






1.主从复制
主从复制
分库分表
读写分离
linux 安装mysql8.0 超详细图文教程
1.1 概述
主从复制指: 将主数据库的DDL和DML操作通过二进制日志传递到从库服务器中, 然后从库根据日志重新执行(也叫重做), 从而使从库和主库的数据保存同步
MYSQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务的主库, 实现链状复制
主从复制的优点:
- 高可用性
主从复制提供了高可用性,因为如果主库发生故障,可以快速切换到从库,确保系统的连续性和可用性 - 负载分担
通过将读操作分发到从库,可以减轻主库的负载。从而提高系统整体的性能和响应速度。 - 数据备份
从库可以用于实时备份主库数据。通过在从库上进行备份,避免了对主库的额外负载,同时确保备份的实时性。 - 故障恢复
如果主库发生故障,可以迅速将从库提升为新的主库,从而实现快速的故障恢复。 - 实时分析
从库可以用于执行实时分析、报表生成等任务,而不会影响主库的性能。这允许在不干扰主库的情况下进行复杂的数据分析。 - 版本切换和测试
可以使用从库进行版本升级、新功能测试等操作,而不会影响主库的生产环境。这提供了一个安全的环境,用于测试和验证变更。 - 灾难恢复
在发生灾难性事件时,从库可以用于灾难恢复。通过在异地备份从库,可以更好地保护数据并加快系统恢复速度。
DDL和DML的区别
- DDL: 定义数据库的结构和模式的语言. 通常用于创建、修改和删除数据库、表、视图、索引等数据库对象. 常见的DDL语句包括CREATE、ALTER、DROP. DDL语句一般会自动提交事务, 即执行后会立即生效且无法回滚
- DML: 用于操作数据库中的数据的语言. DML语句用于插入、更新、删除数据库中的数据. 常见的DML包括INSERT、UPDATE、DELETE.DML语句一般不会自动提交事务, 需要通过COMMIT语句手动提交才能生效, 也可以通过ROLLBACK语句回滚操作
1.2 原理
- 角色分配
- 主库(Master)
主库在事务提交时, 将对数据库的更改(DDL和DML)记录到二进制日志(Binary Log)中 - 从库(Slave)
从库读取主库的二进制日志, 并将这些日志中的更改(DDL和DML)应用到自己的数据库中
- 主库(Master)
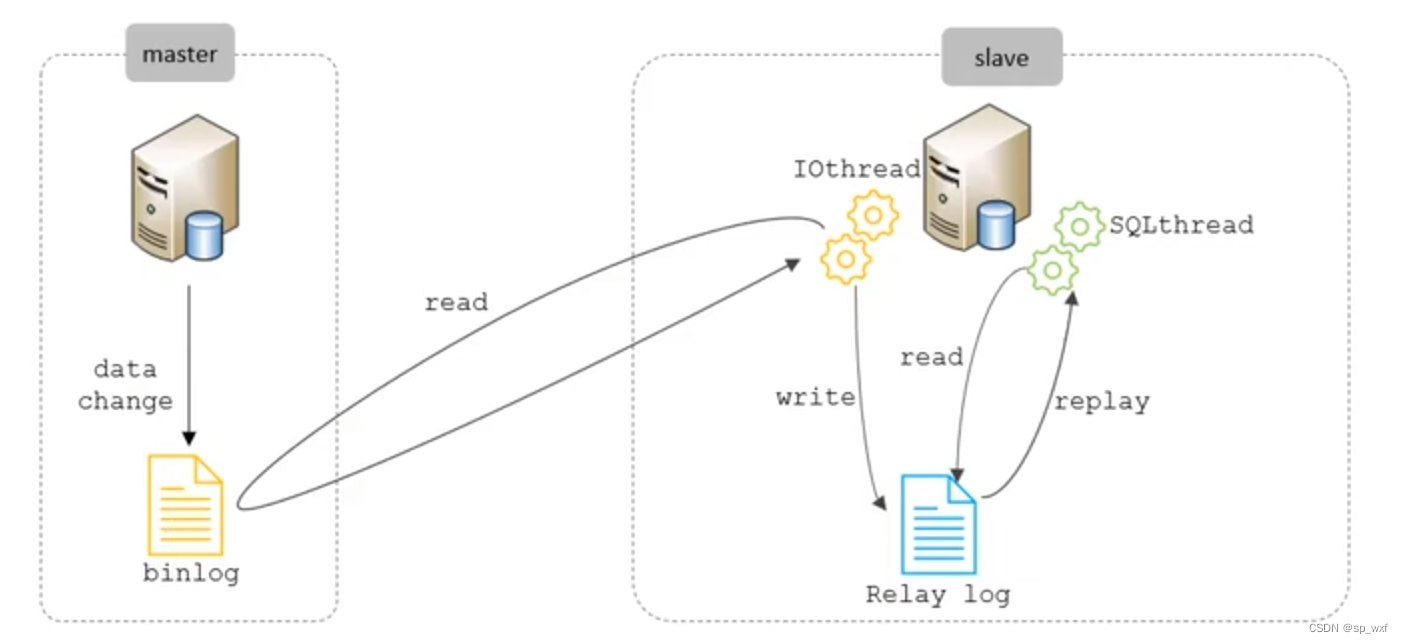
- 二进制日志
主库将所有更改数据库的操作写入二进制日志中 - IO线程
从库有一个IO线程, 负责连接到主库并请求主库的二进制日志, 写入从库本地的中继日志中 - 中继日志
从库用来存储主库二进制日志事件的本地副本 - SQL线程
从库有一个SQL线程, 它负责读取中继日志中的SQL语句, 并在从库上执行这些SQL语句, 以使从库的数据保持与主库同步
1.3 搭建
1.3.1 主库配置
- 第一步: 通过
my.cnf文件, 设置标识符和是否只读- server-id: 唯一标识, 在主从复制场景中, 用来区分不同的服务器
- read-only: 是否可读是否只读, 1代表只读, 0代表读写
- 当前我们不需要指定
binlog-ignore-db、binlog-do-db这两个参数, 这意味需要同步给所有的从库
# mysql服务ID, 确保整个集群环境中唯一
server-id=1
# 是否只读, 1代表只读, 0代表读写
read-only=0
# 同步时, 忽略的数据库
# binlog-ignore-db=mysql
# 指定同步的数据库
# binlog-do-db=db01
- 第二步: 重启mysql服务
sudo service mysql restart
- 第三步: 创建一个用户, 授予主从复制权限
- 创建用户’wxf’
