







仅知道如何使用那是远远不够的,我们应该分析源码看其内部实现原理,这样才能够进步。
1.主线
首先我们从整体上把握volley的工作流程,抓住其主线。
(1)请求队列(RequestQueue)的创建
创建请求队列的工作是从Volley#newRequestQueue开始的,这个方法内部会调用RequestQueue的构造器,同时指定一些基本配置,如缓存策略为硬盘缓存(DiskBasedCache),http请求方式为HttpURLConnection(level>9)和HttpClient(level<9),默认线程池大小为4。最后,调用RequestQueue#start启动请求队列。
看详细代码:
//Volley.java
public static RequestQueue newRequestQueue(Context context) {
return newRequestQueue(context, null);
}
调用另一个工厂方法:
//volley.java
public static RequestQueue newRequestQueue(Context context, HttpStack stack) {
File cacheDir = new File(context.getCacheDir(), DEFAULT_CACHE_DIR);
... ...
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();
} else {
// Prior to Gingerbread, HttpUrlConnection was unreliable.
// See: http://android-developers.blogspot.com/2011/09/androids-http-clients.html
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
Network network = new BasicNetwork(stack);
RequestQueue queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
queue.start();
return queue;
}
这里指定了硬盘缓存的位置为data/data/package_name/cache/volley/...,Network类(具体实现类是BasicNetwork)封装了请求方式,并且根据当前API版本来选用不同的http工具。最后启动了请求队列。
下面看RequestQueue的构造器:
//RequestQueue.java
public RequestQueue(Cache cache, Network network) {
this(cache, network, DEFAULT_NETWORK_THREAD_POOL_SIZE);
}
指定默认线程池大小为4。
//RequestQueue.java
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
public RequestQueue(Cache cache, Network network, int threadPoolSize,
ResponseDelivery delivery) {
mCache = cache;
mNetwork = network;
mDispatchers = new NetworkDispatcher[threadPoolSize];
mDelivery = delivery;
}
这里的ResponseDelivery是请求结果的分发器(具体实现是ExecutorDelivery),内部将结果返回给主线程(
根据代码中使用了Handler和UI线程的Looper大家就应该能猜到了),并处理回调事件。
下面看请求队列的开始后会发生什么,查看RequestQueue#start方法:
public void start() {
stop(); // Make sure any currently running dispatchers are stopped.
// Create the cache dispatcher and start it.
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// Create network dispatchers (and corresponding threads) up to the pool size.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
逻辑很简单,创建了CacheDispatcher和4个NetworkDispatcher个对象,然后分别启动之。这个CacheDispatcher和NetworkDispatcher都是Thread的子类,其中CacheDispatcher处理走缓存的请求,而4个NetworkDispatcher处理走网络的请求。CacheDispatcher通过构造器注入了缓存请求队列(mCacheQueue),网络请求队列(mNetworkQueue),硬盘缓存对象(DiskBasedCache),结果分发器(mDelivery)。之所以也注入网络请求队列是因为一部分缓存请求可能已经过期了,这时候需要重新从网络获取。NetworkDispatcher除了缓存请求队列没有注入,其他跟CacheDispatcher一样。到这里RequestQueue的任务就完成了,以后有请求都会交由这些dispatcher线程处理。
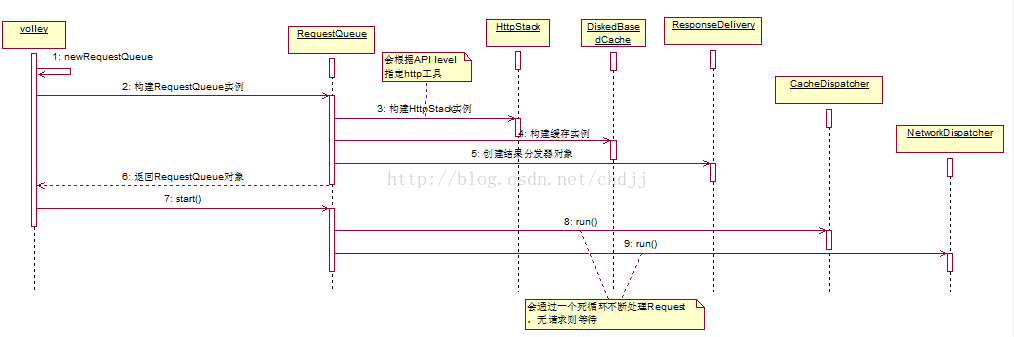
(2)请求的添加
请求的添加是通过RequestQueue#add完成的,add方法的逻辑是这样的:
1.将请求加入mCurrentRequests集合
2.为请求添加序列号
3.判断是否应该缓存请求,如果不需要,加入网络请求队列
4.如果有相同请求正在被处理,加入到相同请求等待队列中,否则加入缓存请求队列。
public Request add(Request request) {
// Tag the request as belonging to this queue and add it to the set of current requests.
