




背景
响应式编程在一些java生态的框架中应用很多,如Spring Cloud Gateway、Spring AI等中,Spring Cloud Gateway依靠响应式编程框架WebFlux基于Netty实现了一个非阻塞的网关,解决传统网关请求量大时候的线程耗尽问题,另外对于日常AIGC生产一般的大模型流式数据返回也是使用到了响应式编程,这样可以第一时间拿到响应内容,提升用户体验。
响应式编程
- Observer、Observable
- 发布者Flux、Mono
- 调度器Schedulers
Spring Cloud Gateway原理
- 自动配置相关组件
- 工作流程
- 定制优化动态路由配置、过滤器热加载的设计思路
响应式编程
响应式编程是一种面向数据流和变化传播的编程范式。
为了应对高并发服务器端开发场景,在2009 年,微软提出了一个更优雅地实现异步编程的方式——Reactive Programming,我们称之为响应式编程。随后,Netflix 和LightBend 公司提供了RxJava 和Akka Stream 等技术,使得Java 平台也有了能够实现响应式编程的框架。
在2017 年9 月28 日,Spring 5 正式发布。Spring 5 发布最大的意义在于,它将响应式编程技术的普及向前推进了一大步。而同时,作为在背后支持Spring 5 响应式编程的框架Spring Reactor,也进入了里程碑式的3.1.0 版本。
Observer、Observable
在Java8的版本,可以使用Observer、Observable实现响应式编程。
Java9 已弃用 此类和 Observer 接口已弃用。Observer 和 Observable 支持的事件模型非常有限,Observable 传递的通知顺序未指定,并且状态更改与通知不是一一对应的。对于更丰富的事件模型,请考虑使用 java.beans 包。要在线程之间实现可靠和有序的消息传递,请考虑使用 java.util.concurrent 包中的并发数据结构之一。有关反应式流样式编程,请参阅 java.util.concurrent.Flow API。
发布者Flux、Mono
发布者Publisher:Publisher是一个可以提供0-N个序列元素的提供者,并根据其订阅者Subscriber<? super T>的需求推送元素。一个Publisher可以支持多个订阅者,并可以根据订阅者的逻辑进行推送序列元素。
订阅者Subscriber:Publisher提供了subscribe方法,允许消费者在有结果可用时进行消费。如果没有消费者Publisher不会做任何事情,不会耗费资源去计算、传输数据,他根据消费情况进行响应,通俗理解把整个事件比作做菜,传统的数据处理如直接向List放元素在处理可以理解为不管有无处理,菜已经做好了,而响应的发布订阅模式只是提前准备好原始原料,等到消费者订阅的时候才开始做菜。
Publisher可能返回零或者多个,甚至可能是无限的,为了更加清晰表示期待的结果就引入了两个实现模型Mono和Flux,使用他们可以发布元素值、完成信号、错误信号,错误信号是终止数据流,然后把错误信息传递给Subscriber,错误信号和完成信号都是终止信号,不能共存。
- Flux:传输0个或者多个事件,常用方法just表示创建的Flux序列在发布这些元素之后自动结束,generate、create一般创建比较复杂的Flux序列,generate方法表示同步、逐一的方式生成序列,表示往序列添加元素的next方法只能被调用一次,而create支持同步、异步的消息产生,next方法可以调用多次。
- Mono:返回0个或者1个事件
调度器Schedulers
在响应式编程中,特别是使用Reactor框架时,调度器(Scheduler)用于控制代码执行的线程模型。以下是你提到的几种调度器的特点和区别:
- Schedulers.immediate():特点:在当前线程上立即执行任务。用途:适合需要在调用线程上同步执行的操作,通常用于测试或简单的同步任务。
- Schedulers.single():特点:使用单一的可复用线程。用途:适用于需要串行执行的任务,这样可以避免多线程环境中的竞争条件。
