






本文章基于的大数据文件:
https://download.csdn.net/download/qq_60567426/87940872?spm=1001.2014.3001.5503
引言:虚拟机经常卡死,卡死就按这个重新启动

VMware虚拟机下载:
1:首先安装VMware,官网链接:
VMware - Delivering a Digital Foundation For Businesses
2:点击Products并点击Workstation Pro

3:下拉并找到试用版VMware下载

4:下拉并找到Windows版本VMware下载虚拟机

Ubuntu20.04.6.iso镜像下载(单纯的20.04没有terminal,换成了20.04.6才有):
(虚拟机相当于一个电脑壳,镜像相当于壳里的灵魂,才组成了一个完整的东西)
1:去Ubuntu官网下载镜像,官网链接:
Enterprise Open Source and Linux | Ubuntu
2:下载桌面版的Ubuntu

3:下拉去找以前的版本


![]()

等待大概30min下完
虚拟机配置:
1:点击VMware并点击创建新的虚拟机

2:选择自定义然后下一步,硬件兼容性不管直接下一步
3:选择自己刚才下载好的镜像的路径

3:填写安装信息(登录系统要用,这里记好,下面的密码为123456,可自己设置)

4:命名虚拟机不管,直接下一步。

(默认配置足够用了,直接下一步)
5:一直下一步到配置虚拟磁盘大小为40GB,然后一直下一步到结束。
虚拟机与主机联网配置(不联网linux的安装指令和去网页下载东西都不行,这部分比较多,沉下心操作):
1:启动虚拟机等待其安装系统结束
2:配置网络(此时虚拟机是用不了网络的)
因为创建虚拟机的时候使用的是NAT模式,使用的是VMnet8,在自己的windows系统电脑中使用win+R并输入cmd,在命令行界面输入ipconfig:


We can see that VMnet8's ip address is192.168.200.1,当然不同的电脑在不同的地区不一样,看自己的电脑就行。
3:网关与网段的介绍(步骤4的前导知识)
网段:网络地址相同的IP地址属于同一网段,即同一子网。
网关:同一网段(子网)间终端可直接通信,不在同一网段(子网)的终端不能直接通信,需要通过网关才能通信。
4:点击VMware的虚拟网络编辑器

5:点击VMnet8然后点击NAT设置,并将网关设置为与子网IP前三个数字相同但是最后一个数字为2-254中任意一个数字(我以2为例),保证宿主机与虚拟机网关相同。


6:在windows系统中的控制面板一直打开到网络连接位置:

7:右键VMnet8的属性

8:右键Internet协议版本4(TCP/IPV4)的属性,并设置默认网关与第5步相同的网关并点击确定,每个人的电脑是不一样的。

9:打开虚拟机的火狐浏览器,左边导航栏的那只狐狸图标,然后点击setting,并修改搜索引擎search为bing


10:即可上网浏览(这个镜像没有中文输入法,命令可搜索其它博客,因为用不到,所以我没下载)

Xshell安装(去官网下载即可):

虚拟机上安装ssh并用xhell连接虚拟机
能否用xshell链接虚拟机,需要被连接机器上安装有ssh。
ssh安装步骤:
1:在Ubuntu桌面右键点击Open in Terminal

2:输入sudo su到root用户下面

3:输入下面命令(如果哪条指令没有就可以去网上搜安装命令):
安装ssh
apt-get install openssh-servercd /etc/ssh/vim sshd_config注意:

修改为:

ssh localhost输入yes,然后乱输,一直结束,然后直接往下操作,别管他的报错。
cd ~/.ssh/ssh-keygen -t rsa一直回车
cat ./id_rsa.pub >> ./authorized_keys4:输入ifconfig,查看ens33的inet为多少,然后用xshell去连接,这里我的是192.168.200.129