request.setRequestQueue(this);
synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
}
// Process requests in the order they are added.
request.setSequence(getSequenceNumber());
request.addMarker("add-to-queue");
// If the request is uncacheable, skip the cache queue and go straight to the network.
if (!request.shouldCache()) {
mNetworkQueue.add(request);
return request;
}
// Insert request into stage if there's already a request with the same cache key in flight.
synchronized (mWaitingRequests) {
String cacheKey = request.getCacheKey();
if (mWaitingRequests.containsKey(cacheKey)) {
// There is already a request in flight. Queue up.
Queue<Request> stagedRequests = mWaitingRequests.get(cacheKey);
if (stagedRequests == null) {
stagedRequests = new LinkedList<Request>();
}
stagedRequests.add(request);
mWaitingRequests.put(cacheKey, stagedRequests);
if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);
}
} else {
// Insert 'null' queue for this cacheKey, indicating there is now a request in
// flight.
mWaitingRequests.put(cacheKey, null);
mCacheQueue.add(request);
}
return request;
}
}
通过这一方法,请求就被分发到两个队列中分别供CacheDispatcher和NetworkDispatcher处理。
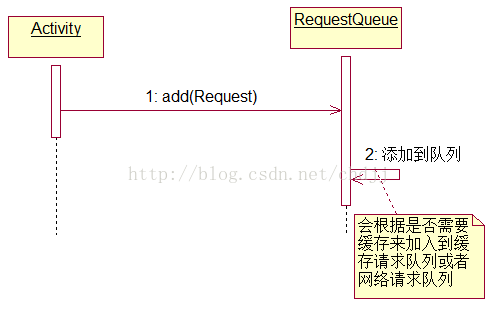
(3)请求的处理
请求的处理是由CacheDispatcher和NetworkDispatcher来完成的,它们的run方法通过一个死循环不断去从各自的队列中取出请求,进行处理,并将结果交由ResponseDelivery。两者处理思想一致但是具体逻辑还是有点区别,我们分别看看。
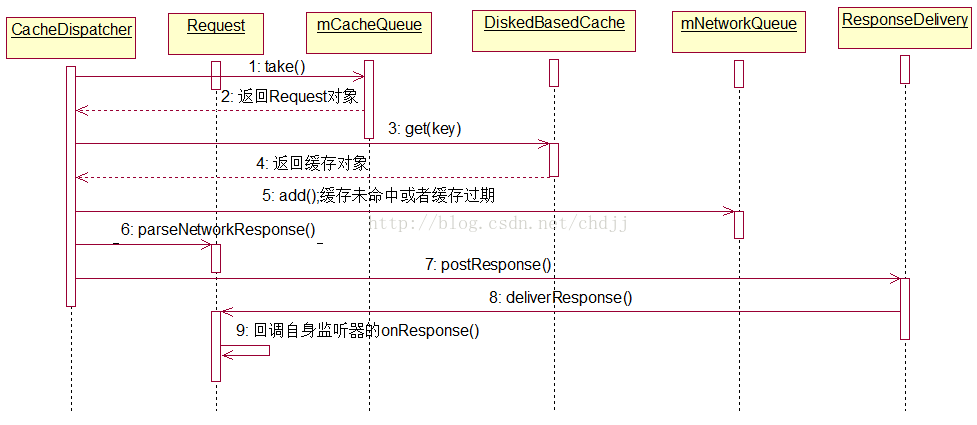
1.走缓存的请求
CacheDispatcher.java#run
@Override
public void run() {
if (DEBUG) VolleyLog.v("start new dispatcher");
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
// Make a blocking call to initialize the cache.
mCache.initialize();
while (true) {
try {
// Get a request from the cache triage queue, blocking until
// at least one is available.
final Request request = mCacheQueue.take();
request.addMarker("cache-queue-take");
// If the request has been canceled, don't bother dispatching it.
if (request.isCanceled()) {
request.finish("cache-discard-canceled");
continue;
}
// Attempt to retrieve this item from cache.
