









参考
- docker,containerd,runc,docker-shim 之间的关系
- Containerd shim 进程 PPID 之谜
- 内核大神教你从 Linux 进程的角度看 Docker
- RunC 简介
- OCI和runC
- Containerd 简介
- 从 docker 到 runC
- Dockershim究竟是什么
- 技术干货|Docker和 Containerd 的区别,看这一篇就够了
- Docker,containerd,CRI,CRI-O,OCI,runc 分不清?看这一篇就够了
- k8s、dockershim、containershim、容器运行时的关系
- Docker服务进程关系
- 关于容器中进程的继承关系
- containerd,containerd-shim和runc的依存关系
- dockerd、contaierd、containerd-shim、runC通信机制分析
- docker,containerd,runc,docker-shim 之间的关系 k8s cri 的演变
- 容器中的 Shim 到底是个什么鬼?
排错博客整理
-
最新的示意图(取消了 docker-shim)
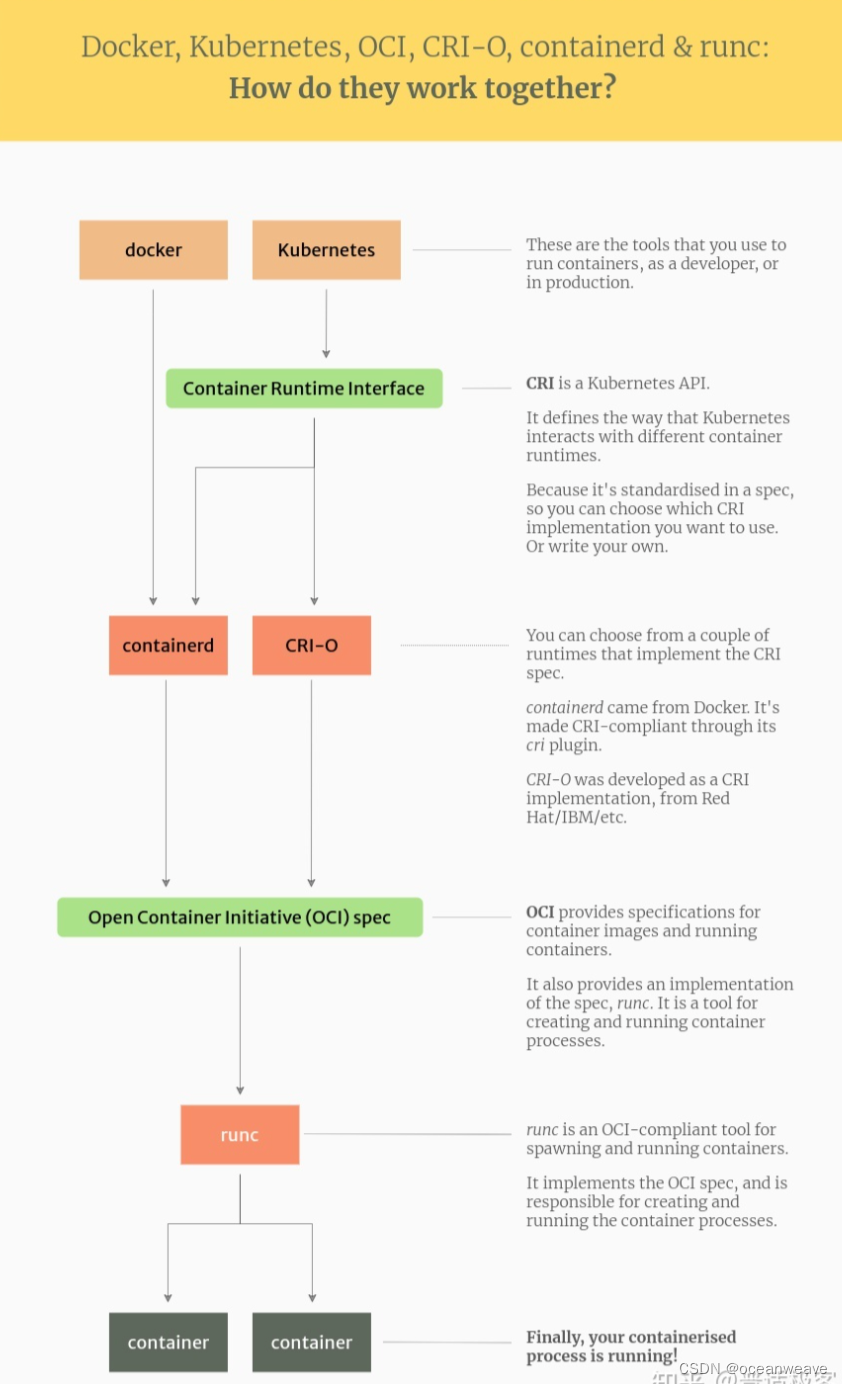
- Kubernetes 的容器运行时对接示意图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kmVTuCso-1678071207063)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230303150508901.png)]](https://i-blog.csdnimg.cn/blog_migrate/8b0c9224c7c4e601dc89f473f9de9bf1.png)
| 名词 | 解释 | 补充 |
|---|---|---|
| OCI | OCI(open Container Initiative)容器标准化组织的主要目的是推进容器技术的标准化。对容器标准进行准确的定义。其主要目的是为了解决容器标准混乱的问题。没有统一的容器标准,工业界就无法按照统一的标准进行容器开发。因此OCI于2015年由docker牵头和其他公司制定了相应的容器标准。 OCI目前包含两个标准: runtime-spec和image-spec。分别定义了容器运行时标准和容器镜像标准。 - 可以理解为,是个标准,统一创建容器的接口以及镜像的结构 | 接口规范标准 |
| RunC | RunC 是一个轻量级的工具,它是用来运行容器的 - 可以理解为实现了 OCI 定义的接口的工具 | 标准的简单实现 |
| Containerd | Containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。Containerd 可以在宿主机中管理完整的容器生命周期:容器镜像的传输和存储、容器的执行和管理、存储和网络等。 详细点说,Containerd 负责干下面这些事情: - 管理容器的生命周期(从创建容器到销毁容器) - 拉取/推送容器镜像 - 存储管理(管理镜像及容器数据的存储) - 调用 runC 运行容器(与 runC 等容器运行时交互) - 管理容器网络接口及网络 注意:Containerd 被设计成嵌入到一个更大的系统中,而不是直接由开发人员或终端用户使用。 | 较为丰富的功能,对 RunC 的封装 工业级容器运行时,主要用于大型系统,不直接面向用户 |
| Docker | docker本身而言,包括docker client和dockerd,是一个客户端工具,用来把用户的请求发送给docker daemon(dockerd)。 dockerd:dockerd是对容器相关操作的最上层封装,直接面向操作用户。Docker daemon,一般也会被称为docker engine。dockerd启动时会启动containerd 子进程。 | 封装了 Containerd,可以理解为面向用户级别的产品 |
