







一、前言
本文主要是针对 Flink SQL 使用 Flink CDC 无法实现多库多表的多源合并问题,以及多源合并后如何对下游 Kafka 同步更新的问题,因为目前 Flink SQL 也只能进行单表 Flink CDC 的作业操作,这会导致数据库 CDC 的连接数过多。
但是 Flink CDC 的 DataStream API 是可以进行多库多表的同步操作的,本文希望利用 Flink CDC 的 DataStream API 进行多源合并后导入一个总线 Kafka,下游只需连接总线 kafka 就可以实现 Flink SQL 的多源合并问题,资源复用。
二、环境
版本
组件
版本
Flink
1.13.3
Flink CDC
2.0
Kafka
2.13
Java
1.8
CDC预览
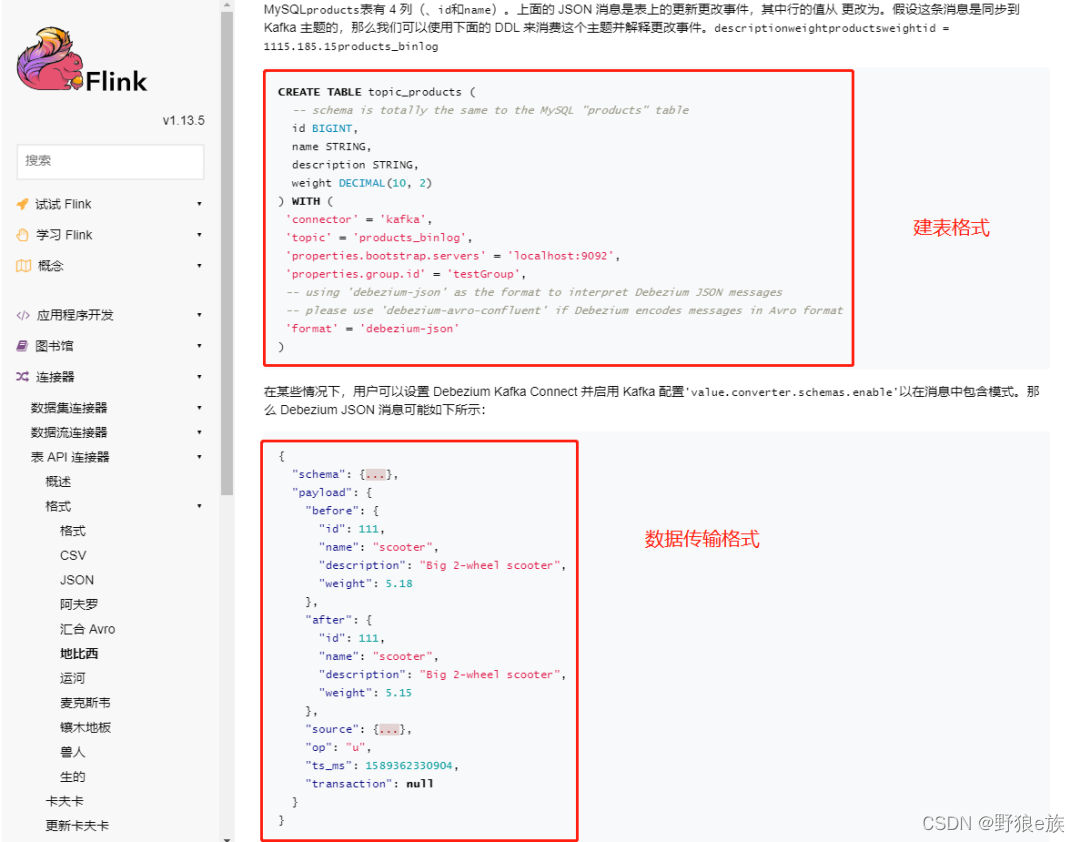
我们先打印一下 Flink CDC 默认的序列化 JSON 格式如下:
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1643273051, file=mysql_bin.000002, pos=5348135, row=1, server_id=1, event=2}}
ConnectRecord{topic='mysql_binlog_source.gmall.spu_info', kafkaPartition=null, key=Struct{id=12}, keySchema=Schema{mysql_binlog_source.gmall.spu_info.Key:STRUCT}, value=Struct{before=Struct{id=12,spu_name=华为智慧屏 14222K1 