5:在xshell新建会话

6:输入虚拟机的ip地址

7:双击master
![]()
8:因为虚拟机信息就用的master

这里的密码是自己虚拟机的密码


这样就连接上自己的虚拟机了
JAVA环境安装
1:在https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html下载
 2:在hadoop官网下载hadoop-2.7.7
2:在hadoop官网下载hadoop-2.7.7
3:在Ubuntu命令行中安装sz命令与rz命令(记得在xshell中使用sudo su到root用户)
apt-get install lrzsz4:
cd /home/master/mkdir bighomeworkcd bighomework
5:从windows上传文件到Ubuntu上面
rz
6:解压这两个文件:
tar -zxvf jdk-8u371-linux-x64.tar.gztar -zxvf hadoop-2.7.7.tar.gz![]()
7: 配置环境变量
cd /etcvim profile在文件中输入(注意这个master路径是不是自己虚拟机的,不要直接粘了就不管了)
export JAVA_HOME=/home/master/bighomework/jdk1.8.0_371
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/home/master/bighomework/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存文件并退出
执行
source profile
java -versionhadoop version可以看到

 配置hadoop-env.sh
配置hadoop-env.sh
cd /home/master/bighomework/hadoop-2.7.7/etc/hadoopvim hadoop-env.sh输入
export JAVA_HOME=/home/master/bighomework/jdk1.8.0_371
export HADOOP_HOME=/home/master/bighomework/hadoop-2.7.7
配置core-site.xml
vim core-site.xmlcd /home/master/bighomework/hadoop-2.7.7mkdir tmpcd /home/master/bighomework/hadoop-2.7.7/etc/hadoopvim core-site.xml输入
<property>
<name>hadoop.tmp.dir</name>
<value>/home/master/bighomework/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>

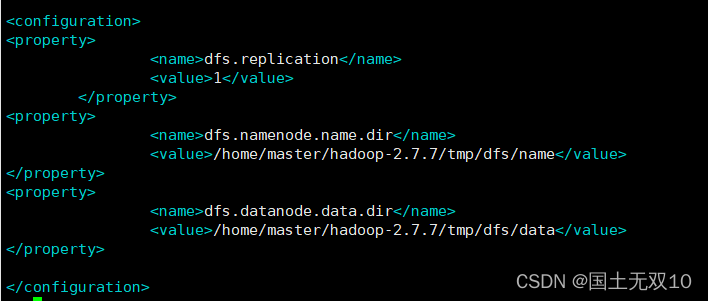
配置hdfs-site.xml
vim hdfs-site.xml<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/master/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/master/hadoop-2.7.7/tmp/dfs/data</value>
</property>
cd /home/master/bighomework/hadoop-2.7.7/tmpmkdir dfscd dfsmkdir namemkdir data启动hadoop集群节点
hdfs namenode -formatcd /home/master/bighomework/hadoop-2.7.7/sbinstart-dfs.sh
等待结束(可能会暂停输入yes)
jps

可以看到DataNode与NameNode与SecondaryNameNode启动成功
cd /home/master/bighomework/hadoop-2.7.7/etc/hadoopvim yarn-site.xml输入
<property>
<name>yarn.nodemanager.aux-services </name>
<value>mapreduce_shuffle</value>
</property>

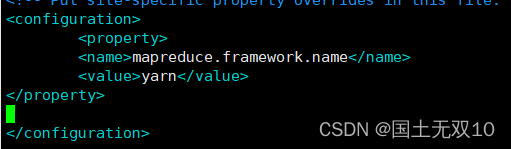
vim mapred-site.xml.template
输入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
cd /home/master/bighomework/hadoop-2.7.7/sbinstart-all.sh等待运行结束
jps
可以发现六个东西都出来了
数据处理:
1:这是一个乱码csv