Cache.Entry entry = mCache.get(request.getCacheKey());
if (entry == null) {
request.addMarker("cache-miss");
// Cache miss; send off to the network dispatcher.
mNetworkQueue.put(request);
continue;
}
// If it is completely expired, just send it to the network.
if (entry.isExpired()) {
request.addMarker("cache-hit-expired");
request.setCacheEntry(entry);
mNetworkQueue.put(request);
continue;
}
// We have a cache hit; parse its data for delivery back to the reques
request.addMarker("cache-hit");
Response<?> response = request.parseNetworkResponse(
new NetworkResponse(entry.data, entry.responseHeaders));
request.addMarker("cache-hit-parsed");
if (!entry.refreshNeeded()) {
// Completely unexpired cache hit. Just deliver the response.
mDelivery.postResponse(request, response);
} else {
// Soft-expired cache hit. We can deliver the cached response,
// but we need to also send the request to the network for
// refreshing.
request.addMarker("cache-hit-refresh-needed");
request.setCacheEntry(entry);
// Mark the response as intermediate.
response.intermediate = true;
// Post the intermediate response back to the user and have
// the delivery then forward the request along to the network.
mDelivery.postResponse(request, response, new Runnable() {
@Override
public void run() {
try {
mNetworkQueue.put(request);
} catch (InterruptedException e) {
// Not much we can do about this.
}
}
});
}
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
}
}
大体逻辑是这样的,首先从队列中取出请求,看其是否已被取消,若是则返回,否则继续向下走。接着从硬盘缓存中通过缓存的键找到值(Cache.Entry),如果找不到,那么将此请求加入网络请求队列。否则对缓存结果进行过期判断( 这个需要请求的页面指定了Cache-Control或者Last-Modified/Expires等字段,并且Cache-Control的优先级比Expires更高。否则请求一定是过期的 ),如果过期了,则加入网络请求队列。如果没有过期,那么通过request.parseNetworkResponse方法将硬盘缓存中的数据封装成Response对象(Request的parseNetworkResponse是抽象的,需要复写)。最后进行新鲜度判断,如果不需要刷新,那么调用ResponseDelivery结果分发器的postResponse分发结果。否则先将结果返回,再将请求交给网络请求队列进行刷新。【这段代码读起来很爽,google工程师写的太赞了!】 关于ResponseDelivery的具体过程我们留到下节讲。
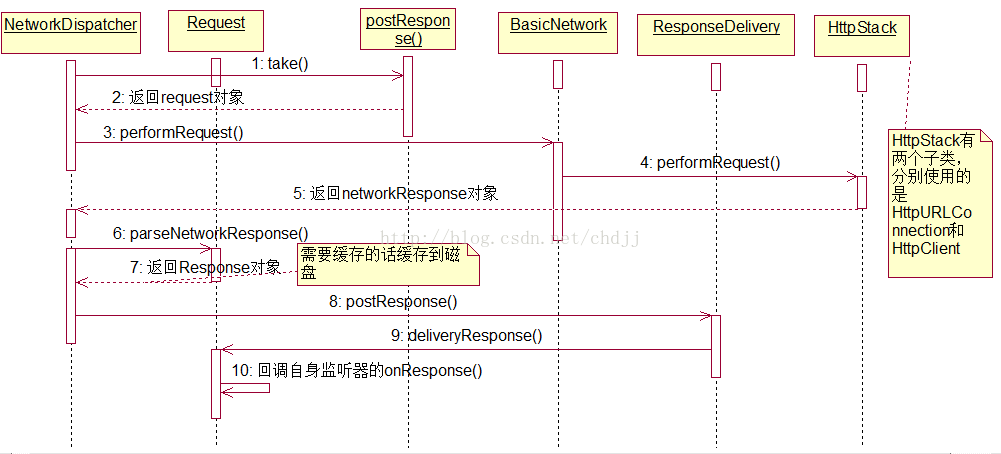
2.走网络的请求
@Override
public void run() {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
Request request;
while (true) {
try {
// Take a request from the queue.
request = mQueue.take();
} catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
try {
request.addMarker("network-queue-take");
// If the request was cancelled already, do not perform the
// network request.