| 简单总结 | - OCI :是个容器和镜像标准,定义了一些接口和规范 - RunC : 实现了 OCI 标准,可以实现容器的创建,功能比较简单 - Containerd:封装了 RunC,提供更丰富功能,适用于工业级需求(对接大型系统,如k8s) - Docker:引擎部分 dockerd 封装了 Containerd,提供 client 端由客户操作,用户级别的产品 | |
| CRI | CRI(容器运行时接口)是 Kubernetes 用来控制创建和管理容器的不同运行时的 API,它使 Kubernetes 更容易使用不同的容器运行时。它一个插件接口,这意味着任何符合该标准实现的容器运行时都可以被 Kubernetes 所使用 | 接口规范标准 |
| Docker-shim | 在 Kubernetes 包括一个名为 dockershim 的组件,使它能够支持 Docker。**但 Docker 由于比 Kubernetes 更早,没有实现 CRI,所以这就是 dockershim 存在的原因,它支持将 Docker 被硬编码到 Kubernetes 中。**随着容器化成为行业标准,Kubernetes 项目增加了对额外运行时的支持,比如通过 Container Runtime Interface (CRI) 容器运行时接口来支持运行容器。因此 dockershim 成为了 Kubernetes 项目中的一个异类,对 Docker 和 dockershim 的依赖已经渗透到云原生计算基金会(CNCF)生态系统中的各种工具和项目中,导致代码脆弱。 | 是组件 |
| K8s决定在 1.20 开始放弃 Docker,并在1.21完全抛弃 Docker 的支持。。今后 Kubernetes 将取消对 Docker 的直接支持,而倾向于只使用实现其容器运行时接口的容器运行时,这可能意味着使用 containerd 或 CRI-O。这并不意味着 Kubernetes 将不能运行 Docker 格式的容器。containerd 和 CRI-O 都可以运行 Docker 格式(实际上是 OCI 格式)的镜像,它们只是无需使用 docker 命令或 Docker 守护程序。 | ||
| 适配器,将k8s cri接口与各种容器实现的接口进行适配 - 早期,k8s cri 容器运行时接口直接对接 docker,由于 cri 是个标准(有固定的接口形式),因此为了将 k8s cri 的命令传达给 docker,需要有个翻译,也就是 docker-shim | ||
| Containerd-shim | 调用runc启动容器,监控容器进程状态,回收容器中的相关进程等 - 一个 containerd-shim 进程只负责管理一个运行的容器 - 通过 docker 运行容器,containerd-shim 进程可能被命名为 docker-containerd-shim - k8s 1.24 后,cri 直接对接了 containerd,容器对应的 shim 进程名称为 containerd-shim | 是进程 |
| CRI-O | CRI-O 是另一个实现了容器运行时接口(CRI)的高级别容器运行时,可以使用 OCI(开放容器倡议)兼容的运行时,它是 containerd 的一个替代品。 CRI-O 诞生于 RedHat、IBM、英特尔、SUSE、Hyper 等公司。它是专门从头开始创建的,作为 Kubernetes 的一个容器运行时,它提供了启动、停止和重启容器的能力,就像 containerd 一样。 | 是组件 注意是容器运行时,和containerd 同等地位 |
| k8s 调用链路的变化 | ||
| K8s 1.21 前调用链路 | K8S -> kubelet -> grpc call -> Dockerd --> Containerd-> runC - 进程纳管情况:Containerd(纳管所有containerd-shim) --> Containerd-shim(纳管单个容器) --> 容器进程 | |
