






--------------2018/12/11 update-------------------
爬取的网站已经关闭,此爬虫已经失效,代码也不会再维护,不建议学习此代码等设计风格。写的实在挺烂(摔!
感兴趣的同学浏览下就好。
-----2017-5-22再更新-----------------
现在爬虫好像出问题了。。。。。。。。。好像很多同学都对这个感兴趣,那我就放到GitHub上维护吧:https://github.com/qq1367212627/youmziSpider 感兴趣的可以去这个地址看
---------2016-----------------
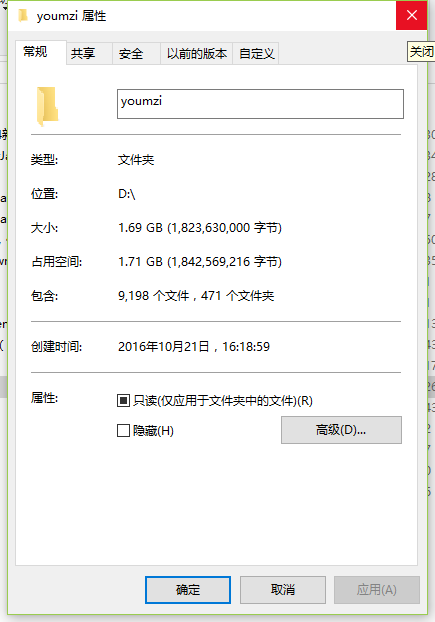
花了一天左右的时间,用Java写了一个图片爬取,理论上是可以将所有的图片爬下的,但是整个站点图片太多了,所以只测试的爬了9000张左右的图片。好啦先看效果图。
接下来是代码,这个简单的小爬虫是基于httpclient,所以大家使用代码,还要记得下载依赖库才可以运行(依赖库下载地址:Apache HttpComponents),网页解析使用正则解析的,还是比较简单的小爬虫。
以下,代码(代码风格很混乱,请谅解):
主程序入口:Main
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Set;
public class Main {
public static Set<String> set =null;
public static void main(String[] args) {
DownLoad.CreateDir("D:\\youmzi"); //图片保存路径
set = new HashSet<>();
ArrayList<String> Page_Link = new ArrayList<>();
ArrayList<PictMsg> Pict_Link =new ArrayList<>();
Page_Link.add("http://www.youmzi.com/xg/");
Page_Link.add("http://www.youmzi.com/mingxing.html");
Page_Link.add("http://www.youmzi.com/meinvgif.html");// gif图
Page_Link.add("http://www.youmzi.com/meinv.html");
Page_Link.add("http://www.youmzi.com/baoru.html");
Page_Link.add("http://www.youmzi.com/luguan.html");
Page_Link.add("http://www.youmzi.com/tuinvlang.html");
Page_Link.add("http://www.youmzi.com/liufeier.html");
Page_Link.add("http://so.youmzi.com/");
while(Page_Link.size()>0){
String url=Page_Link.get(0);
Find_Link.Add_Page_Link(url,Page_Link);
Find_Link.Add_Pict_Link(url,Pict_Link);
DownLoad.downloadPict(Pict_Link);
Page_Link.remove(0);
}
}
}
import java.util.ArrayList;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
/**
* Created by lewis on 2016/10/20.
*/
public class Find_Link {
public static boolean Add_Page_Link(String Context, ArrayList<String> Page_link) {
String link=null;
String fa="<a href=(['\"]?)(?!http)((?!js|css)[^\"' \\r\\n])+\\1>下一页";
Pattern r= Pattern.compile(fa);
Matcher m = r.matcher(DownLoad.downloadHtml(Context));
if (m.find(0)) {
link = m.group();
String pa = "<a href='(.+?)'>下一页";
r = Pattern.compile(pa);
m = r.matcher(link);
if (m.find(0)) {
link = m.group(1);
if (!link.equals("#") && link != null&&!Main.set.contains(link)) {
Main.set.add(link);
Page_link.add("http://www.youmzi.com/" + link); //获得捕获组1,一共2个组,被匹配的字符算一个组
}
}
}
return m.find(0)&&(!link.equals("#"))&&link!=null;
}
public static void Add_Pict_Link(String Context,ArrayList<PictMsg> Pict_link) {
String pa;
Pattern r;
Matcher m ;
pa="<a href=\"(.+?)\" title=\"(.+?)\" target=\"_blank\">(.+?)<\\/a>";
r= Pattern.compile(pa);
m = r.matcher(DownLoad.downloadHtml(Context));
while(m.find()) {
String url=m.group(1);
String head=m.group(2);
if(!Main.set.contains(url)){
Pict_link.add(new PictMsg(url,head));
Main.set.add(url);
}
}
}
}
/**
* Created by lewis on 2016/10/21.
