







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
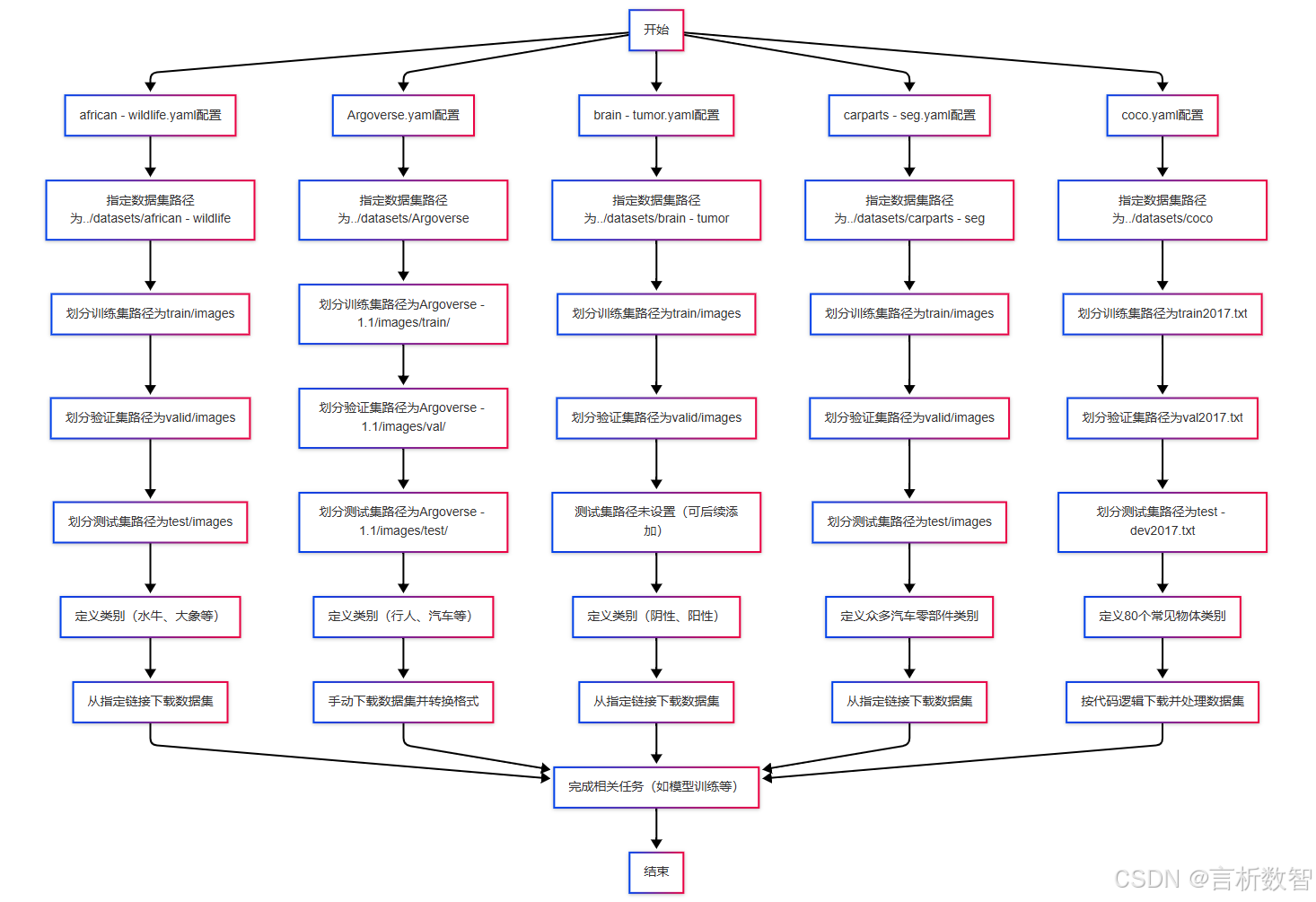
african-wildlife.yaml- 通常用于配置与
非洲野生动物相关的数据集或模型训练等任务。 - 比如指定数据集的路径、划分训练集 / 验证集 / 测试集的方式,以及定义数据集中不同野生动物类别的名称等信息,为相关的研究、模型训练和分析提供配置依据。
- 通常用于配置与
Argoverse.yaml- 一般是针对 Argoverse 数据集或相关任务的配置文件。
- 可能用于指定 Argoverse 数据集的存储位置、数据格式说明,以及在进行与
自动驾驶、交通场景分析等相关任务时,对数据处理、模型训练参数等进行配置。
brain-tumor.yaml- 主要用于
脑部肿瘤相关的项目,比如脑部肿瘤图像数据集的管理和模型训练配置。 - 它可以规定数据集的路径,包括不同模态(如 MRI、CT 等)图像的存放位置,以及标注信息的格式,还可能包含用于
训练肿瘤检测、分割或分类模型的超参数等配置信息。
- 主要用于
carparts-seg.yaml- 从名称推测,是用于
汽车零部件分割任务的配置文件。 - 文件中会指定汽车零部件数据集的路径,如训练集、验证集和测试集图像的存储位置,同时会定义数据集中各个汽车零部件类别的名称,为汽车零部件分割模型的训练和评估提供必要的配置信息。
- 从名称推测,是用于
coco.yamlCOCO(Common Objects in Context)数据集是计算机视觉领域常用的数据集,这个文件是针对 COCO 数据集的配置文件。- 它会指定 COCO 数据集的路径,包括图像和标注文件的位置,
定义数据集中 80 个类别的名称,还可能包含一些与模型训练、评估相关的参数配置,例如数据增强方式、模型输入尺寸等,方便在使用 COCO 数据集进行目标检测、实例分割、图像分类等任务时进行统一的配置和管理。
african-wildlife.yaml
african-wildlife.yaml# 数据集所在的根路径 path: ../datasets/african-wildlife # 训练集图片所在的相对路径,相对于path指定的根路径 train: train/images # 验证集图片所在的相对路径,相对于path指定的根路径 val: valid/images # 测试集图片所在的相对路径,相对于path指定的根路径 test: test/images # 类别名称映射,键为类别编号,值为对应的类别名称 names: 0: buffalo # 编号为0的类别是水牛 1: elephant # 编号为1的类别是大象 2: rhino # 编号为2的类别是犀牛 3: zebra # 编号为3的类别是斑马 # 数据集的下载链接,可通过此链接下载数据集 download: https://github.com/ultralytics/assets/releases/download/v0.0.0/african-wildlife.zip
Argoverse.yaml
Argoverse.yaml# 数据集的根路径,指定了数据集在文件系统中的位置 path: ../datasets/Argoverse # 训练集图片所在的相对路径,相对于path指定的根路径 train: Argoverse-1.1/images/train/ # 验证集图片所在的相对路径,相对于path指定的根路径 val: Argoverse-1.1/images/val/ # 测试集图片所在的相对路径,相对于path指定的根路径 test: Argoverse-1.1/images/test/ # 类别名称映射,键为类别编号,值为对应的类别名称 names: 0: person # 编号为0的类别是行人 1: bicycle # 编号为1的类别是自行车 2: car # 编号为2的类别是汽车 3: motorcycle # 编号为3的类别是摩托车 4: bus # 编号为4的类别是公交车 5: truck # 编号为5的类别是卡车 6: traffic_light # 编号为6的类别是交通信号灯 