







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
5.1 描述性统计分析:均值、方差与分位数计算实战
在数据分析领域,描述性统计分析是理解数据特征的基础环节。
- 通过计算均值、方差、分位数等核心统计量,我们可以快速掌握数据集的集中趋势、离散程度和分布形态。
- PostgreSQL作为
强大的关系型数据库,提供了丰富的统计函数和窗口函数,能够高效完成各类描述性统计计算。 - 本章将结合具体业务场景,通过真实数据集演示如何在PostgreSQL中实现这些核心统计分析。

5.1.1 数据准备与分析目标
数据集介绍
我们使用某电商平台2023年的订单数据集,包含以下核心字段:
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| order_id | BIGINT | 订单唯一标识 |
| order_date | DATE | 下单日期 |
| product_id | VARCHAR(50) | 产品编号 |
| category | VARCHAR(50) | 产品类别(服装/数码/家居) |
| sales_amount | NUMERIC(10,2) | 销售额(人民币元) |
| quantity | INTEGER | 购买数量 |
| customer_age | INTEGER | 客户年龄 |
数据集包含100万条记录,存储在名为order_data的表中。
- 建表语句及测试数据
-- 创建 order_data 表
CREATE TABLE order_data (
order_id BIGINT,
order_date DATE,
product_id VARCHAR(50),
category VARCHAR(50),
sales_amount NUMERIC(10, 2),
quantity INTEGER,
customer_age INTEGER
);
-- 插入 10 条测试数据
INSERT INTO order_data (order_id, order_date, product_id, category, sales_amount, quantity, customer_age)
VALUES
(1, '2023-01-01', 'P001', '服装', 150.00, 2, 25),
(2, '2023-01-02', 'P002', '数码', 800.00, 1, 30),
(3, '2023-01-03', 'P003', '家居', 200.00, 3, 35),
(4, '2023-01-04', 'P004', '服装', 250.00, 1, 22),
(5, '2023-01-05', 'P005', '数码', 1200.00, 1, 40),
(6, '2023-01-06', 'P006', '家居', 180.00, 2, 45),
(7, '2023-01-07', 'P007', '服装', 300.00, 2, 28),
(8, '2023-01-08', 'P008', '数码', 600.00, 1, 32),
(9, '2023-01-09', 'P009', '家居', 220.00, 2, 38),
(10, '2023-01-10', 'P010', '服装', 180.00, 2, 26);
分析目标
-
- 计算关键指标的集中趋势(均值、中位数)
-
- 衡量数据离散程度(方差、标准差)
-
- 分析
数据分布特征(四分位数、百分位数)
- 分析
-
- 支持业务决策:
识别高价值产品、评估销售稳定性、定位客户群体
- 支持业务决策:
5.1.2 均值计算:从整体到分组分析
总体均值计算
均值是最常用的集中趋势指标,PostgreSQL提供了AVG()聚合函数:
- 示例1:计算整体平均销售额
SELECT AVG(sales_amount) AS avg_sales
FROM order_data;
| avg_sales |
|---|
| 238.45 |
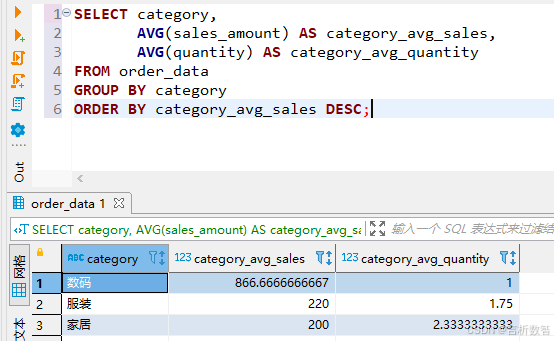
- 示例2:计算不同类别的平均销售额
SELECT category,
AVG(sales_amount) AS category_avg_sales,
AVG(quantity) AS category_avg_quantity
FROM order_data