| k8s 1.21 后调用链路 | K8S -> kubelet -> grpc call -> Containerd-> runC - 进程纳管情况:Root-init(宿主机上1号进程)–> Containerd-shim(纳管单个容器) --> 容器进程 - 如何实现被 Root-init 进程纳管呢? - 猜测是(下文有详细介绍): 1. Containerd 启动一个进程(称之为 Start 进程)拉起 Containerd-shim 进程,从而创建出容器 2. 当容器起来后,Start 进程快速结束,此时 Containerd-shim 进程变为了孤儿集成,因此被 Root-init 进程纳管 | |
| 完全理解 Docker 创建容器的一个过程 | ||
| 首先理解linux创建子进程 | Docker Daemon 的 fork 和我们程序员普通的 fork 有什么区别,为什么 Docker 的 fork,fork 出的是容器,而我们的却不叫容器呢? | |
| Linux 中创建进程的基本模型 | Linux 操作系统中,由父进程创建并执行子进程,创建通过 fork 完成,执行通过 exec 完成 | |
| 在上图中,我们看到进程 A 创建了一个新的进程 B,最终两个进程各自运行。创建时,进程 A 通过 fork 系统调用来完成。fork 之后,两个进程最大的区别就是:进程 A 依然拥有原来的 PID,新创建的进程 B 会占用一个全新的 PID,两者的 PID 不同。 | ||
| 并且 Linux 内核会在 fork 系统调用时,会拷贝进程 A 的 task_struct,拷贝的副本是为进程 B 准备的。完成 fork 操作之后,拥有全新 PID 的进程 B 会执行 exec 操作,保证执行新的程序,真正开始进程 B 的运行逻辑。 | ||
| 进程 B 运行过程中,假若 B 正常或者异常退出,那么内核就会给进程 B 的父进程 A,发送一个 SIGHOLD 信号,父进程 A 则对退出的进程 B 执行 wait 操作,实现对 B 进程资源的回收,如进程描述符 task_struct 等。 | ||
| 创建逻辑 | 1. Dockerd 通过 GRPC 与 Containerd 通信,传输一些镜像信息等 2. Containerd 通过 exec 系统调用创建 Containerd-shim 进程(创建过程中会传递 namespace 等参数,用于实现之后不同容器进程视图和资源的隔离) 3. Contaienrd-shim 进程通过 exec 系统调用创建容器进程 补充:execve 系统调用创建出来的进程是全新的,不会从原进程复制进程结构 | |
| 创建容器 | 1. 容器镜像的下载是由 dockerd 完成的,但容器的创建和运行就需要 containerd(docker-containerd) 来完成了。 2. Dockerd 与 docker-containerd 之间是通过 grpc 协议通信的。 3. 当 docker-containerd 收到 dockerd 启动容器的请求之后,会做一些初始化工作,然后启动 docker-containerd-shim 进程,并将相关配置作为参数传给它。 4. docker-containerd 负责管理所有本机正在运行的容器,而一个 docker-containerd-shim 进程只负责管理一个运行的容器,它相当于 docker-runc 的一个封装,充当 docker-containerd 和 docker-runc 之间的桥梁,docker-runc 能干的就交给 docker-runc 来做,docker-runc 做不了的就放到这里来做。 | |
| 创建完成后没有见到 runc 进程 | 1. 在容器启动的过程中,docker-runc 进程是作为 docker-containerd-shim 的子进程存在的。 2. docker-runc 进程根据配置找到容器的 rootfs 并创建子进程(根据容器的entrypoint和cmd创建进程) 作为容器中的第一个进程。 3. 当这一切都完成后 docker-runc 进程退出,然后容器进程由 docker-runc 的父进程 docker-containerd-shim 接管 | |
