







文章目录
组成
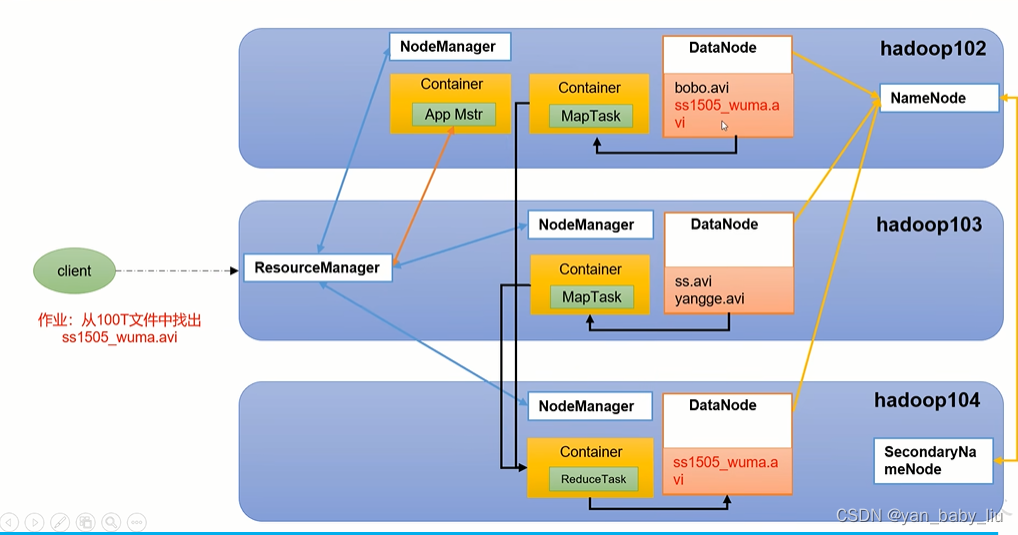
1.NameNode :存储文件元数据
2.DataNode :存储文件块数据
3.2NN :每隔一段时间对NameNode备份
4.YARN 管理cpu和内存,资源管理者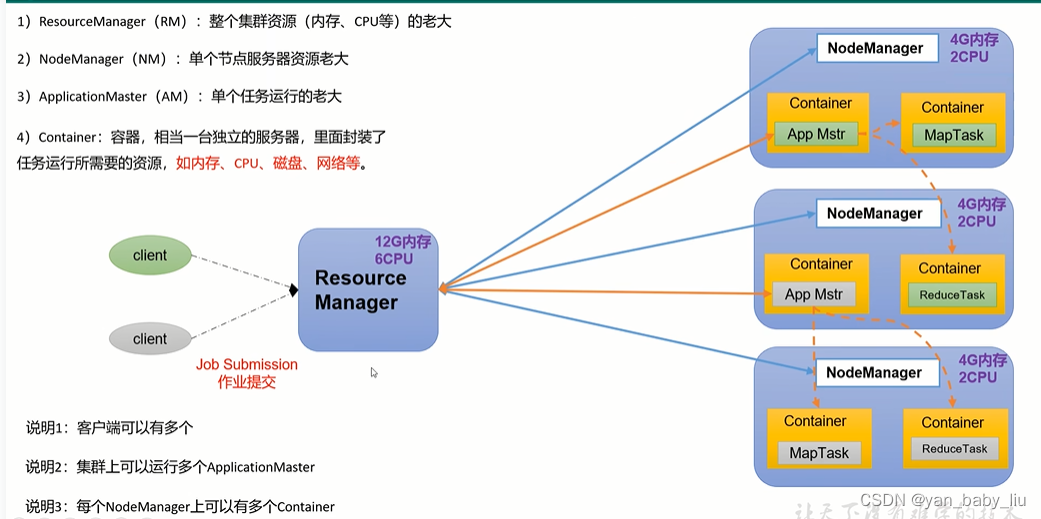
大数据生态
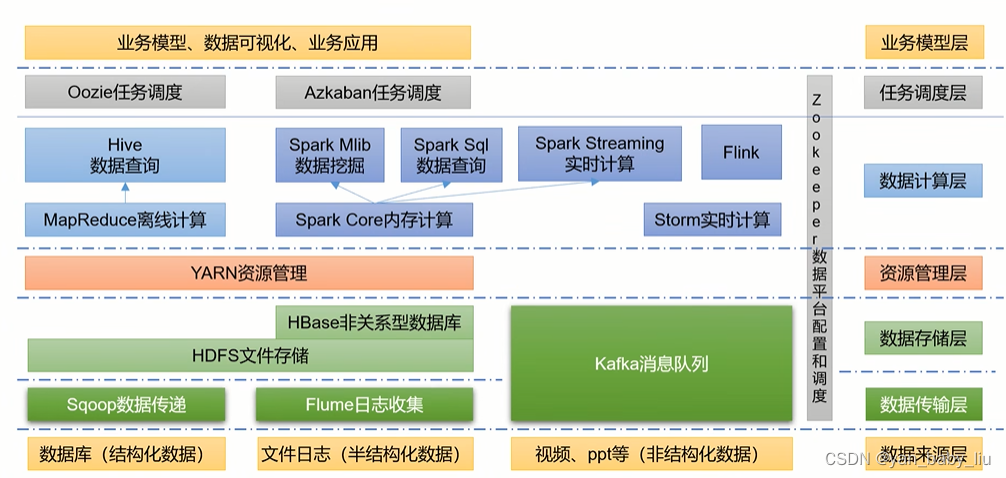
Mapreduce是基于硬盘的
Storm基本已经过气了,老的项目在用
Flink new
虚拟机搭建
搭建硬件
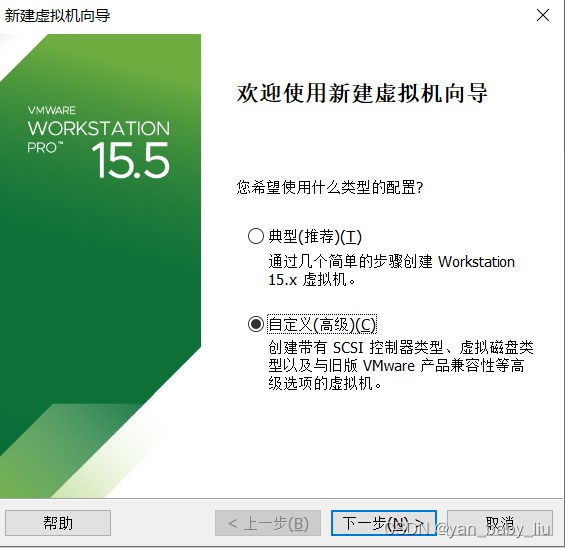
直接下一步
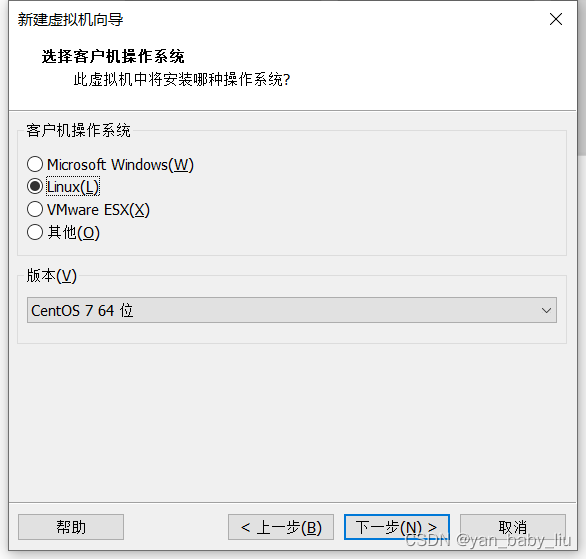
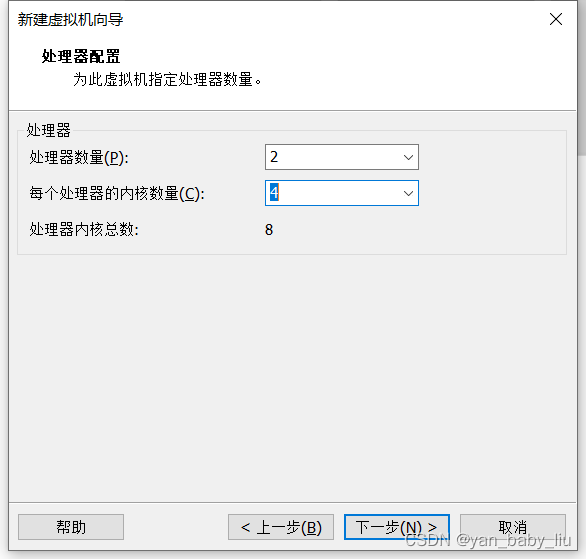
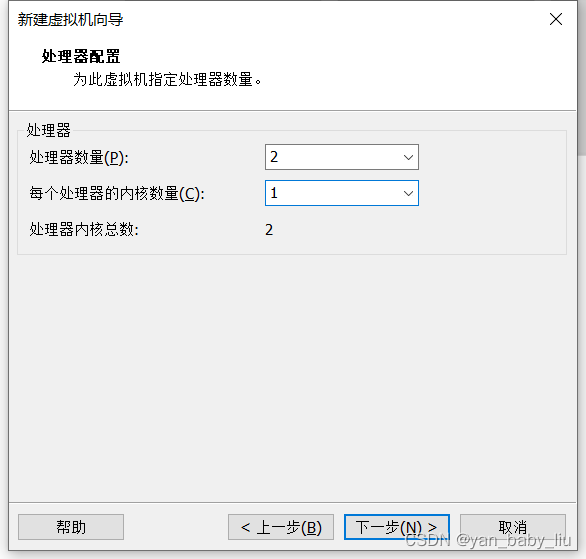
因为我本机cpu处理器是8核的,所以这里配置的内核总数不能超过8,而我打算部署四个虚拟机,所以每个虚拟机,也就是2核
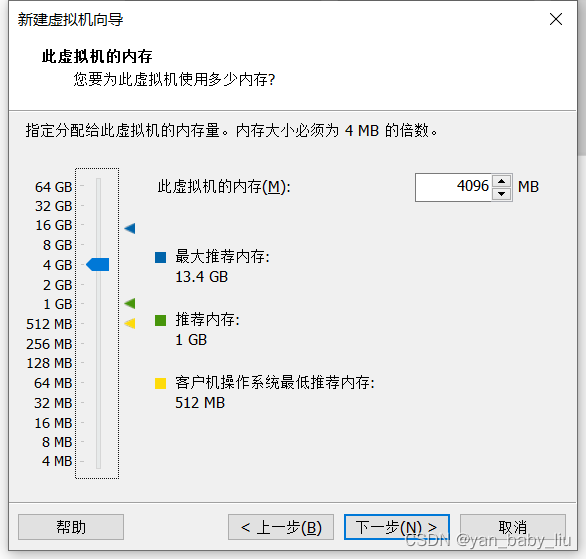
下一步,默认都是推荐的
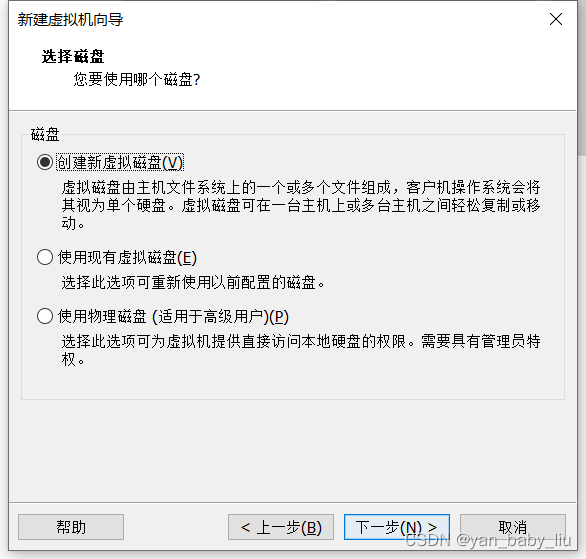
