







参考
简单介绍
基本概念
Docker 包括三个基本概念:
- 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04
就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。 - 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
- 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
进程模型
注意:Linux 容器的“单进程”模型,指的是容器的生命周期等同于 PID=1 的进程(容器应用进程)的生命周期,而不是说容器里不能创建多进程。当然,一般情况下,容器应用进程并不具备进程管理能力,所以你通过 exec 或者 ssh 在容器里创建的其他进程,一旦异常退出(比如 ssh 终止)发生,其是很容易变成孤儿进程的。
docker 其实并没有创新新的技术,只是把一些现存的隔离技术(chroot 和 Namespace 和 Cgroup 等)封装为更简单易用的一个命令。
容器进程和宿主机进程有什么关系
容器其实是一种沙盒技术。顾名思义,沙盒就是能够像一个集装箱一样,把你的应用“装”起来的技术。这样,应用与应用之间,就因为有了边界而不至于相互干扰;而被装进集装箱的应用,也可以被方便地搬来搬去,这不就是 PaaS 最理想的状态嘛。
首先,操作系统从“程序”中发现输入数据保存在一个文件中,所以这些数据就会被加载到内存中待命。同时,操作系统又读取到了计算加法的指令,这时,它就需要指示 CPU 完成加法操作。而 CPU 与内存协作进行加法计算,又会使用寄存器存放数值、内存堆栈保存执行的命令和变量。同时,计算机里还有被打开的文件,以及各种各样的 I/O 设备在不断地调用中修改自己的状态。
就这样,一旦“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就是我们今天的主角:进程。
所以,对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
容器进程和宿主机进程并没有太大区别
- 通过利用 Namespace 和 Cgroup 等机制,创建一个隔离的空间,并进行资源的限制
- 通过 Namespace 技术,实现不同应用进程的视图隔离,只能看到自己进程内的信息,比如 PID
- 利用 Mount Namespace 和 Rootfs(镜像),在容器根目录“/"挂载个独立的、完整的文件系统
容器的重要几种机制
优点
- 相比于虚拟机上的应用需要虚拟化软件的拦截和处理(多一层消耗),容器更敏捷和高性能
缺点
- 基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
- 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
- 这就意味着,如果你的容器中的程序使用 settimeofday(2) 系统调用修改了时间,整个宿主机的时间都会被随之修改,这显然不符合用户的预期。相比于在虚拟机里面可以随便折腾的自由度,在容器里部署应用的时候,“什么能做,什么不能做”,就是用户必须考虑的一个问题。
1. Namespace 障眼法 —— 只看到自己的信息
注意此处 Linux Namespace 不要和 k8s Namespace 概念混淆:
Linux Namespace 机制:用于资源和视图隔离,使宿主机看不到容器内的资源,容器也看不到其他容器内的资源,实现不同应用的视图隔离,避免干扰
k8s Namespace 机制:就是用户资源的隔离,为了便于管理 k8s 自身的资源
Linux Namespace 是 Linux 提供的一种内核级别环境隔离的方法。这种隔离机制和 chroot 很类似,chroot 是把某个目录修改为根目录,从而无法访问外部的内容。Linux Namesapce 在此基础之上,提供了对 UTS、IPC、Mount、PID、Network、User 等的隔离机制,如下所示。
| 分类 | 系统调用参数 | 作用 | 相关内核版本 |
|---|---|---|---|
| Mount Namespaces | CLONE_NEWNS | 隔离挂载点 | Linux 2.4.19 |
| UTS Namespaces | CLONE_NEWUTS | 隔离主机名和域名 | Linux 2.6.19 |
| IPC Namespaces | CLONE_NEWIPC | 隔离System V IPC和POSIX message queues | Linux 2.6.19 |
| PID Namespaces | CLONE_NEWPID | 隔离进程ID | Linux 2.6.19 |
| Network Namespaces | CLONE_NEWNET | 隔离网络设备、端口号等 | 始于Linux 2.6.24 完成于 Linux 2.6.29 |
| User Namespaces | CLONE_NEWUSER | 隔离用户和用户组 | 始于 Linux 2.6.23 完成于 Linux 3.8) |
1.1 PID Namespace —— 全新的进程空间,自己就是 number 1
而当我们用 clone() 系统调用创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间**,在这个进程空间里,它的 PID 是 1**。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
当然,我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID Namespace 里的具体情况。
