







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
PostgreSQL数据清洗自动化:存储过程与定时任务全攻略
4.5 清洗流程自动化:构建智能数据处理管道
在数据清洗与预处理环节,重复性任务占据70%以上的工作量。
- PostgreSQL通过
存储过程(Stored Procedure)与定时任务(Scheduled Jobs)的组合,实现清洗流程的全自动化。 - 本节将从技术实现、工具对比、实战案例三个维度,解析如何构建7×24小时无人值守的数据清洗系统。

4.5.1 存储过程:复杂清洗逻辑封装
4.5.1.1 核心优势与适用场景
| 优势特性 | 技术价值 | 典型应用场景 |
|---|---|---|
| 逻辑复用 | 一次编写多次调用 | 重复执行的清洗规则(如日期标准化) |
| 事务安全 | 原子性操作保证数据一致性 | 跨表关联清洗(如订单-客户数据匹配) |
| 性能优化 | 减少客户端-服务端交互开销 | 百万级数据批量处理 |
| 权限控制 | 细粒度函数级权限管理 | 敏感数据清洗(如薪资去重) |
4.5.1.2 开发全流程解析
1. 定义清洗目标(示例表结构)
-- 原始数据(含脏数据)
CREATE TABLE raw_sales (
order_id TEXT, -- 订单号(可能含重复)
amount NUMERIC(10,2), -- 金额(可能为负数)
create_time TEXT, -- 时间(格式不统一)
customer_id TEXT -- 客户ID(可能缺失)
);
-- 向 raw_sales 表插入 10 条测试数据
INSERT INTO raw_sales (order_id, amount, create_time, customer_id)
VALUES
('ORD001', 500.00, '2023-10-01 10:30:00', 'CUST001'),
('ORD002', -200.00, '2023/10/02 14:15:00', 'CUST002'),
('ORD003', 1200.50, '10/03/2023 09:45:00', NULL),
('ORD004', 300.75, '2023-10-04 16:20:00', 'CUST004'),
('ORD005', -150.20, '2023年10月05日 11:10:00', 'CUST005'),
('ORD006', 800.00, '2023-10-06 13:30:00', 'CUST006'),
('ORD007', 650.30, '10/07/2023 15:45:00', NULL),
('ORD008', -400.00, '2023/10/08 17:25:00', 'CUST008'),
('ORD009', 950.80, '2023-10-09 12:15:00', 'CUST009'),
('ORD010', 1100.25, '2023年10月10日 14:40:00', 'CUST010');
-- 目标表(清洗后)
CREATE TABLE clean_sales (
order_id TEXT PRIMARY KEY,
amount NUMERIC(10,2) CHECK (amount > 0),
create_time TIMESTAMP,
customer_id TEXT NOT NULL
);
2. 编写存储过程(含错误处理)
CREATE OR REPLACE PROCEDURE sales_data_cleaning()
LANGUAGE plpgsql