这是设置最大是50G,并不是一定会占用这么多
点击浏览,可以更改存放位置
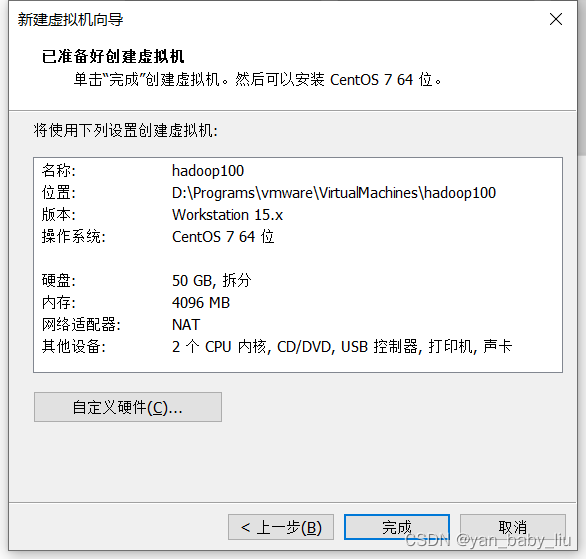
直接点击完成
安装操作系统
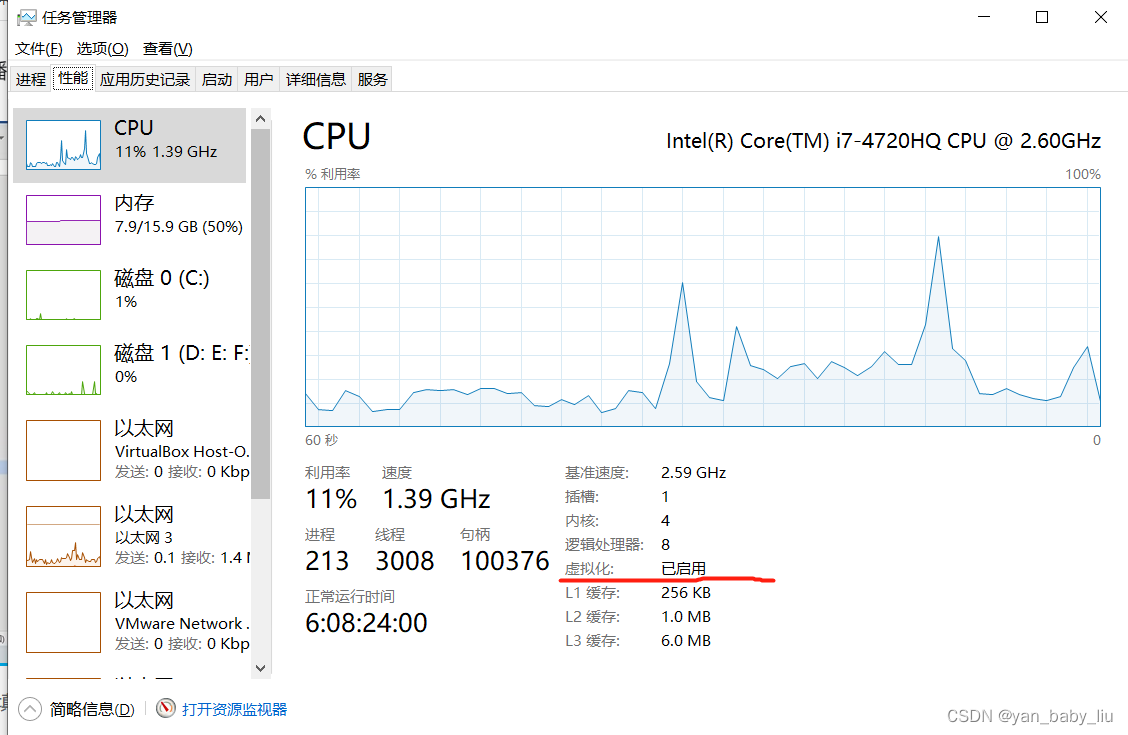
先确保虚拟化技术已经开启
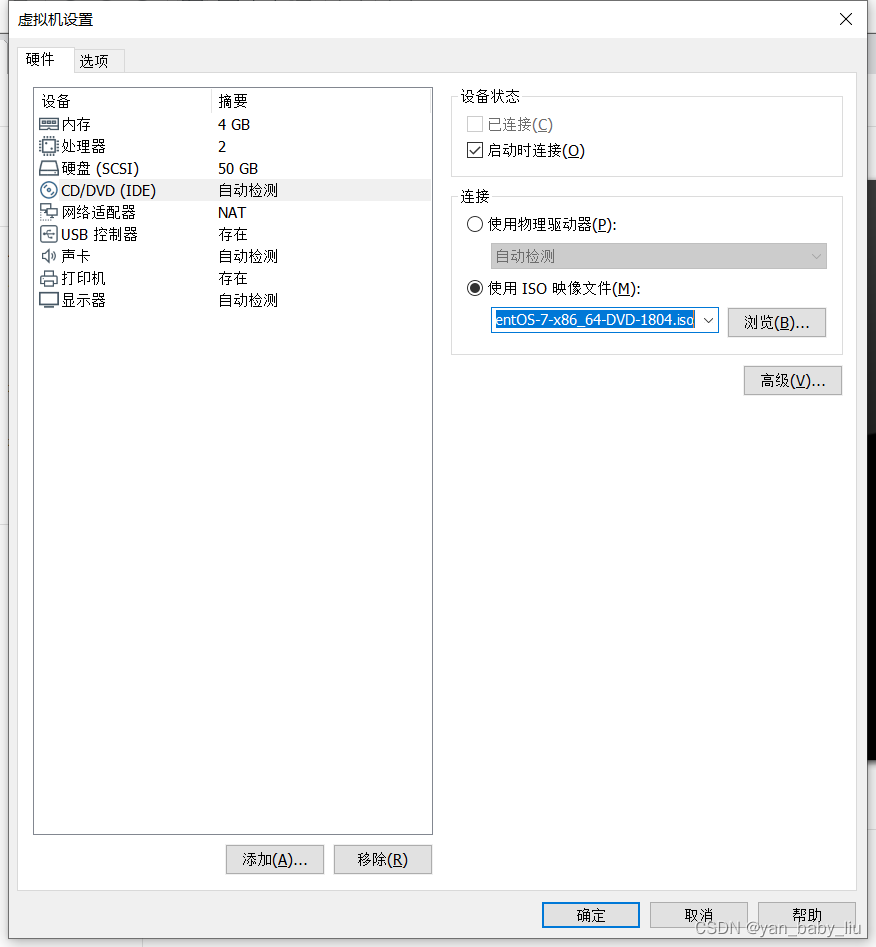
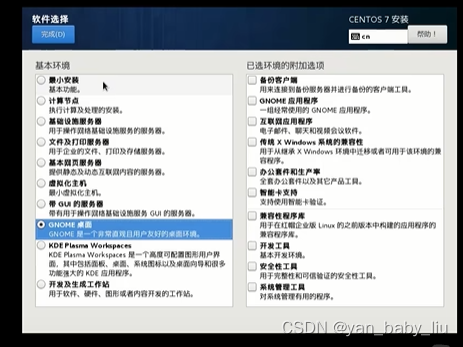
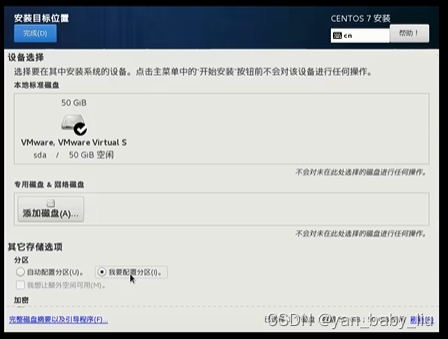
选择我要分配,点击完成
点击+号
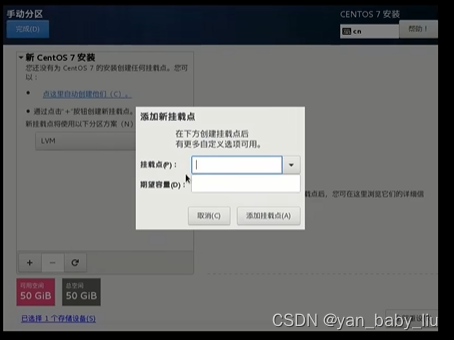
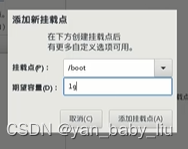
刚启动电脑的时候,配置1g
添加完毕以后,修改文件系统为ext4
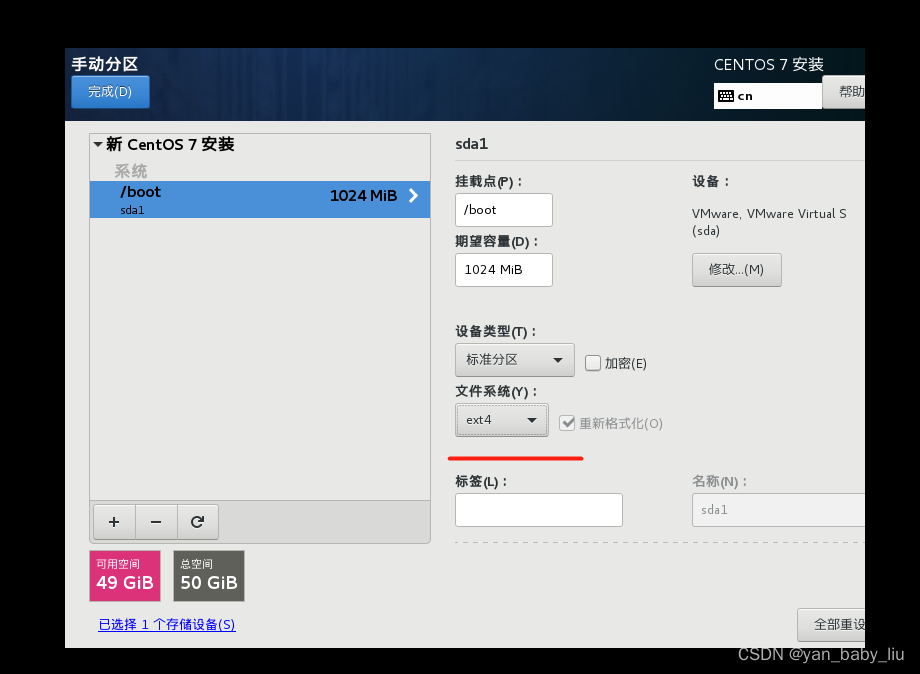
swap 当内存不够了的时候,可以用一块硬盘当做是内存
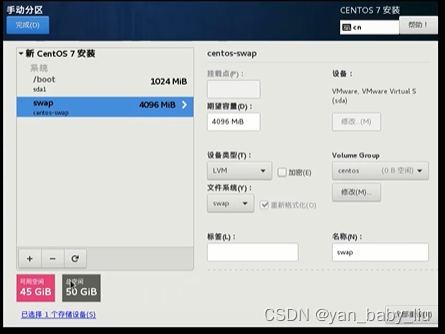
另外设置根目录/ 为45G
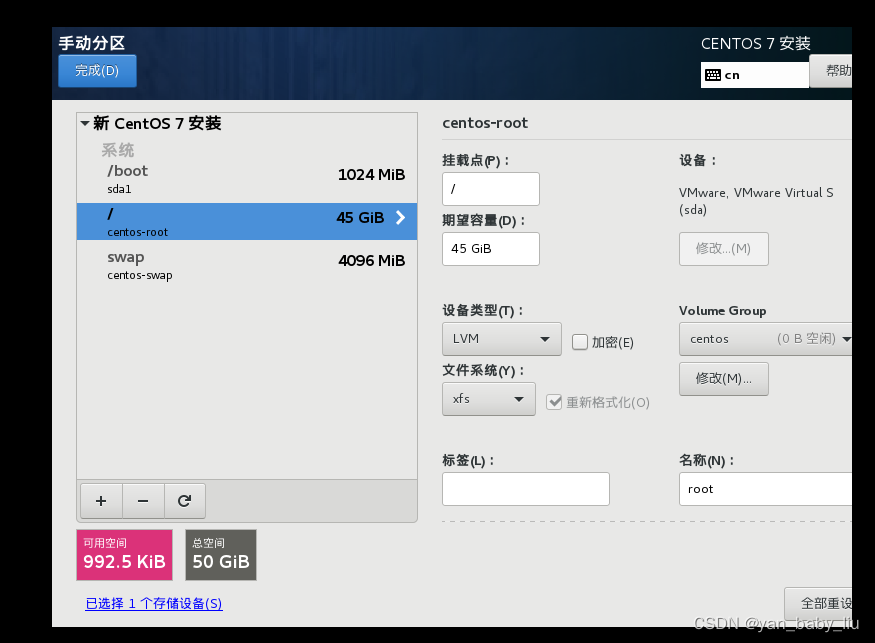
完成–接受并更改
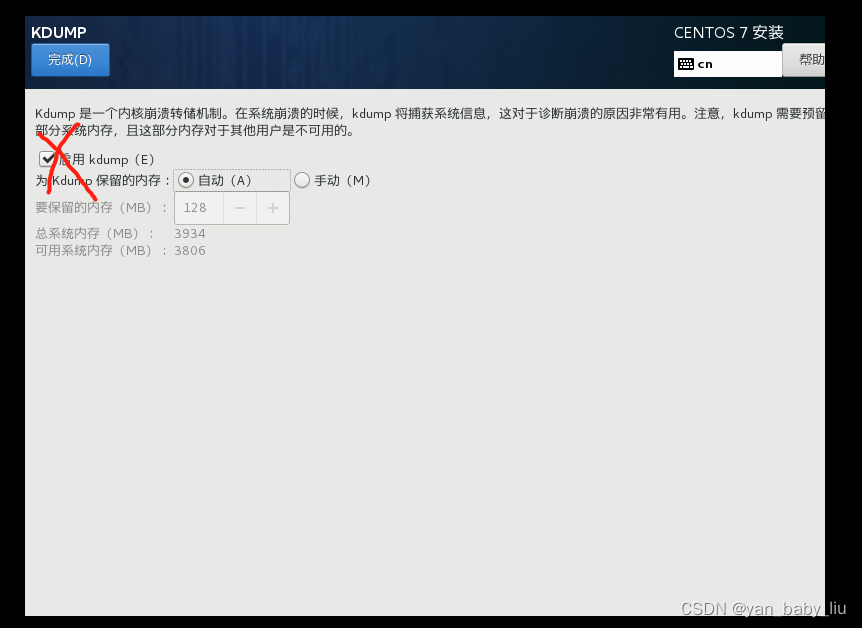