CREATE USER 'wxf'@'%': 创建了一个用户名为 ‘wxf’,可以从任何主机(‘%’ 表示任意主机)连接的用户IDENTIFIED WITH mysql_native_password:指定使用 MySQL 原生密码进行身份验证。BY 'Root@123456': 设置用户’wxf’的密码为’Root@123456’。
- 授予主从复制权限
GRANT REPLICATION SLAVE ON *.*: 授予用户’wxf’从服务器的主从复制权限,允许其连接到任何数据库(‘.’ 表示所有数据库)的从服务器。TO 'wxf'@'%': 授权给用户 ‘wxf’,可以从任何主机连接
- 创建用户’wxf’
CREATE USER 'wxf'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
GRANT REPLICATION SLAVE ON *.* TO 'wxf'@'%';
- 第四步: 通过指令, 查看二进制日志坐标
show master status;
1.3.2 从库配置
- 第一步: 通过
my.cnf文件, 设置标识符和是否只读
# mysql服务ID, 确保整个集群环境中唯一
server-id=2
# 是否只读, 1代表只读, 0代表读写
read-only=1
- 第二步: 重启mysql服务
sudo service mysql restart
- 第三步: 指定从服务器连接到主服务器的详细信息
执行这个语句后, 从库将启动ioThread复制主库的二进制日志到中继日志
# mysql 8.0.23的语法
mysql> CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.202.128', SOURCE_USER='wxf', SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000003', SOURCE_LOG_POS=649;
# mysql 8.0.23之前版本的语法
mysql> change master to master_host='192.168.202.128',master_user='wxf',master_password='Root@123456',master_log_file='binlog.000003',master_log_pos=649;
- 第四步: 启动同步操作
执行这个命令后,从服务器将开始连接到主服务器,获取主服务器的二进制日志,并将其应用到从服务器上,实现主从同步。
# 8.0.22之后的语法
mysql> start replica;
# 8.0.22之前的语法
mysql> start slave;
- 第五步: 查看主从同步状态
# 8.0.22之后的语法
mysql> show replica status;
# 8.0.22之前的语法
mysql> show slave status;
2.分库分表
2.1 概述
分库分表对比单个数据库, 存在哪些优点:
- 提升性能
分库分表可以将数据分散到多个数据库节点和表中, 减轻了单一数据库的读写压力, 每个数据库节点和表的负载相对较小, 从而提高了整体性能 - 水平扩展
在单个数据库场景下, 只能通过垂直扩展来提升服务器的计算能力, 例如:增加CPU核数、内存容量、硬盘速度等, 而分库分表可以通过增加数据库节点和表的方式进行水平扩展 - 提高可用性
分库分表可以提高系统的可用性, 如果某个数据库节点或表发生故障, 其他节点或表仍然可以继续提供服务. 这种冗余和分布式的架构有助于减小单点故障带来的影响 - 更好的数据安全
分库分表可以提高数据安全性, 将数据分散存储在多个节点和表中, 即使部分数据泄漏或受到攻击, 也不会影响整个系统的所有数据 - 更好的并发处理
分库分表可以提高数据安全性。将数据分散存储在多个节点和表中,即使部分数据泄露或受到攻击,也不会影响整个系统的所有数据。
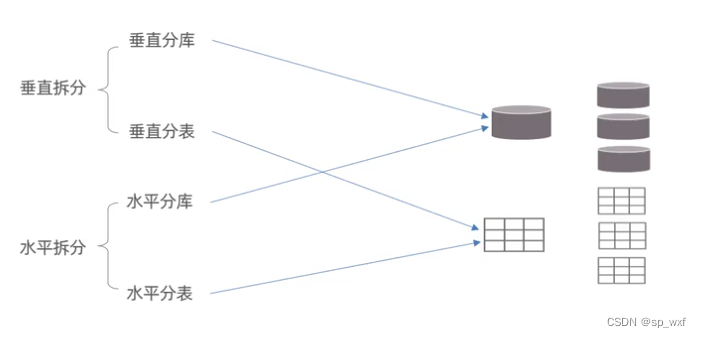
2.2 拆分策略
- 垂直拆分