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
continue;
}
// Tag the request (if API >= 14)
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.ICE_CREAM_SANDWICH) {
TrafficStats.setThreadStatsTag(request.getTrafficStatsTag());
}
// Perform the network request.
NetworkResponse networkResponse = mNetwork.performRequest(request);
request.addMarker("network-http-complete");
// If the server returned 304 AND we delivered a response already,
// we're done -- don't deliver a second identical response.
if (networkResponse.notModified && request.hasHadResponseDelivered()) {
request.finish("not-modified");
continue;
}
// Parse the response here on the worker thread.
Response<?> response = request.parseNetworkResponse(networkResponse);
request.addMarker("network-parse-complete");
// Write to cache if applicable.
// TODO: Only update cache metadata instead of entire record for 304s.
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
// Post the response back.
request.markDelivered();
mDelivery.postResponse(request, response);
} catch (VolleyError volleyError) {
parseAndDeliverNetworkError(request, volleyError);
} catch (Exception e) {
VolleyLog.e(e, "Unhandled exception %s", e.toString());
mDelivery.postError(request, new VolleyError(e));
}
}
}
这里的逻辑跟CacheDispatcher类似,也是构造Response对象,然后交由ResponseDelivery处理,但是这里的Response对象是通过NetworkResponse转化的,而这个NetworkResponse是从网络获取的,这里最核心的一行代码就是
NetworkResponse networkResponse = mNetwork.performRequest(request);这个mNetwork是BasicNetwork对象,我们看其performRequest的实现:
public NetworkResponse performRequest(Request<?> request) throws VolleyError {
long requestStart = SystemClock.elapsedRealtime();
while (true) {
HttpResponse httpResponse = null;
byte[] responseContents = null;
Map<String, String> responseHeaders = new HashMap<String, String>();
try {
// Gather headers.
Map<String, String> headers = new HashMap<String, String>();
addCacheHeaders(headers, request.getCacheEntry());
httpResponse = mHttpStack.performRequest(request, headers);
StatusLine statusLine = httpResponse.getStatusLine();
int statusCode = statusLine.getStatusCode();
responseHeaders = convertHeaders(httpResponse.getAllHeaders());
// Handle cache validation.
if (statusCode == HttpStatus.SC_NOT_MODIFIED) {
return new NetworkResponse(HttpStatus.SC_NOT_MODIFIED,
request.getCacheEntry().data, responseHeaders, true);
}
// Some responses such as 204s do not have content. We must check.
if (httpResponse.getEntity() != null) {
responseContents = entityToBytes(httpResponse.getEntity());
} else {
// Add 0 byte response as a way of honestly representing a
// no-content request.
responseContents = new byte[0];
}
// if the request is slow, log it.
long requestLifetime = SystemClock.elapsedRealtime() - requestStart;
logSlowRequests(requestLifetime, request, responseContents, statusLine);
if (statusCode < 200 || statusCode > 299) {
throw new IOException();
}
return new NetworkResponse(statusCode, responseContents, responseHeaders, false);
} catch (SocketTimeoutException e) {
attemptRetryOnException("socket", request, new TimeoutError());
} catch (ConnectTimeoutException e) {
attemptRetryOnException("connection", request, new TimeoutError());
} catch (MalformedURLException e) {
throw new RuntimeException("Bad URL " + request.getUrl(), e);
} catch (IOException e) {
int statusCode = 0;
NetworkResponse networkResponse = null;
if (httpResponse != null) {
statusCode = httpResponse.getStatusLine().getStatusCode();
} else {
throw new NoConnectionError(e);
}
VolleyLog.e("Unexpected response code %d for %s", statusCode, request.getUrl());
if (responseContents != null) {
networkResponse = new NetworkResponse(statusCode, responseContents,
responseHeaders, false);
if (statusCode == HttpStatus.SC_UNAUTHORIZED ||
statusCode == HttpStatus.SC_FORBIDDEN) {
attemptRetryOnException("auth",
request, new AuthFailureError(networkResponse));
} else {
// TODO: Only throw ServerError for 5xx status codes.
