






JVM调优可能很多人都没遇到过,真正遇到了不知道如何去分析和解决问题,其实很多时候我们出现这个问题的原因都是最近提交的代码有问题,出现问题的时候主要靠cpu,内存等指标去参考,并且一般只有内存dump才能知道是什么问题。所以下面我总结了我如何排查真实项目线上JVM的问题,以及如何去调优,下一章我也会介绍一个大杀器Arthas。
背景:由于我们香港bo小程序服务器经常内存突然拉升,cpu又没拉满,多次手动dump导不出,有时候能dump出来,但是等待了半个小时,dump出来的内存快照只有30MB,按道理这是不科学的,我建议以下方案去排查。
Jmap使用
注意:线上如果dump的时候 加live参数和不加live参数都得dump一次,live参数会先执行一次fullgc,所以我们上面dump出来的只有30MB,侧面证明我们的内存溢出不是对象不能回收导致的,而且执行dump的时候会STW,注意对业务的影响。
jmap
jmap 可用来输出JVM内存的统计信息,支持访问本地JVM,以及远程JVM实例。使用 -dump 选项来获取堆内存转储,命令为:
jmap -dump:[live],format=b,file=<file-path> <pid>
1
在 -dump: 选项后面, 可以指定以下参数:live: 可选参数;表示只输出存活对象,也就是会先执行一次FullGC来清除可以被回收的部分。
format=b: 可选参数, 指定 dump 文件为二进制格式(binary format). 在堆内存转储时,默认就是二进制格式。
file: 指定转储文件的保存路径。
pid: 指定Java进程的pid。
节点摘除:把有问题节点摘下,让他继续oom生成内存快照,或者我们手动dump,等时间。然后新增一个新节点提供给外部使用。建议项目启动命令带上gc日志保存,这样拿到GC日志可以分析出更多信息,gc日志分析也有很多工具例如easyGC,但是现在监控工具比较发达,直接普罗米修斯+grafana已经解决大部分问题了。