| 为什么需要 docker-containerd-shim | 为什么在容器的启动或运行过程中需要一个 docker-containerd-shim 进程呢?把它移除掉整个架构会更简洁也更优美一些!事实上 docker-containerd-shim 的存在是非常有必要的,其目的有如下几点: 1. 它允许容器运行时(即 runC)在启动容器之后退出,简单说就是不必为每个容器一直运行一个容器运行时(runC) 2. 即使在 containerd 和 dockerd 都挂掉的情况下,容器的标准 IO 和其它的文件描述符也都是可用的 3. 向 containerd 报告容器的退出状态 | 此处 docker-containerd-shim 进程,指的就是 containerd-shim 进程 |
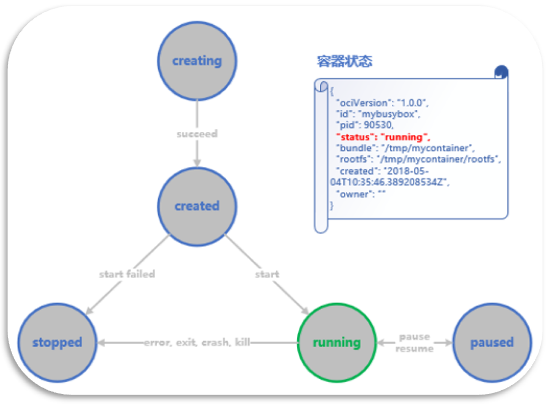
理解OCI标准规定的容器状态转移
在运行 busybox 容器前让我们先来看看 OCI 都定义了哪几种容器状态,以及这些状态是如何转移的。先看容器的状态:
- creating:使用 create 命令创建容器,这个过程称为创建中。
- created:容器已经创建出来,但是还没有运行,表示镜像文件和配置没有错误,容器能够在当前平台上运行。
- running:容器里面的进程处于运行状态,正在执行用户设定的任务。
- stopped:容器运行完成,或者运行出错,或者 stop 命令之后,容器处于暂停状态。这个状态,容器还有很多信息保存在平台中,并没有完全被删除。
- paused:暂停容器中的所有进程,可以使用 resume 命令恢复这些进程的执行。
下图则是对容器不同状态间转移的一个粗略描述:
从进程角度看 Docker 创建容器
dockerd、contaierd、containerd-shim、runC通信机制分析
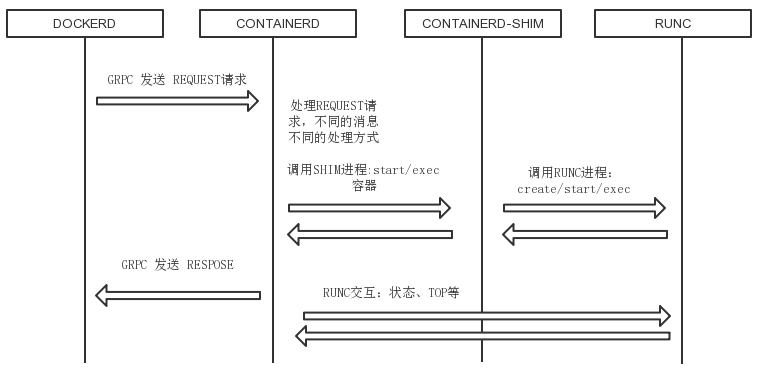
通信流程:
- docker daemon 模块通过 grpc 和 containerd模块通信:dockerd 由
libcontainerd负责和containerd模块进行交换, dockerd 和 containerd 通信socket文件:docker-containerd.sock- containerd 在dockerd 启动时被启动,启动时,启动grpc请求监听。containerd处理grpc请求,根据请求做相应动作;
- 若是start或是exec 容器,containerd 拉起一个container-shim , 并通过exit 、control 文件(每个容器独有)通信;
- container-shim被拉起后,start/exec/create拉起runC进程,通过exit、control文件和containerd通信,通过父子进程关系和SIGCHLD监控容器中进程状态;
- 若是top等命令,containerd通过runC二级制组件直接和容器交换;
- 在整个容器生命周期中,containerd通过 epoll 监控容器文件,监控容器的OOM等事件;
NOTE: containerd,container-shim 组件本质上runC 和dockerd 间的adapter中间件,容器本身有runC单独完成 — 使用runC可以单独完成一个容器部署。
理解 Docker 和 containerd 的容器进程管控方式
首先,我们来看下containerd,containerd-shim和容器进程的关系:
root 2156 1733 0 13:17 pts/0 00:00:00 ./bin/containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --shim /home/fankang/docker/containerd-0.2.4/src/github.com/docker/containerd/bin/containerd-shim --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --runtime docker-runc # containerd 进程,纳管所有容器,就是所有 containerd-shim 进程
root 2198 2156 0 13:45 pts/0 00:00:00 /home/fankang/docker/containerd-0.2.4/src/github.com/docker/containerd/bin/containerd-shim nginx /home/fankang/mycontainer runc # containerd-shim 进程,一个 shim 进程纳管一个容器进程,因此 1 个 shim 进程可以等同于 1 个容器进程
root 2214 2198 0 13:45 ? 00:00:00 /usr/bin/python /usr/bin/supervisord # 容器进程
可以看出,containerd是containerd-shim的父进程,contaienrd-shim是容器进程的父进程。
而杀死containerd进程后,contaienrd-shim和容器进程依然存在,只是containerd进程成孤儿进程后,被1进程接收了:
root 2301 1 0 13:50 pts/0 00:00:00 /home/fankang/docker/containerd-0.2.4/src/github.com/docker/containerd/bin/containerd-shim nginx /home/fankang/mycontainer runc
root 2317 2301 1 13:50 ? 00:00:00 /usr/bin/python /usr/bin/supervisord
所以,为了简化三个进程的关系,我们从下面4种情况来分析:
- containerd进程存在的情况下,杀死containerd-shim进程;
- 结论:容器进程退出。在containerd运行的情况下,杀死containerd-shim,容器进程会退出。
- containerd进程存在的情况下,杀死容器进程;
- containerd存在的情况下,杀死容器进程,conainerd-shim主动退出,containerd触发exit事件以清理该容器。
- containerd进程不存在的情况下,杀死containerd-shim进程,然后启动containerd进程;
- 容器进程还在,成为孤儿进程,被进程1接收
- 启动containerd,容器进程消失
- containerd进程不存在的情况下,杀死容器进程,然后启动containerd进程;
- 所有进程都不存在。
- 所以,在Go中,默认子进程的退出会引起父进程的退出。
理解 k8s 1.21 后 containerd 的管控方式
Kubernetes 自从 1.21 版废除对 dockershim 的支持,改用 Containerd 作为默认的容器运行时。
我们使用 ps 命令来观察一下 Containerd 相关进程:
$ ps -ef | grep containerd
root 1002 1 3 02:29 ? 00:00:19 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock
root 1011 1 1 02:29 ? 00:00:07 /usr/bin/containerd
root 1622 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 5ca114f2233d4638fae47b86ed058c0774a248168b3bb66d41f94bdcd1e56626 -address /run/containerd/containerd.sock