而除了我们刚刚用到的 PID Namespace,**Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。**比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。这,就是 Linux 容器最基本的实现原理了。
1.2 Mount Namespace —— 更改挂载点,挂载镜像
Mount Namespace 修改的,是容器进程对文件系统“挂载点”的认知。但是,这也就意味着,只有在“挂载”这个操作发生之后,进程的视图才会被改变。而在此之前,新创建的容器会直接继承宿主机的各个挂载点。
Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是**伴随着挂载操作(mount)**才能生效(未 mount 操作前,展示的是宿主机的文件);在容器 Mount Namespace 执行 mount 操作后,宿主机使用 mount -l命令不会看到容器内挂载点的改变,只有在容器内执行mount -l 才能看到挂载点的改变(也就是视图的改变)
不难想到,我们可以在容器进程启动之前重新挂载它的整个根目录“/”。而由于 Mount Namespace 的存在,这个挂载对宿主机不可见,所以容器进程就可以在里面随便折腾了。
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在 shell 中方便地完成这个工作。顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的位置。
实际上,Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统,比如 Ubuntu16.04 的 ISO。这样,在容器启动之后,我们在容器里通过执行 “ls /” 查看根目录下的内容,就是 Ubuntu 16.04 的所有目录和文件。
而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。 —— rootfs 即为镜像
1.3 UTS Namespace
UTS Namespace主要用来隔离nodename和domainname两个系统标识。在UTS Namespace 里面,每个Namespace拥有一个独立的主机名。
为了演示UTS Namespace的功能,我们先要创建一个UTS Namespace,并在新的Namespace修改主机名。
sudo unshare --uts --fork /bin/bash
hostname -b newhostname
输出如下

然后再打开宿主机的shell来查看hostname如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-75pfwMt9-1675763313349)(https://mmbiz.qpic.cn/mmbiz_png/R9Ibkk1UKqDdERkkwX9nrNEdIukTnL6y8wicoFfUMiawF3nEOyfJBic8MicjcEVhhs1fMicrKFBHcYZAwFibic3lomZOw/640?wx_fmt=png&wxfrom=5&wx_lazy=1&wx_co=1)]
1.4 IPC Namespce
IPC Namespace主要用来隔离进程间通信,PID Namespace和IPC Namespace一起使用可以实现同一IPC Namespace内的进程彼此可以通信,不同IPC Namespace的进程不能通信。
我们来验证一下,创建一个IPC Namespace,然后使用icps -q来查看当前Namespace中的进程间通信队列。
sudo unshare --ipc --fork /bin/bash
ipcs -q
输出如下

可见当前Namespace的进程间通信列表为空,没有任何系统进程的通信队列。
然后我们使用ipcmk -Q在当前Namespace创建一个系统通信队列。
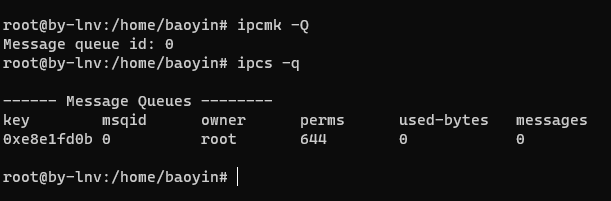
可以看到当前Namespace下有一个系统通信队列,我们新打开一个shell窗口并使用ipcs -q来查看宿主机的系统通信队列。
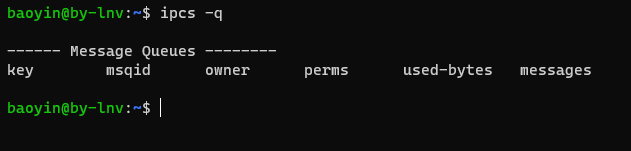
可见在单独的IPC Namespace中创建的系统通信队列在宿主机上无法看到,IPC Namespace实现了对系统进程间通信的隔离。
1.5 User Namespace
User Namespace 主要是用来隔离用户和用户组的。一个比较典型的应用场景就是在主机上以非 root 用户运行的进程可以在一个单独的 User Namespace 中映射成 root 用户。使用 User Namespace 可以实现进程在容器内拥有 root 权限,而在主机上却只是普通用户。
为了演示,我们先使用普通用户创建一个User Namespace,并且使用id命令查看当前登录用户的信息,然后尝试执行reboot命令。
unshare --user -r /bin/bash
id
reboot
输出如下

可见当前用户在新的User Namespace里是root用户,uid和gid都是0。但当这个“root”用户执行reboot操作的时候并不会真的执行重启操作系统的动作。由此可见,User Namespace实现了和宿主机的用户和用户组的隔离。
1.6 Net Namespace
Net Namespace 是用来隔离网络设备、IP 地址和端口等信息的。Net Namespace 可以让每个进程拥有自己独立的 IP 地址,端口和网卡信息。例如主机 IP 地址为 172.16.4.1 ,容器内可以设置独立的 IP 地址为 192.168.1.1。