2:将该csv以txt文本形式打开

3:txt是不乱码的

4:点击文件的另存为

5:选择带有BOM的UTF-8进行保存(也可以ANSI,只是不知道后面的idea代码会不会识别ANSI格式文字不乱码)
 6:csv正常显示
6:csv正常显示

处理好文件后将文件上传到bighomework文件夹下,再创建一个project(后面用)

hadoop dfs -put data.csv /hadoop dfs -ls /
文件已上传上去
下载idea编译器
在VMware虚拟机的火狐浏览器中输入idea


点击下载后,下拉页面并下载社区版的idea,这是一个tar.gz,按照前面的解压缩命令可以执行安装。

下载完后进入xshell输入
cd /home/master/Downloads默认的Ubuntu下载都在这个文件夹下

tar -zxvf ideaIC-2023.1.3.tar.gz ![]()
但凡下载的东西都在在Downloads下面运行
在VMware虚拟机打开Open in Terminal

sudo sucd ~/Downloads/idea-IC-231.9161.38/bin
./idea.sh 
于是打开了idea,开始点击New Project,创建一个Maven工程文件,我将工程文件放在了
/home/master/bighomework/project下面

JDK路径为下载的安装包

在Pom.xml文件中添加
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.1.2</spark.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
</exclusion>
</exclusions>
<!-- <scope>provided</scope> -->
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>点击右侧Maven,并点击这个圈圈进行更新。

在Main类中代码改为如下(注意爆红的类引入类,之前Pom已经把这些类下好了),通过Spark读取之前上传的csv的文件:
public class Main {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data.csv",
1);
System.out.println(rdd.first());
}
}执行结果如下:

mysql配置:
1:打开Open in Terminal

2:
sudo susudo apt updatesudo apt install mysql-serversudo systemctl start mysqlmysqlMysql命令一定是以冒号结尾的
3:开始给所有用户赋予访问权限:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';flush privileges;SHOW VARIABLES LIKE 'validate_password%';
SET GLOBAL validate_password.policy = LOW;SET GLOBAL validate_password.length = 6;exitexit回到主命令行,不是mysql里面了。
4:
sudo mysql_secure_installation填入密码
Do you wish to continue with the password provided? 填y
Remove anonymous users?填n
Disallow root login remotely?填n
Remove test database and access to it? 填n
Reload privilege tables now? (Press y|Y for Yes, any other key for No) 填n
5:之后登录mysql使用命令
mysql -u root –p然后键入自己的密码(第6步,我设的是123456)
6:进入mysql后,
show databases;
7:开始创建自己的数据库和表:
create database hotel;![]()
use hotel;create table room (province varchar(60),rooms varchar(16));ALTER TABLE room CONVERT TO CHARACTER SET utf8mb4;insert into room(province,rooms) values("四川","20");select * from room;
此时mysql已经配置好了。
idea测试mysql能否使用
1:检查自己mysql的版本mysql –V,我的是8.0.33,然后进入Maven Repository: mysql » mysql-connector-java (mvnrepository.com)搜索Maven中对应版本的connector连接器。
![]()


2:打开VMware虚拟机的idea工程文件,并导入该段代码到Pom.xml


一开始可能导不进去,下面命令行会有蓝色报错force import开始强制导入,点一下,多试试,会成功的。
3:在Main类里面写下下面代码,目的是向mysql表插入"sichuan","20",注意String driver可能不一样,mysql5.x与mysql8.x不一样,我的是8.x的,所以有cj
package不要复制,看看自己的工程的package,保留它。
package org.example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.concurrent.locks.ReentrantReadWriteLock;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
insertData("room","sichuan","20");
}
public static void insertData(String tableName, String data1, String data2) throws ClassNotFoundException, SQLException {
String driver = "com.mysql.cj.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/hotel?useUnicode=true&characterEncoding=utf8";
String user = "root";
String password = "123456";
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, user, password);
PreparedStatement preparedStatement;
String sql = "insert into " + tableName + " values (?,?)";
preparedStatement =connection.prepareStatement(sql);
preparedStatement.setString(1,data1);
preparedStatement.setString(2,data2);
preparedStatement.executeUpdate();
System.out.println("churuchenggong");
}
}4:查询结果