root 1624 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 4727e762c3fa1a7f2d4beebfeb79a4ee22298e48018beee5204cc8fd98e7bd41 -address /run/containerd/containerd.sock
root 1660 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 35d2d1cafe57afde4a1e3041a75d216e48f75312760b1c77ffaa7acc0ee8802f -address /run/containerd/containerd.sock
root 1661 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id c7769877c77465c86e803b1522ad44ec5ee62b4ff90d1e7f9afd13680215f048 -address /run/containerd/containerd.sock
root 2003 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id f4165704fb540c52586e2edcff1c420fe4177d0494205a019201689c7d65d5d4 -address /run/containerd/containerd.sock
root 2090 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id ebe6394198639bfe1e9a09e5e72bf4fc6f55fb1c1e617cdda5409a7d35941010 -address /run/containerd/containerd.sock
root 2637 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 68611b98a5fa4e19a18494898d084b1c025ff94bf840ffc035dd00694bb3fd17 -address /run/containerd/containerd.sock
root 2792 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 5aba84afafa0e41a93034903d079aaa5ba730b7b134fff3a1fd533e4db85f28b -address /run/containerd/containerd.sock
root 2957 1 0 02:29 ? 00:00:00 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id ced3e51f8774077aaaf52bf6e381f0e1d21be585cc1f2f1abd285a1588da638b -address /run/containerd/containerd.sock
我们会发现了一个奇怪的现象,containerd 进程是由 PID 1 号进程 systemd 托管,所以 containerd 进程的父进程 ID(PPID)毫无疑问就是 1;而由 containerd 拉起的 containerd-shim 进程的 PPID 也是 1,但实际上 containerd-shim 并非由 systemd 托管。
这一定是有意为之,containerd-shim 进程与 containerd 进程彻底脱离关系,containerd 进程即使崩溃重启就不会对 containerd-shim 进程造成任何影响,而 Kubernetes 集群中的各个容器进程正是由 containerd-shim 拉起的。
那么 Containerd 是如何做到 fork 出 containerd-shim 进程后保留其 PPID 的呢?