- 垂直分库
- 垂直分表
- 水平拆分
- 水平分库
- 水平分表
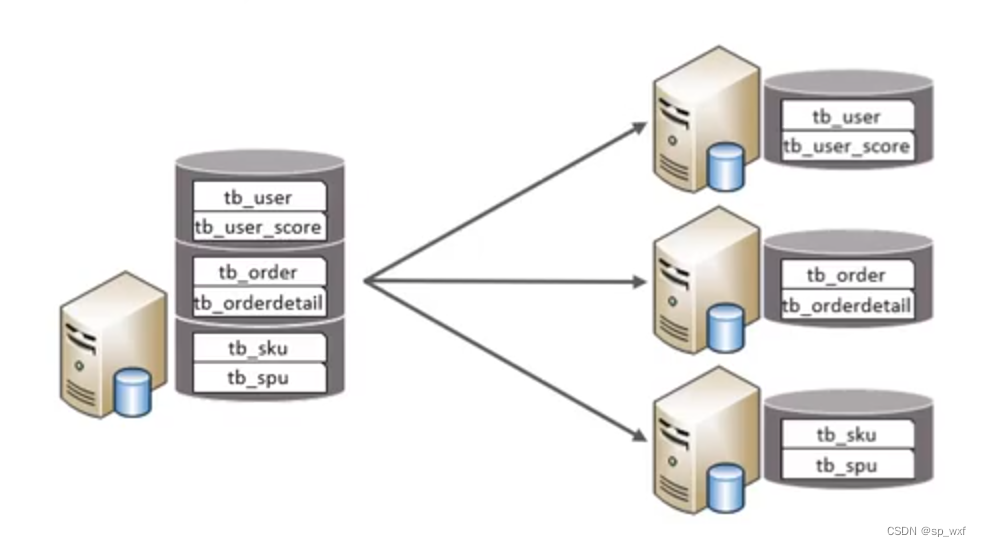
2.2.1 垂直分库
以表为依据, 根据业务将不同的表拆分到不同的库中
特点:
- 每个库的表结构都不一样
- 每个库的数据也不一样
- 所有库的并集是全量数据
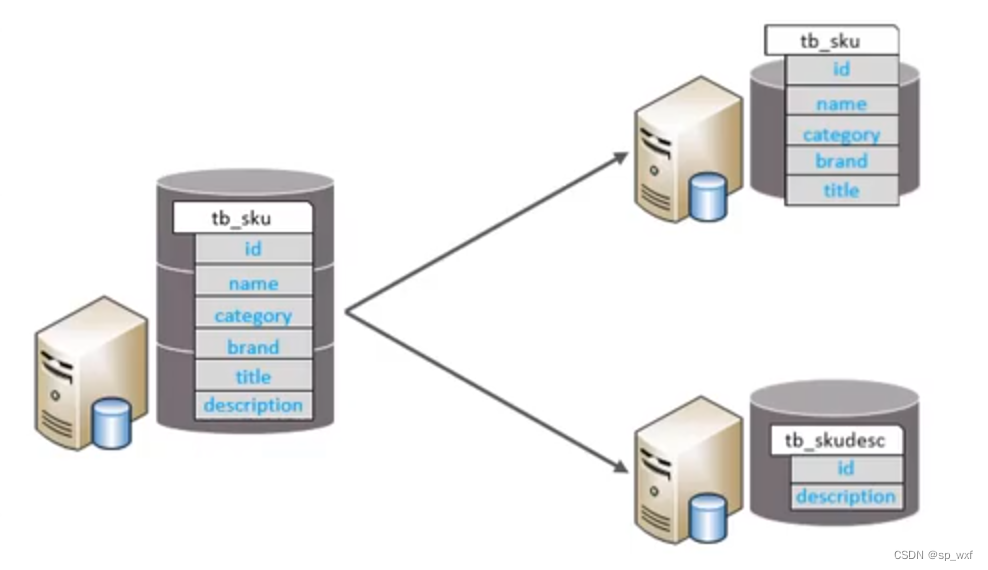
2.2.2 垂直分表
以字段为依据, 根据字段属性将不同字段拆分到不同表中
特点:
- 每个表的结构都不一样
- 每个表的数据也不一样, 一般通过一列(主键/外键)关联
- 所有表的并集是全量数据
2.2.3 水平分库
以字段为依据, 按照一定策略, 将一个库的数据拆分到多个库中
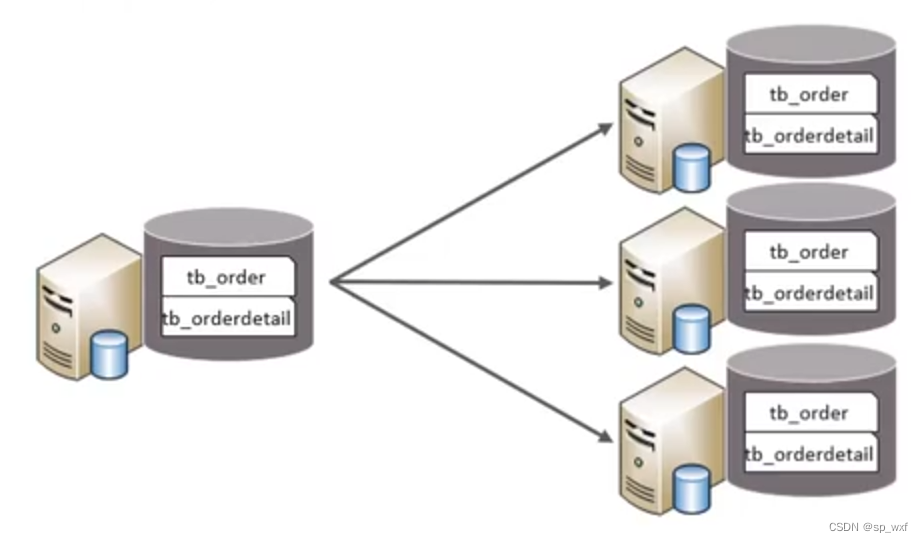
特点:
- 每个库的表结构都一样
- 每个库的数据都不一样
- 所有库的并集是全量数据
2.2.4 水平分表
以字段为依据, 按照一定策略, 将一个表的数据拆分到多个表中
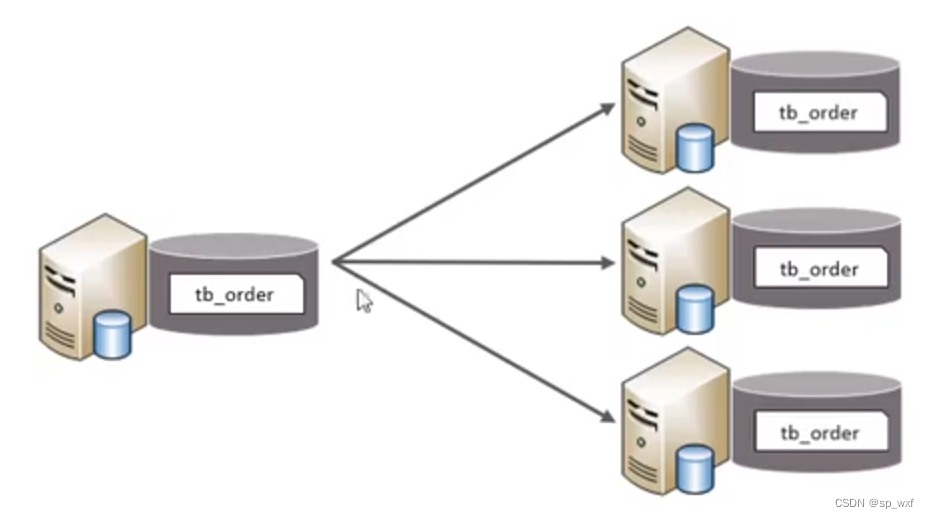
- 每个表的表结构都一样
- 每个表的数据都不一样
- 所有表的并集是全量数据
3 Mycat
3.1 为什么要使用Mycat
Mycat(全称为MySQL Cluster Auto-Test,中文名为蚂蚁分布式数据库管理系统)是一个开源的数据库中间件,主要用于实现MySQL数据库的分库分表和读写分离。它提供了一套较为完整的数据库中间件解决方案,具有如下主要特点和功能:
- 分库分表: Mycat可以将单一的MySQL数据库分成多个片(Sharding),每个片分别存储一部分数据,从而实现水平扩展。
- 读写分离: Mycat支持读写分离,可以将读请求和写请求分发到不同的MySQL节点上,提高数据库的并发处理能力。
- 分布式事务: Mycat实现了分布式事务的支持,可以在分布式环境下保障事务的一致性。
- SQL解析和路由: Mycat通过对SQL的解析,可以将查询请求路由到相应的MySQL节点,实现透明的分片访问。
- 自动切分: Mycat支持自动切分,可以根据表的规模和数据量自动进行分片。
- 高可用性: Mycat通过集群模式,提供了高可用性的解决方案,防止单点故障。
- 丰富的监控和管理功能: Mycat提供了丰富的监控和管理工具,方便管理员对数据库集群进行监控和管理。
Mycat是采用java语言开发的开源数据库中间件, 支持windows和linux运行环境, 我们需要在准备好的服务器中安装如下软件
- Mysql
- JDK
- Mycat
PS:如果部署Mycat的运行环境, 没有提前安装JDK, 那么
3.2 安装步骤
现在我们有三台服务器, 分别如下:
| 服务器 | 安装软件 | 说明 |
|---|---|---|
| 192.168.202.128 | jDK、Mycat、Mysql | 既作为Mycat中间件服务器, 又作为其中一个Mysql分片服务器 |
| 192.168.202.130 | Mysql | 分片服务器 |
| 192.168.202.131 | Mysql | 分片服务器 |
- 第一步: 上官网或者CSDN下载Mycat的Linux安装包
将下载好的Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz文件上传到/usr/local目录下
- 第二步: 解压文件
tar -zxvf Mycat-server-1.6.7.3-release-20190927161129-linux.tar.gz
解压成功后, 会出现一个新的文件夹:/mycat
- 第三步: 替换Mysql驱动
# 切换到mycat根目录下的lib依赖目录
cd /mycat/lib