关闭KDUMP ,就是系统崩溃的时候,会开辟一块空间,做数据备份,因为我们是学习阶段,所以这块关闭掉
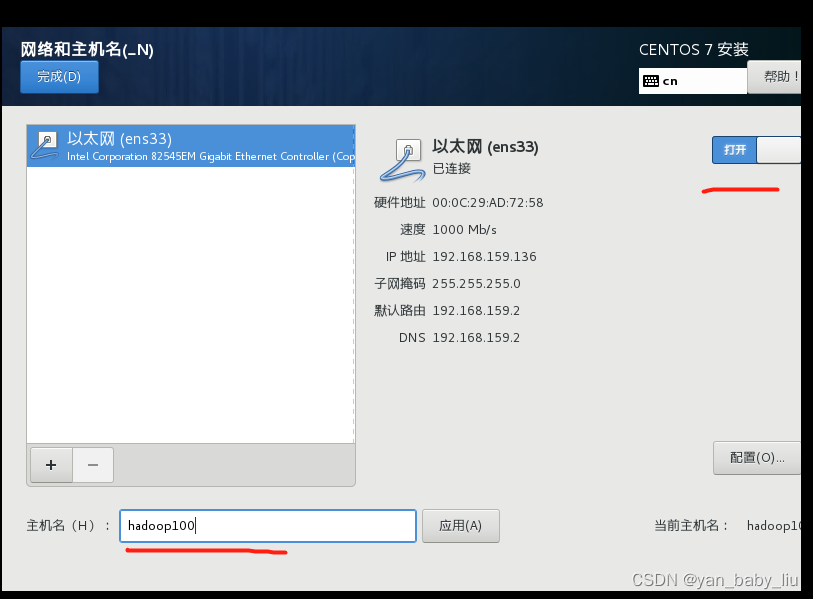
配置网络和主机名
安装完以后reboot
设置了root 123456
设置了普通用户yanweiling 123456
配置IP地址
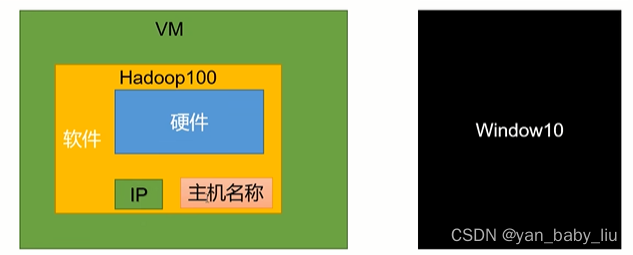
配置VM的IP
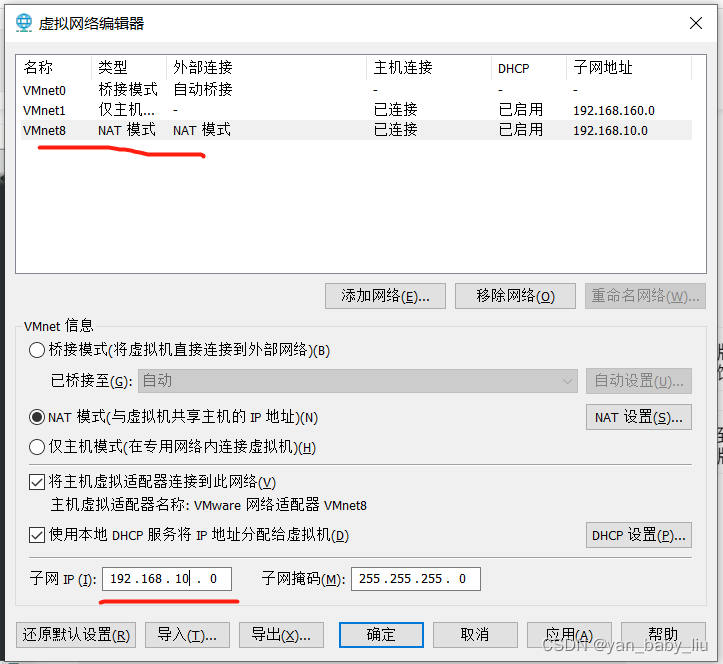
虚拟机–编辑–虚拟网络编辑器
点击VMnet8,点击更改设置

再点击VMnet8
更改子网IP
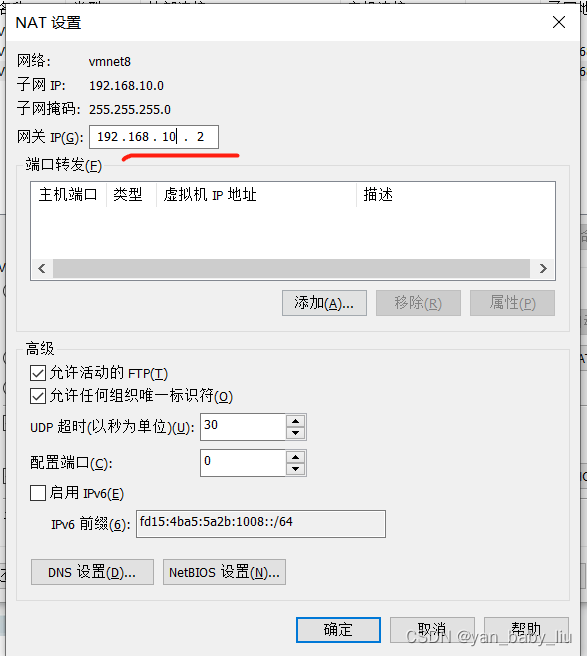
点击NAT设置
配置Window10
打开window的以太网–>更改适配器
点击VMnet8,属性
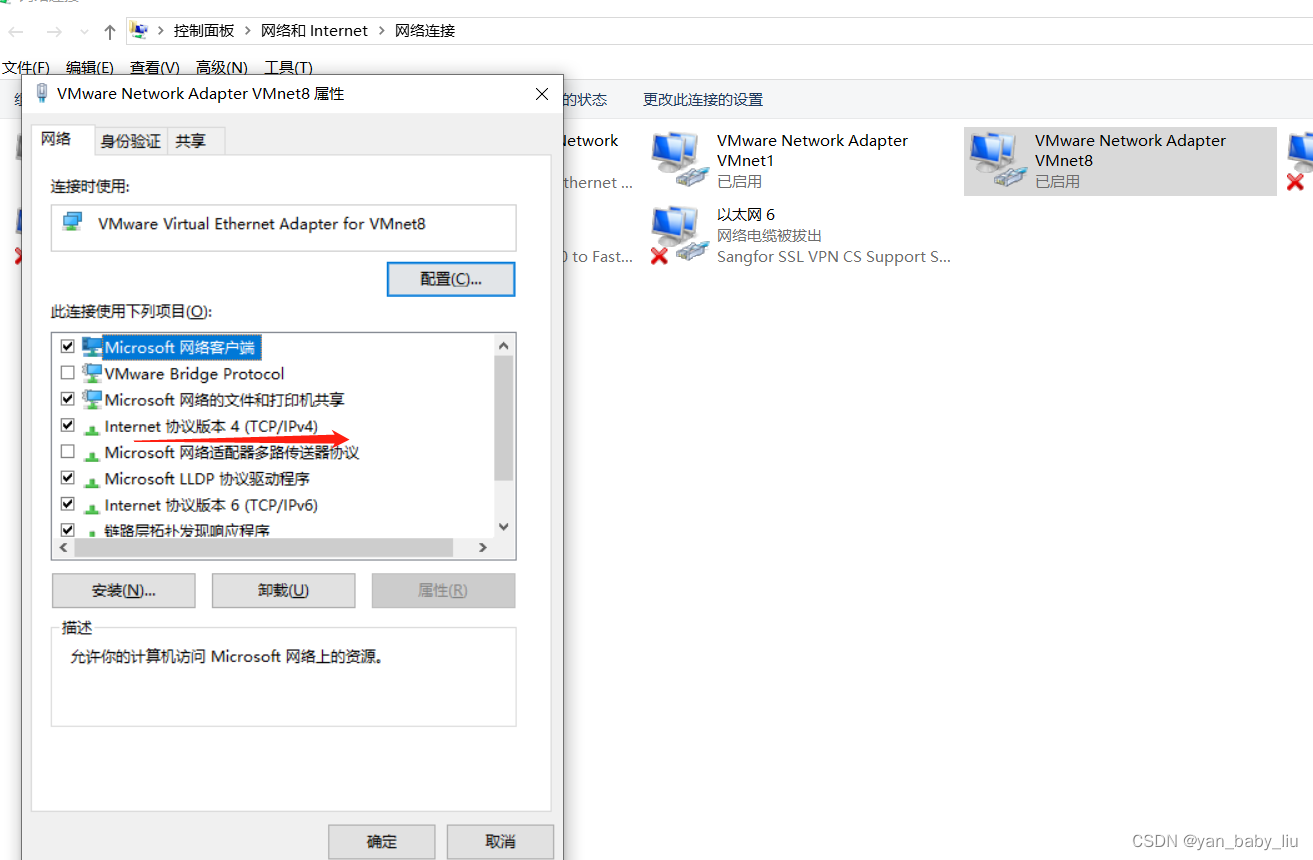
双击Internet协议版本4
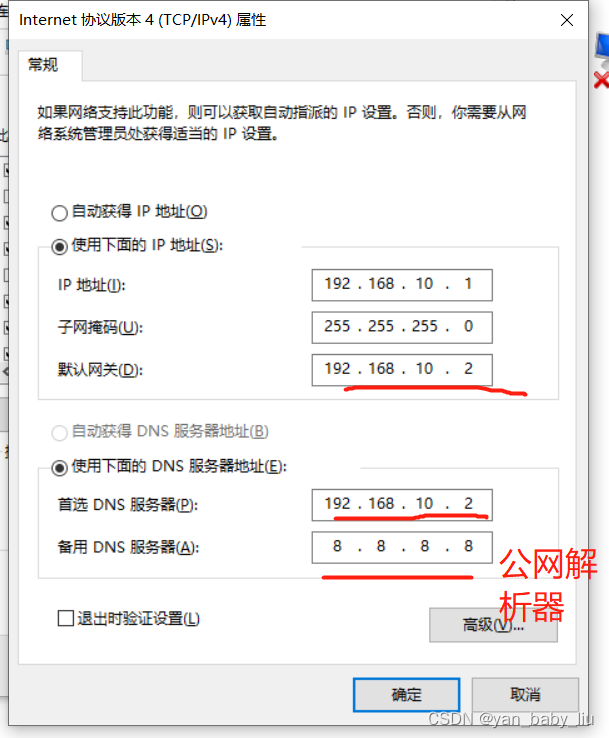
输入网关和DNS服务器,和公网解析器8.8.8.8
配置Hadoop100的IP
登录到hadoop100
切到root用户
su root
[root@hadoop100 yanweiling]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
