







本篇博文的主题就是处理字体反爬,其实这种网上已经很多了,只是这次有点不一样,处理方式变化了点,记录一下。
以python3.7为基础
直接干货:
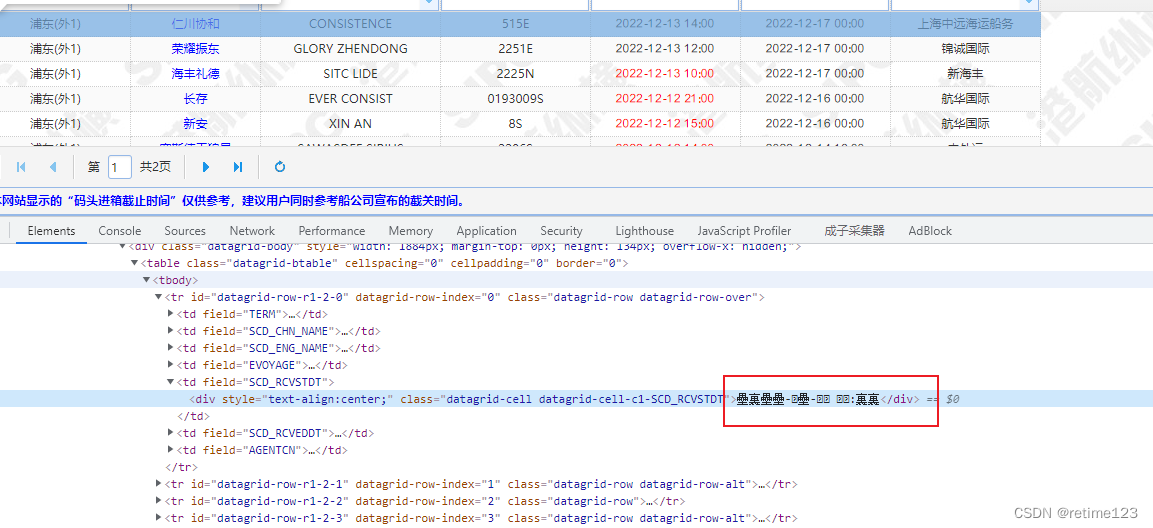
网站是json数据返回的:

这个网站有个好玩的地方,直接请求目标api,是不给数据的,要先请求生成woff名的api,才能请求目标数据,通过woff名,我们把woff文件下载下来分析,为了保证分析的准确性,我们要多下载几个woff文件,然后我们用 fontcreator 打开看下:
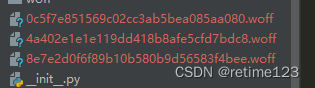
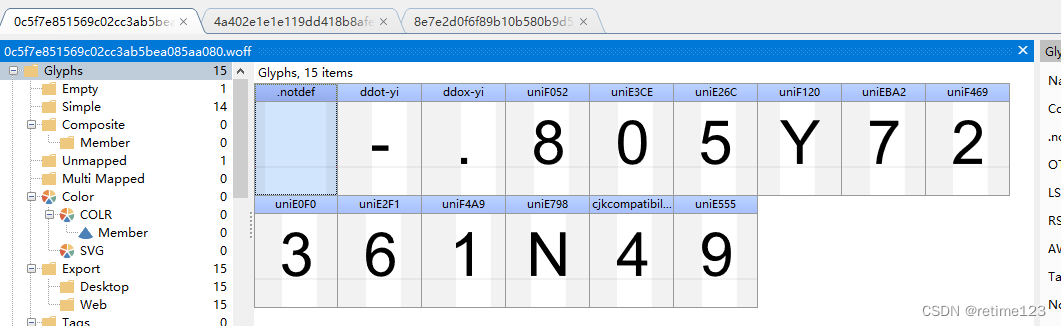
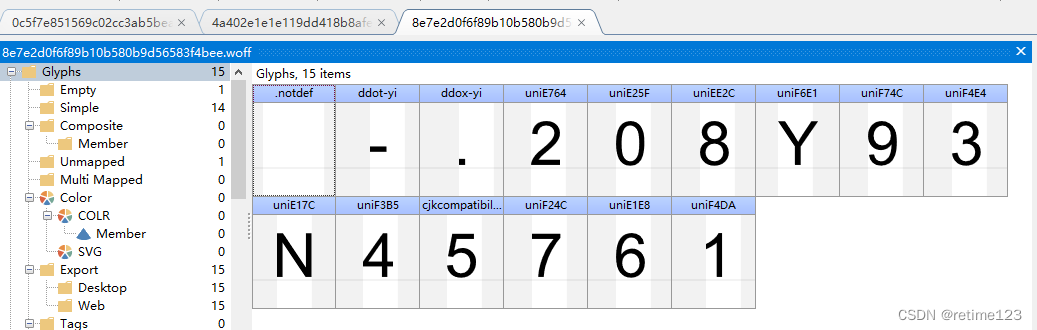
可看出3个文件,前面3个是固定的,后面是不固定的,这个就需要重点分析了!
结论:
- 每次页面加载的字体文件都不是同一个
- 某一个字体对象的命名方式不一样
- 同一个字体对应的像素坐标会有微妙的变化(观察了多个样本,每个字体像素点xy坐标的差距都不大于55)
- 同一个字体的像素点个数是一样的
下面是我的处理方法:
一、转化成图片,然后识别:
from fontTools.ttLib import TTFont
import pygame
import os,io
import ddddocr
# rFontPath = r'4a402e1e1e119dd418b8afe5cfd7bdc8.woff'
# rFontPath = '8e7e2d0f6f89b10b580b9d56583f4 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