当前使用的Mysql驱动版本是mysql-connector-java-5.1.35.jar, 因为我们安装的Mysql版本是8.0, 两者并不匹配, 需要手动替换这个驱动, 当前我们可以替换为mysql-connector-java-8.0.29.jar
- 第四步: 重新授权
chmod 777 mysql-connector-java-8.0.29.jar
3.3 核心概念
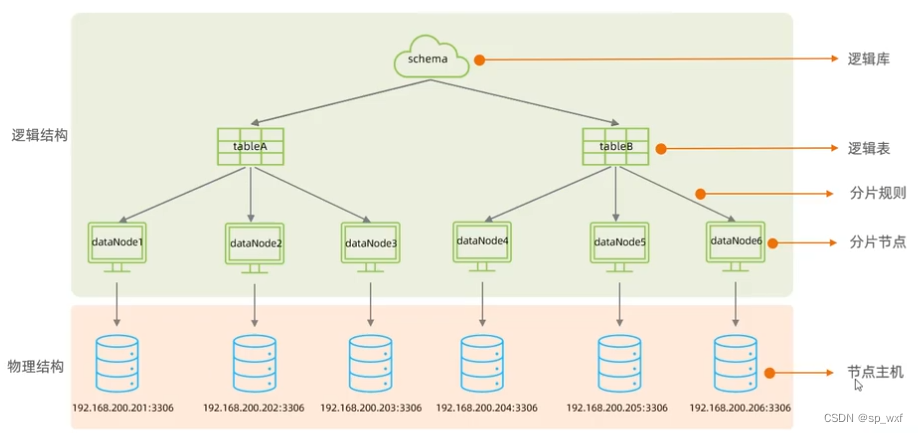
Mycat是一个数据库中间件,它本身并不存储数据, 它的主要功能是在应用程序与底层数据库系统之间充当中介
Mycat通过拦截和处理数据库请求来实现对数据库的操作
- 逻辑库
逻辑层面的数据库, 包含一组逻辑表, 可能对应多个实际的数据库节点. 应用程序通常直接访问逻辑库而不是直接访问底层的实际数据库 - 逻辑表
逻辑层面的数据库表, 逻辑表可以映射一个或多个实际的物理表, Mycat的分片和路由规则通常是基于逻辑表进行配置 - 分片规则
分片规则决定了查询请求应该路由到哪个数据库节点 - 分片节点
每个逻辑表可以配置在一个或多个分片节点上,这些分片节点实际上对应了不同的节点主机。
节点主机是实际的物理数据库节点,而分片节点是逻辑上的概念,表示逻辑表数据在分布式环境中的存储节点,它们之间的关系是通过在schema.xml文件中进行配置来建立的。
3.4 分片配置
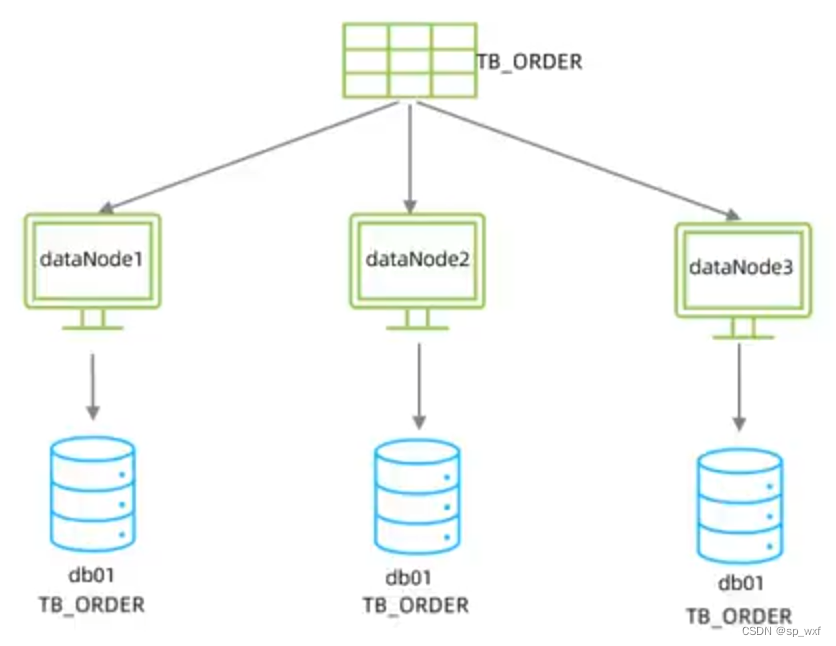
由于tb_order表中数据量很大, 磁盘IO以及容量都达到了瓶颈, 现在需要对tb_order表进行数据分片, 分为三个数据节点, 每一个节点主机位于不同的服务器上, 具体的结构如下:
- 第一步: 通过
schema.xml定义逻辑库、逻辑表、分片规则、分片节点、节点主机等信息
切换到Mycat文件夹下的config目录, 找到schema.xml进行编辑- <schema>: 定义逻辑库
- <table>: 定义逻辑表, 包括逻辑表的
名称、分片规则、分片节点- rule: 分片规则
- <dataNode>: 定义分片节点
- <dataHost>: 定义节点主机, 包括
名称、负载均衡策略、数据库类型、数据库驱动等信息
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库 -->
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100">
<!-- 逻辑表 -->
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
<!-- 分片节点 -->
<dataNode name="dn1" dataHost="dhost1" database="db01" />
<dataNode name="dn2" dataHost="dhost2" database="db01" />
<dataNode name="dn3" dataHost="dhost3" database="db01" />
<!-- 节点主机1 -->
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.128:3306" user="root" password="123456">
</writeHost>
</dataHost>
<!-- 节点主机2 -->
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.130:3306" user="root" password="123456"></writeHost>
</dataHost>
<!-- 节点主机3 -->
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.131:3306" user="root" password="123456"></writeHost>
</dataHost>
</mycat:schema>