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},after=Struct{id=12,spu_name=华为智慧屏 2K 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},source=Struct{version=1.4.1.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1643273051000,db=gmall,table=spu_info,server_id=1,file=mysql_bin.000002,pos=5348268,row=0,thread=3742},op=u,ts_ms=1643272979401}, valueSchema=Schema{mysql_binlog_source.gmall.spu_info.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
可以看到,这种格式的 JSON,传给下游有很大的问题,要实现多源合并和同步更新,我们要解决以下两个问题。
①总线 Kafka 传来的 json ,无法识别源库和源表来进行具体的表创建操作,因为不是固定的 json 格式,建表 with 配置里也无法指定具体的库和表。
②总线 Kafka 传来的 json 如何进行 CRUD 等事件对 Kafka 流的同步操作,特别是 Delete,下游kafka如何感知来更新 ChangeLog。
三、查看文档
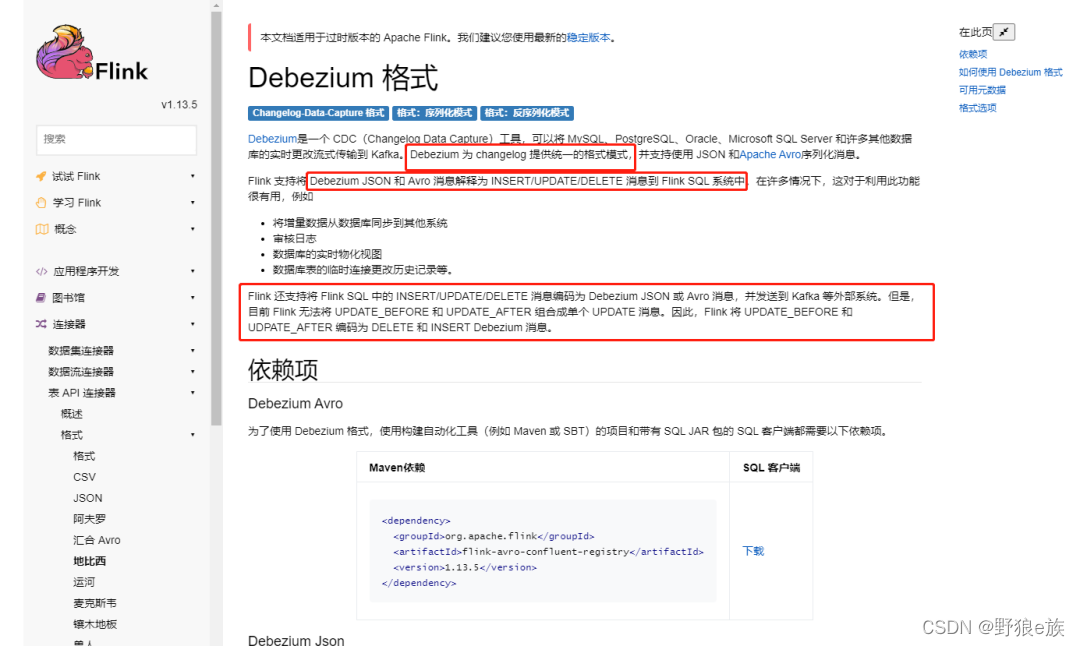
