






1.索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
可参考:数据结构可视化
可参考:BTree和B+Tree详解
可参考:面试
引子
假设我们有一个两列7行的表
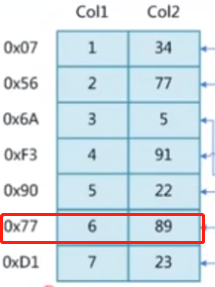
假设我们要查第六条数据,select * from t where col2 = 89,如果col2字段没有做索引,在查询时就会从表的第一行开始逐行遍历,找6次磁盘io才能找到这条记录,
1.1 二叉树
可参考:java实现二叉树
假设我们对col2做了索引,底层是二叉树,我们每插入一条数据,都会讲索引字段的值放到二叉树中,最终形成如下索引树

此时我们要查89,从根节点开始查找,89大于34,所以从34的右子节点继续往下找,只要找4次就能找到了
二叉树的一个节点存储的结构实质上是key-value的结构,key是存储的索引值,value是索引值所在那行数据在磁盘文件中的地址
弊端:
当我们用col1列作为索引时,索引树如下

二叉树如果插入的是单边增长/减少的数据,二叉树退化成链表,我们知道链表做查询是非常慢的,我们要查col1=6,也要查6次,跟逐行查找没有区别
所以mysql的存储结构并没有使用二叉树
1.2 红黑树(二插平衡树)
使用红黑树后,单边增长时,做了平衡

弊端:
数据量越大,高度越高,查找效率越低
存储大数量级别时,树的高度无法控制.例如索引是1~100w的单边增长数据,此时树的高度就有50w层…要查找一个叶子节点的数据,就要经过50w次的磁盘io,显然很不合理
1.3 B-Tree(平衡多路查找树)
刚刚说了红黑树的缺点,无法控制树的高度,那我们有没有办法可以将树的高度控制在一个比较小的范围中呢?
我们可以在每个节点多存储一些数据

mysql对每个节点的大小设置为16kb
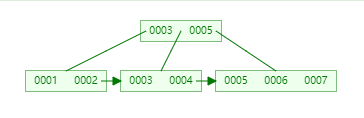
1.3 B+Tree
是B-Tree的变种
- 非叶子节点不存储data,只存储索引(冗余),这样就可以在每一个节点放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
2.mysql的两种常用存储引擎
存储引擎最终是作用到数据库表的
- myisam
- innodb
两个存储引擎底层都使用了B+tree

2.1 myisam
一张myisam表,会在磁盘中形成三个文件
- .frm :存储表结构相关的信息
- .MYD :存储data
- .MYI :存储index(索引字段) 底层使用B+tree
myisam索引文件和数据文件是分离的(非聚集)

例如我们查找15,首先在MYI文件中在叶子节点获取到15所在行记录的磁盘文件地址指针 0x07,然后根据此地址去MYD文件中找到这条记录
2.2 innodb
- .frm :存储表结构相关的信息
- .ibd :数据文件+索引文件
InnoDB索引实现(聚集)
- 表数据文件本身就是按B+tree组织的一个索引结构的文件
- 聚集索引-叶节点包含了完整的数据结构(索引和数据放一起)
- 为什么Innodb表必须有主键,并且推荐使用整值的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?
















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