- 第二步: 通过
server.xml配置mycat的用户以及用户的权限信息
我们配置两个用户, 一个root用户既可以读也可以写, 另一个user用户只读
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB01</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">DB01</property>
<property name="readOnly">true</property>
</user>
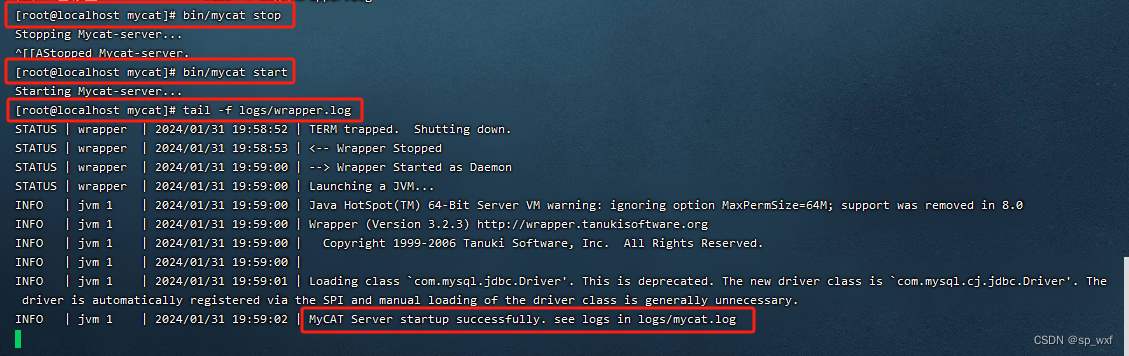
- 第三步: 启动Mycat服务
切换到Mycat的安装目录, 执行如下指令, 启动Mycat, Mycat启动后, 占用端口号8066
# 启动
bin/mycat start
# 停止
bin/mycat stop
我们可以通过tail -f logs/wrapper.log指令来查看Mycat是否正常启动
- 第四步: 登录Mycat
通过下面的指令, 就可以连接并登录Mycat
mysql -uroot -p -P8066 -h192.168.202.128 --default-auth=mysql_native_password
输入密码:123456
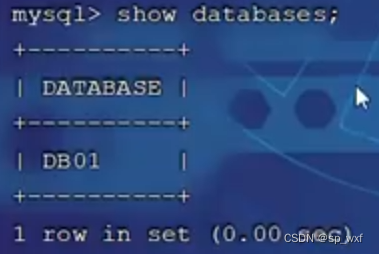
- 第五步: 查看Mycat的逻辑库
show databases;
-
第六步: 创建节点主机
上面显示的DB01是逻辑库, 而根据配置, 数据最终是存储在每台服务器的db01这个数据库, 所以我们需要先去创建这个库, 因为我们开启了主从复制, 所以当我们在192.168.202.128这个服务器上创建了db01后, 其他几个服务器也会同步 -
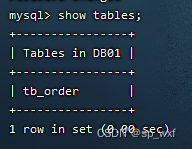
第七步: 查看Mycat的逻辑表
# 切换到DB01库
use DB01;
# 查看库中的逻辑表
show tables;
- 第八步: 创建节点中的表, 并插入数据
虽然我们在Mycat中可以看到这张表, 但是在实际的数据库中是没有这张表的, 所以我们需要创建表, 并往表结构中插入数据, 查看数据在MySql中的分布情况
CREATE TABLE TB_ORDER(
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
INSERT INTO TB_ORDER(id,title) VALUES(1,'goods1');
INSERT INTO TB_ORDER(id,title) VALUES(2,'goods2');
INSERT INTO TB_ORDER(id,title) VALUES(3,'goods3');
INSERT INTO TB_ORDER(id,title) VALUES(1000000,'goods1000000');
INSERT INTO TB_ORDER(id,title) VALUES(10000000,'goods10000000');
3.5 配置讲解
3.5.1 schema.xml
1.schema标签
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100">
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long">
<!-- 表的其他配置项 -->
</table>
</schema>
schema标签用于定义Mycat的逻辑库, 一个Mycat实例中, 可以定义多个逻辑库, 通过schema标签来划分不同的逻辑库
- name: 逻辑库的库名
- checkSQLschema: 在sql语句操作时指定了数据库名称, 执行时是否自动去除(true代表去除; false代表不去除)