- Schedulers.elastic():特点:使用弹性的线程池,线程可以被复用。若线程闲置时间过长,则会被销毁。用途:适合I/O操作,如文件读写或网络请求,因为这些操作通常会阻塞线程。弹性线程池可以根据需要动态调整线程数量。
- Schedulers.parallel():特点:使用为并行操作优化的线程池,线程数量通常与CPU核心数一致。用途:适用于CPU密集型任务,如复杂计算或数据处理。这种调度器可以充分利用多核CPU的性能。
- Schedulers.timer():特点:支持任务调度的调度器。用途:适合需要在特定时间点或延时后执行的任务。通常用于定时任务或周期性任务。
- Schedulers.fromExecutorService():特点:从已有的
ExecutorService对象创建调度器。用途:适合需要自定义线程池配置的场景,允许使用已有的ExecutorService来控制线程的创建和管理。
这些调度器提供了多种线程管理策略,可以根据任务的特性选择合适的调度器,以优化性能和资源使用。
在响应式编程中,元素发送的顺序可能会受到使用的调度器和操作符的影响。以下是一些可能影响元素发送顺序的因素:
- Schedulers.immediate() 和 Schedulers.single():通常会按照代码的顺序发送元素,因为这些调度器在单一线程上执行。
- Schedulers.elastic() 和 Schedulers.parallel():可能会改变元素的发送顺序,因为这些调度器涉及多线程操作,尤其是在并行执行的情况下。
Spring Cloud Gateway
在Spring Cloud Gateway未发布前,Spring Cloud使用的是Zuul网关,Zuul使用的是基于Servlet的阻塞模型,每次请求需要分配专门的线程处理,所以资源开销比较大,在高并发场景需要大量的线程,线程数成为了系统的瓶颈,所以作为替代,Spring Cloud Gateway网络层使用了基于非阻塞的Netty服务,从而解决线程瓶颈提升了性能。
Spring Cloud Gateway 是基于 Spring 5 和 Spring Boot 2 搭建的,本质上是一个 Spring Boot 应用。网关作为统一的流量入口,一些请求预处理如鉴权、限流、服务保护等可以在做在网关层,这样各个微服务只需要专注自己的业务逻辑,另外网关的作用
- 请求路由
- 修改请求响应
- 权限校验
- 限流熔断
- 请求重试:可以对那些幂等性的接口网关转发到微服务失败的重试
- 响应缓存:缓存一些频繁访问不经常变动的静态资源
- 响应聚合:将不同的微服务响应聚合一块响应
- 灰度流量
- 异常响应处理
SpringMVC使用了传统的阻塞Servlet框架,Gateway使用了Spring WebFlux非阻塞Reactor框架,网络层使用的是非阻塞Netty,主要作用是处理请求进行预处理以及转发,包含的组件
- Route:路由ID + 转发URI + 多个 Predicate + 多个 Filters 组成,可以针对一个api配置多个Route,匹配的时候按照优先级
- Predicate:路由的匹配条件,一个Route可以包含多个Predicates,最终会被合并一个Predicate
- Filter:对请求、响应进行pre、post处理,分为Route Filter和全局Filter
- 全局Filter:作用域全部的Route
- Route Filter:作用域是某个Route
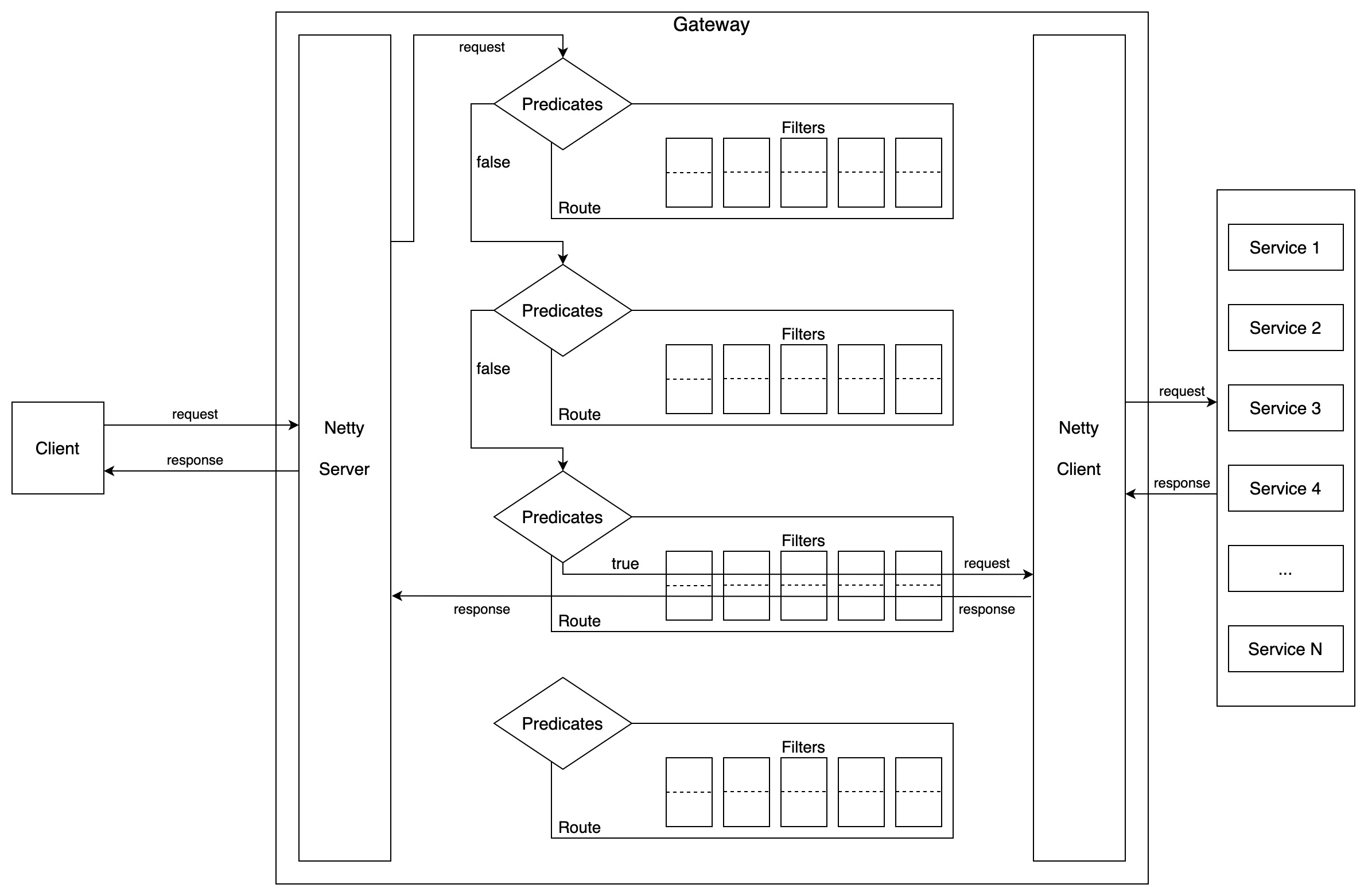
自动配置相关组件
在GatewayAutoConfiguration类中,相关注解
@Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(name = "spring.cloud.gateway.enabled", matchIfMissing = true)
@EnableConfigurationProperties
@AutoConfigureBefore({
HttpHandlerAutoConfiguration.class, WebFluxAutoConfiguration.class })
@AutoConfigureAfter({
GatewayReactiveLoadBalancerClientAutoConfiguration.class,