我们可以看到红框部分,基于 Debezium 格式的 json 可以在 Kafka connector 建表中可以实现表的 CRUD 同步操作。只要总线 Kafka 的 json 格式符合该模式就可以对下游 kafka 进行 CRUD 的同步更新,刚好 Flink CDC 也是基于Debezium。
那这里就已经解决了问题②。
剩下问题①,如何解决传来的多库多表进行指定表和库的识别,毕竟建表语句没有进行 where 的设置参数。
再往下翻文档:
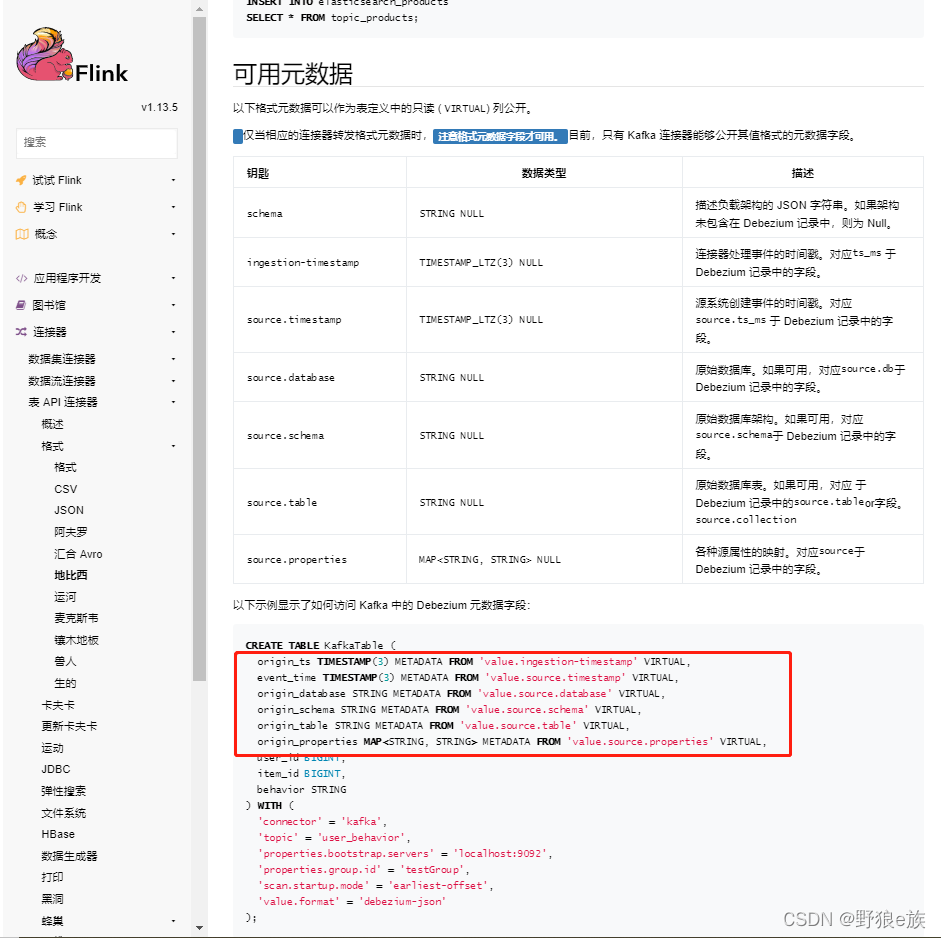
可以看到,基于 Debezium-json 格式,可以把上面的 schema 定义的 json 格式的元数据给取出来放在字段里。
比如,我把 table 和 database 给放在建表语句里,那样我就可以在 select 语句中进行库和表的过滤了。
如下:
CREATE TABLE Kafka_Table (
origin_database STRING METADATA FROM 'value.source.database' VIRTUAL, //schema 定义的 json 里的元数据字段
origin_table STRING METADATA FROM 'value.source.table' VIRTUAL,
`id` INT,
`spu_name` STRING,
`description` STRING,
`category3_id` INT,
`tm_id` INT
) WITH (
'connector' = 'kafka',
'topic' = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7930
7930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











