






1.Hibernate持久化类和对象标识符
1.1 持久化类的编写规范
1.什么是持久化类
Hibernate是持久层的ORM映射框架,专注于数据的持久化工作。所谓的持久化,就是将内存中的数据永久存储到关系型数据库中。
那么知道了什么是持久化,什么又是持久化类呢?其实所谓的持久化类指的是一个Java类与数据库表建立了映射关系,那么这个类称为是持久化类。
其实你可以简单的理解为持久化类就是一个Java类有了一个映射文件与数据库的表建立了关系。那么我们在编写持久化类的时候有哪些要求呢?接下来我们来看一下:
2.持久化类的编写规则
我们在编写持久化类的时候需要有以下几点需要注意:
持久化类需要提供无参数的构造方法。因为在Hibernate的底层需要使用反射生成类的实例。持久化类的属性需要私有,对私有的属性提供公有的get和set方法。因为在Hibernate底层会将查询到的数据进行封装。持久化类的属性要尽量使用包装类的类型。因为包装类和基本数据类型的默认值不同,包装类的类型语义描述更清晰而基本数据类型不容易描述。
举个例子:
假设表中有一列员工工资,如果使用double类型,如果这个员工工资忘记录入到系统中,系统会将默认值0存入到数据库,如果这个员工工资被扣完了,也会向系统中存入0.那么这个0就有了多重含义,而如果使用包装类类型就会避免以上情况,如果使用Double类型,忘记录入工资就会存入null,而这个员工工资被扣完了,就会存入0,不会产生歧义。持久化类要有一个唯一标识OID与表的主键对应。因为Hibernate中需要通过这个唯一标识OID区分在内存中是否是同一个持久化类。在Java中通过地址区分是否是同一个对象的,在关系型数据库的表中是通过主键区分是否同一条记录。那么Hibernate就是通过这个OID来进行区分的。Hibernate是不允许在内存中出现两个OID相同的持久化对象的。持久化类尽量不要使用final进行修饰。因为Hibernate中有延迟加载的机制,这个机制中会产生代理对象,Hibernate产生代理对象使用的是字节码的增强技术完成的,其实就是产生了当前类的一个子类对象实现的。如果使用了final修饰持久化类。那么就不能产生子类,从而就不会产生代理对象,那么Hibernate的延迟加载策略(是一种优化手段)就会失效。
简单的说:我们的持久化类(实体类)都需要遵从JavaBean的编写规范。
什么是JavaBean:
Bean:在软件开发领域,Bean表示可重用组件。
JavaBean就是用java语言开发的可重用组件。
JavaBean的编写规范是什么:
类都是public的
都有默认无参构造函数
成员变量都是私有的
都有公有的get/set方法
一般都实现Serializable接口。
基本类型和包装类的选择问题:
由于包装类可以有null值。所以实际开发中都是用包装类。
持久化类我们已经可以正常编写了,但是在持久化类中有一个特殊的属性(唯一对象标识OID),这个属性是用来与表的主键去建立映射关系。
1.2 Hibernate对象标识符(OID)
OID全称是Object Identifier,又叫做对象标识符。
它是hibernate用于区分两个对象是否是同一个对象的标识。
我们都知道:虚拟机内存区分两个对象是通过判断两个对象的内存地址是否一致;数据库区分两条记录是否相同,靠的是表的主键。hibernate负责把内存中的对象持久化到数据库表中,靠的就是对象标识符来区分两个对象是否是同一个。

实体类中映射主键的字段就是OID,如下图所示:

通常主键一般我们是不会让客户手动录入的,一般我们是由程序生成主键。那么Hibernate中也提供了相应的主键生成的方式,那么我们来看下Hibernate的主键生成策略。
1.3 Hibernate的主键生成策略
在讲解Hibernate的主键生成策略之前,先来了解两个概念,即自然主键和代理主键,具体如下:
自然主键(业务主键):把具有业务含义的字段作为主键,称之为自然主键。例如在customer表中,如果把name字段作为主键,其前提条件必须是:每一个客户的姓名不允许为null,不允许客户重名,并且不允许修改客户姓名。尽管这也是可行的,但是不能满足不断变化的业务需求,一旦出现了允许客户重名的业务需求,就必须修改数据模型,重新定义表的主键,这给数据库的维护增加了难度。代理主键(逻辑主键):把不具备业务含义的字段作为主键,称之为代理主键。该字段一般取名为“ID”,通常为整数类型,因为整数类型比字符串类型要节省更多的数据库空间。在上面例子中,显然更合理的方式是使用代理主键。