7: stop_sign # 编号为7的类别是停车标志 # 数据集下载及格式转换的Python代码 download: | # 导入json模块,用于处理JSON格式的数据 import json # 导入Path类,用于处理文件路径 from pathlib import Path # 导入tqdm库,用于显示进度条 from tqdm import tqdm # 从ultralytics库中导入download函数,可能用于下载文件 from ultralytics.utils.downloads import download def argoverse2yolo(set): """ 将Argoverse数据集的标注信息转换为YOLO格式,用于目标检测任务。 :param set: 包含标注信息的JSON文件路径 """ # 用于存储每个图像对应的标注信息 labels = {} # 打开JSON文件并加载其中的标注信息 a = json.load(open(set, "rb")) # 遍历所有标注信息,使用tqdm显示进度条 for annot in tqdm(a["annotations"], desc=f"Converting {set} to YOLOv5 format..."): # 获取当前标注对应的图像ID img_id = annot["image_id"] # 根据图像ID获取图像的名称 img_name = a["images"][img_id]["name"] # 生成对应的标注文件名称,将图像文件扩展名替换为txt img_label_name = f"{img_name[:-3]}txt" # 获取当前标注的类别ID cls = annot["category_id"] # 获取边界框的坐标和尺寸信息 x_center, y_center, width, height = annot["bbox"] # 计算归一化后的中心坐标x x_center = (x_center + width / 2) / 1920.0 # 计算归一化后的中心坐标y y_center = (y_center + height / 2) / 1200.0 # 归一化边界框的宽度 width /= 1920.0 # 归一化边界框的高度 height /= 1200.0 # 计算标注文件的存储目录 img_dir = set.parents[2] / "Argoverse-1.1" / "labels" / a["seq_dirs"][a["images"][annot["image_id"]]["sid"]] # 如果标注文件存储目录不存在,则创建该目录 if not img_dir.exists(): img_dir.mkdir(parents=True, exist_ok=True) # 构建标注文件的完整路径 k = str(img_dir / img_label_name) # 如果该标注文件路径还未在labels字典中,则初始化一个空列表 if k not in labels: labels[k] = [] # 将当前标注信息添加到对应的标注文件列表中 labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n") # 遍历所有标注文件路径 for k in labels: # 打开标注文件并写入标注信息 with open(k, "w", encoding="utf-8") as f: f.writelines(labels[k]) # 获取数据集的根目录 dir = Path(yaml["path"]) # 定义数据集的下载链接 urls = ["https://drive.google.com/file/d/1st9qW3BeIwQsnR0t8mRpvbsSWIo16ACi/view?usp=drive_link"] # 打印警告信息,提示需要手动下载数据集 print("\n\nWARNING: Argoverse dataset MUST be downloaded manually, autodownload will NOT work.") # 打印警告信息,提示手动下载数据集的链接和保存位置 print(f"WARNING: Manually download Argoverse dataset '{urls[0]}' to '{dir}' and re-run your command.