| java -jar -Xloggc:./gc-%t.log gc日志文件输出路径 -XX:+PrintGCDetails 打印gc信息 -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=30 -XX:GCLogFileSize=100M -XX:+HeapDumpOnOutOfMemoryError oom自动导出内存快照 -XX:HeapDumpPath=/opt/heap.hprof xxx.jar |
|---|
1.JVM线上问题案例(jdk8,ParallelGC)
案例一:
错误线上事例,就是我们上面的bo服务,经常预警,但是cpu也不高,dump出来的也只有30M,接着就直接手动重启了:
线上JVM配置我们是没考虑过,根据心情配置的,例如我们bo的线上配置,在我们2核4g的设备上面跑,配置了3g的堆内存,看着没问题
| nohup nice java -jar -Dfile.encoding=utf-8 -Dserver.port=$RUN_PORT -Xms3000m -Xmx3000m -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+PrintGCDetails -jar ${JAR_FULLNAME} > /dev/null 2>&1 & |
|---|
现象
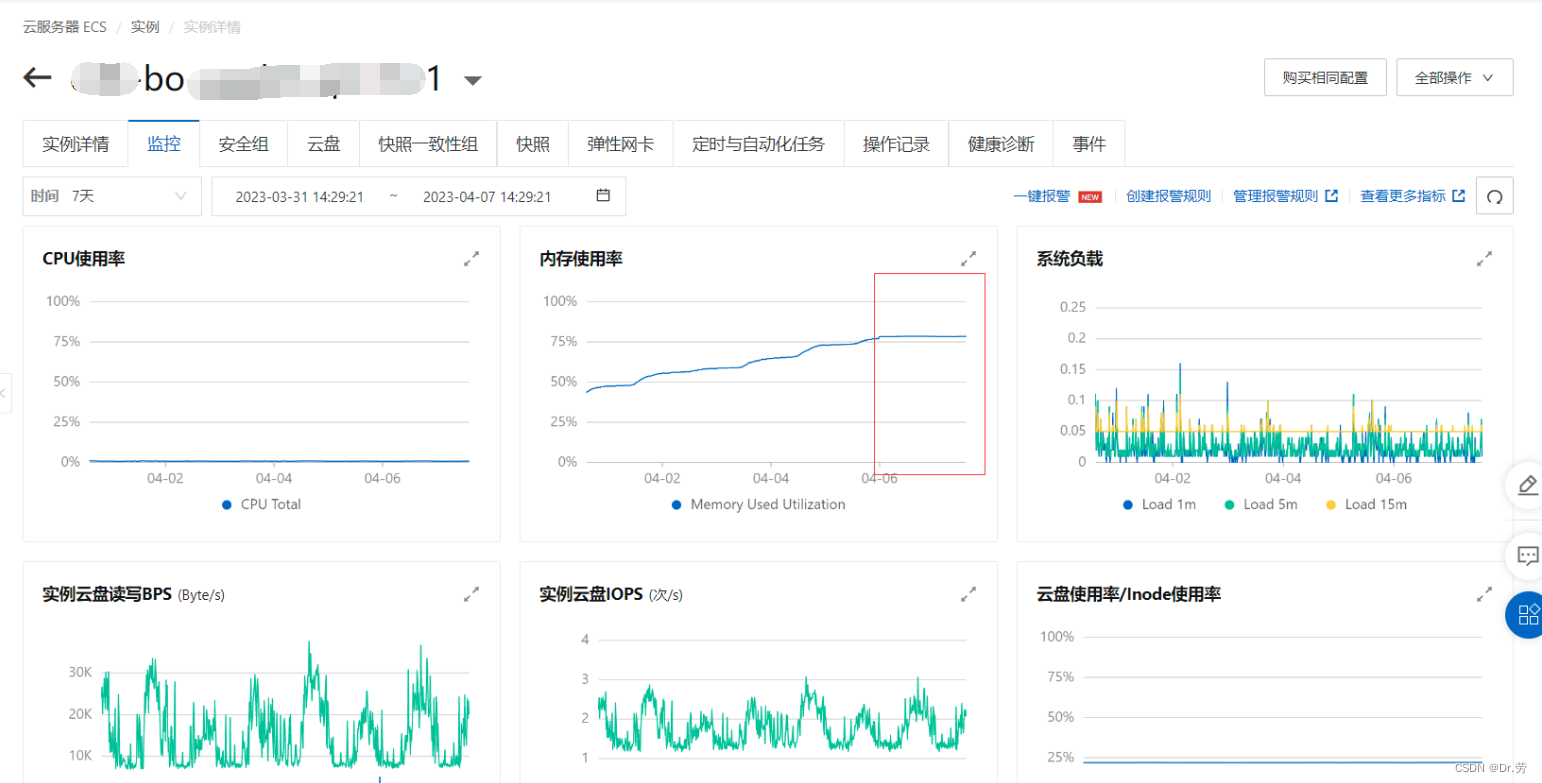
阿里云服务器发生预警了,但是我们老年代old gen,仍然没有达到full gc阈值

普罗米修斯显示堆内存占用82%,但是我们老年代还没到达GC的阈值,所以不能触发FULL GC,但是我们机器的物理内存却占用大于96%了,再下去可能宕机

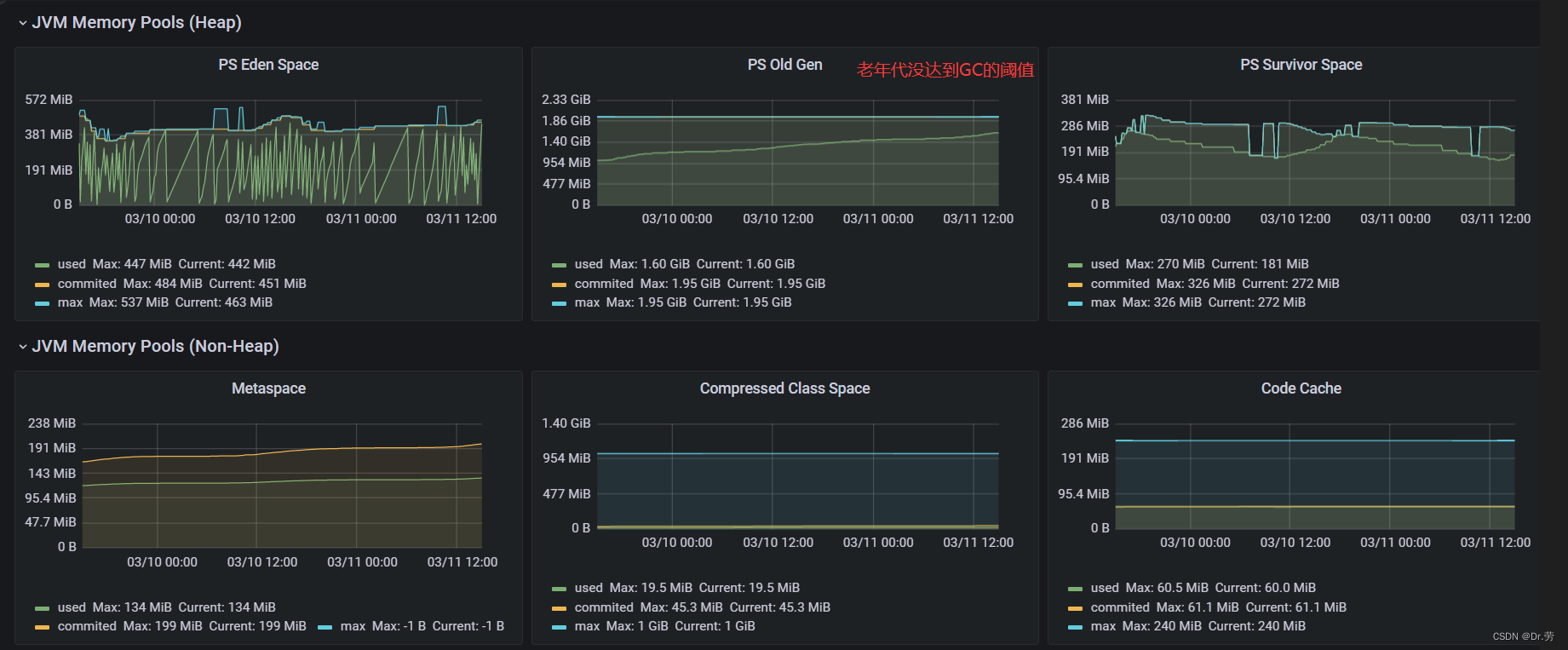
原因
4g内存的服务器只有3.6G可以用,系统自己就占了400M,我们设置3G堆内存给JVM,都还没触发到老年代垃圾回收阈值,内存就快满了,所以没有释放物理内存,阿里云就报警了,然后我们就预警,而且有个MetaspaceSize,这是使用直接内存,而不是JVM内存,这里就100M左右了.