创建一个Net Namespace,然后分别对别Net Namespace的网络信息和宿主机的网络信息。
sudo unshare --net --fork /bin/bash
ip a

可以看到宿主机上的enp0s3是Net Namespace中没有的。
2. Cgroups 资源限制 —— 避免单个容器抢占宿主机所有资源
2.1 容器 Cgroups 限制
虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
而 Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
在今天的分享中,我只和你重点探讨它与容器关系最紧密的“限制”能力,并通过一组实践来带你认识一下 Cgroups。在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu 16.04 机器里,我可以用 mount 指令把它们展示出来,这条命令是:
$ mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
它的输出结果,是一系列文件系统目录。如果你在自己的机器上没有看到这些目录,那你就需要自己去挂载 Cgroups,具体做法可以自行 Google。
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
如果熟悉 Linux CPU 管理的话,你就会在它的输出里注意到 cfs_period 和 cfs_quota 这样的关键词。这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
而这样的配置文件又如何使用呢?你需要在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
# 1. 创建 cpu cgroup 限制子系统
# 这个目录就称为一个“控制组”。你会发现,操作系统会在你新创建的 container 目录下,自动生成该子系统对应的资源限制文件。
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
# 2. 测试,没有添加限制值时,cpu 是否会被占满?
# 而此时,我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
# 进行测试,可以看出 cpu 被占满了
# 现在,我们在后台执行这样一条脚本:
$ while : ; do : ; done &
[1] 226
# 显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 226。
# 这样,我们可以用 top 指令来确认一下 CPU 有没有被打满:
$ top
%Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
# 在输出里可以看到,CPU 的使用率已经 100% 了(%Cpu0 :100.0 us)。
# 3. 测试,添加 cpu cgroup 限制值
# 比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):—— 重点1 写入 cpu 限制值
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
# 结合前面的介绍,你应该能明白这个操作的含义,它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
# 接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了: —— 重点2 写入进程号
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
# 我们可以用 top 指令查看一下:
# 可以看到,计算机的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)。
$ top
%Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
除 CPU 子系统外,Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的**,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合**。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而**至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,**比如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
# 在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
# 这就意味着这个 Docker 容器,只能使用到 20% 的 CPU 带宽。
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
2.2 明确 Pod 的资源限制
Pod 资源限制本质就是 利用 Cgroup 机制限制容器资源
操作系统中对于一个进程来说,如果希望运行必须需要cpu和存储才行,同样的道理一个pod想要运行,也必须有这两部分才行,于是k8s把pod运行所需要的资源划分成了两大类:可压缩资源和不可压缩资源。
k8s的资源模型:
可压缩资源:指的是cpu这一类资源,这类资源的特点是,在资源不够的时候,只会导致pod等运行的时间越来越久也就是会导致“饥饿”,并不会退出。