\n\n") # 定义标注文件所在的目录 annotations_dir = "Argoverse-HD/annotations/" # 将'tracking'目录重命名为'images'目录 (dir / "Argoverse-1.1" / "tracking").rename(dir / "Argoverse-1.1" / "images") # 遍历训练集和验证集的标注文件 for d in "train.json", "val.json": # 调用argoverse2yolo函数将标注信息转换为YOLO格式 argoverse2yolo(dir / annotations_dir / d)
brain-tumor.yaml
brain-tumor.yaml# 数据集在文件系统中的根路径,后续的 train、val、test 路径都基于此路径 path: ../datasets/brain-tumor # 训练集图片所在的相对路径,相对于上面指定的 path 路径 train: train/images # 验证集图片所在的相对路径,相对于 path 路径 val: valid/images # 测试集图片所在的相对路径,此处留空可能表示暂时未指定测试集路径 test: # 类别名称映射,键为类别编号,值为对应的类别名称 names: # 编号为 0 的类别代表阴性(无肿瘤) 0: negative # 编号为 1 的类别代表阳性(有肿瘤) 1: positive # 数据集的下载链接,可通过该链接获取此数据集 download: https://github.com/ultralytics/assets/releases/download/v0.0.0/brain-tumor.zip
carparts-seg.yaml
carparts-seg.yaml# 数据集在文件系统中的根路径,后续 train、val、test 路径均相对于此路径 path: ../datasets/carparts-seg # 训练集图像所在的相对路径,该路径下存放用于模型训练的图像数据 train: train/images # 验证集图像所在的相对路径,此路径下的图像用于在训练过程中验证模型的性能 val: valid/images # 测试集图像所在的相对路径,路径下的图像用于最终评估训练好的模型的性能 test: test/images # 类别名称映射,键为类别编号,值为对应的类别名称 names: 0: back_bumper # 编号 0 代表汽车后保险杠类别 1: back_door # 编号 1 代表汽车后门类别 2: back_glass # 编号 2 代表汽车后挡风玻璃类别 3: back_left_door # 编号 3 代表汽车左后门类别 4: back_left_light # 编号 4 代表汽车左后灯类别 5: back_light # 编号 5 代表汽车后灯类别 6: back_right_door # 编号 6 代表汽车右后门类别 7: back_right_light # 编号 7 代表汽车右后灯类别 8: front_bumper # 编号 8 代表汽车前保险杠类别 9: front_door # 编号 9 代表汽车前门类别 10: front_glass # 编号 10 代表汽车前挡风玻璃类别 11: front_left_door # 编号 11 代表汽车左前门类别 12: front_left_light # 编号 12 代表汽车左前灯类别 13: front_light # 编号 13 代表汽车前灯类别 14: front_right_door # 编号 14 代表汽车右前门类别 15: front_right_light # 编号 15 代表汽车右前灯类别 16: hood # 编号 16 代表汽车发动机罩类别 17: left_mirror # 编号 17 代表汽车左后视镜类别 18: object # 编号 18 代表通用物体类别 19: right_mirror # 编号 19 代表汽车右后视镜类别 20: tailgate # 编号 20 代表汽车尾门类别 21: trunk # 编号 21 代表汽车后备箱类别 22: wheel # 编号 22 代表汽车车轮类别 # 数据集的下载链接,通过该链接可以获取此汽车零部件分割数据集 download: https://github.com/ultralytics/assets/releases/download/v0.0.0/carparts-seg.zip