- sqlMaxLimit: 对查询结果集的大小进行限制,以避免一次查询返回过多的数据
sqlMaxLimit 被设置为 100,这意味着对于这个逻辑库中的表执行的查询,每次查询最多返回 100 行数据
2.table标签
- name: 逻辑表的表名, 该逻辑库下唯一
- dataNode: 这张逻辑表对应哪几个分片节点; 多个dataNode逗号分隔
- rule: 引用的分片规则, 分片规则在rule.xml中定义
- primaryKey: 逻辑表对应真实表的主键
- type: 逻辑表的类型
3.dataNode标签
定义了Mycat的分片节点
- name: 分片节点名称
- dataHost: 数据库实例主机名称
- database: 分片所属数据库
4.dataHost标签
- name: 唯一标识
- maxCon/minCon: 最大连接数/最小连接数
- balance: 负载均衡策略, 取值0,1,2,3
- writeType: 写操作分发方式
- dbDriver: 数据库驱动, 支持native、jdbc
3.6 分片
3.6.1 垂直分库
垂直分表主要在业务层面操作, 我们这里就不演示了
场景:
在业务系统中, 涉及以下表结构, 但是由于用户和订单每天都会产生大量的数据, 单台服务器的数据存储以及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下:
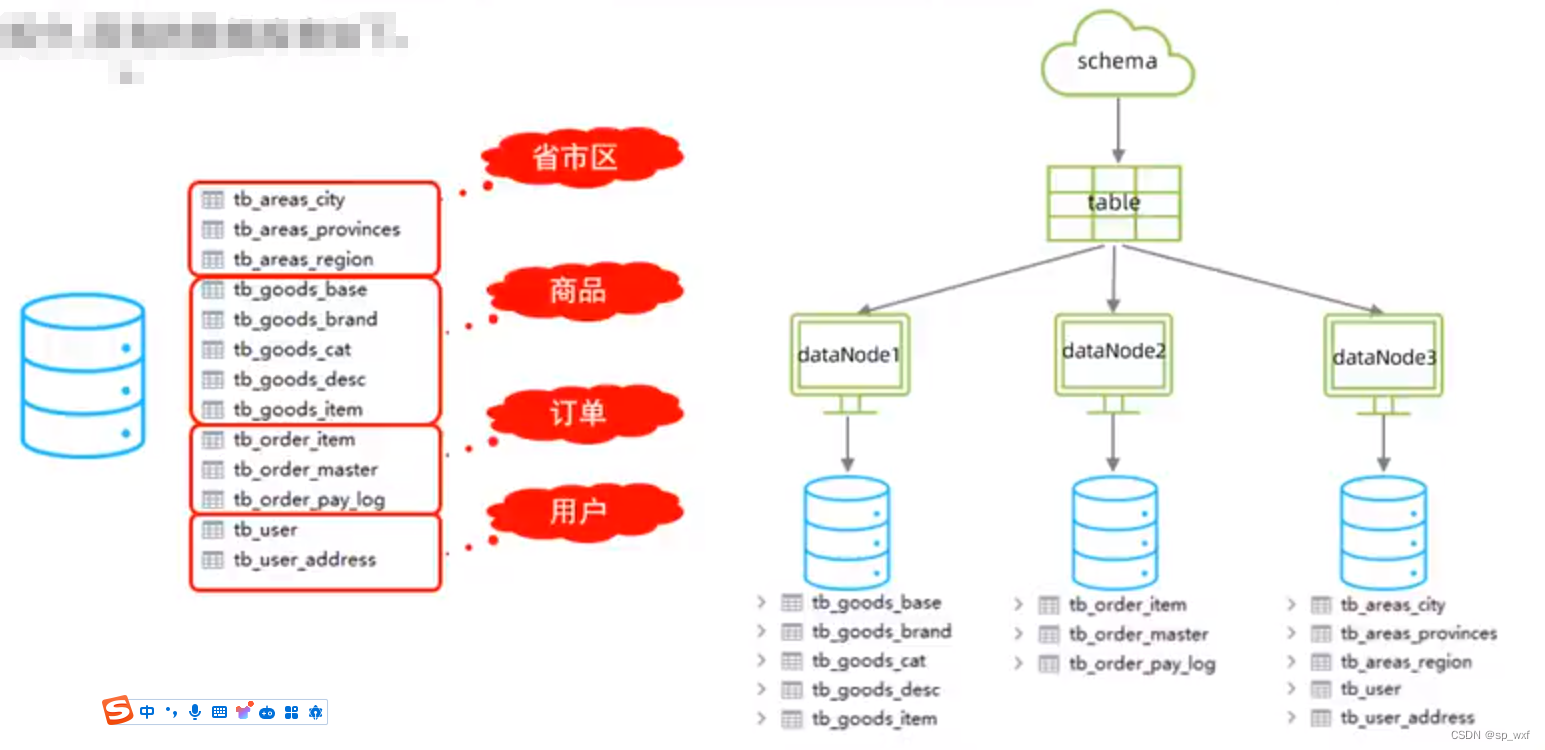
- 步骤一: 分别在三台Mysql中创建数据库Shopping
- 步骤二: 通过
schema.xml定义逻辑库、逻辑表、分片规则、分片节点、节点主机等信息
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库 -->
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100">
<!-- 逻辑表 -->
<table name="tb_goods_base" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_brand" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_cat" dataNode="dn1" primaryKey="id" />
<table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id" />
<table name="tb_goods_item" dataNode="dn1" primaryKey="id" />
<table name="tb_order_item" dataNode="dn2" primaryKey="id" />
<table name="tb_order_master" dataNode="dn2" primaryKey="order_id" />
<table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no" />
<table name="tb_user" dataNode="dn3" primaryKey="id" />
<table name="tb_user_address" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_provinces" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_city" dataNode="dn3" primaryKey="id" />
<table name="tb_areas_region" dataNode="dn3" primaryKey="id" />