证明mysql数据库可以在idea中调用并使用。
Pycharm安装
1:下载Pycharm,并创建工程,同idea的下载方式。


社区版足矣
2:解压并安装,默认路径都是Downloads,跟idea在一块
cd /home/master/Downloadstar -zxvf pycharm-community-2023.1.2.tar.gz![]()
3:进入pycharm的bin文件夹,并启动pycharm
cd /home/master/Downloads/pycharm-community-2023.1.2/bin./pycharm.sh
与idea的工程文件同文件夹下再创建一个pycharmproject,作为python工程的使用空间。


4:点击create,等待pycharm自动配置完成。(虚拟机太卡就看引言部分,文章最上面)

pycharm有自带的python3.8的解释器,所以可以直接执行,到此pycharm配置好了
最后就是利用idea编写Spark调用RDD的代码来处理大数据存到mysql数据库,并用pycharm做可视化的操作。
大数据Spark代码合集+讲解(重点)都在自己的Main类操作,package填自己的Main类所在目录。
data.csv


一:
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.rdd.RDD;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data.csv",1);
System.out.println(rdd.first()); //读取csv第一行的数据
System.out.println(rdd.toJavaRDD().count());//读取csv非空的行总数
}
}1:SparkConf 是 Spark 的配置类,想用Spark都需要有它,相当于汽车发动机,不然开不了车。(心脏)
setAppName是给这个Spark取个名,setMaster("local")是程序执行只调用一个线程,可以local[4]配置4个线程,加快程序执行速度,但是电脑受不受得了就不知道了。
2:new SparkContext是创建一个SparkContext对象,其核心作用是初始化 Spark 应用程序运行所需要的核心组件,相当于调用汽车各个部件,各个部件在一起才能组装成车。(四肢)
3:sparkContext.textFile是按行读取文件,一行一行的数据。后面的"hdfs://localhost:9000/data.csv"是刚才上传的data.csv在hadoop上的路径,后面的1是给给这个rdd分配1个块,一个块128M,相当于给RDD一个住的地方,不然无家可归就找不到它了,也可以多分几个块,相当于住在了连栋别墅。
RDD<String>是一个String类型的RDD。
4:两个System.out.println的代码后面都有解释。
执行效果如下:
第一行数据显示出来了:


csv表总共3197行也被统计出来了,其实rdd.count()也能输出3197。toJavaRDD有时候可以不用加。

3198为空,所以不统计。
二、
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.rdd.RDD;
import scala.Tuple2;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data.csv",1);
//统计各省份宾馆数量
JavaPairRDD<String, Integer> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String,String,Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2(s.split(",")[3],1);
}
});
//
JavaPairRDD<String,Integer> rdd2 = rdd1.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer aDouble, Integer aDouble2) throws Exception {
return aDouble + aDouble2;
}
});
System.out.println(rdd2.collect());
}
}核心代码讲解:
//统计各省份宾馆数量
JavaPairRDD<String, Integer> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String,String,Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2(s.split(",")[3],1);
}
});
//1:rdd.toJavaRDD().mapToPair是将上面得到的<String>RDD转化为键值对类型的RDD,也就是等号左边的JavaPairRDD<String,Integer>类型,这里键是String类型,值为Integer类型。只要用了mapToPair函数,结果就一定是JavaPairRDD<?,?>的类型,这是固定写法。
2:new PairFunction<String,String,Integer>(){....}的意思是将rdd的每个元素都执行这个PairFunction函数,mapToPair里面的函数一定是new PairFunction,这是Spark的api固定的写法,其中第一个String代表着rdd每个元素的类型,因为csv每一行都是String,所以第一个参数也应该是String。第二个参数String与第三个参数Integer代表着每个元素的处理结果的键值对类型<String,Integer>,String是键的类型,Integer是值的类型。
3: return new Tuple2(s.split(",")[3],1); 是对rdd每个元素进行切分,然后每个元素都得到一个元组Tuple,这个形参(String s)传入的是rdd的每个元素即csv每一行字符串。
System.out.println(rdd1.collect());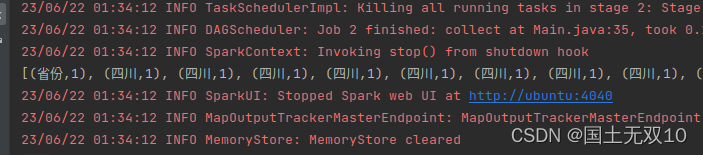
可以看出列表中全是键值对类型。
再看data.csv:

可以发现每一行的省份都以(省份,1)的格式输出出来了,最后所有的元组放在了一个列表中。当然后面这个1不是定死的,可以填写什么你想要的数字,甚至替换成s.split(',')[num],用该行分割后的某个字符串代替。
既然new Tuple2(s.split(",")[3],1)是输出省份的话,那么new Tuple2(s.split(",")[1],1)是输出什么呢?知道python的字符串分隔符的同学应该知道,它实际上是将每一行的数据按逗号分割然后从0开始数到3。0是SEQ,1是酒店,2是国家,3是省份,4是城市等等....,我们可以知道new Tuple2(s.split(",")[1],1)输出的应该是(酒店,1)的元组集合,那我们来测试一下吧。

看起来我们的猜测是正确的。那么问题来了,为什么要写s.split(","),以逗号为分隔符而不是其它的分隔符?那么以txt文本的方式打开csv文件,可以看到每一行的数据都是逗号。

什么?你说csv里面看不到是逗号?no,no,no,当我们在数据处理保存csv时,就已经默认逗号了,这么规矩的排版也是csv默认帮我们做的。

JavaPairRDD<String,Integer> rdd2 = rdd1.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer aDouble, Integer aDouble2) throws Exception {
return aDouble + aDouble2;
}
});1:这段代码的作用是将刚才得到的键值对RDD类型的rdd1使用reduceByKey进行按键分组,rdd1在上面可以看出键是省份,这里也就是按省份分组。
2:new Function2后面的三个Integer分别对应,返回的类型,传入的rdd1的键值对的值,传入的rdd1的键值对的值。返回的值是JavaPairRDD<String,Integer>的Integer部分,这个函数是不会影响String的。
3:上面的rdd1键值对的值都是Integer类型,相当于做了一个累加。
让我们看看效果吧。

可以看到它将所有省份在RDD中出现的次数做了统计。
三、(注意csv文件的数字是int还是double,建议RDD用<String, Double>类型,因为Double可以兼容int,而反之不能)
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.rdd.RDD;
import scala.Tuple2;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data2.csv",1);
JavaPairRDD<String, Double> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String,String,Double>() {
@Override
public Tuple2<String, Double> call(String s) throws Exception {
return new Tuple2(s.split(",")[3],Double.parseDouble(s.split(",")[8]));
}
});
JavaPairRDD<String,Double> rdd2 = rdd1.reduceByKey(new Function2<Double, Double, Double>() {
@Override
public Double call(Double aDouble, Double aDouble2) throws Exception {
return aDouble + aDouble2;
}
});
rdd2.foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> tuple2) throws Exception {
System.out.println(tuple2._1 + ":" +tuple2._2);
}
});
System.out.println(rdd2.collect());
}
}在代码二的基础上增加了
JavaPairRDD<String, Double> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String,String,Double>() {
@Override
public Tuple2<String, Double> call(String s) throws Exception {
return new Tuple2(s.split(",")[3],Double.parseDouble(s.split(",")[8]));
}
});这个rdd的返回值是取出4个属性和第9个属性的的二元组集合,但是