最终落实下来是一个名为 do_fork 的函数 https://github.com/torvalds/linux/blob/v3.10/kernel/fork.c#L1557-L1636:
fork 系统调用会通过 copy_process 函数复制进程结构,第一个参数 clone_flags 标记子进程从父进程中需要继承的资源清单。
再找同一文件下 copy_process 函数的定义 https://github.com/torvalds/linux/blob/v3.10/kernel/fork.c#L1124-L1533:
clone_flags 参数只要传入 CLONE_PARENT 即可在复制进程结构时保留原先的父进程信息。
结合上面 ps 命令的输出,containerd-shim 进程启动时确实带上了 namespace、id、address 这几个参数,但可执行二进制文件却是通过 os.Executable() 得到的,并不是通过变量传递来的,我们已经知道了这个执行文件就是 /usr/bin/containerd-shim-runc-v2。那就说明 containerd-shim 进程也是由一个 containerd-shim 父进程拉起来的。
结合源码 https://github.com/containerd/containerd/blob/v1.4.3/runtime/v2/shim/shim.go#L221-L229
还有 StartShim 方法 https://github.com/containerd/containerd/blob/v1.4.3/runtime/v2/runc/v2/service.go#L174-L286
**证实了我的猜想,containerd-shim 进程都是由一个 containerd-shim 父进程通过 start 子命令启动的。**那就回到原来的问题了,containerd-shim 是如何将 PPID 设置为为 1 的,毕竟 execsnoop 显示该进程实际的 PPID 是 1693。
containerd-shim 进程是通过 os/exec 包中的 Start 方法启动的 https://github.com/golang/go/blob/master/src/os/exec/exec.go#L370-L458:
再跳到 os 包的 StartProcess 函数 https://github.com/golang/go/blob/master/src/os/exec_posix.go:
再跳到 syscall 包的 StartProcess 函数 https://github.com/golang/go/blob/master/src/syscall/exec_unix.go
因为 Containerd 运行在 Linux 系统,所以 forkAndExecInChild 函数要看 Linux 的那份 https://github.com/golang/go/blob/master/src/syscall/exec_linux.go
根据 https://github.com/golang/go/blob/master/src/syscall/zsysnum_linux_amd64.go#L68 在 Linux amd64 架构中 SYS_EXECVE 为 59,这与 Linux 系统调用表 sys_call_table 是完全相同的。
再追下去就是汇编了。。。
所以搞了半天最终的系统调用还不是 fork。。。execve 落实下来是一个名为 do_execve 的函数 https://github.com/torvalds/linux/blob/v3.10/fs/exec.c
使用 execve 系统调用创建出来的进程是全新的,不会从原进程复制进程结构。
所以容器进程是通过系统调用 execve 创建出来的
62.028335 1688 1118 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -address /run/containerd/containerd.sock -publish-binary /usr/bin/containerd -id 66cbc3f2e8a67d59177959801cd6b9b3c76cb27833068c426e14dee5667b20d3 start # 此处有个 start
62.061869 1698 1693 /usr/bin/containerd-shim-runc-v2 -namespace k8s.io -id 66cbc3f2e8a67d59177959801cd6b9b3c76cb27833068c426e14dee5667b20d3 -address /run/containerd/containerd.sock
根据源码当 1693 进程也就是 1688 进程很快结束后,1698 也就成为了孤儿进程,孤儿进程会被 init 进程也即是 1 号进程(systemd)收养,这就是 containerd-shim 进程的 PPID 全都是 1 的原因。
kubelet是怎样创建容器的
Dockershim作用:把外部收到的请求转化成docker daemon能听懂的请求,让 Docker Daemon 执行创建、删除等容器操作。CRI容器运行时接口
- 参考链接:https://github.com/kubernetes/community/blob/master/contributors/devel/sig-node/container-runtime-interface.md
- CRI:容器运行时接口 container runtime interface,CRI 中定义了容器和镜像两个接口,实现了这两个接口目前主流的是:CRI-O、Containerd。(目前 PCI 产品使用的即为 Containerd)。
CRI接口的具体用处就在于
- 对容器操作的接口,包括容器的创建、启动和停止.即
create、stop等操作。- 对镜像的操作,下载、删除镜像等. 即
pull、rmi等操作。- podsandbox
- Kubelet 通过 CRI 接口(gRPC)调用