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping" />
<dataNode name="dn2" dataHost="dhost2" database="shopping" />
<dataNode name="dn3" dataHost="dhost3" database="shopping" />
<!-- 节点主机1 -->
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.128:3306" user="root" password="123456">
</writeHost>
</dataHost>
<!-- 节点主机2 -->
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.130:3306" user="root" password="123456"></writeHost>
</dataHost>
<!-- 节点主机3 -->
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.202.131:3306" user="root" password="123456"></writeHost>
</dataHost>
</mycat:schema>
- 步骤三: 通过
server.xml配置mycat的用户以及用户的权限信息
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<property name="readOnly">true</property>
</user>
- 第四步: 登录Mycat
通过下面的指令, 就可以连接并登录Mycat
mysql -uroot -p -P8066 -h192.168.202.128 --default-auth=mysql_native_password
输入密码:123456
- 第五步: 查看逻辑库、逻辑表
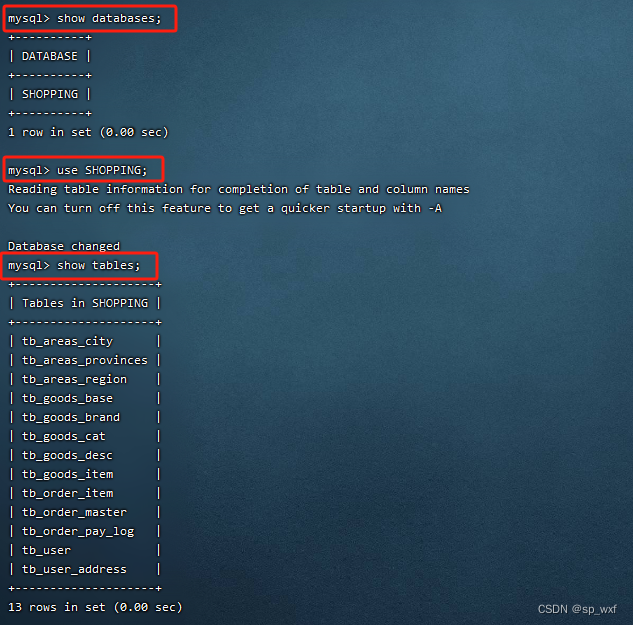
- 第六步: 创建节点中的表, 并插入数据
- 第七步: 测试多表联查
# sql一
select * from tb_user_address ua, tb_areas_city c, tb_areas_provinces p, tb_areas_region r where ua.province_id = p.provinceid and ua.city_id = c.cityid and ua.town_id = r.areaid;
# sql二
select * from tb_order_master o, tb_areas_provinces p, tb_areas_city c, tb_areas_region r where o.receiver_province = p.provinceid and o.receiver_city = c.cityid and o.receiver_region = r.areaid;
我们发现第一段sql可以正常执行, 因为这段sql涉及的表都落在同一个节点主机的库中, 而第二段sql涉及了不同节点主机中的表, 所以在执行的过程中报"表不存在"
3.6.1.1 全局表配置
数据字典表(在多个业务模块中都会用到), 可以将其设置为全局表, 利于业务操作
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" />
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" />
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id" type="global" />
它的本质是在所有节点主机中都创建这几张全局表
3.6.2 水平分表