所以就是我们JVM参数没经过考虑,就直接凭感觉去设置,这样是不行的.
dump之前会触发一次gc,所以dump出来的基本没啥东西,剩下30M.而且服务器cpu,风平浪静的,根本就不是OOM不断回收垃圾导致的现象.
底层原因(上面分析的原因其实有部分是错误的,即使触发老年代垃圾回收,仍然不会释放物理内存)
JAVA 服务内存占用太高_java内存占用高怎么解决_summer_west_fish的博客-CSDN博客
进程在申请内存时,并不是直接分配物理内存的,而是分配一块虚拟空间,到真正堆这块虚拟空间写入数据时才会通过缺页异常(Page Fault)处理机制分配物理内存,也就是我们看到的进程 Res 指标。
可以简单的认为:操作系统的内存分配是“惰性”的,分配并不会发生实际的占用,有数据写入时才会发生内存占用,影响 Res。
所以,哪怕配置了Xms6G,启动后也不会直接占用 6G 内存,只是 JVM 在启动后会malloc 6G 而已,但实际占用的内存取决于你有没有往这 6G 内存区域中写数据的。
JVM占用内存和物理内存是不一样的.例如我们认为FULL GC会释放物理内存,如果FULL GC会释放物理内存,则我们看到服务器的物理内存占用是波浪线,每次GC内存占用都会掉下去.
但是实际上并不会,JVM刚刚启动的时候我们会看到服务器内存很低,例如我设置最大堆内存-Xmx=2G的服务,在2核4G的服务器上,我们甚至可以启动4到5个这样最大堆内存-Xmx=2G的服务.
这就证明了,应用启动的时候并不会真正的去占用物理内存.
那么什么时候会真正占用物理内存呢,就是真正生成对象的时候,才会占用物理内存,我们会看到项目刚刚启动物理内存是一条上升的线,直到应用占用的堆内存达到我们-Xmx,然后物理内存就不会释放了,就会看到一条直线.
而且FULL GC的时候,是基本不会释放物理内存的,因为频繁对内存扩容缩容很耗费性能.这个时候我们能看到我们下图,物理内存占用一直很高,而且是平均的一条线.