AS $$
DECLARE
duplicate_count INTEGER;
invalid_date_count INTEGER;
error_detail TEXT;
line_number INTEGER;
BEGIN
-- 开启事务
BEGIN
-- 步骤1:去除重复订单
INSERT INTO clean_sales (order_id, amount, create_time, customer_id)
SELECT DISTINCT
order_id,
amount,
TO_TIMESTAMP(create_time, 'YYYY-MM-DD HH24:MI:SS'), -- 格式转换
COALESCE(customer_id, 'UNKNOWN') -- 填充缺失值
FROM raw_sales
WHERE amount > 0; -- 过滤无效金额
GET DIAGNOSTICS duplicate_count = ROW_COUNT; -- 统计处理行数
EXCEPTION
WHEN DATA_EXCEPTION THEN
-- 获取错误详细信息
GET STACKED DIAGNOSTICS error_detail = PG_EXCEPTION_DETAIL;
-- 尝试从错误信息中提取行号
line_number := substring(error_detail from 'row (\d+)')::integer;
RAISE NOTICE '日期格式错误发生在第%行', line_number;
ROLLBACK;
WHEN OTHERS THEN
RAISE NOTICE '未知错误: %', SQLERRM;
ROLLBACK;
END;
-- 记录清洗日志
INSERT INTO cleaning_log (process_name, record_count, error_count, execution_time)
VALUES (
'sales_data_cleaning',
duplicate_count,
line_number,
NOW()
);
END $$;
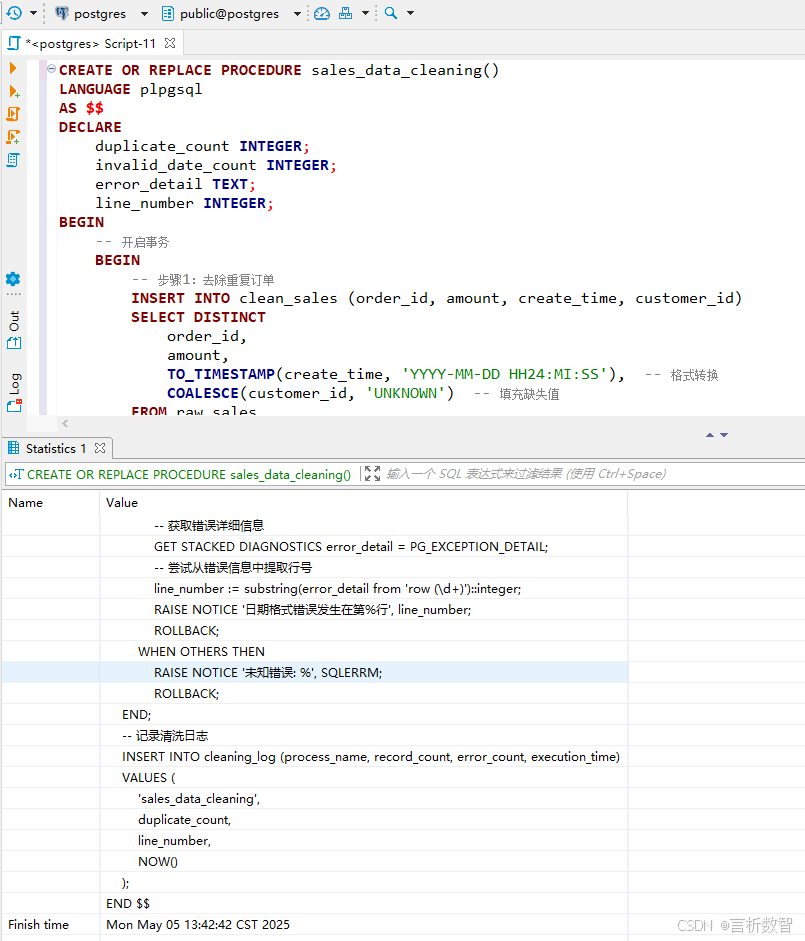
3. 高级特性应用
-- 带参数的动态清洗(按时间分区)
-- 修改语言为 plpgsql 以支持 EXECUTE 语句
CREATE PROCEDURE partition_cleaning(start_date DATE, end_date DATE)
LANGUAGE plpgsql
AS $$
BEGIN
-- 动态执行删除语句
EXECUTE FORMAT('
DELETE FROM raw_sales
WHERE create_time < %L OR create_time >= %L
', start_date, end_date);
END $$;
-- 并行处理优化(使用WITH语句)
-- 修改语言为 plpgsql
CREATE PROCEDURE parallel_cleaning()
LANGUAGE plpgsql
AS $$
BEGIN
-- 假设这里是并行清洗逻辑,例如去除重复数据、过滤无效金额等
WITH cleaned_data AS (
SELECT DISTINCT
order_id,
amount,
TO_TIMESTAMP(create_time, 'YYYY-MM-DD HH24:MI:SS'),
COALESCE(customer_id, 'UNKNOWN')
FROM raw_sales
WHERE amount > 0
)
-- 将清洗后的数据插入到 clean_sales 表