throw new ServerError(networkResponse);
}
} else {
throw new NetworkError(networkResponse);
}
}
}
}
这里最核心的是这一句:
httpResponse = mHttpStack.performRequest(request, headers);
它调用了HttpStack的performRequest,这个方法内部肯定会调用HttpURLConnection或者是HttpClient去请求网络。这里我们就不必继续向下跟源码了。
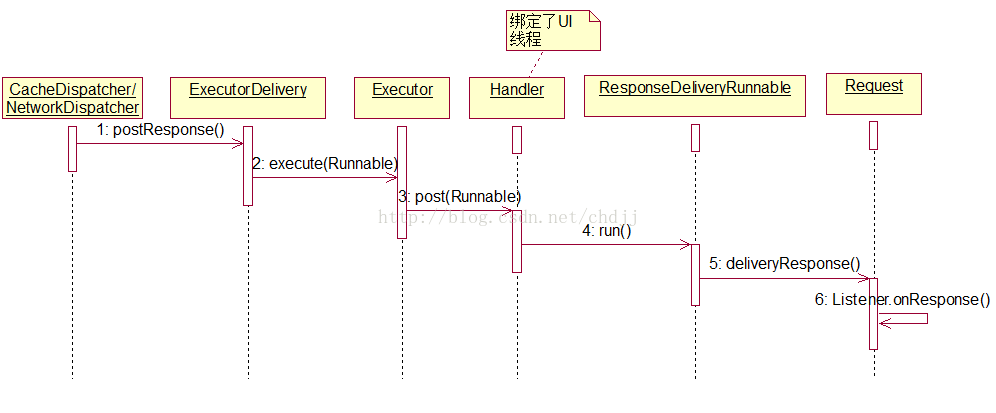
(4)请求结果的分发与处理
请求结果的分发处理是由ResponseDelivery实现类ExecutorDelivery完成的,ExecutorDelivery是在RequestQueue的构造器中被创建的,并且绑定了UI线程的Looper:
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
ExecutorDelivery内部有个自定义Executor,它仅仅是封装了Handler,所有待分发的结果最终会通过handler.post方法交给UI线程。
public ExecutorDelivery(final Handler handler) {
// Make an Executor that just wraps the handler.
mResponsePoster = new Executor() {
@Override
public void execute(Runnable command) {
handler.post(command);
}
};
}
下面看我们最关心的postResponse方法:
@Override
public void postResponse(Request<?> request, Response<?> response, Runnable runnable) {
request.markDelivered();
request.addMarker("post-response");
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
}
@Override
public void postResponse(Request<?> request, Response<?> response) {
postResponse(request, response, null);
}
最终执行的是ResponseDeliveryRunnable这个Runnable:
private class ResponseDeliveryRunnable implements Runnable {
private final Request mRequest;
private final Response mResponse;
private final Runnable mRunnable;
public ResponseDeliveryRunnable(Request request, Response response, Runnable runnable) {
mRequest = request;
mResponse = response;
mRunnable = runnable;
}
@SuppressWarnings("unchecked")
@Override
public void run() {
// If this request has canceled, finish it and don't deliver.
if (mRequest.isCanceled()) {
mRequest.finish("canceled-at-delivery");
return;
}
// Deliver a normal response or error, depending.
if (mResponse.isSuccess()) {
mRequest.deliverResponse(mResponse.result);
} else {
mRequest.deliverError(mResponse.error);
}
// If this is an intermediate response, add a marker, otherwise we're done
// and the request can be finished.
if (mResponse.intermediate) {
mRequest.addMarker("intermediate-response");
} else {
mRequest.finish("done");
}
// If we have been provided a post-delivery runnable, run it.
if (mRunnable != null) {
mRunnable.run();
}
}
}
这里我们看到了request.deliverResponse被调用了,这个方法通常会回调Listener.onResponse。哈哈,到这里,整个volley框架的主线就看完了!读到这里,我真是由衷觉得google工程师牛逼啊!