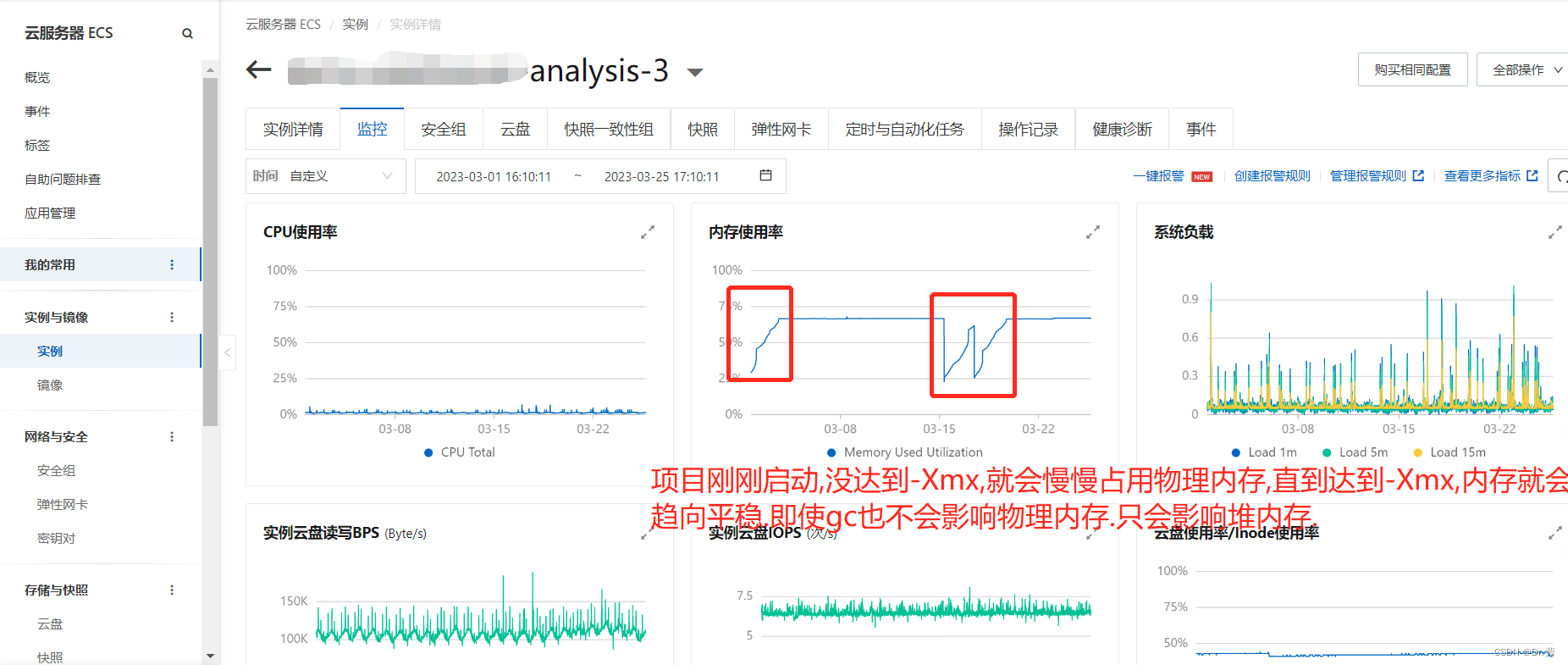

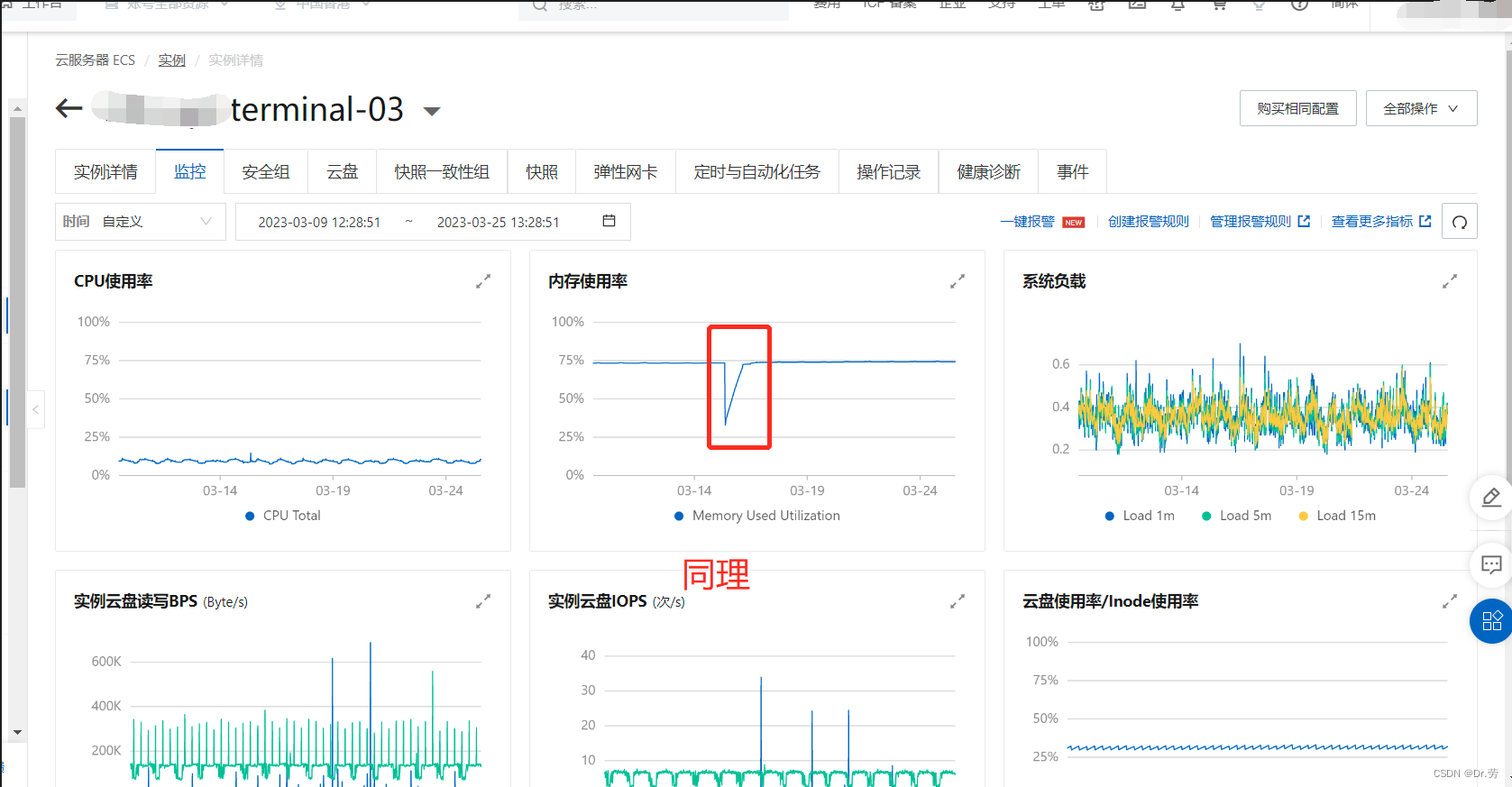
看完上面的问题,再来看一下我们bo的内存情况,一目了然,就是我们-Xmx配置得太大了,而