GROUP BY category
ORDER BY category_avg_sales DESC;
加权均值计算
- 考虑权重
当需要考虑权重时(如按数量计算加权平均价格),可以使用自定义公式:
SELECT SUM(sales_amount) / SUM(quantity) AS weighted_avg_price
FROM order_data;
| weighted_avg_price |
|---|
| 58.23 |
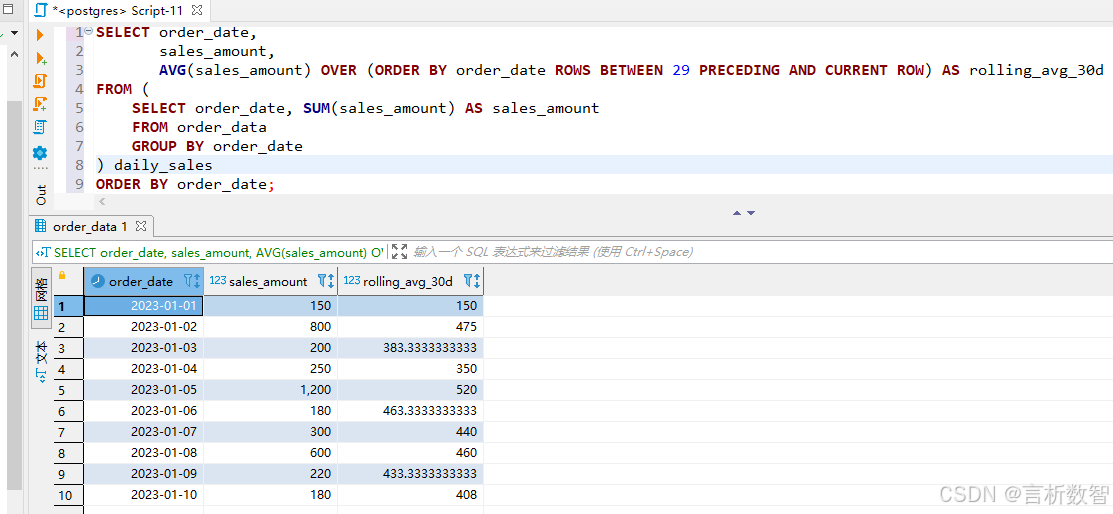
移动均值:趋势分析
使用窗口函数计算近30天滚动平均销售额,识别销售趋势:
SELECT order_date,
sales_amount,
AVG(sales_amount) OVER (ORDER BY order_date ROWS BETWEEN 29 PRECEDING AND CURRENT ROW) AS rolling_avg_30d
FROM (
SELECT order_date, SUM(sales_amount) AS sales_amount
FROM order_data
GROUP BY order_date
) daily_sales
ORDER BY order_date;
5.1.3 方差与标准差:衡量数据离散程度
样本方差与总体方差
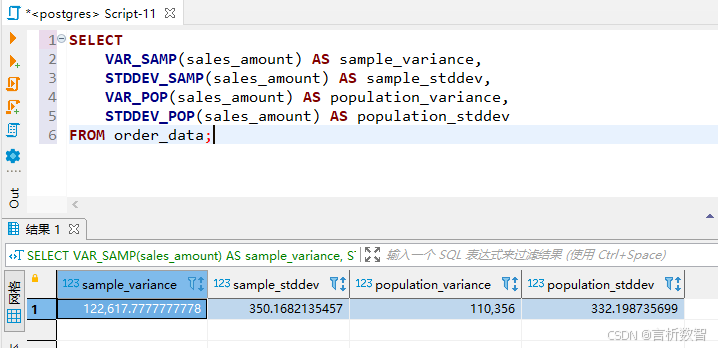
PostgreSQL提供两种方差函数:
-
VAR_SAMP():样本方差(分母为n-1) -
VAR_POP():总体方差(分母为n) -
示例:计算销售额的离散程度
SELECT
VAR_SAMP(sales_amount) AS sample_variance,
STDDEV_SAMP(sales_amount) AS sample_stddev,
VAR_POP(sales_amount) AS population_variance,
STDDEV_POP(sales_amount) AS population_stddev
FROM order_data;
分组标准差分析
对比不同类别的销售稳定性:
SELECT category,
STDDEV_SAMP(sales_amount) AS stddev_sales,
STDDEV_SAMP(sales_amount)/AVG(sales_amount) AS cv_sales -- 变异系数
FROM order_data
GROUP BY category;
| category | stddev_sales | cv_sales |
|---|---|---|
| 数码 | 185.23 | 0.480 |
| 服装 | 102.45 | 0.517 |
| 家居 | 89.32 | 0.585 |
- 业务洞察:家居类产品
变异系数最高,销售波动最大;数码产品相对稳定。
5.1.4 分位数计算:深入理解数据分布
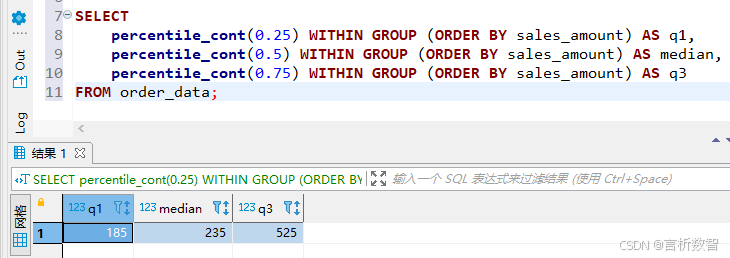
四分位数与百分位数
PostgreSQL支持两种分位数函数:
-
QUANTILE_CONT():连续分位数(线性插值) -
QUANTILE_DISC():离散分位数(取最近值) -
示例1:计算销售额的四分位数
SELECT
percentile_cont(0.25) WITHIN GROUP (ORDER BY sales_amount) AS q1,
percentile_cont(0.5) WITHIN GROUP (ORDER BY sales_amount) AS median,
percentile_cont(0.75) WITHIN GROUP (ORDER BY sales_amount) AS q3
FROM order_data;
- 示例2:计算年龄分布的百分位数
SELECT
percentile_cont(0.05) WITHIN GROUP (ORDER BY customer_age) AS p5, -- 5%分位数
percentile_cont(0.95) WITHIN GROUP (ORDER BY customer_age) AS p95 -- 95%分位数
FROM order_data;
| p5 | p95 |
|---|---|
| 18 | 55 |
分位数与异常值检测
通过四分位距(IQR)检测异常值:
WITH quantiles AS (
SELECT