dockershim,请求创建一个容器。CRI 即容器运行时接口,这一步中,Kubelet 可以视作一个简单的CRI Client,而 dockershim 就是接收请求的 Server。目前dockershim是内嵌在 Kubelet 中的,所以接收调用就是 Kubelet 进程。 dockershim收到请求后,转化成 docker daemon的请求,发到docker daemon 上请求创建一个容器。- Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程 containerd 中,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器。
- containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让
containerd-shim去操作容器。是因为容器进程需要一个父进程来做诸如收集状态,维持 stdin 等 fd 打开等工作。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了containerd-shim就规避了这个问题(containerd 和 shim 并不是父子进程关系)。 - 我们知道创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范,那就是 OCI。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器。
- runC 启动完容器后本身会直接退出,
containerd-shim则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。
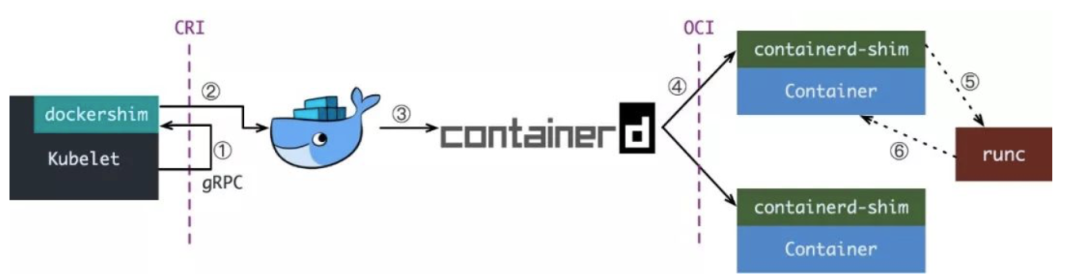
k8s 中 shim 的变化
在容器标准的大战中,docker公司围绕docker swarm推出了CNM,Google等以屠龙者的姿态围绕 k8s 推出了CNI,目前来看,k8s已经奠定了在 PaaS 事实的地位。
CRI 是一套通过 protocol buffers 定义的 API,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SG6AfPAj-1678071207067)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230306103608224.png)]](https://i-blog.csdnimg.cn/blog_migrate/6b086d617c30cfacf3d64c8f1ae28e18.png)
kubelet 实现了 client 端,CRI shim 实现 server 端。只要实现CRI对应的接口,就能接入 k8s 作为 Container Runtime。
-
k8s 1.5 中自己实现了 docker CRI shim,此时启动容器的流程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TlTY5T3H-1678071207067)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230303150331590.png)]](https://i-blog.csdnimg.cn/blog_migrate/c1539f3dd4194df7b0dfd79658c63ca6.png)
-
从 containerd 1.0 开始,为了能够减少一层调用的开销(废掉docker,也就是把上边的docker cri shim和docker踢掉),containerd 开发了一个新的 daemon,叫做 CRI-Containerd,直接与 containerd 通信,从而取代了 dockershim:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tiBwdcdh-1678071207068)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230303150351430.png)]](https://i-blog.csdnimg.cn/blog_migrate/181f2fbfb27ff276e788dbeb349e944b.png)
-
但是这仍然多了一个独立的 daemon,从 containerd 1.1 开始,社区选择在 containerd 中直接内建 CRI plugin,通过方法调用来进行交互,从而减少一层 gRPC 的开销,最终的容器启动流程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IplTFGUN-1678071207068)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230303150444829.png)]](https://i-blog.csdnimg.cn/blog_migrate/c734473cbf0ff2e80e61c34460fa3400.png)
最终的结果是 k8s 的 Pod 启动延迟得到了降低,CPU 和内存占用率都有不同程度的降低。
-
但是这还不是终点,为了能够直接对接 OCI 的 runtime 而不是 containerd,社区孵化了 CRI-O 并加入了 CNCF。CRI-O 的目标是让 kubelet 与运行时直接对接,减少任何不必要的中间层开销。CRI-O 运行时可以替换为任意 OCI 兼容的 Runtime,镜像管理,存储管理和网络均使用标准化的实现。
@xuxinkun 的文章中有个图将他们之间的关系描绘的很清楚:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vqmWbwF9-1678071207069)(/Users/dufengyang/Library/Application Support/typora-user-images/image-20230303150508901.png)]](https://i-blog.csdnimg.cn/blog_migrate/6f66304abf67f75dddbf846ec0064a68.png)
以下更新于2021年4月9日

















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