且内存没达到-Xmx,物理每次就快被用满了,因为没到达-Xmx,所以物理内存还会继续涨.
阿里云监控和 普罗米修斯里面 每一次内存顶峰到低谷的内存释放,都是我们手动重启的或者服务上线,和上面其他服务一对比,一目了然.
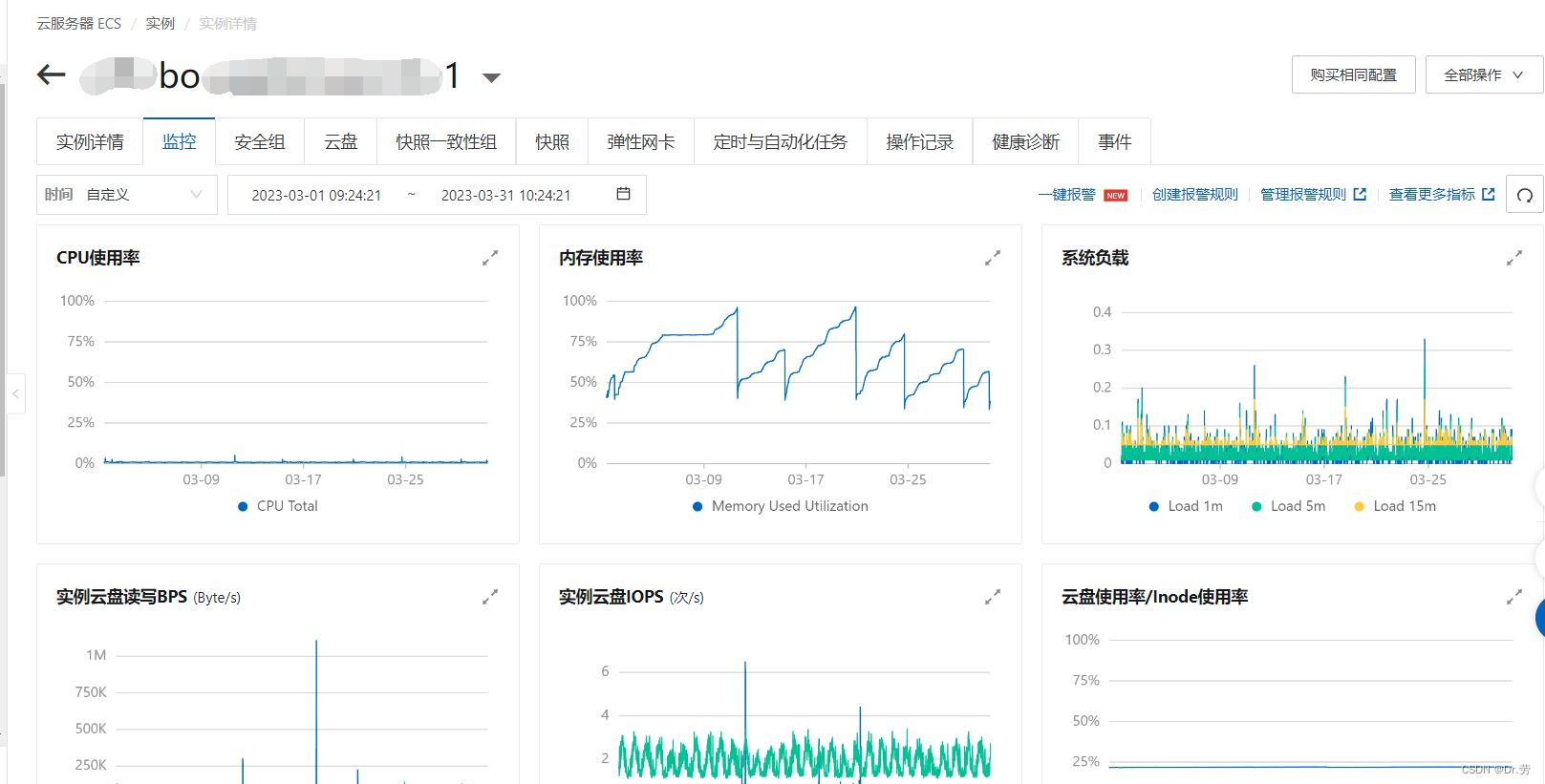
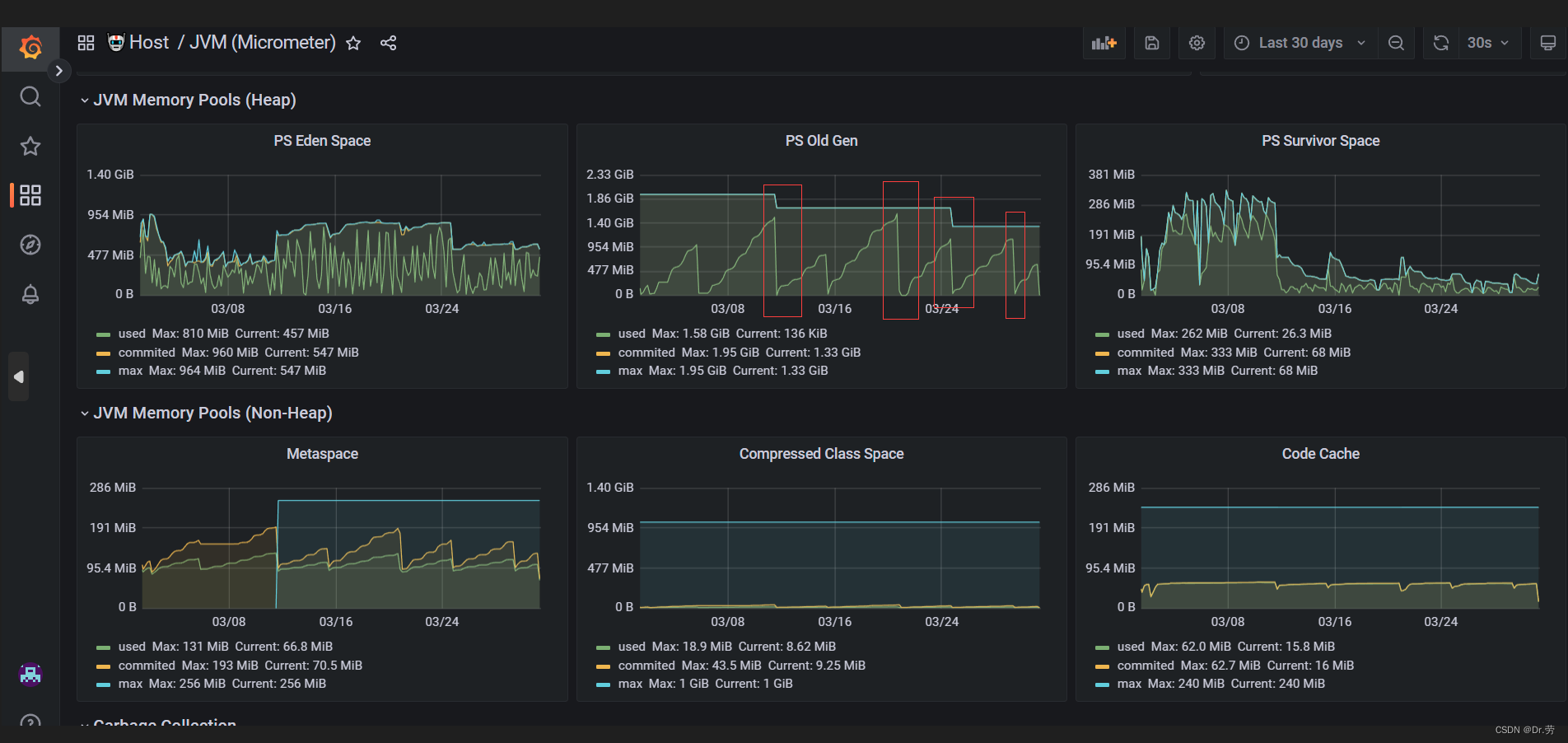
结果
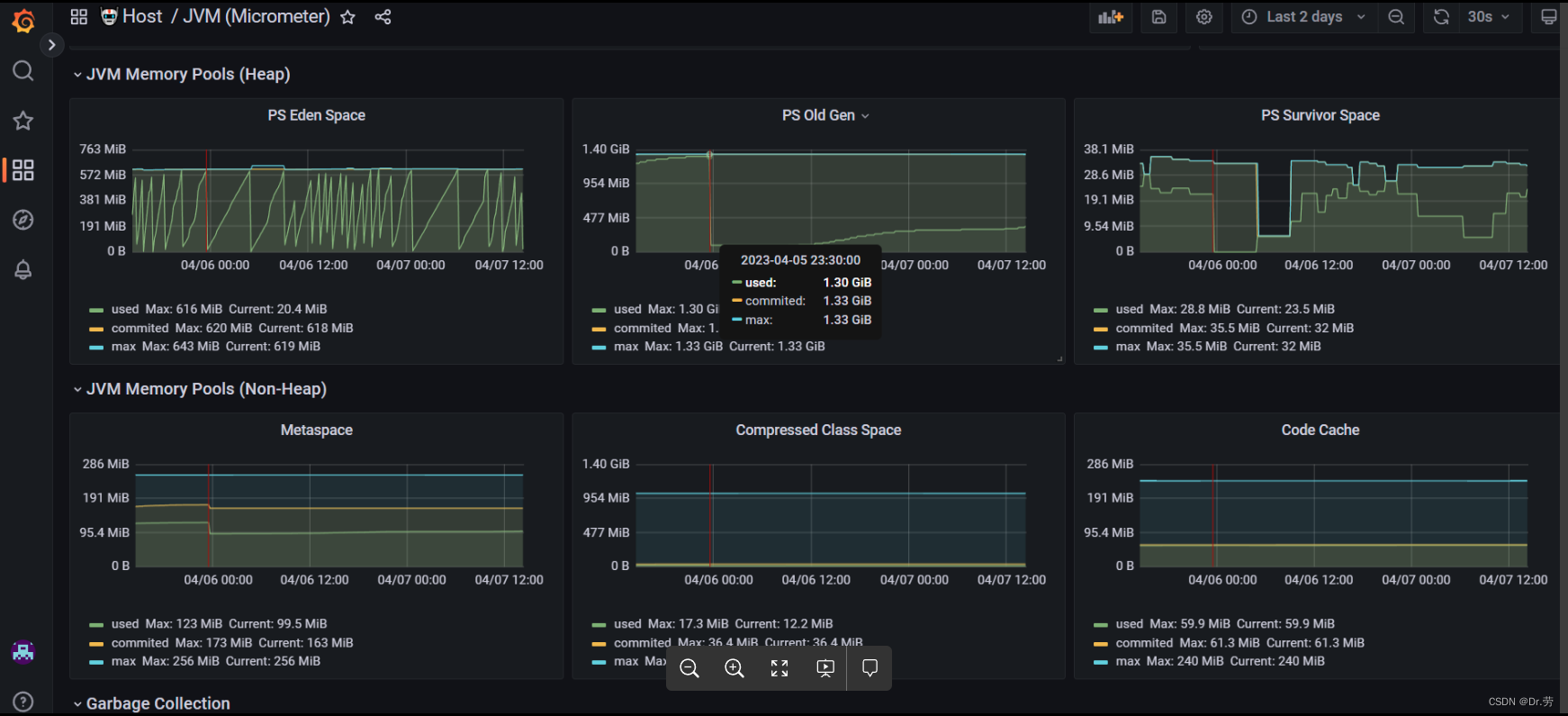
修改后的bo1的配置,我们降低了堆内存,显而易见,因为堆内存小了,gc频率高了,服务器在4月6号就达到了我们设置的-Xmx的2048M.这个时候占用服务器内存75%,变成一条直线平均了.可以看出即使Full gc也不影响物理内存.而且我们的物理内存达到75%的时候,物理内存没有继续上涨了.