coco.yaml
coco.yaml-79种类别# 数据集在文件系统中的根路径,后续的 train、val、test 路径均相对于此路径 path: ../datasets/coco # 训练集文件,包含训练图像相关信息的文件路径,相对于 path 路径 train: train2017.txt # 验证集文件,包含验证图像相关信息的文件路径,相对于 path 路径 val: val2017.txt # 测试集文件,包含测试图像相关信息的文件路径,相对于 path 路径 test: test-dev2017.txt # 类别名称映射,键为类别编号,值为对应的类别名称 names: 0: person # 编号 0 代表行人类别 1: bicycle # 编号 1 代表自行车类别 2: car # 编号 2 代表汽车类别 3: motorcycle # 编号 3 代表摩托车类别 4: airplane # 编号 4 代表飞机类别 5: bus # 编号 5 代表公交车类别 6: train # 编号 6 代表火车类别 7: truck # 编号 7 代表卡车类别 8: boat # 编号 8 代表船类别 9: traffic light # 编号 9 代表交通信号灯类别 10: fire hydrant # 编号 10 代表消防栓类别 11: stop sign # 编号 11 代表停车标志类别 12: parking meter # 编号 12 代表停车计时器类别 13: bench # 编号 13 代表长椅类别 14: bird # 编号 14 代表鸟类类别 15: cat # 编号 15 代表猫类别 16: dog # 编号 16 代表狗类别 17: horse # 编号 17 代表马类别 18: sheep # 编号 18 代表绵羊类别 19: cow # 编号 19 代表牛类别 20: elephant # 编号 20 代表大象类别 21: bear # 编号 21 代表熊类别 22: zebra # 编号 22 代表斑马类别 23: giraffe # 编号 23 代表长颈鹿类别 24: backpack # 编号 24 代表背包类别 25: umbrella # 编号 25 代表雨伞类别 26: handbag # 编号 26 代表手提包类别 27: tie # 编号 27 代表领带类别 28: suitcase # 编号 28 代表行李箱类别 29: frisbee # 编号 29 代表飞盘类别 30: skis # 编号 30 代表滑雪板类别 31: snowboard # 编号 31 代表滑雪板(单板)类别 32: sports ball # 编号 32 代表运动球类类别 33: kite # 编号 33 代表风筝类别 34: baseball bat # 编号 34 代表棒球棒类别 35: baseball glove # 编号 35 代表棒球手套类别 36: skateboard # 编号 36 代表滑板类别 37: surfboard # 编号 37 代表冲浪板类别 38: tennis racket # 编号 38 代表网球拍类别 39: bottle # 编号 39 代表瓶子类别 40: wine glass # 编号 40 代表酒杯类别 41: cup # 编号 41 代表杯子类别 42: fork # 编号 42 代表叉子类别 43: knife # 编号 43 代表刀类别 44: spoon # 编号 44 代表勺子类别 45: bowl # 编号 45 代表碗类别 46: banana # 编号 46 代表香蕉类别 47: apple # 编号 47 代表苹果类别 48: sandwich # 编号 48 代表三明治类别 49: orange # 编号 49 代表橙子类别 50: broccoli # 编号 50 代表西兰花类别 51: carrot # 编号 51 代表胡萝卜类别 52: hot dog # 编号 52 代表热狗类别 53: pizza # 编号 53 代表披萨类别 54: donut # 编号 54 代表甜甜圈类别 55: cake # 编号 55 代表蛋糕类别 56: chair # 编号 56 代表椅子类别 57: couch # 编号 57 代表沙发类别 58: potted plant # 编号 58 代表盆栽植物类别 59: bed # 编号 59 代表床类别 60: dining table # 编号 60 代表餐桌类别 61: toilet # 编号 61 代表马桶类别 62: tv # 编号 62 代表电视类别 63: laptop # 编号 63 代表笔记本电脑类别 64: mouse # 编号 64 代表鼠标类别 65: remote # 编号 65 代表遥控器类别 66: keyboard # 编号 66 代表键盘类别 67: cell phone # 编号 67 代表手机类别 68: microwave # 编号 68 代表微波炉类别 69: oven # 编号 69 代表烤箱类别 70: toaster # 编号 70 代表烤面包机类别 71: sink # 编号 71 代表水槽类别 72: refrigerator # 编号 72 代表冰箱类别 73: book # 编号 73 代表书籍类别 74: clock # 编号 74 代表时钟类别 75: vase # 编号 75 代表花瓶类别 76: scissors # 编号 76 代表剪刀类别 77: teddy bear # 编号 77 代表泰迪熊类别 78: hair drier # 编号 78 代表吹风机类别 79: toothbrush # 编号 79 代表牙刷类别 # 数据集下载的 Python 代码 download: | # 从 pathlib 模块导入 Path 类,用于处理文件路径 from pathlib import Path # 从 ultralytics 库的 utils.downloads 模块导入 download 函数,用于下载文件 from ultralytics.utils.downloads import download # 是否使用分割标注数据的标志 segments = True # 获取数据集的根目录 dir = Path(yaml["path"]) # 定义基础下载链接 url = "https://github.com/ultralytics/assets/releases/download/v0.0.0/" # 根据 segments 标志选择不同的标注数据压缩包 urls = [url + ("coco2017labels-segments.zip" if segments else "coco2017labels.zip")] # 调用 download 函数下载标注数据压缩包到数据集根目录的父目录 download(urls, dir=dir.parent) # 定义图像数据的下载链接列表 urls = [ "http://images.cocodataset.org/zips/train2017.zip", # 训练集图像压缩包,约 19G,包含 118k 张图像 "http://images.cocodataset.org/zips/val2017.zip", # 验证集图像压缩包,约 1G,包含 5k 张图像 "http://images.cocodataset.org/zips/test2017.zip", # 测试集图像压缩包,约 7G,包含 41k 张图像(可选) ] # 调用 download 函数下载图像数据压缩包到数据集根目录下的 images 子目录,使用 3 个线程进行下载 download(urls, dir=dir / "images", threads=3)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