csv第一行为中文,这意味着Integer在这里就不能转化了,不能将汉字转化为数字,所以要上传一个新csv文件data2.csv,也就是在原来data.csv基础上删去第一行,并点击I列将所有空单元格替换为0(点击I列之后再点击ctrl+F),因为后面不能有空单元格,不然程序要寄。


rdd2.foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> tuple2) throws Exception {
System.out.println(tuple2._1 + ":" +tuple2._2);
}
});可能你会对._1与._2感到陌生,我举个例子tuple=(1,(2,3)),那么tuple._1是1,tuple._2是(2,3)。
进阶:tuple._2._1是2,tuple._2._2是3。这个._就是取元组的第几个值,因此要知道每个tuple长啥样,也可能是((2,3),(3,5))这个样子,那么起码都要._1._1这样取值,甚至是._1._1._1._1。
foreach是将rdd2列表的元素逐个读出,然后执行new VoidFunction函数。理解方式同之前的解释,观察rdd2每个元素的类型是不是键值对等等。(是)
System.out.println(rdd2.collect());运行效果:

这部分是rdd2.foreach的执行效果:
就是遍历rdd2的列表并且逐个输出,rdd2长啥样之前也有,我再放一遍(注意白色输出部分):

四、结合System的输出与注解理解
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.rdd.RDD;
import scala.Tuple2;
// Press Shift twice to open the Search Everywhere dialog and type `show whitespaces`,
// then press Enter. You can now see whitespace characters in your code.
public class Main {
public static void main(String[] args){
SparkConf sparkConf = new SparkConf().setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data2.csv", 1);
//统计各省份宾馆平均得分
//1.对数据集进行处理,获取省份以及宾馆评分,再追加一个计数器
JavaPairRDD<String, Double> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String, String, Double>() {
@Override
public Tuple2<String, Double> call(String s) throws Exception {
return new Tuple2(s.split(",")[3], Double.valueOf(s.split(",")[10]));
}
});
JavaPairRDD<String, Tuple2<Double, Long>> rdd2 = rdd1.mapValues(x -> new Tuple2<Double, Long>(x, 1L));
System.out.println(rdd2.collect()); //->的意思是:省份与元组的映射
//2.对rdd2进行统计,按照省份将数据分组,分别对分数和计数器进行累加操作,得出各省份总分数与总数据个数,再做除法得出平均值,结果保存到rdd2中
JavaPairRDD<String,Tuple2<Double,Long>> rdd3 = rdd2.reduceByKey((x,y) ->{
return new Tuple2<Double,Long>(x._1 +y._1,x._2 +y._2);
});
System.out.println(rdd3.collect());//按键值分组,再评分加评分,1+1统计省份数量
JavaPairRDD<String, Double> rdd4 = rdd3.mapToPair(x ->{
return new Tuple2<String, Double>(x._1, x._2._1 *1.0D / x._2._2); //相当于python读取元组的第几个元素,_1就是元组第一个元素,_2是元组第二个元素,以此类推,就是python语法习惯
});
rdd4.foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
System.out.println(stringDoubleTuple2._1 + ":" + stringDoubleTuple2._2);
}
});
//将rdd1按照省份进行分组,统计每个省的宾馆评分最大值(最小值)
//public Double call就是找每个省份最大值,因为rdd做迭代计算,所以会迭代到rdd所有内容
//结束
rdd1.reduceByKey(new Function2<Double, Double, Double>() {
@Override
public Double call(Double v1, Double v2) throws Exception {
Double result;
if (v1 > v2){
result = v1;
}else{
result = v2;
}
return result;
}
}).foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
System.out.println(stringDoubleTuple2._1+ ":" +stringDoubleTuple2._2);
}
});
}
}执行效果:

这部分是按键分组后,同组内两两对比,取出值最大的。




五、
package org.example;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.rdd.RDD;
import scala.Tuple2;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class Main {
static Connection connection = null;
public static void main(String[] args) throws SQLException {
SparkConf sparkConf = new SparkConf()
.setAppName("testsparkjava").setMaster("local");
SparkContext sparkContext = new SparkContext(sparkConf);
RDD<String> rdd = sparkContext.textFile("hdfs://localhost:9000/data2.csv", 1);
//统计各省份宾馆平均得分
//1.对数据集进行处理,获取省份以及宾馆评分,再追加一个计数器
JavaPairRDD<String, Double> rdd1 = rdd.toJavaRDD().mapToPair(new PairFunction<String, String, Double>() {
@Override
public Tuple2<String, Double> call(String s) throws Exception {
return new Tuple2(s.split(",")[3], Double.valueOf(s.split(",")[10]));
}
});
JavaPairRDD<String, Tuple2<Double, Long>> rdd2 = rdd1.mapValues(x -> new Tuple2<Double, Long>(x, 1L));
//2.对rdd2进行统计,按照省份将数据分组,分别对分数和计数器进行累加操作,得出各省份总分数与总数据个数,再做除法得出平均值,结果保存到rdd2中
JavaPairRDD<String,Tuple2<Double,Long>> rdd3 = rdd2.reduceByKey((x,y) ->{
return new Tuple2<Double,Long>(x._1 +y._1,x._2 +y._2);
});
JavaPairRDD<String, Double> rdd4 = rdd3.mapToPair(x ->{
return new Tuple2<String, Double>(x._1, x._2._1 *1.0D / x._2._2);
});
rdd4.foreach(new VoidFunction<Tuple2<String, Double>>() {
@Override
public void call(Tuple2<String, Double> stringDoubleTuple2) throws Exception {
insertData("room",stringDoubleTuple2._1,String.valueOf(stringDoubleTuple2._2));
}
});
connection.close();
}
public static void insertData(String tableName, String data1, String data2) throws ClassNotFoundException, SQLException {
String driver = "com.mysql.cj.jdbc.Driver";
String url = "jdbc:mysql://localhost:3306/hotel?useUnicode=true&characterEncoding=utf8";
String user = "root";
String password = "123456";
Class.forName(driver);
connection = DriverManager.getConnection(url, user, password);
PreparedStatement preparedStatement;
String sql = "insert into " + tableName + " values (?,?)";
preparedStatement =connection.prepareStatement(sql);
preparedStatement.setString(1,data1);
preparedStatement.setString(2,data2);
preparedStatement.executeUpdate();
}
}
这个部分插入数据库就普通的mysql操作了,把最后的结果插到表就行了,没啥新奇的。
结果如下:插入到之前创建的hotel数据库的room表了。

Last Step:pycharm进行可视化展示(来到这说明已经可以修仙了)
1:打开pycharm命令行

2:
apt install python sudo apt-get update
sudo apt-get install python3.8-distutils这个是不是3.8得看自己的python具体版本,在命令行输入python可查看,然后exit()可退出
pip install pyechartspip install pymysql# python 3.7 pyecharts 1.5
# pyecharts pymysql
# pip install pyecharts
# pip install mysql
from pyecharts.charts import Bar,Pie
import pymysql
conn = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="hotel",
charset="utf8")
sql = "select * from room"
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute(sql)
result1 = cursor.fetchall()
print(result1)
province = []
score = []
for row in result1:
province.append(row['province'])
score.append(row['rooms'])
pie = Pie()
pie.add("room",
data_pair=[list(z) for z in zip(province, score)])
pie.render("pie.html")
# bar = Bar()
# bar.add_xaxis(province)
#
# bar.add_yaxis("score",score)
#
# # render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
#
# # 也可以传入路径参数,如 bar.render("mycharts.html")
#
# bar.render("score.html")
#
以上是main.py,执行效果,在python的工程目录文件夹下找到pie.html文件并打开:


结束!














 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