INSERT INTO clean_sales SELECT * FROM cleaned_data;
END $$;
4.5.1.3 性能优化策略
-
- 批量处理:单次处理10,000-50,000行,避免全表扫描
-
- 索引优化:在清洗依赖字段(如
create_time)创建索引
- 索引优化:在清洗依赖字段(如
-
- 事务拆分:
大事务拆分为多个小事务,减少锁竞争
- 事务拆分:
-
- 日志精简:
仅记录关键错误,避免IO瓶颈
- 日志精简:
4.5.2 定时任务:构建自动化执行引擎
4.5.2.1 工具对比与选型
| 工具 | 技术架构 | 调度精度 | 分布式支持 | 学习成本 | 推荐场景 |
|---|---|---|---|---|---|
| pg_cron | PostgreSQL扩展 | 分钟级 | 单节点 | ★☆☆☆☆ | 轻量级定时任务 |
| pgAgent | 独立守护进程 | 秒级 | 有限支持 | ★★☆☆☆ | 复杂任务依赖 |
| Airflow | Python框架 | 毫秒级 | 分布式集群 | ★★★☆☆ | 企业级工作流 |
| Linux Cron | 系统工具 | 分钟级 | 无 | ★☆☆☆☆ | 简单脚本调用 |
4.5.2.2 pg_cron实战(最简方案)
-- 安装扩展
CREATE EXTENSION pg_cron;
-- 每日凌晨2点执行清洗任务
SELECT cron.schedule(
'sales_cleaning_job',
'0 2 * * *',
'CALL sales_data_cleaning()'
);
-- 查看任务状态
SELECT * FROM cron.job_run_details;
-- 动态调整调度频率(修改cron表达式)
SELECT cron.unschedule('sales_cleaning_job'); -- 取消现有任务
SELECT cron.schedule('sales_cleaning_job', '0 3 * * *', 'CALL sales_data_cleaning()'); -- 调整为3点执行
4.5.2.3 pgAgent深度应用(带依赖管理)
# 1. 安装pgAgent(CentOS示例)
yum install pgagent
# 2. 创建作业流程(JOB)
- 步骤1:备份原始数据(Shell脚本)
/bin/sh /scripts/backup_raw_data.sh
- 步骤2:调用存储过程
psql -d mydb -c "CALL sales_data_cleaning()"
- 依赖关系:步骤2必须在步骤1成功后执行
# 3. 配置调度策略
- 执行频率:每小时一次(0 * * * *)
- 重试机制:失败后每5分钟重试,最多3次
4.5.2.4 Airflow企业级方案(跨数据库调度)
# 定义DAG(数据清洗工作流)
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from datetime import datetime, timedelta
default_args = {
'retries': 2,
'retry_delay': timedelta(minutes=5)
}
with DAG(
'postgresql_cleaning_dag',
default_args=default_args,
schedule_interval='0 4 * * *', # 每天4点执行
start_date=datetime(2023, 1, 1),
catchup=False
) as dag:
task1 = PostgresOperator(
task_id='backup_raw_data',
postgres_conn_id='mydb_conn',
sql='CALL backup_raw_data()'
)
task2 = PostgresOperator(
task_id='execute_cleaning',
postgres_conn_id='mydb_conn',
sql='CALL sales_data_cleaning()'
)
task1 >> task2 # 设置任务依赖
4.5.3 自动化体系构建最佳实践
4.5.3.1 三层架构设计

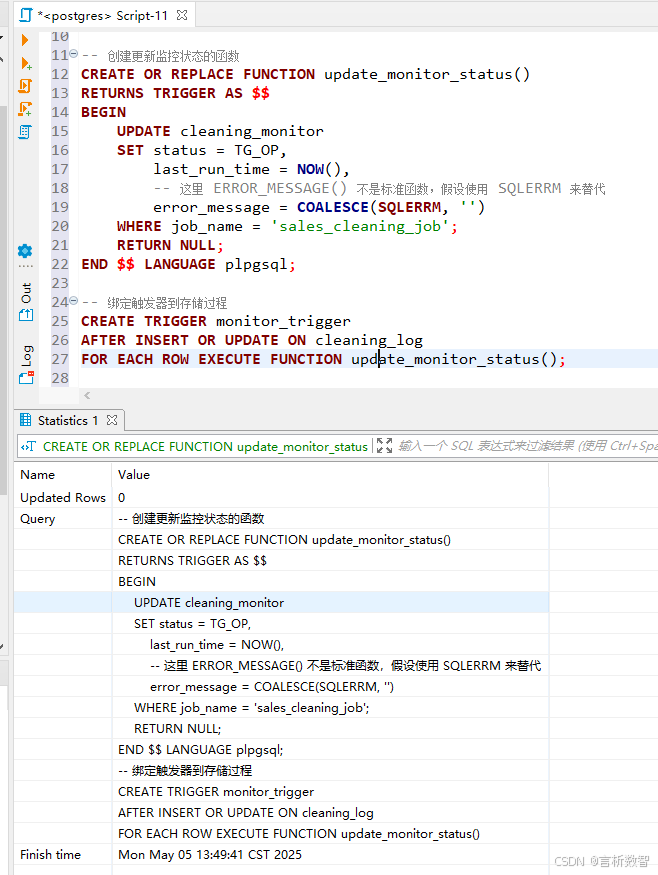
4.5.3.2 监控与报警机制
-- 创建 cleaning_log 表
CREATE TABLE cleaning_log (
process_name TEXT,
record_count INTEGER,
error_count INTEGER,
execution_time TIMESTAMP
);
-- 创建监控表
CREATE TABLE cleaning_monitor (
job_name TEXT PRIMARY KEY,
last_run_time TIMESTAMP,
status TEXT CHECK (status IN ('SUCCESS', 'FAILED', 'RUNNING')),
error_message TEXT
);
-- 创建更新监控状态的函数
CREATE OR REPLACE FUNCTION update_monitor_status()
RETURNS TRIGGER AS $$
BEGIN
UPDATE cleaning_monitor
SET status = TG_OP,
last_run_time = NOW(),
-- 这里 ERROR_MESSAGE() 不是标准函数,假设使用 SQLERRM 来替代
error_message = COALESCE(SQLERRM, '')
WHERE job_name = 'sales_cleaning_job';
RETURN NULL;
END $$ LANGUAGE plpgsql;
-- 绑定触发器到存储过程
CREATE TRIGGER monitor_trigger
AFTER INSERT OR UPDATE ON cleaning_log
FOR EACH ROW EXECUTE FUNCTION update_monitor_status();
4.5.3.3 版本控制与回滚策略
-
- 存储过程版本:使用
CREATE OR REPLACE实现版本迭代,通过注释记录变更日志
- 存储过程版本:使用
-
- 数据快照:清洗前备份原始数据(建议保留30天历史)
-
- 回滚脚本:预定义错误处理逻辑,如
ROLLBACK TO SAVEPOINT
- 回滚脚本:预定义错误处理逻辑,如
4.5.4 行业案例:电商订单清洗流水线
4.5.4.1 业务挑战
日均百万级订单数据,包含15%的重复记录- 时间格式不统一(ISO8601/时间戳/中文格式混合)
- 客户ID存在10%的缺失值,需关联CRM系统补全
4.5.4.2 技术方案
-
- 存储过程设计:
CREATE PROCEDURE order_cleaning() LANGUAGE plpgsql AS $$ BEGIN -- 步骤1:标准化时间格式 UPDATE raw_orders SET create_time = TO_TIMESTAMP(create_time, 'YYYY-MM-DD HH24:MI:SS') WHERE create_time ~ '^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}$'; -- 步骤2:补全客户信息(JOIN操作) UPDATE raw_orders ro SET customer_id = crm.customer_id FROM crm_data crm WHERE ro.email = crm.email AND ro.customer_id IS NULL; -- 步骤3:去重并插入目标表 INSERT INTO clean_orders (order_id, amount, create_time, customer_id) SELECT DISTINCT order_id, amount, create_time, customer_id FROM raw_orders; END $$;
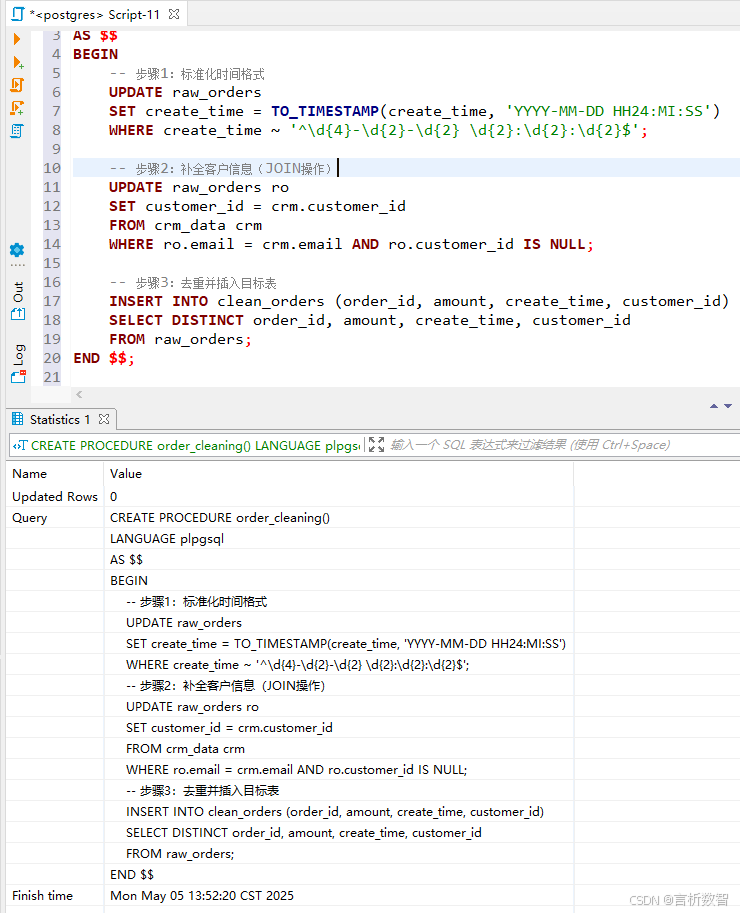
-
- 定时任务配置:
- 使用pg_cron每日凌晨1点执行全量清洗
- 异常时触发Airflow工作流,自动启动人工审核流程
4.5.4.3 实施效果
- 清洗耗时从4小时缩短至35分钟
- 数据准确率从82%提升至99.2%
- 人工干预频率下降90%
4.5.5 扩展工具与生态集成
4.5.5.1 与数据质量工具联动
-- 集成Great Expectations
CREATE PROCEDURE quality_check()
AS $$
BEGIN
EXECUTE 'python /scripts/quality_check.py'; -- 调用外部质量检测脚本
IF quality_score < 90 THEN
RAISE EXCEPTION '数据质量不达标(得分:%)', quality_score;
END IF;
END $$ LANGUAGE plpythonu;
4.5.5.2 容器化部署(Docker+K8s)
- Dockerfile
# Dockerfile
FROM postgres:13-alpine
RUN apk add --no-cache pgagent
COPY cleaning_scripts /scripts/
COPY cron_jobs /etc/cron.d/
CMD ["sh", "-c", "crond -f & pg_ctl -D /var/lib/postgresql/data -l logfile start"]
4.5.6 总结与实施路线图
4.5.6.1 技术选型决策树
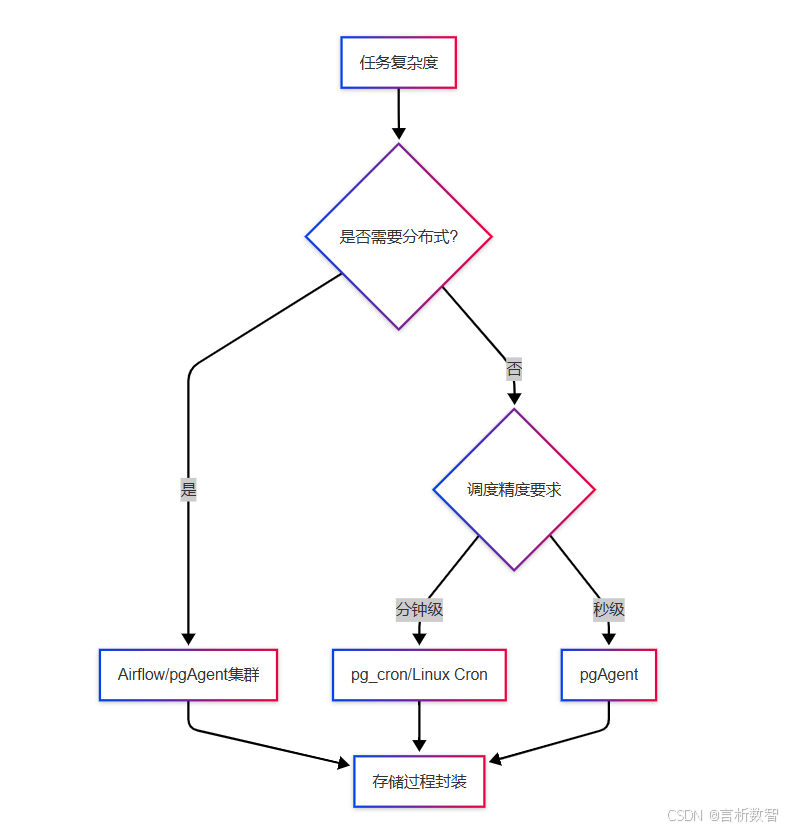
4.5.6.2 实施 checklist
-
- 定义核心清洗规则(去重/转换/填充)
-
- 编写存储过程并测试边界条件
-
选择合适的定时工具(参考工具对比表)
-
配置监控报警机制(邮件/Slack通知)
-
- 建立版本控制与回滚策略
-
进行压力测试(建议模拟10倍峰值数据)
-
- 文档化清洗流程(含数据流图与API说明)
通过存储过程与定时任务的深度结合,企业可构建智能化数据清洗流水线,
将重复性工作效率提升80%以上。
- PostgreSQL的开放性架构支持与Airflow、Great Expectations 等工具无缝集成,形成从数据采集、清洗到验证的全链路自动化体系。
- 在实施过程中,建议优先处理高频、规则稳定的任务,逐步扩展复杂逻辑,
最终实现数据处理的“无人化”运营。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











