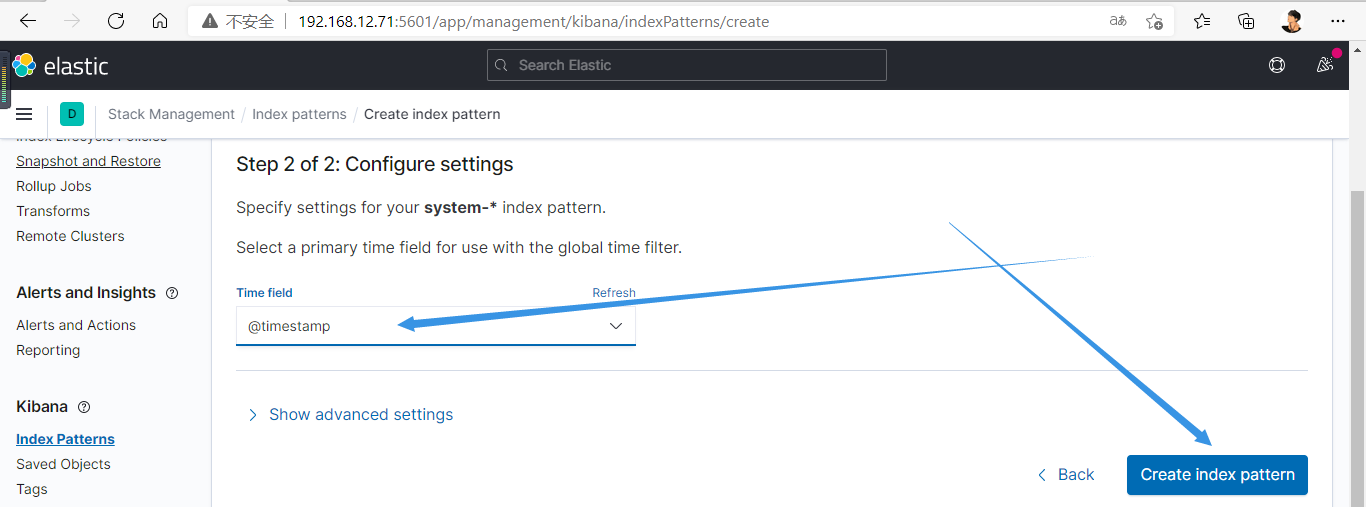
此时是没有数据的,因为logstash没有启动,需启动才行
# 启动logstash
[root@es-01 ~]# /usr/share/logstash/bin/logstash -f test.conf
[root@es-01 filebeat]# echo "~~~~~~~~~~~~~~~~~~~~~~~~" >> /var/log/cron
# 可查看多种数据,每echo一个内容,可再次刷新查看
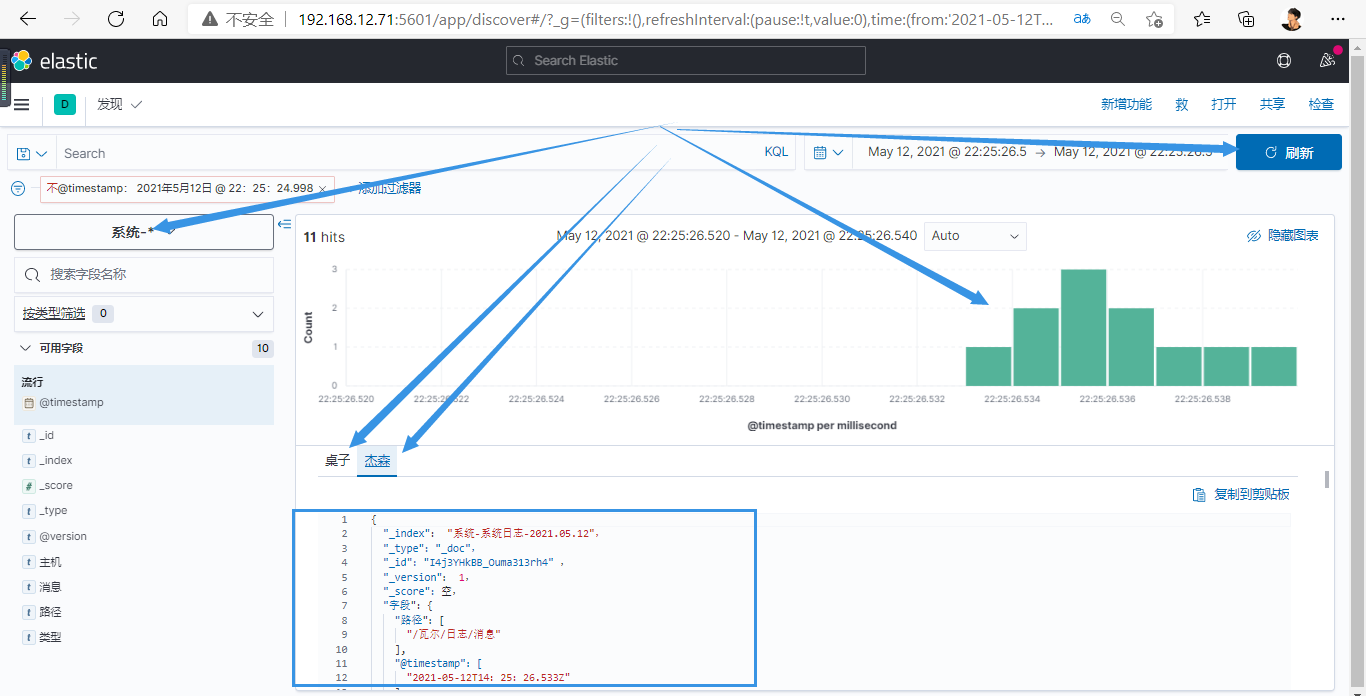
















 1838
1838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