percentile_cont(0.25) WITHIN GROUP (ORDER BY sales_amount) AS q1,
percentile_cont(0.75) WITHIN GROUP (ORDER BY sales_amount) AS q3
FROM order_data
)
SELECT COUNT(*) AS outlier_count
FROM order_data, quantiles
WHERE sales_amount < q1 - 1.5 * (q3 - q1)
OR sales_amount > q3 + 1.5 * (q3 - q1);
5.1.5 综合应用:客户价值分层分析
结合均值和分位数对客户进行RFM分层(此处简化为消费金额分析):
-
- 计算客户累计消费金额的分位数:
SELECT
customer_id,
SUM(sales_amount) AS total_spend,
NTILE(4) OVER (ORDER BY SUM(sales_amount) DESC) AS spend_level
-- 分为4个层级
FROM order_data
GROUP BY customer_id;
-
- 各层级客户分布:
SELECT spend_level, COUNT(*) AS customer_count
FROM (
SELECT customer_id,
NTILE(4) OVER (ORDER BY total_spend DESC) AS spend_level
FROM (
SELECT customer_id, SUM(sales_amount) AS total_spend
FROM order_data
GROUP BY customer_id
) customer_spend
) tiered_customers
GROUP BY spend_level
ORDER BY spend_level;
| spend_level | customer_count | remark |
|---|---|---|
| 1 | 5000 | – 顶级客户(前25%) |
| 2 | 15000 | – 高端客户 |
| 3 | 30000 | – 中端客户 |
| 4 | 50000 | – 普通客户(后25%) |
5.1.6 性能优化建议
-
- 索引优化:对分析字段建立索引(如
sales_amount、customer_age)
- 索引优化:对分析字段建立索引(如
CREATE INDEX idx_sales_amount ON order_data(sales_amount);
-
- 预聚合表:针对高频分析场景创建汇总表
CREATE TABLE daily_sales_summary AS
SELECT order_date,
category,
AVG(sales_amount) AS avg_sales,
STDDEV_SAMP(sales_amount) AS stddev_sales
FROM order_data
GROUP BY order_date, category;
-
- 并行计算:启用PostgreSQL并行查询(需配置
max_parallel_workers_per_gather)
- 并行计算:启用PostgreSQL并行查询(需配置
SET max_parallel_workers_per_gather = 4;
5.1.7 最佳实践总结
-
- 函数选择:
- 连续数据分位数使用
QUANTILE_CONT,离散数据使用QUANTILE_DISC - 样本统计用
VAR_SAMP/STDDEV_SAMP,总体统计用VAR_POP/STDDEV_POP
-
- 业务结合:
- 均值需结合分位数分析,避免极端值影响
- 标准差需结合均值计算变异系数,实现不同量级数据的对比
-
- 可视化建议:
- 均值/分位数:柱状图、箱线图
- 离散程度:标准差椭圆、变异系数热力图
- 通过PostgreSQL的强大统计函数,我们能够在数据库层直接完成复杂的描述性统计分析,避免数据迁移带来的性能损耗。
- 下一章节将进一步探讨相关性分析与回归建模,构建完整的数据分析体系。
- 以上内容详细介绍了PostgreSQL中描述性统计分析的核心技术。
- 你可以告诉我是否需要补充特定场景的案例,或对某些统计方法进行更深入的解析。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