2.Hibernate一级缓存
2.1 什么是缓存
数据存储到数据库里面,数据库本身是一个文件系统,使用流方式操作文件(效率不高)
改进方式:把数据存到内存中,不需要使用流方式,可以直接读取内存中的数据
缓存:内存中的临时数据,当内存释放时,缓存消失。
在读取数据时,先去缓存中查找,缓存中有就直接拿出,缓存中没有则再去数据库中查询
缓存的优点:降低IO读写、提高执行效率。
2.2 一级缓存
Hibernate的一级缓存就是指Session缓存,Session缓存是一块内存空间,用来存放相互管理的java对象,在使用Hibernate查询对象的时候,首先会使用对象属性的OID值在Hibernate的一级缓存中进行查找,如果找到匹配OID值的对象,就直接将该对象从一级缓存中取出使用,不会再查询数据库;如果没有找到相同OID值的对象,则会去数据库中查找相应数据。当从数据库中查询到所需数据时,该数据信息也会放置到一级缓存中。
Hibernate的一级缓存的作用就是减少对数据库的访问次数(降低IO读写次数)。
Hibernate的一级缓存有如下特点:
- 一级缓存默认是打开状态
- 一级缓存的使用范围是session范围(从session创建到session关闭)
- 一级缓存中存储的数据必须都是持久态数据
2.3 测试一级缓存
@Test
public void testCache(){
//从Hibernate封装的工具类中获取Session对象
Session session=HibernateUtil.openSession();
//开启事务
Transaction tx=session.beginTransaction();
//第一次执行get方法:一级缓存中无数据,会去数据库中查询
Customer c1=session.get(Customer.class, 100L);
System.out.println("One : "+c1);
//第二次执行get方法:一级缓存中有数据,直接获取缓存中的数据
Customer c2=session.get(Customer.class, 100L);
System.out.println("Two : "+c2);
System.out.println(c1==c2);//结果为true
tx.commit();
session.close();
}

2.4 一级缓存执行过程

2.5 一级缓存的特性,快照机制
@Test
public void testUpdateName(){
//从Hibernate封装的工具类中获取Session对象
Session session=HibernateUtil.openSession();
//开启事务
Transaction tx=session.beginTransaction();
//第一步:先查询出客户信息(根据ID查询)
Customer c=session.get(Customer.class, 95L);
//第二步:对查询出的客户实体进行修改(修改名称)
c.setCustName("传智.黑马程序员");
//第三步:调用Hibernate方法实现更新操作
//session.update(c); //常规方式是要调用update方法,但此处省略看看执行结果
tx.commit();
session.close();
}


解释:以上java程序中没有直接调用update方法,同样也对数据修改成功。主要是借助了Hibernate的快照功能
Hibernate 向一级缓存放入数据时,同时复制一份数据放入到Hibernate快照中,当使用commit()方法提交事务时,同时会清理Session的一级缓存,这时会使用OID判断一级缓存中的对象和快照中的对象是否一致,如果两个对象中的属性发生变化,则执行update语句,将缓存的内容同步到数据库,并更新快照;如果一致,则不执行update语句。
结论:Hibernate快照的作用就是确保一级缓存中的数据和数据库中的数据一致。
3.Hibernate对象状态
了解过Hibernate一级缓存之后,我们可以进一步来了解持久化类了。
Hibernate为了更好的来管理持久化类,特将持久化类分成了三种状态。在Hibernate中持久化的对象可以划分为三种状态,分别是瞬时态、持久态和脱管态,一个持久化类的实例可能处于三种不同状态中的某一种,三种状态的详细介绍如下。
1.瞬时态(transient)
瞬时态也称为临时态或者自由态,瞬时态的实例是由new命令创建、开辟内存空间的对象,不存在持久化标识OID(相当于主键值),尚未与Hibernate Session关联,在数据库中也没有记录,失去引用后将被JVM回收。瞬时状态的对象在内存中是孤立存在的,与数据库中的数据无任何关联,仅是一个信息携带的载体。
2.持久态(persistent)
持久态的对象存在持久化标识OID ,加入到了Session缓存中,并且相关联的Session没有关闭,在数据库中有对应的记录,每条记录只对应唯一的持久化对象,需要注意的是,持久态对象是在事务还未提交前变成持久态的。
3.脱管态(detached)
脱管态也称离线态或者游离态,当某个持久化状态的实例与Session的关联被关闭时就变成了脱管态。脱管态对象存在持久化标识OID,并且仍然与数据库中的数据存在关联,只是失去了与当前Session的关联,脱管状态对象发生改变时Hibernate不能检测到。