GatewayClassPathWarningAutoConfiguration.class })
@ConditionalOnClass(DispatcherHandler.class) // 仅在WebFlux存在的时候该配置类生效
自动配置类注册一些功能bean
- 转换器相关的bean:比如字符串和时间日期互转、键值对相关转换bean
- 路由定位器相关的bean:主要是RouteLocator的编排类CompositeRouteLocator、CompositeRouteDefinitionLocator可以设置多种加载方式编排所有的RouteLocator然后放入CachingRouteLocator组合路由定位器缓存,提高路由查找性能。
- RouteLocatorBuilder:提供一个DSL API 路由定位器构建器,用于创建和配置路由。
- RouteDefinitionLocator:通过getRoutes获取全部的路由定位器
- RouteDefinitionRouteLocator:负责从不同的数据源(如配置文件、数据库等)加载RouteDefinition,通过getRouteDefinitions获取全部的RouteDefinition
- PropertiesRouteDefinitionLocator:从配置属性中加载路由定义。
- InMemoryRouteDefinitionRepository:在内存中存储路由定义,作为默认的路由定义存储库。
- RouteDefinitionRouteLocator:负责从不同的数据源(如配置文件、数据库等)加载RouteDefinition,通过getRouteDefinitions获取全部的RouteDefinition
- 路由刷新监听相关的bean
- RouteRefreshListener:监听路由刷新事件,当路由变化时,触发响应的处理
- 处理器映射器HandlerMapping相关bean
- FilteringWebHandler:处理请求的过滤逻辑,应用全局过滤器和路由过滤器。
- RoutePredicateHandlerMapping:据路由谓词匹配请求,将请求映射到相应的Handler处理器。
- 跨域相关bean
- GlobalCorsProperties:配置全局跨域属性
- CorsGatewayFilterApplicationListener:处理跨域请求,应用跨域过滤器
- 全局过滤器相关bean:一些请求通用的过滤器,如:适配缓存的请求体、处理转发路径、处理WebSocket路由请求
- 路由谓词工厂相关的bean:一些根据请求头部、路径、方法、Cookie等信息判断请求是否匹配的类
- 相关内部配置bean
- Bucket4jConfiguration:配置Bucket4j限流相关的bean
- NettyConfiguration:配置Netty相关的bean
工作流程
当接收到一个请求,需要的处理过程
- 路由匹配 :根据请求的属性(如路径、请求头等),匹配到对应的路由规则。
- 过滤器处理 :对匹配到的路由应用一系列的过滤器,包括全局过滤器和路由特定的过滤器。
- 请求转发 :将处理后的请求转发到目标服务。
- 响应处理 :接收目标服务的响应,并应用过滤器进行处理,最后返回给客户端
调度器初始化
调度器初始化:在此过程DispatcherHadler作为调度器,在Spring启动后,会扫描响应的处理器、处理器适配器类型的bean加载到成员属性
public class DispatcherHandler implements WebHandler, PreFlightRequestHandler, ApplicationContextAware {
// 请求处理器
@Nullable
private List<HandlerMapping> handlerMappings;
// 处理器适配器
@Nullable
private List<HandlerAdapter> handlerAdapters;
// 处理器处理结果
@Nullable
private List<HandlerResultHandler> resultHandlers;
// 省略...
