




INFA字符集乱码主要体现是因为字符集不同导致的。
①源数据==> ②INFA应用所在服务器 ==> ③数据源
从数据源抽到目标数据库发现字符乱码,可以在D设计器中先预览看看是否乱码,再使用debug进行查看是在哪一步导致乱码的,每次修改完成都要重启一下infa服务。
在①处预览出现乱码:
1、 查看数据库字符集;
select *from nls_database_parameters t where t.parameter in ('NLS_CHARACTERSET', 'NLS_TERRITORY', 'NLS_LANGUAGE'); --这三个分别是字符集,服务器日期和数据,语言。
一般为 SIMPLIFIED CHINESE_CHINA.AL32UTF8
2.检查workfolw中的菜单选择 连接,关系 ,选择源的连接,代码页设置成为utf-8 encoding of unicode.
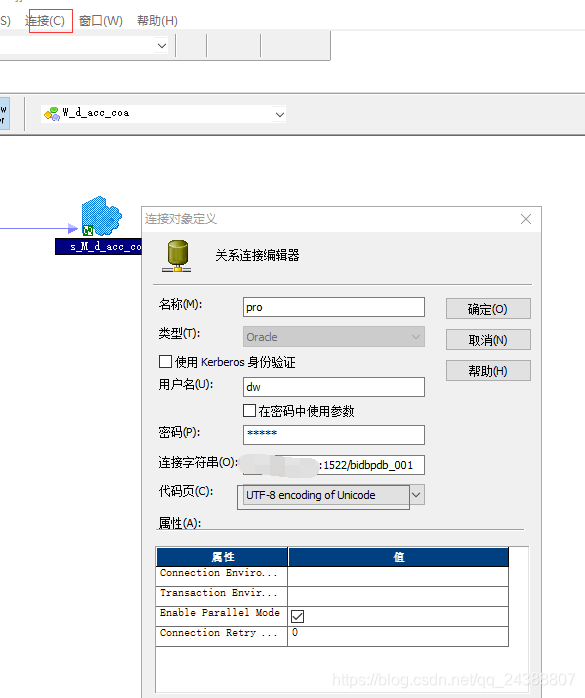
在 ②处预览出现乱码:
1、登陆infa所在的服务器,查看环境变量
windows: cmd 输入 set nls_lang 查看环境变量 如果和数据源不一样就在环境变量添加/修改NLS_LANG的环境变量值。
linux: echo $NLS_LANG 如果和数据源不一样就在该用户环境变量配置profile文件 添加/修改NLS_LANG的环境变量值。
在 ③处预览出现乱码:
1、查看对应的数据库的字符集,然后把最好修改成为数据源一样,或者是其的超级。
扩展知识:连接来自https://www.cnblogs.com/rootq/articles/2049324.html


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