2.一些支线细节
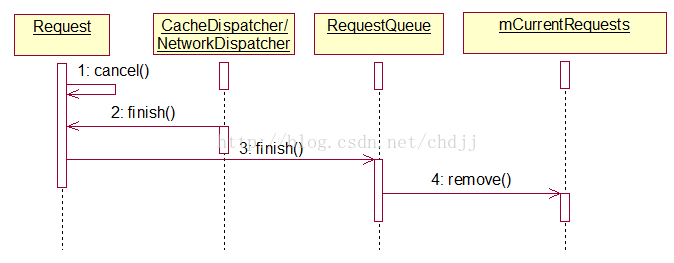
(1)请求的取消
调用Request#cancel可以取消一个请求。cancel方法很简单,仅将mCanceled变量置为true。而CacheDispatcher/NetworkDispatcher的run方法中在取到一个Request后会判断是否请求取消了:
if (request.isCanceled()) {
request.finish("network-discard-cancelled");
continue;
}
如果请求取消就调用Request#finish,finish方法内部将调用与之绑定的请求队列的finish方法,该方法内部会将请求对象在队列中移除。
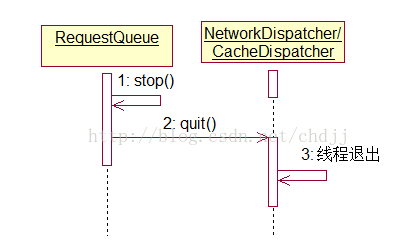
(2)请求队列的终止
调用RequestQueue#stop可以终止整个请求队列,并终止缓存请求线程与网络请求线程:
public void stop() {
if (mCacheDispatcher != null) {
mCacheDispatcher.quit();
}
for (int i = 0; i < mDispatchers.length; i++) {
if (mDispatchers[i] != null) {
mDispatchers[i].quit();
}
}
}
XXXDispatcher的quit方法会修改mQuit变量并调用interrupt使线程抛Interrupt异常,而Dispatcher捕获到异常后会判断mQuit变量最终while循环结束,线程退出。
catch (InterruptedException e) {
// We may have been interrupted because it was time to quit.
if (mQuit) {
return;
}
continue;
}
(3)ImageLoader
ImageLoader是对ImageRequest的封装,这里重点关注下get方法:
public ImageContainer get(String requestUrl, ImageListener imageListener,
int maxWidth, int maxHeight) {
...
final String cacheKey = getCacheKey(requestUrl, maxWidth, maxHeight);
// Try to look up the request in the cache of remote images.
Bitmap cachedBitmap = mCache.getBitmap(cacheKey);
if (cachedBitmap != null) {
// Return the cached bitmap.
ImageContainer container = new ImageContainer(cachedBitmap, requestUrl, null, null);
imageListener.onResponse(container, true);
return container;
}
...
Request<?> newRequest =
new ImageRequest(requestUrl, new Listener<Bitmap>() {
@Override
public void onResponse(Bitmap response) {
onGetImageSuccess(cacheKey, response);
}
}, maxWidth, maxHeight,
Config.RGB_565, new ErrorListener() {
@Override
public void onErrorResponse(VolleyError error) {
onGetImageError(cacheKey, error);
}
});
mRequestQueue.add(newRequest);
mInFlightRequests.put(cacheKey,
new BatchedImageRequest(newRequest, imageContainer));
return imageContainer;
}
首先会从缓存中获取如果没有则构造ImageRequest并添加到请求队列。
(4)关于缓存
Volley的CacheDispatcher工作时需要指定缓存策略,这个缓存策略即Cache接口,这个接口有两个实现类,DiskBasedCache和NoCache,默认使用DiskedBasedCache。它会将请求结果存入文件中,以备复用。Volley是一个高度灵活的框架,缓存是可以配置的。甚至你可以使用自己的缓存策略。
可惜这个DiskBasedCache很多时候并不能被使用,因为CacheDispatcher即使从缓存文件中拿到了缓存的数据,还需要看该数据是否过期,如果过期,将不使用缓存数据。这就要求服务端的页面可以被缓存,这个是由Cache-Control和Expires等字段决定的,服务端需要设定此字段才能使数据可以被缓存。否则缓存始终是过期的,最终总是走的网络请求。
服务端假如是servlet写的可以这样做:
Servlet#doPost/doGet()
/*设置缓存*/
resp.setDateHeader("Last-Modified",System.currentTimeMillis());
resp.setDateHeader("Expires", System.currentTimeMillis()+10*1000*60);
resp.setHeader("Cache-Control","max-age=10000");
resp.setHeader("Pragma","Pragma");
Cache-Control字段的优先级高于Expires。这个可以从HttpHeaderParser#parseCacheHeaders方法中看到。
public static Cache.Entry parseCacheHeaders(NetworkResponse response) {
long now = System.currentTimeMillis();
Map<String, String> headers = response.headers;
long serverDate = 0;
long serverExpires = 0;
long softExpire = 0;
long maxAge = 0;
boolean hasCacheControl = false;
String serverEtag = null;
String headerValue;
headerValue = headers.get("Date");
if (headerValue != null) {
serverDate = parseDateAsEpoch(headerValue);
}
headerValue = headers.get("Cache-Control");
if (headerValue != null) {
hasCacheControl = true;
String[] tokens = headerValue.split(",");
for (int i = 0; i < tokens.length; i++) {
String token = tokens[i].trim();
if (token.equals("no-cache") || token.equals("no-store")) {
return null;
} else if (token.startsWith("max-age=")) {
try {
maxAge = Long.parseLong(token.substring(8));
} catch (Exception e) {
}
} else if (token.equals("must-revalidate") || token.equals("proxy-revalidate")) {
maxAge = 0;
}
}
}
headerValue = headers.get("Expires");
if (headerValue != null) {
serverExpires = parseDateAsEpoch(headerValue);
}
serverEtag = headers.get("ETag");
// Cache-Control takes precedence over an Expires header, even if both exist and Expires
// is more restrictive.