不可压缩资源:指的是mem这一类,一旦资源不足,就会被内核杀死,并强制pod退出。
为了描述这些资源信息,k8s将这部分资源与pod绑定,又因为k8s里面一个pod是由多个容器组成的,所以pod里面的资源就是容器资源的总和,其中两个比较重要的指标CPU和Memory。
CPU 属于可压缩资源:K8S里面描述CPU的单位是millicpu,例如:500m,指的就是 500 millicpu,也就是 0.5 个 CPU 的意思。
Memory属于不可压缩资源:K8S里面使用这些Ei、Pi、Ti、Gi、Mi、Ki(或者 E、P、T、G、M、K)的方式来作为 bytes 的值,其中带i结尾的是2的幂次方,例如:1Mi=10241024;1M=10001000。
在调度的时候,kube-scheduler 只会按照 requests 的值进行计算,表示的是分配的资源大小。—— request 用于调度时的筛选和打分
而在真正设置 Cgroups 限制的时候,kubelet 则会按照 limits 的值来进行设置,表示的使用资源的大小。—— limit 用于设置 cgroup 限额
k8s将这些资源划分成预期和限制两种方式来描述,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
3. Rootfs 文件系统 —— 更改容器根目录”/"
现在,你应该可以理解,对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
这样,一个完整的容器就诞生了。不过,Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。这两个系统调用虽然功能类似,但是也有细微的区别,这一部分小知识就交给你课后去探索了。
另外,需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
所以说,rootfs 只包括了操作系统的“躯壳”,并没有包括操作系统的“灵魂”。那么,对于容器来说,这个操作系统的“灵魂”又在哪里呢?实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核。
这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说是一个“全局变量”,牵一发而动全身。
正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。
由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
事实上,对于大多数开发者而言,他们对应用依赖的理解,一直局限在编程语言层面。比如 Golang 的 Godeps.json。但实际上,一个一直以来很容易被忽视的事实是,对一个应用来说,操作系统本身才是它运行所需要的最完整的“依赖库”。
有了容器镜像“打包操作系统”的能力,这个最基础的依赖环境也终于变成了应用沙盒的一部分。这就赋予了容器所谓的一致性:无论在本地、云端,还是在一台任何地方的机器上,用户只需要解压打包好的容器镜像,那么这个应用运行所需要的完整的执行环境就被重现出来了。
这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
例子
不过,这时你可能已经发现了另一个非常棘手的问题:难道我每开发一个应用,或者升级一下现有的应用,都要重复制作一次 rootfs 吗?
比如,我现在用 Ubuntu 操作系统的 ISO 做了一个 rootfs,然后又在里面安装了 Java 环境,用来部署我的 Java 应用。那么,我的另一个同事在发布他的 Java 应用时,显然希望能够直接使用我安装过 Java 环境的 rootfs,而不是重复这个流程。
一种比较直观的解决办法是,我在制作 rootfs 的时候,每做一步“有意义”的操作,就保存一个 rootfs 出来,这样其他同事就可以按需求去用他需要的 rootfs 了。但是,这个解决办法并不具备推广性。原因在于,一旦你的同事们修改了这个 rootfs,新旧两个 rootfs 之间就没有任何关系了。这样做的结果就是极度的碎片化
。那么,既然这些修改都基于一个旧的 rootfs,我们能不能以增量的方式去做这些修改呢?这样做的好处是,所有人都只需要维护相对于 base rootfs 修改的增量内容,而不是每次修改都制造一个“fork”。答案当然是肯定的。
这也正是为何,Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程,而是做了一个小小的创新:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union File System)的能力。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
# 比如,我现在有两个目录 A 和 B,它们分别有两个文件:
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
# 然后,我使用联合挂载的方式,将这两个目录挂载到一个公共的目录 C 上:
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
# 这时,我再查看目录 C 的内容,就能看到目录 A 和 B 下的文件被合并到了一起:
$ tree ./C
./C
├── a
├── b
└── x