// 在Spring启动之后调用initStrategies
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
initStrategies(applicationContext);
}
// 扫描相关的bean放入成员属性
protected void initStrategies(ApplicationContext context) {
Map<String, HandlerMapping> mappingBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerMapping.class, true, false);
ArrayList<HandlerMapping> mappings = new ArrayList<>(mappingBeans.values());
AnnotationAwareOrderComparator.sort(mappings);
this.handlerMappings = Collections.unmodifiableList(mappings);
// 这个方法是 Return all beans of the given type or subtypes
Map<String, HandlerAdapter> adapterBeans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerAdapter.class, true, false);
this.handlerAdapters = new ArrayList<>(adapterBeans.values());
AnnotationAwareOrderComparator.sort(this.handlerAdapters);
Map<String, HandlerResultHandler> beans = BeanFactoryUtils.beansOfTypeIncludingAncestors(
context, HandlerResultHandler.class, true, false);
this.resultHandlers = new ArrayList<>(beans.values());
AnnotationAwareOrderComparator.sort(this.resultHandlers);
}
}
路由匹配
需要匹配对应的Route信息:接收到请求之后,请求相关信息被封装到了ServerWebExchange类,DispatcherHandler会调用handler方法,会找对应的所有HandlerMapping异步处理请求,调用handlerMapping.getHandler方法拿到handler处理请求
// ServerWebExchange 接口提供了一个统一的方式来处理 HTTP 请求和响应,以及与服务器端处理相关的其他属性和特性。
// 通过实现该接口,可以方便地构建自定义的 Web 应用程序。
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
if (this.handlerMappings == null) {
return createNotFoundError();
}
// 检查当前请求是否为 CORS 预检请求。如果是,则调用 handlePreFlight 方法处理预检请求,并返回处理结果
if (CorsUtils.isPreFlightRequest(exchange.getRequest())) {
return handlePreFlight(exchange);
}
return Flux.fromIterable(this.handlerMappings) // 将 handlerMappings 列表转换为一个 Flux 对象,用于异步处理每个 HandlerMapping
.concatMap(mapping -> mapping.getHandler(exchange)) // 对每个 HandlerMapping 调用 getHandler 方法,获取能够处理当前请求的处理器,并将结果合并为一个新的 Flux 对象。
.next() // 从 Flux 中获取第一个元素,如果没有元素,则返回一个空的 Mono 对象。
.switchIfEmpty(createNotFoundError())
.onErrorResume(ex -> handleResultMono(exchange, Mono.error(ex)))
// 如果成功获取到处理器webHandler(即找到了Route放在了WebServerExchange本地请求上下文并返回了FilteringWebHandler)
// 调用 handleRequestWith 方法处理请求,并返回处理结果。
.flatMap(handler -> handleRequestWith(exchange, handler));
}
// AbstractHandlerMapping#getHandler方法
@Override
public Mono<Object> getHandler(ServerWebExchange exchange)
// 调用子类的getHandlerInternal
return getHandlerInternal(exchange).map(handler -> {
if (logger.isDebugEnabled()) {
logger.debug(exchange.getLogPrefix() + "Mapped to " + handler);
}
ServerHttpRequest request = exchange.getRequest();
if 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7216
7216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