if (hasCacheControl) {
softExpire = now + maxAge * 1000;
} else if (serverDate > 0 && serverExpires >= serverDate) {
// Default semantic for Expire header in HTTP specification is softExpire.
softExpire = now + (serverExpires - serverDate);
}
Cache.Entry entry = new Cache.Entry();
entry.data = response.data;
entry.etag = serverEtag;
entry.softTtl = softExpire;
entry.ttl = entry.softTtl;
entry.serverDate = serverDate;
entry.responseHeaders = headers;
return entry;
}
这个方法是由Request子类的parseNetworkResponse方法调用的:
Response.success(parsed, HttpHeaderParser.parseCacheHeaders(response))
另外,在使用图片加载框架时还有个ImageCache,它是作为图片加载的一级缓存,跟上面的DiskedBasedCache没有任何关系,大家不要混淆。ImageCache需要我们自己实现,通常结合LRUCache,具体第一部分已经介绍过了。
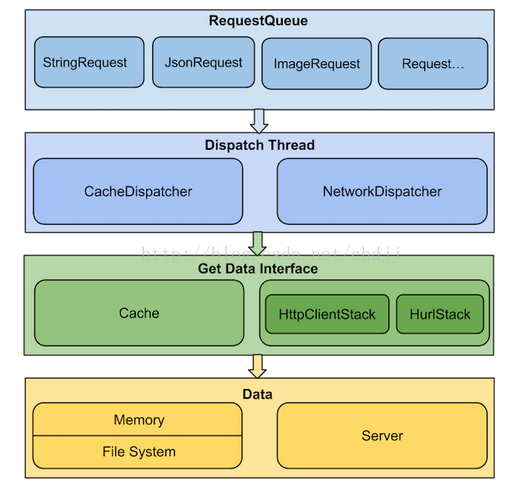
到这里我们把整个Volley框架全部分析完了。最后贴上Volley的整体架构图:
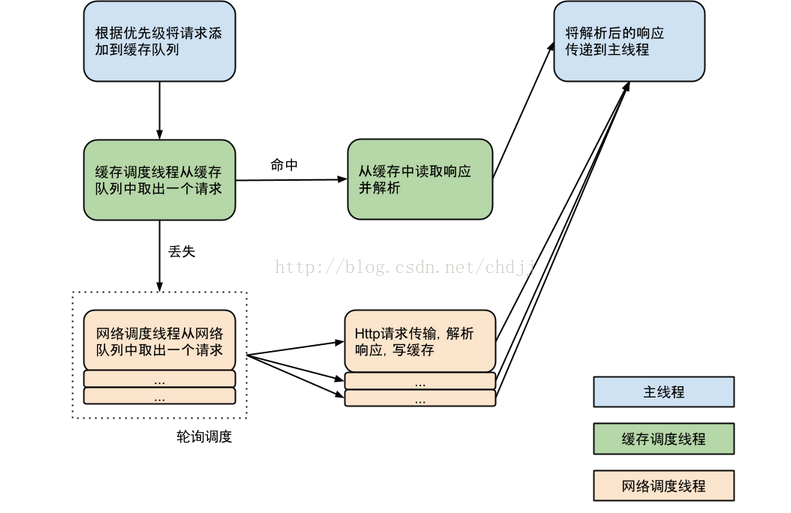
下面这幅图也很好:















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