# 可以看到,在这个合并后的目录 C 里,有 a、b、x 三个文件,并且 x 文件只有一份。这,就是“合并”的含义。此外,如果你在目录 C 里对 a、b、x 文件做修改,这些修改也会在对应的目录 A、B 中生效。
那么,在 Docker 项目中,又是如何使用这种 Union File System 的呢?我的环境是 Ubuntu 16.04 和 Docker CE 18.05,这对组合默认使用的是 AuFS 这个联合文件系统的实现。你可以通过 docker info 命令,查看到这个信息。AuFS 的全称是 Another UnionFS,后改名为 Alternative UnionFS,再后来干脆改名叫作 Advance UnionFS,从这些名字中你应该能看出这样两个事实:
- 它是对 Linux 原生 UnionFS 的重写和改进;
- 它的作者怨气好像很大。我猜是 Linus Torvalds(Linux 之父)一直不让 AuFS 进入 Linux 内核主干的缘故,所以我们只能在 Ubuntu 和 Debian 这些发行版上使用它。
# 对于 AuFS 来说,它最关键的目录结构在 /var/lib/docker 路径下的 diff 目录:
/var/lib/docker/aufs/diff/<layer_id>
# 而这个目录的作用,我们不妨通过一个具体例子来看一下。现在,我们启动一个容器,比如:
$ docker run -d ubuntu:latest sleep 3600
# 这时候,Docker 就会从 Docker Hub 上拉取一个 Ubuntu 镜像到本地。
# 这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成:
$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
# 可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
# 这个挂载点就是 /var/lib/docker/aufs/mnt/,比如:
/var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
# 不出意外的,这个目录里面正是一个完整的 Ubuntu 操作系统:
$ ls /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fcfa2a2f5c89dc21ee30e166be823ceaeba15dce645b3e
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
# 那么,前面提到的五个镜像层,又是如何被联合挂载成这样一个完整的 Ubuntu 文件系统的呢?
# 这个信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面。
# 首先,通过查看 AuFS 的挂载信息,我们可以找到这个目录对应的 AuFS 的内部 ID(也叫:si):
# 即,si=972c6d361e6b32ba。
$ cat /proc/mounts| grep aufs
none /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba,dio,dirperm1 0 0
# 然后使用这个 ID,你就可以在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息:
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh
# 从这些信息里,我们可以看到,镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面。
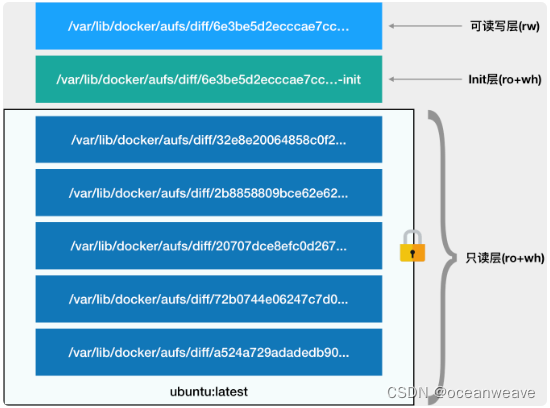
# 而且,从这个结构可以看出来,这个容器的 rootfs 由如下图所示的三部分组成:
# 1. 只读层。
# 它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout,至于什么是 whiteout,我下面马上会讲到)。这时,我们可以分别查看一下这些层的内容:
# 可以看到,这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
$ ls /var/lib/docker/aufs/diff/72b0744e06247c7d0...
etc sbin usr var
$ ls /var/lib/docker/aufs/diff/32e8e20064858c0f2...
run
$ ls /var/lib/docker/aufs/diff/a524a729adadedb900...
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
# 2. 可读写层。
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
可是,你有没有想到这样一个问题:如果我现在要做的,是删除只读层里的一个文件呢?
为了实现这样的删除操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。
比如,你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
所以,最上面这个可读写层的作用,就是专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。而当我们使用完了这个被修改过的容器之后,还可以使用 docker commit 和 push 指令,保存这个被修改过的可读写层,并上传到 Docker Hub 上,供其他人使用;而与此同时,原先的只读层里的内容则不会有任何变化。这,就是增量 rootfs 的好处。
# 3. Init 层。
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