原内容
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="d71d864d-dc61-4ac8-8040-b7efde9b7153"
DEVICE="ens33"
ONBOOT="yes"
将BOOTPROTO由动态获取ip变成静态ip
BOOTPROTO=“static”
后面增加
IPADDR=192.168.10.100
GATEWAY=192.168.10.2
DNS1=192.168.10.2
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="d71d864d-dc61-4ac8-8040-b7efde9b7153"
DEVICE="ens33"
ONBOOT="yes"
#IP地址
IPADDR=192.168.10.100
#网关
GATEWAY=192.168.10.2
#域名解析器
DNS1=192.168.10.2
修改主机名称
[root@hadoop100 yanweiling]# vim /etc/hostname
检查是否是hadoop100
修改主机名称映射
vim /etc/hosts
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
修改完成以后,reboot
重启以后,查看
[yanweiling@hadoop100 ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.100 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::4b5d:e670:d498:d2a2 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:ad:72:58 txqueuelen 1000 (Ethernet)
RX packets 36 bytes 11620 (11.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 65 bytes 8317 (8.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 72 bytes 8088 (7.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 72 bytes 8088 (7.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:2d:c5:1b txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[yanweiling@hadoop100 ~]$
虚拟机可以ping www.baidu.com
window10 ,也可以ping 通192.168.10.100
运行环境准备
安装epel-release
这个属于一个软件仓库,大多数rpm包在官方repository中找不到
安装要切到root用户
关闭防火墙
在企业开发的时候,通常单个服务器的防火墙是关闭的,公司整体对外设置非常安全的防火墙
systemctl stop firewalld
systemctl disable firewalld.service 开启启动的时候也给关闭掉
创建普通用户
这里就不操作了,因为安装的时候,就已经创建用户yanweiling了
如果安装的时候,没有创建,则按照如下方式创建
useradd yanweiling
passwd yanweiling
配置普通用户具有root权限
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:

注意:yanweiling这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了yanweiling具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以yanweiling要放到%wheel这行下面。
这样,当我们用yanweiling用户去
/opt目录下创建目录的时候