*/
public class PictMsg {
private String url;
private String headline;
public PictMsg(String url, String headline) {
this.url = url;
this.headline = headline;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getHeadline() {
return headline;
}
public void setHeadline(String headline) {
this.headline = headline;
}
@Override
public String toString() {
return "网址:"+url+"标题:"+headline;
}
}
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.*;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by lewis on 2016/10/20.
*/
public class DownLoad {
public static CloseableHttpClient httpClient = HttpClients.custom().build();
public static String downloadHtml(String url) {
CloseableHttpResponse response = null;
BufferedReader br=null;
HttpGet httpGet = new HttpGet(url);
try {
response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
InputStreamReader isr = new InputStreamReader(entity.getContent(),"gb2312");
StringBuilder stringBuilder =new StringBuilder();
br =new BufferedReader(isr);
String line =null;
while((line=br.readLine())!=null){
stringBuilder.append(line+'\n');
}
return stringBuilder.toString();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(br!=null){
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
public static void downloadPict(PictMsg pictMsg,int count) {
String url=pictMsg.getUrl();
CloseableHttpResponse response;
OutputStream out = null;
InputStream in=null;
BufferedReader br=null;
byte buffer[] = new byte[1024];
if(url!=null){
try {
HttpGet httpGet = new HttpGet(url);
response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
in = entity.getContent();
CreateDir("D:\\youmzi"+File.separator+pictMsg.getHeadline());
String suffix;
if(url.charAt(url.length()-1)=='g') {
suffix=".jpg";
}
else{
suffix=".gif";
}
System.out.print("正在下载:"+"D:\\youmzi"+File.separator+pictMsg.getHeadline()+File.separator+count+suffix+":");
out = new FileOutputStream(new File("D:\\youmzi"+File.separator+pictMsg.getHeadline()+File.separator+count+suffix));
int index=0;
while((index=in.read(buffer))!=-1){
out.write(buffer,0,index);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if (br!=null){
br.close();
}
if(out!=null){
out.close();
}
if(in!=null){
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void downloadPict(ArrayList<PictMsg> Pict_link){
for(int i = 0;i< Pict_link.size();i++){
// Main.print(Pict_link.get(i));
if(Pict_link.get(i)!=null)
DownLoad_All_PictSoruce(Pict_link.get(i));
}
Pict_link.clear();
}
public static void CreateDir(String dir){
File file = new File(dir);
if(!file.exists()){
file.mkdir();
}
}
public static void DownLoad_All_PictSoruce(PictMsg pictMsg){
ArrayList<String> All_Pict_Soruce = new ArrayList<>();
String url =pictMsg.getUrl();
All_Pict_Soruce.add(url);
while(Find_Link.Add_Page_Link(url,All_Pict_Soruce)){ //通过循环一直找到最后一个页面
url=All_Pict_Soruce.get(All_Pict_Soruce.size()-1);
}
for(int i =0;i<All_Pict_Soruce.size();i++){
//Main.print(Pict_down_Soruce(All_Pict_Soruce.get(i)));
if(All_Pict_Soruce.get(i)!=null){
String link=Pict_down_Soruce(All_Pict_Soruce.get(i));
if(!Main.set.contains(link)) {
downloadPict(new PictMsg(link, pictMsg.getHeadline()), i);
System.out.println("一共有:"+All_Pict_Soruce.size()+","+"还剩下:"+(All_Pict_Soruce.size()-i));
Main.set.add(link);
}
}
}
All_Pict_Soruce.clear();
}
public static String Pict_down_Soruce(String url){
String context = DownLoad.downloadHtml(url);
String pa;
Pattern r;
Matcher m ;
pa="<img src='(.+?)' alt=";
r= Pattern.compile(pa);
m = r.matcher(context);
if(m.find(0)){
return m.group(1);
}
return null;
}
}















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









