场景
- 没有爬数据的能力,更谈不上做好数据分析!
- 网上虽有很多文档参考,但一直感觉:纸上得来终觉浅!
- 啊哈, 有点儿假文艺了。其实最大的痛就是,毕竟网上的都是别(zi)人(ji)家(tai)的(cai)文档;通过总结,一方面希望积累知识,另一方面希望有所帮助。
描述
代码
import re
import urllib
import bs4
import pandas as pd
from bs4 import BeautifulSoup
page = 1 # 第 1 页
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3236.0 Safari/537.36'}
request = urllib.request.Request(url,headers=header)
response = urllib.request.urlopen(request).read()
content=BeautifulSoup(response, 'lxml')
'''
1 获取段子内容
'''
divs = content.find_all('div', class_='content')
content_lis=[]
for div in divs:
content_lis.append(div.span.get_text())
'''
2 获取用户昵称
'''
tmp=content.find_all('div', class_='col1')[0]
nick_name_lis=[]
for nick_name in tmp.find_all('h2'):
nick_name_lis.append(nick_name.get_text())
'''
3 获取好笑、评论数量
'''
counter=0
funny_lis=[]
comment_lis=[]
for cofu in content.find_all('i', class_='number'):
counter+=1
if counter%2!=0:
funny_lis.append(cofu.get_text())
else :
comment_lis.append(cofu.get_text())
'''
4 打印当前页
'''
current_page=content.find_all('ul',class_='pagination')[0].find_all('span',class_='current')[0].get_text()
print ('\033[1;31m[24H] current page:\033[0m \033[0;30;43m%s\033[0m' % (current_page.replace('\n','')))
'''
5 转换为 DF并显示
'''
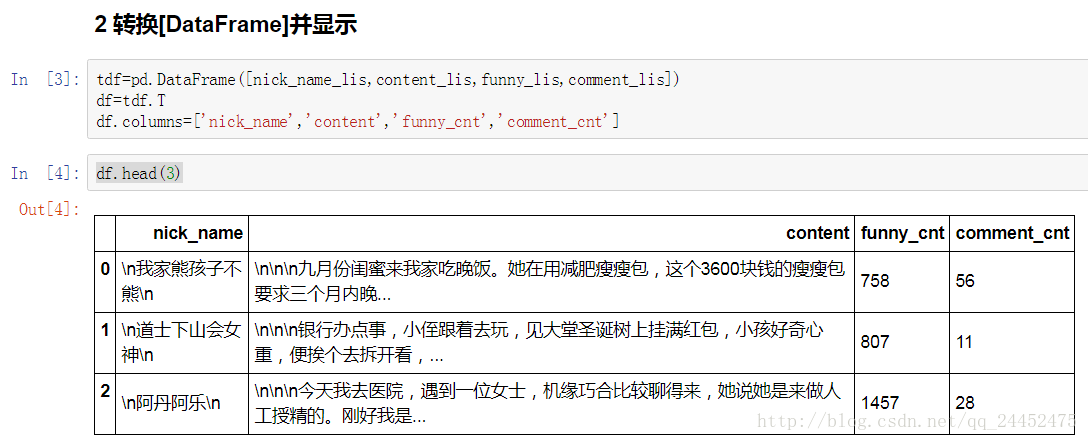
tdf=pd.DataFrame([nick_name_lis,content_lis,funny_lis,comment_lis])
df=tdf.T
df.columns=['nick_name','content','funny_cnt','comment_cnt']
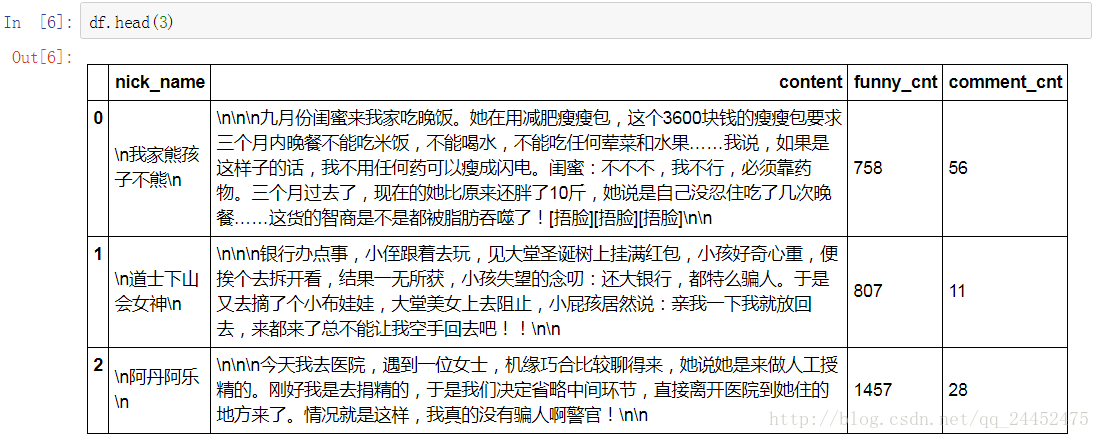
df.head(3)
pd.set_option('display.width',200)
pd.set_option('display.max_columns',20)
pd.set_option('display.max_rows',50)
pd.set_option('display.max_colwidth',200)
工具
- Anaconda 3.Jupyter NoteBook
- Python 3
参考

























 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