场景: 在业务系统中, 有一张表(日志表), 业务系统每天都产生大量的日志数据, 单台服务器的数据存储以及处理能力是有限的, 可以对数据库表进行拆分
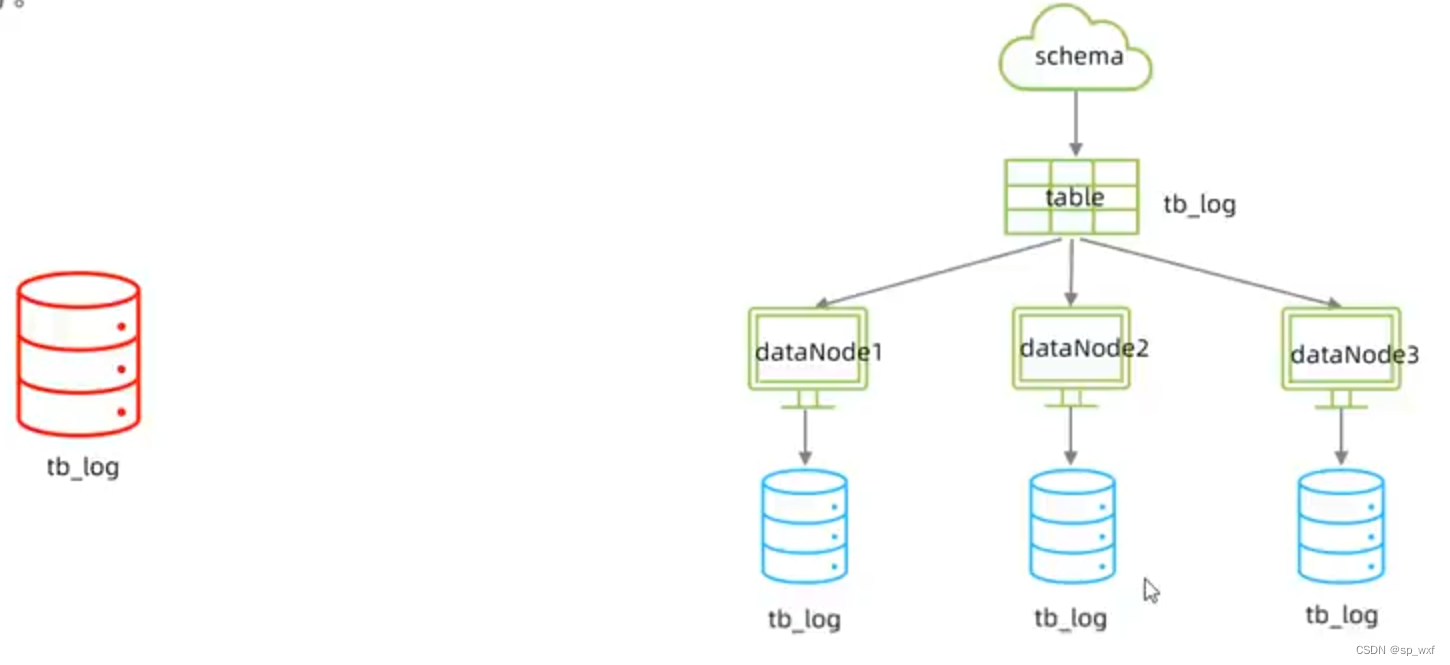
- 步骤一: 分别在三台Mysql中创建数据库itcast
- 步骤二: 通过
schema.xml定义逻辑库、逻辑表、分片规则、分片节点、节点主机等信息
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库 -->
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100">
<!-- 逻辑表 -->
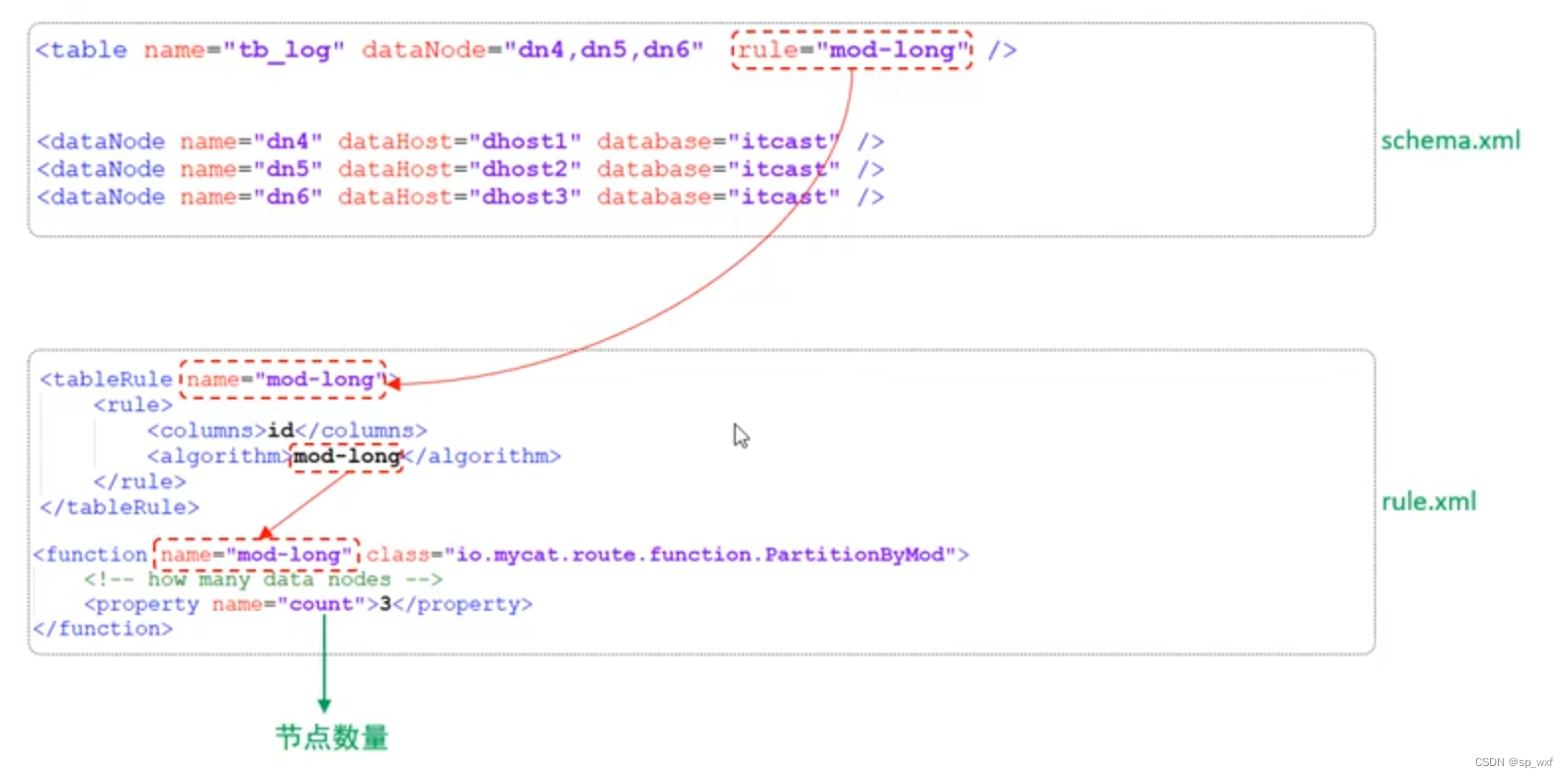
<table name="tb_log" dataNode="dn4,dn5,dn6" rule="mod-long" />
</schema>
<!-- 分片节点 -->
<dataNode name="dn4" dataHost="dhost1" database="itcast" />
<dataNode name="dn5" dataHost="dhost2" database="itcast" />
<dataNode name="dn6" dataHost="dhost3" database="itcast" />
</mycat:schema>
我们这次没有配节点主机, 因为节点主机与上面的案例是同一份
- 步骤三: 通过
server.xml配置mycat的用户以及用户的权限信息
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING, ITCAST</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
3.7 分片规则
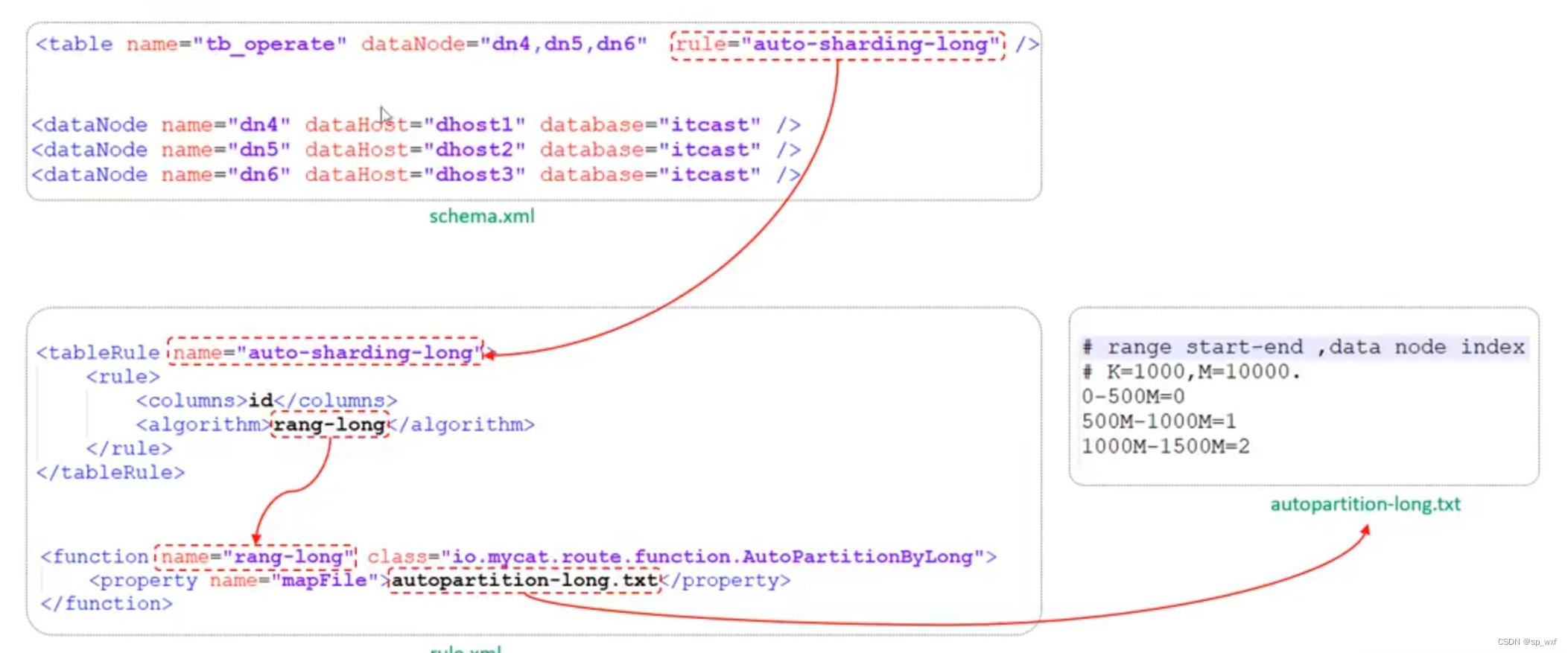
3.7.1 范围分片
3.7.2 取模分片
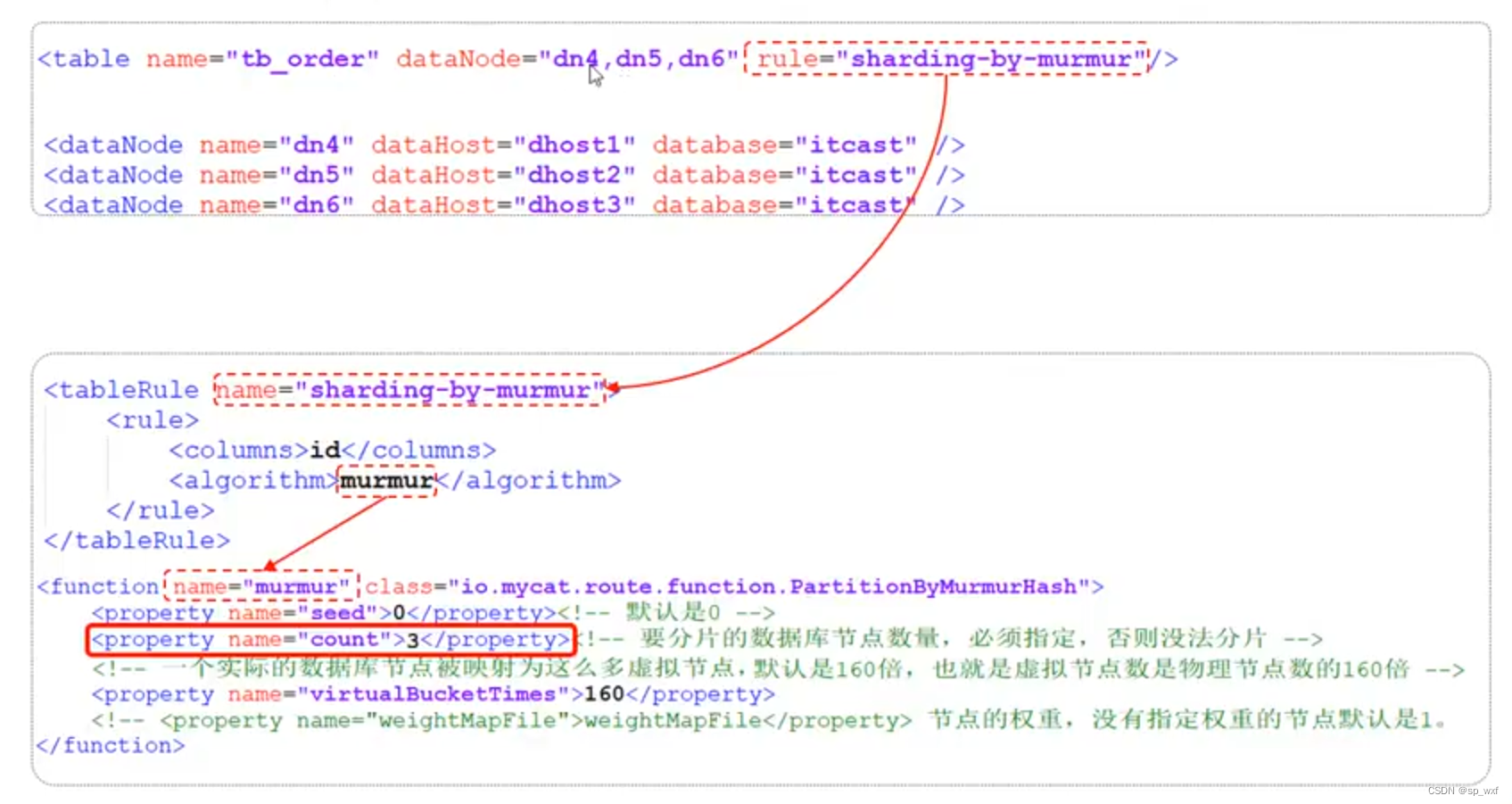
3.7.3 一致性hash
3.7.4 枚举分片

3.7.5 应用指定算法
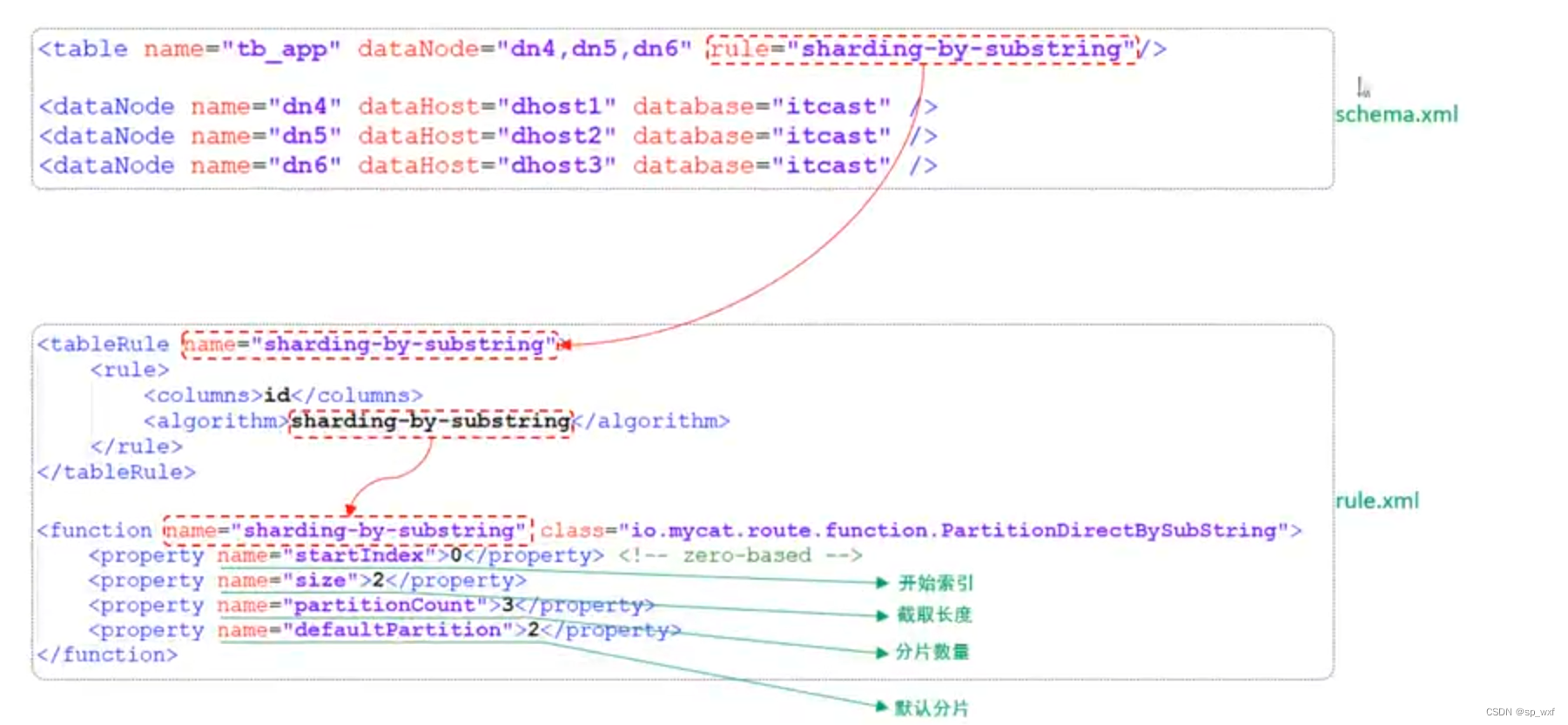
3.7.6 固定hash算法
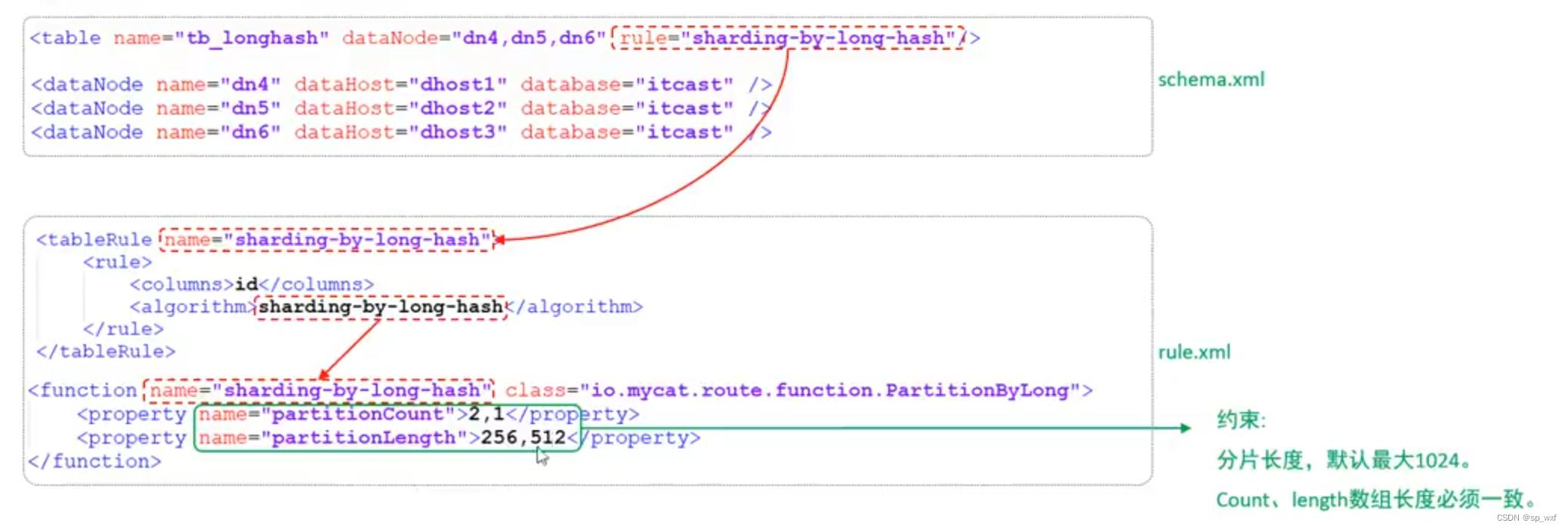
3.7.7 字符串hash解析
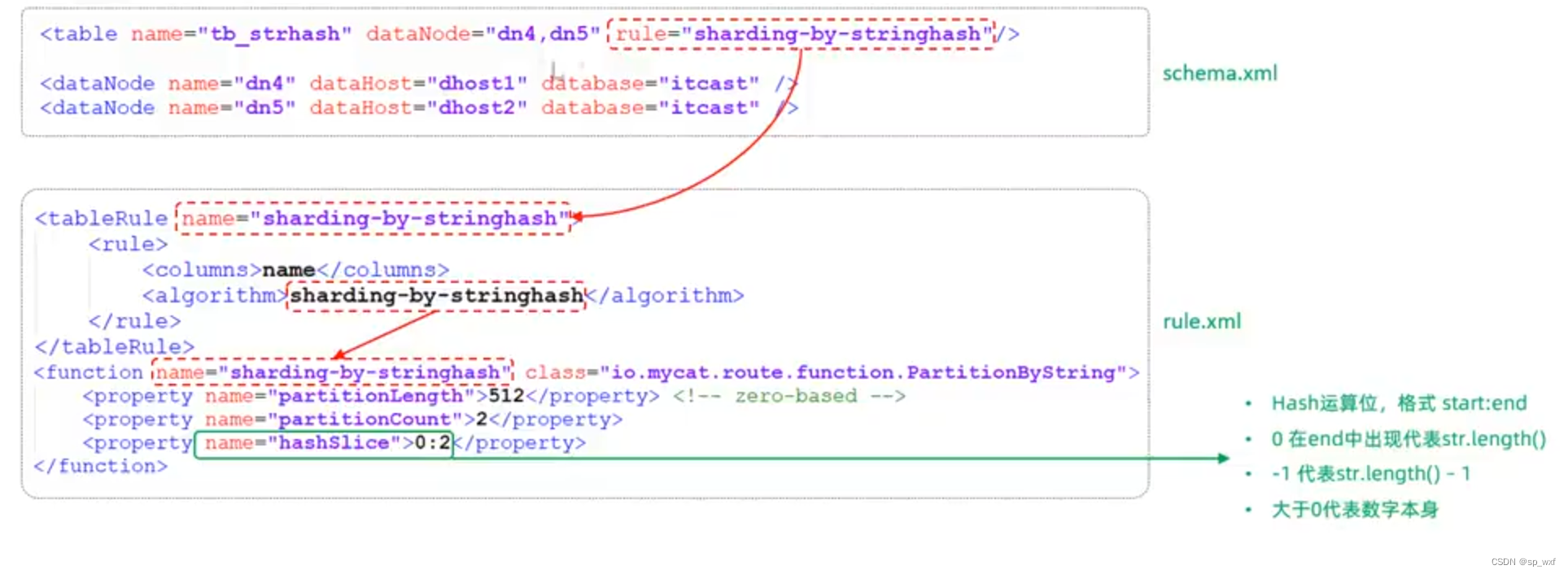
3.7.8 按天分片
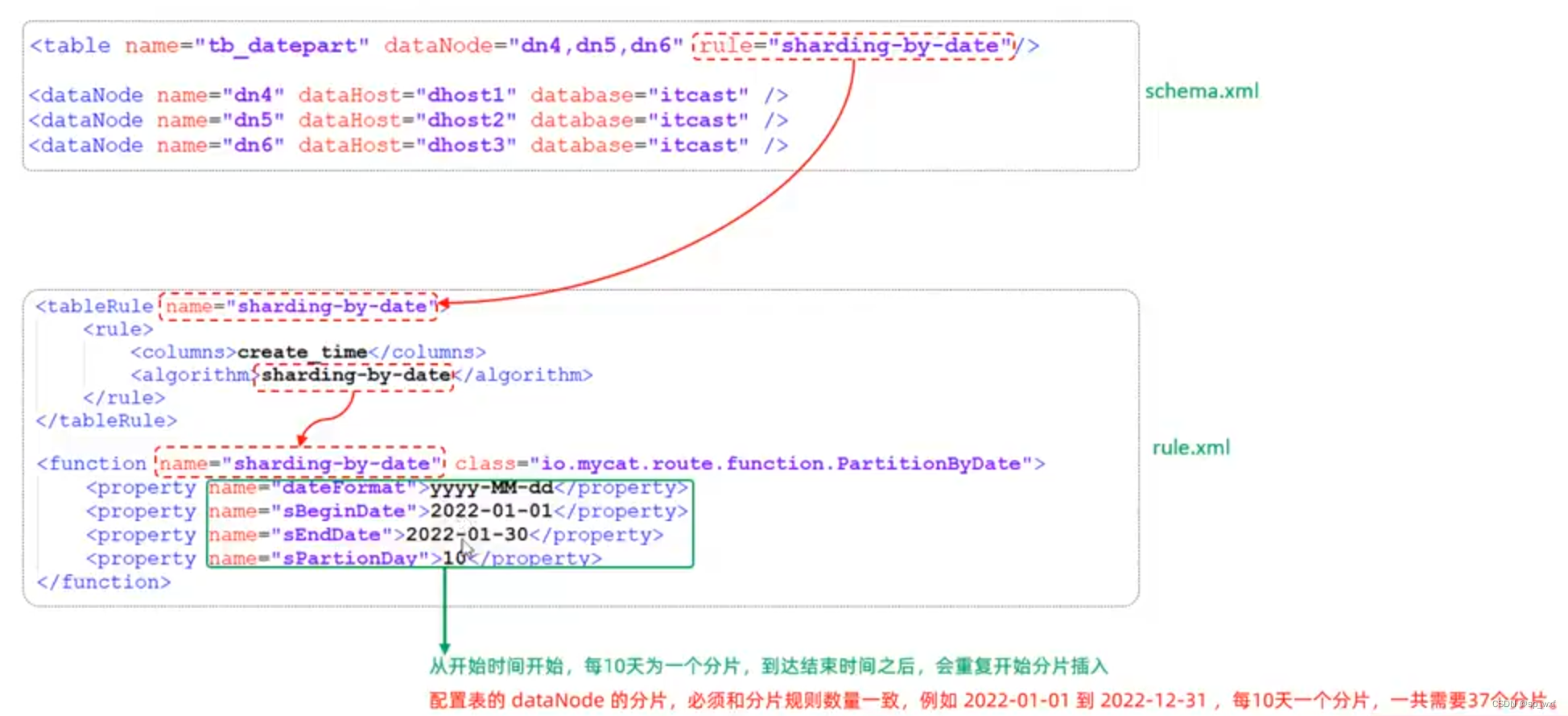
3.7.9 按自然月分片
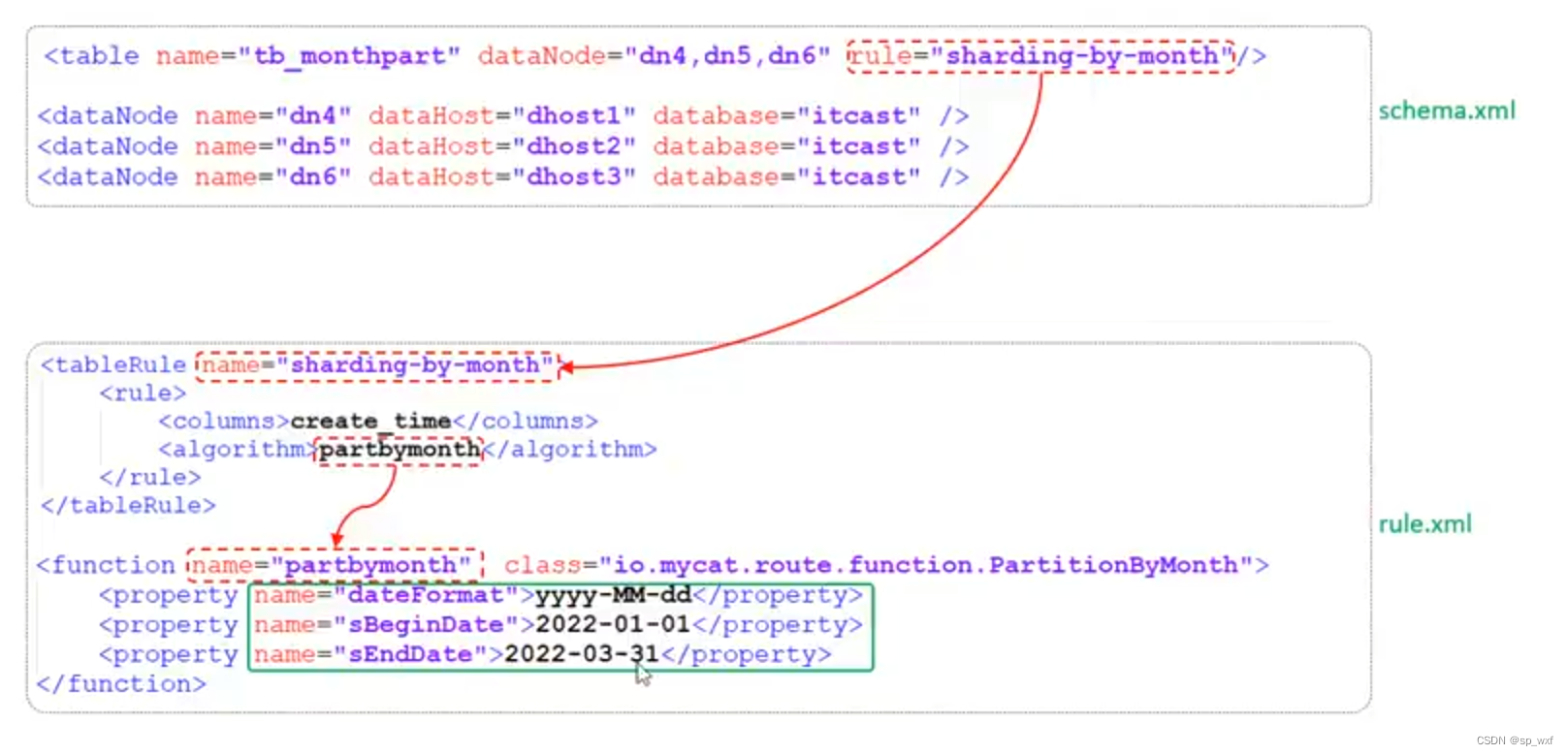
4.读写分离
4.1 一主一从读写分离
- 第一步: 通过
schema.xml定义逻辑库、逻辑表、分片规则、分片节点、节点主机等信息
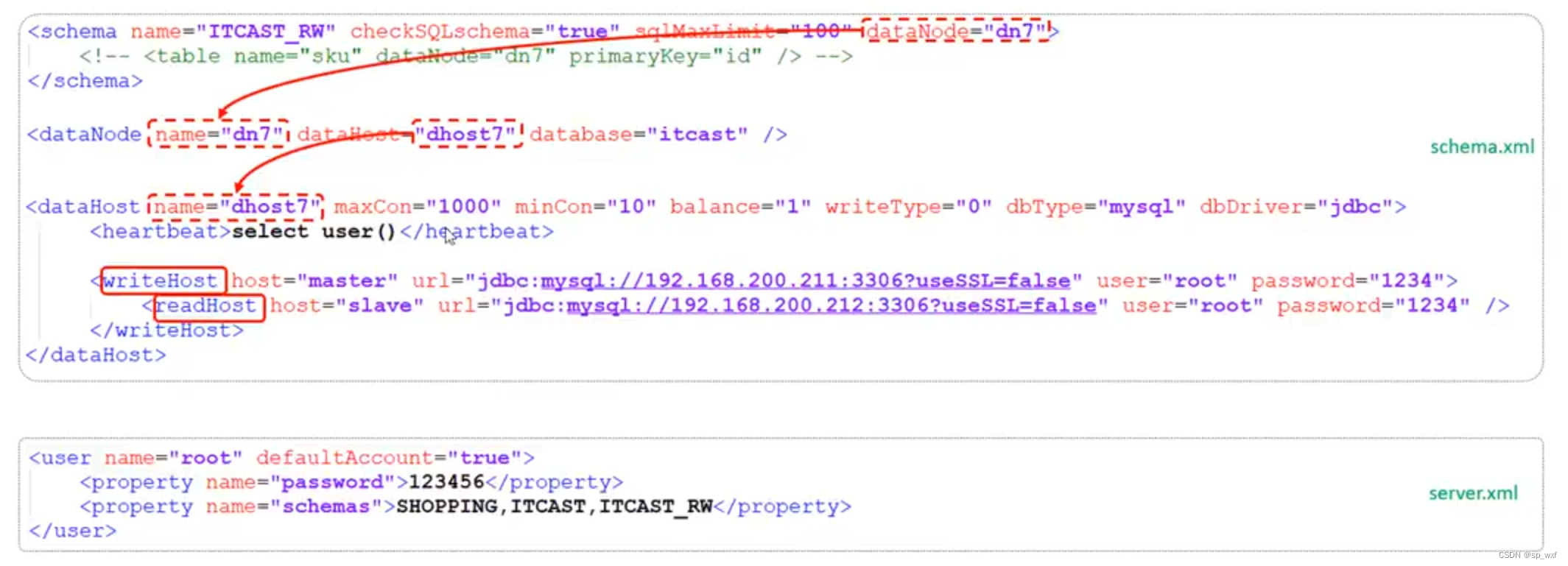
| 参数值 | balance的含义 |
|---|---|
| 0 | 不开启读写分离机制, 所有读操作都发送到当前可用的writeHost上 |
| 1 | 全部的readHost与备用的writeHost都参与select语句的负载均衡(主要针对于双主双从模式) |
| 2 | 所有的读写操作都随机在writeHost、readHost上分发 |
| 3 | 所有的读请求随机分发到writeHost对应的readHost上执行, writeHost不负担读压力 |
- 第二步: 重启mycat
4.2 双主双从读写分离
…















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









