










1.学习《深入浅出python量化交易交易实战》第三章(笔记2)
记录学习过程中的代码、疑问和心得
3.3 基于机器学习的简单交易策略
本小节的代码有多处看不明白,这里现在前面列出来:
1. 发现的错误
错误
knn_reg看名字应该是回归模型的实例,但是书中这段是进阶者knn_clf分类模型的,是变量写错了,还是有确实的代码?
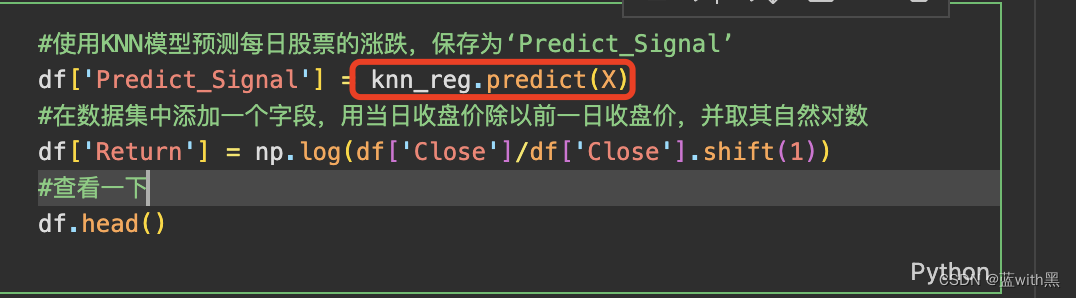
2. 本章节的疑问
- 基础收益中
cum_return_data = df[split_value:]['return'].cumsum() * 100,为什么对数收益累计值*100就是收益 - 策略收益 = 对数收益*交易信号.shift(1)? 原理是什么?
- 分类算法计算的准确率,是如何转换为交易信号的?
- knn_clf.predict(x)内部的逻辑是什么,为什么返回的就是交易信号呢?
- 对数收益?这里书中没说明,对啥log(两个交易日相除)就是收益呢?
- open-close, high-low创建的这两个字段也没看明白在算法中的作用。
knn_clf = KNeighborsClassifier(n_neighbors=95)
knn_clf.fit(x_train, y_train)
# *** 这里计算的准确率,是如何转换为交易信号的?
print('训练集中的准确率:', knn_clf.score(x_train, y_train))
print('验证集中的准确率:', knn_clf.score(x_test, y_test))
# 使用KNN模型预测每日股票的涨跌,保存为predict_signal
# *** knn_clf.predict(x)内部的逻辑是什么,为什么返回的就是交易信号呢?
df['predict_signal'] = knn_clf.predict(x)
# *** 对数收益?这里书中没说明,对啥log(两个交易日相除)就是收益呢?
df['return'] = np.log(df['close'] / df['close'].shift(1)) # 当日/前一天
使用分类算法制定交易策略
首先实现几个交易策略需要用到的函数。
分类函数
# 定义一个用于分类的函数 classification_tc:预测股票下一个交易日是否上涨
# 给表增加三个字段
# open-close 开盘价-收盘价
# high-low 最高价-最低价
# 分类函数
def classification_tc(df):
df['open-close'] = df['open'] - df['close'] # 开盘价-收盘价
df['high-low'] = df['high'] = df['low'] # 最高价-最低价
# 增加一个target字段,如果次日收盘价高于当日收盘价格,标记为1,否则为-1
# df.shift(-1) 将列向上移动一位,这里就把后一天的和当天的数据对齐,然后直接做比较运算
df['target'] = np.where(df['close'].shift(-1) > df['close'], 1, -1)
# 去掉有空值的行
df = df.dropna()
# 将open-close和high-low作为数据集的特征
x = df[['open-close', 'high-low']]
y = df['target']
return x, y
回归函数
# 定义一个用于回归的函数:预测次日收盘价格与当日收盘价格之差
# 特征的添加与分类函数类似
# 只不过target字段改为 次日收盘价 - 当前收盘价 ---> df['close'].shift(-1) - df['close']
def regression_tc(df):
df['open-close'] = df['open'] - df['close'] # 开盘价-收盘价
df['high-low'] = df['high'] = df['low'] # 最高价-最低价
df['target'] = df['close'].shift(-1) - df['close']
df.dropna()
# 将open-close和high-low作为数据集的特征
x = df[['open-close', 'high-low']]
y = df['target']
return x, y
定义一个计算累计回报的函数
def cum_return(df, split_value):
print('cum_return split_value:', split_value)
cum_return_data = df[split_value:]['return'].cumsum() * 100
return cum_return_data
疑问?
基础收益中cum_return_data = df[split_value:]['return'].cumsum() * 100,为什么对数收益累计值*100就是收益
使用策略交易的收益
# 使用策略的收益
def strategy_return(df, split_value):
print('strategy_return split_value:', split_value)
df['strategy_return'] = df['return'] * df['predict_signal'].shift(1)
cum_strategy_return = df[split_value:]['strategy_return'].cumsum() * 100
return cum_strategy_return
疑问?
策略收益 = 对数收益*交易信号.shift(1)? 原理是什么?
绘制收益曲线的函数
# 绘制曲线
def plot_chart(cum_return_data, cum_strategy_return, symbol):
plt.figure(figsize=(9, 6))
plt.plot(cum_return_data, '--', label='%s 收益是' % symbol)
plt.plot(cum_strategy_return, label='策略收益')
plt.legend()
plt.show()
基于机器学习的交易策略
def machine_learn_trade(symbol, start_date, end_date):
stock_dict = get_stock_data_table(symbol, start_date, end_date)
stock = stock_dict['stock']
print('股票代码:symbol', stock.head(3))
x, y = classification_tc(stock)
df = pd.concat([stock, x, y], axis=1)
print('======df======')
print(df.head(3))
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)
# 创建一个KNN实例
knn_clf = KNeighborsClassifier(n_neighbors=95)
knn_clf.fit(x_train, y_train)
# *** 这里计算的准确率,是如何转换为交易信号的?
print('训练集中的准确率:', knn_clf.score(x_train, y_train))
print('验证集中的准确率:', knn_clf.score(x_test, y_test))
# 使用KNN模型预测每日股票的涨跌,保存为predict_signal
# *** knn_clf.predict(x)内部的逻辑是什么,为什么返回的就是交易信号呢?
df['predict_signal'] = knn_clf.predict(x)
# *** 对数收益?这里书中没说明,对啥log(两个交易日相除)就是收益呢?
df['return'] = np.log(df['close'] / df['close'].shift(1)) # 当日/前一天
print('=============添加交易信号和收益后的结果====================')
print(df.head(3))
# 策略累计收益
strategy_return_data = strategy_return(df, split_value=len(x_train))
# 基础累计收益
cum_return_data = cum_return(df, split_value=len(x_train))
plot_chart(cum_return_data, strategy_return_data, 'dahua')
以上代码存在几点疑问:
df['return'] = np.log(df['close'] / df['close'].shift(1))对数收益不明白什么意思df['predict_signal'] = knn_clf.predict(x),为什么交易信号可以直接通过knn_clf.predict(x)获得,其内部原理是什么?
pandas df.shift()
pandas df.shift()函数说明:shift函数是对数据进行移动的操作
stock_dict = get_stock_data_table(symbol, start_date, end_date) stock = stock_dict['stock'] print('股票代码:symbol', stock) test = stock.head(5) print(test['volume']) test['volume_next'] = test['volume'].shift(-1) print(test)

















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