[yanweiling@hadoop100 opt]$ mkdir module
mkdir: 无法创建目录"module": 权限不够
[yanweiling@hadoop100 opt]$ sudo mkdir module
[yanweiling@hadoop100 opt]$
我们发现,不用密码输入了
未来安装的软件都放这里
修改文件夹所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为atguigu用户
[root@hadoop100 ~]# chown atguigu:atguigu /opt/module
[root@hadoop100 ~]# chown atguigu:atguigu /opt/software
(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 atguigu atguigu 4096 5月 28 17:18 module
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 atguigu atguigu 4096 5月 28 17:18 software
卸载自带的JDK
因为我们是桌面版安装的,所以需要卸载自带的jdk
注意:如果你的虚拟机是最小化安装不需要执行这一步。
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e –nodeps:强制卸载软件
重启虚拟机
reboot
虚拟机Clone
先关闭hadoop100
关闭以后,右键hadoop100–>管理–>克隆
下一步,直接到
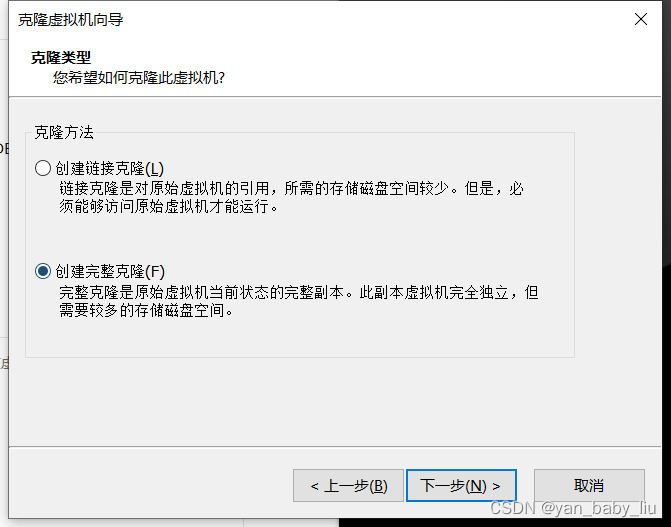
我们选择完整的克隆
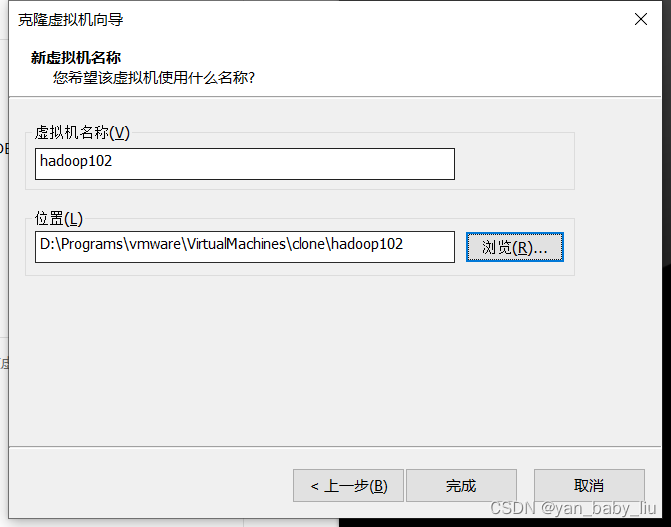
同样的方式,
克隆三台虚拟机:hadoop102 hadoop103 hadoop104
配置每台服务的ip和主机名称
例如在hadoop102上
[root@hadoop100 yanweiling]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
将ip修改为192.168.10.102
[root@hadoop100 yanweiling]# vi /etc/hostname
修改为hadoop102
这样我们就有四台机器 hadoop101 hadoop102 hadoop103 hadoop104了
本地我将hadoop100改为了hadoop101















 3381
3381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