小结:
区分hibernate对象状态只有两个标识:一是否有OID、二是否和Session建立的关系
- 临时状态:没有OID,和Session没有关系。
- 持久化状态:有OID,和Session有关系。
- 脱管状态:有OID,和Session没有关系。
4.Hibernate的事务控制
4.1 配置Session和线程绑定
在Hibernate中,可以通过代码来操作管理事务。例如:
Transaction tx=session.beginTransaction();//开启事务
在进行了持久化操作(save、update、delete)后,通过tx.commit()提交事务
如果事务出现异常,又通过tx.rollback()操作来撤销事务(事务回滚)
除了在代码中对事务开启,提交和回滚操作外,还可以在Hibernate的配置文件中对事务进行配置。配置文件中,可以设置事务的隔离级别。其具体的配置方法是在hibernate.cfg.xml文件中的<session-factory>标签元素中进行的。配置方法如下所示:
<!—
事务隔离级别
hibernate.connection.isolation = 4
1—Read uncommitted isolation (读取未提交的内容。 最低级别,任何情况都无法保证)
2—Read committed isolation (读取提交的内容。 避免脏读的发生)
4—Repeatable read isolation (可重复读。 避免脏读和可重复读的发生)
8—Serializable isolation (可串行化。 最高级别,避免脏读、可重复读和幻读的发生)
-->
<property name="hibernate.connection.isolation">4</property>
到这我们已经设置了事务的隔离级别,那么我们在真正进行事务管理的时候,需要考虑事务的应用的场景,也就是说我们的事务控制不应该是在DAO层实现的,应该在Service层实现,并且在Service中调用多个DAO实现一个业务逻辑的操作。具体操作如下显示:

其实最主要的是如何保证在Service中开启的事务时使用的Session对象和DAO中多个操作使用的是同一个Session对象。
其实有两种办法可以实现:
- 可以在业务层获取到Session,并将Session作为参数传递给DAO。
- 可以使用ThreadLocal将业务层获取的Session绑定到当前线程中,然后在DAO中获取Session的时候,都从当前线程中获取。
其实使用第二种方式肯定是最优方案,那么具体的实现已经不用我们来完成了,Hibernate的内部已经将这个事情做完了。我们只需要完成一段配置即可。
Hibernate5中自身提供了三种管理 Session 对象的方法:
- 1.Session 对象的生命周期与本地线程绑定
- 2.Session 对象的生命周期与 JTA 事务绑定
- 3.Hibernate 委托程序管理 Session 对象的生命周期
在 Hibernate 的配置文件中, hibernate.current_session_context_class 属性用于指定 Session 管理方式, 可选值包括:
- thread:Session 对象的生命周期与本地线程绑定
- jta:Session 对象的生命周期与 JTA 事务绑定
- managed:Hibernate 委托程序来管理 Session 对象的生命周期
4.2 配置步骤
1.在hibernate.cfg.xml文件中配置
<!-- 把session绑定到当前线程上 -->
<property name="hibernate.current_session_context_class">thread</property>
2.获取Session时使用的方法:
/**
* 每次都是从当前线程上获取Session
* @return
*/
public static Session getCurrentSession(){
return factory.getCurrentSession();
}
细节:当我们把Session绑定到当前线程之后,关闭session就是hibernate来做的,我们就不用关了。
到这里我们已经对Hibernate的事务管理有了基本的了解,但是之前我们所做的CRUD的操作其实还没有查询多条记录。那如果我们需要查询多条记录要如何完成呢,我们接下来去学习一下Hibernate的其他的相关的API。
5.Hibernate查询对象的API介绍
5.1 概述
Query代表面向对象的一个Hibernate查询操作。在Hibernate中,通常使用session.createQuery()方法接受一个HQL语句,然后调用Query的list()或uniqueResult()方法执行查询。所谓的HQL是Hibernate Query Language缩写,其语法很像SQL语法,但它是完全面向对象的。
在Hibernate中使用Query对象的步骤,具体所示:
- 获得Hibernate的Session对象。
- 编写HQL语句。
- 调用session.createQuery 创建查询对象。
- 如果HQL语句包含参数,则调用Query的setXxx设置参数。
- 调用Query对象的方法执行查询。
HQL说明:把表的名称换成实体类名称。把表字段名称换成实体类属性名称。
例如:
SQL:select * from cst_customer where cust_name like ?
HQL:select c from Customer c where custName = ?
其中select c 可以省略,写为:from Customer where custName = ?
5.2 api
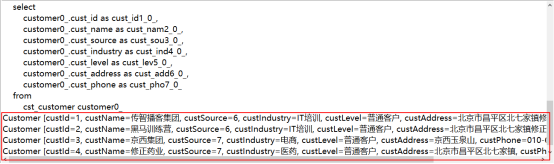
1.基本查询
@Test
public void testAllCostomer(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("from Customer");
//通过Query对象的方法,获取结果集
List list =query.list();
//遍历集合,取出并输出对象
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。事务提交后会自动关闭Session对象
}
执行结果
2.条件查询
@Test
public void testCondition(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("from Customer where custName like ? and custLevel = ?");
//Hibernate中的参数占位符索引是从0开始
query.setString(0, "%集团%");//给第一个参数占位符赋值
query.setString(1, "普通客户");//给第二个参数占位符赋值
//调用Query对象的方法,获取结果集
List list = query.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。 提交后会关闭Session对象
}
程序的执行结果:

使用参数占位符名称的代码:
/**
* 条件查询:通过参数占位符名称给条件赋值
* 参数占位符名称的写法: :名称
* 注意:在赋值时可以省略冒号,直接写"名称"即可。
*/
@Test
public void testCondition2(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("from Customer where custName like :custName and custLevel = :custLevel");
//通过参数占位符名称赋值(直接写名称,不需要写冒号)
query.setString("custLevel", "普通客户");//给第二个参数占位符赋值
query.setString("custName", "%集团%");//给第一个参数占位符赋值
//调用Query对象的方法,获取结果集
List list = query.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。 提交后会关闭Session对象
}
3.分页查询
在MySQL中使用limit进行分页: SELECT * FROM cst_customer LIMIT 0,2
Limit中参数的定义:
第一个:查询的开始记录索引
第二个:每次查询的条数
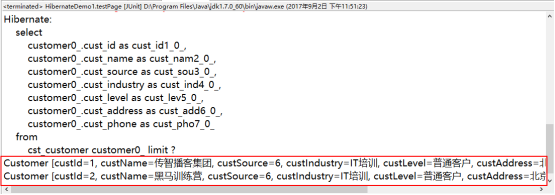
@Test
public void testPage(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("from Customer");
//Hibernate中设置分页的方法
query.setFirstResult(2);//设置记录的索引
query.setMaxResults(2);//设置每次查询的记录条数
//调用Query对象的方法,获取结果集
List list = query.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。
}
程序的执行结果:
4.排序查询
@Test
public void testSort(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("from Customer order by custId desc");
//调用Query对象的方法,获取结果集
List list = query.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务
}

5.统计查询
* 带有聚合函数的HQL
* 聚合函数:count、sum、avg、max、min
* SQL语句在使用聚合函数时,如果没有group by分组,聚合函数返回的结果永远只有一行一列
*
* count()聚合函数的几种用法:
* select count(*) from table; 会统计所有字段,执行效率比较低
* select count(主键) from table; 仅按主键字段进行统计,执行效率比较高
* select count(非主键) from table; 只统计非null字段
* 企业开发中推荐使用:select count(1) from table;
@Test
public void TestCount(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
//获取Query对象
Query query =session.createQuery("select count(custId) from Customer");
//当确定仅有一个结果时,使用Query对象的查询唯一结果集方法
Long count = (Long)query.uniqueResult();
System.out.println("公司现有客户"+count+"个");
tx.commit();//提交事务
}
程序执行结果:

6.投影查询
* 投影查询
* 投影:使用一个实体的部分字段信息,来构建实体类对象,叫做对象的投影(在hibernate中的叫法)
* 使用HQL的方式查询实体类的部分字段信息,并且封装到实体类中。
* HQL语句的写法:select new Customer(custId,custName) from Customer
* 如果工程只有一个唯一的类,可以不写全限定类名,否则必须写全限定类名(cn.itcast.domain.类名)。
* 实体类要求:必须提供一个相同参数列表的构造函数
//提供对应参数列表的构造函数
public class Customer implements Serializable{
......
public Customer(Long custId, String custName) {
super();
this.custId = custId;
this.custName = custName;
}
......
}
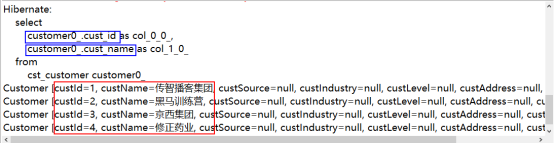
@Test
public void tetsProjection(){
//从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
//开启事务
Transaction tx =session.beginTransaction();
Query query=session.createQuery("select new Customer(custId,custName) from Customer");
//调用Query对象的方法,获取结果集
List list = query.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务
}
5.3 Query对象中的方法说明
- list方法:该方法用于查询语句,返回的结果是一个list集合。
- uniqueResult方法:该方法用于查询,在确保只有一条记录的查询时可以使用该方法,返回的结果是一个Object对象
- setter方法:Query接口中提供了一系列的setter方法用于设置查询语句中的参数,针对不同的数据类型,需要用到不同的setter方法。
- setFirstResult()方法:该方法可以设置获取第一个记录的位置,也就是它表示从第几条记录开始查询,默认从0开始计算。
- setMaxResult()方法:该方法用于设置结果集的最大记录数,通常与setFirstResult()方法结合使用,用于限制结果集的范围,以实现分页功能。
6.Criteria对象
6.1 概述
Criteria是一个完全面向对象,可扩展的条件查询API,通过它完全不需要考虑数据库底层如何实现,以及SQL语句如何编写,它是Hibernate框架的核心查询对象。
Criteria 查询,又称为QBC查询(Query By Criteria),它是Hibernate的另一种对象检索方式。
org.hibernate.criterion.Criterion是Hibernate提供的一个面向对象查询条件接口,一个单独的查询就是Criterion接口的一个实例,用于限制Criteria对象的查询,在Hibernate中Criterion对象的创建通常是通过Restrictions 工厂类完成的,它提供了条件查询方法。
通常,使用Criteria对象查询数据的主要步骤,具体如下:
- 获得Hibernate的Session对象
- 通过Session获得Criteria对象
- 使用Restrictions的静态方法创建Criterion条件对象。Restrictions类中提供了一系列用于设定查询条件的静态方法,这些静态方法都返回Criterion实例,每个Criterion实例代表一个查询条件。
- 向Criteria对象中添加Criterion 查询条件。Criteria的add()方法用于加入查询条件
- 执行Criterita的 list() 或uniqueResult() 获得结果。
细节:
HQL能查的,QBC都能查,反之亦然。
了解了Criteria对象的使用步骤后,接下来,通过具体示例来演示Criteria对象的查询操作
6.2 常用查询
1.基本查询
@Test
public void testBaseQuery(){
//第1步:从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
Transaction tx =session.beginTransaction();//开启事务
//第2步:创建Criteria对象
Criteria c =session.createCriteria(Customer.class);//相当于HQL的from Customer
//执行Criteria对象的方法,获取结果集
List list =c.list();
//遍历
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。同时也关闭了Session
}
2.条件查询
@Test
public void testCondition(){
//第1步:从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
Transaction tx =session.beginTransaction();//开启事务
//第2步:创建Criteria对象
Criteria c =session.createCriteria(Customer.class);//相当于HQL的from Customer
//第3步:设置查询条件
c.add(Restrictions.like("custName", "%集团%"));//相当于where custName like '%集团%'
c.add(Restrictions.eq("custLevel", "普通客户"));//相当于and custLevel ='普通客户'
//执行Criteria对象的方法,获取结果集
List list =c.list();
//遍历
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务
}
3.分页查询
@Test
public void testPage(){
//第1步:从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
Transaction tx =session.beginTransaction();//开启事务
//第2步:创建Criteria对象
Criteria c =session.createCriteria(Customer.class);//相当于HQL的from Customer
//Hibernate中设置分页的方法
c.setFirstResult(0);//设置记录的索引
c.setMaxResults(2);//设置每次查询的记录条数
//执行Criteria对象的方法,获取结果集
List list = c.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务。
}
4.排序查询
@Test
public void testSort(){
//第1步:从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
Transaction tx =session.beginTransaction();//开启事务
//第2步:创建Criteria对象
Criteria c =session.createCriteria(Customer.class);//相当于HQL的from Customer
//设置排序方式
c.addOrder(Order.desc("custId"));//相当于HQL的 order by custId desc
//执行Criteria对象的方法,获取结果集
List list = c.list();
//遍历结果集
for(Object obj : list){
System.out.println(obj);
}
tx.commit();//提交事务
}
5.统计查询
@Test
public void testCount(){
//第1步:从当前线程中获取新的Session对象
Session session= HibernateUtil.getCurrentSession();
Transaction tx =session.beginTransaction();//开启事务
//第2步:创建Criteria对象
Criteria c =session.createCriteria(Customer.class);//相当于HQL的from Customer
// 调用
//c.setProjection(Projections.rowCount());//相当于 select count(*)
c.setProjection(Projections.count("custId"));//相当于 select count(cust_id)
//调用仅返回唯一结果的方法
Long count = (Long)c.uniqueResult();
System.out.println("公司现有客户"+count+"个");
tx.commit();//提交事务
}















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