| nohup nice java -jar -Dfile.encoding=utf-8 -Dserver.port=$RUN_PORT -Xmx2048M -Xms2048M -Xmn683M -Xss256k -XX:MaxMetaspaceSize=256M -XX:MetaspaceSize=256M -XX:SurvivorRatio=8 -XX:MaxDirectMemorySize=256M -XX:ParallelGCThreads=10 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/tmp/gc.log -jar ${JAR_FULLNAME} > /dev/null 2>&1 & |
|---|
修改后的情况: 经过1到2个月观察,已经正常了。old gen(老年代)正常full gc,机器物理内存也没有再暴涨到90%+
4月份指标:
5月份指标:
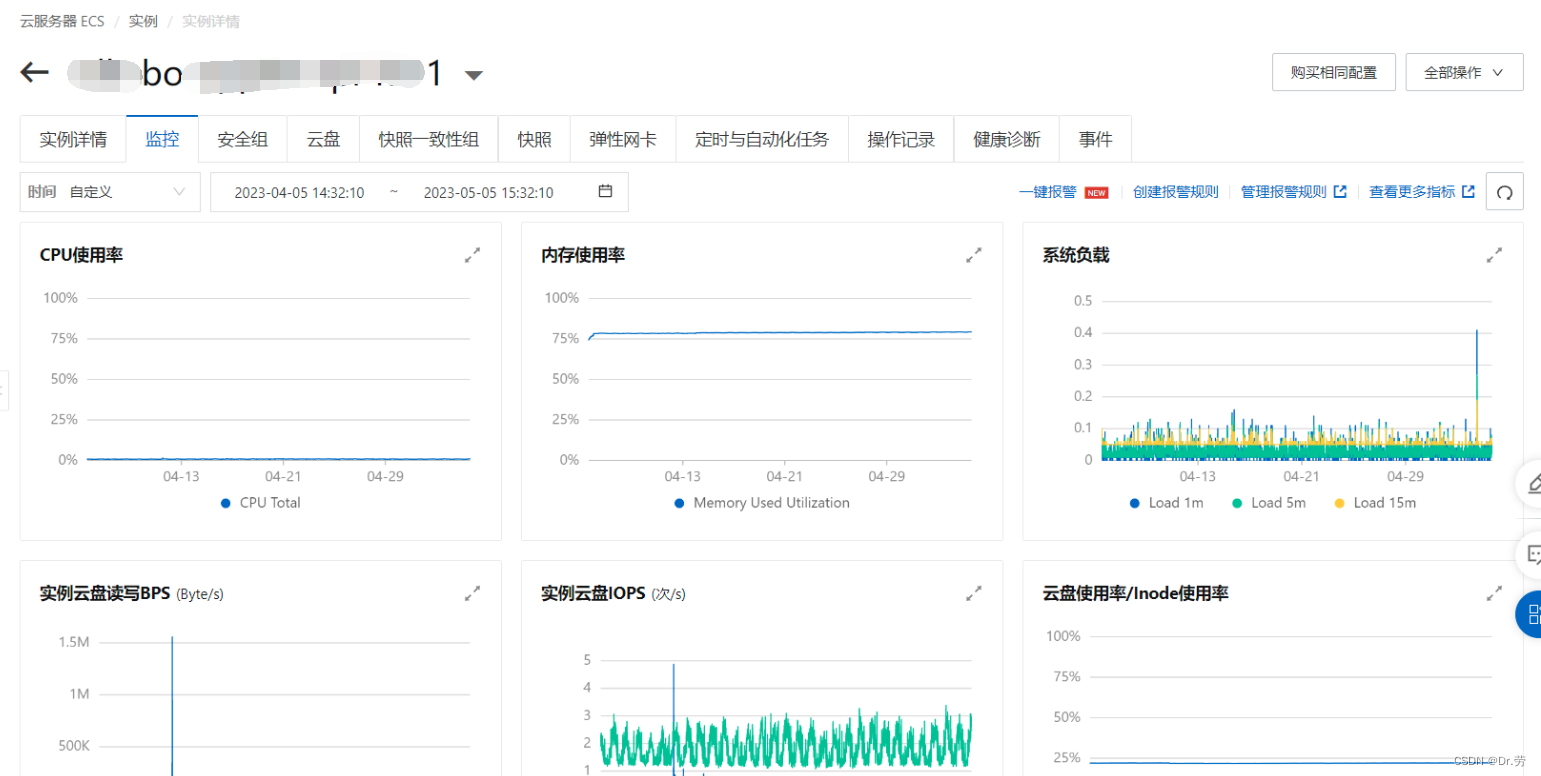

bo-2服务器修改后,经过1个月的观察也正常了
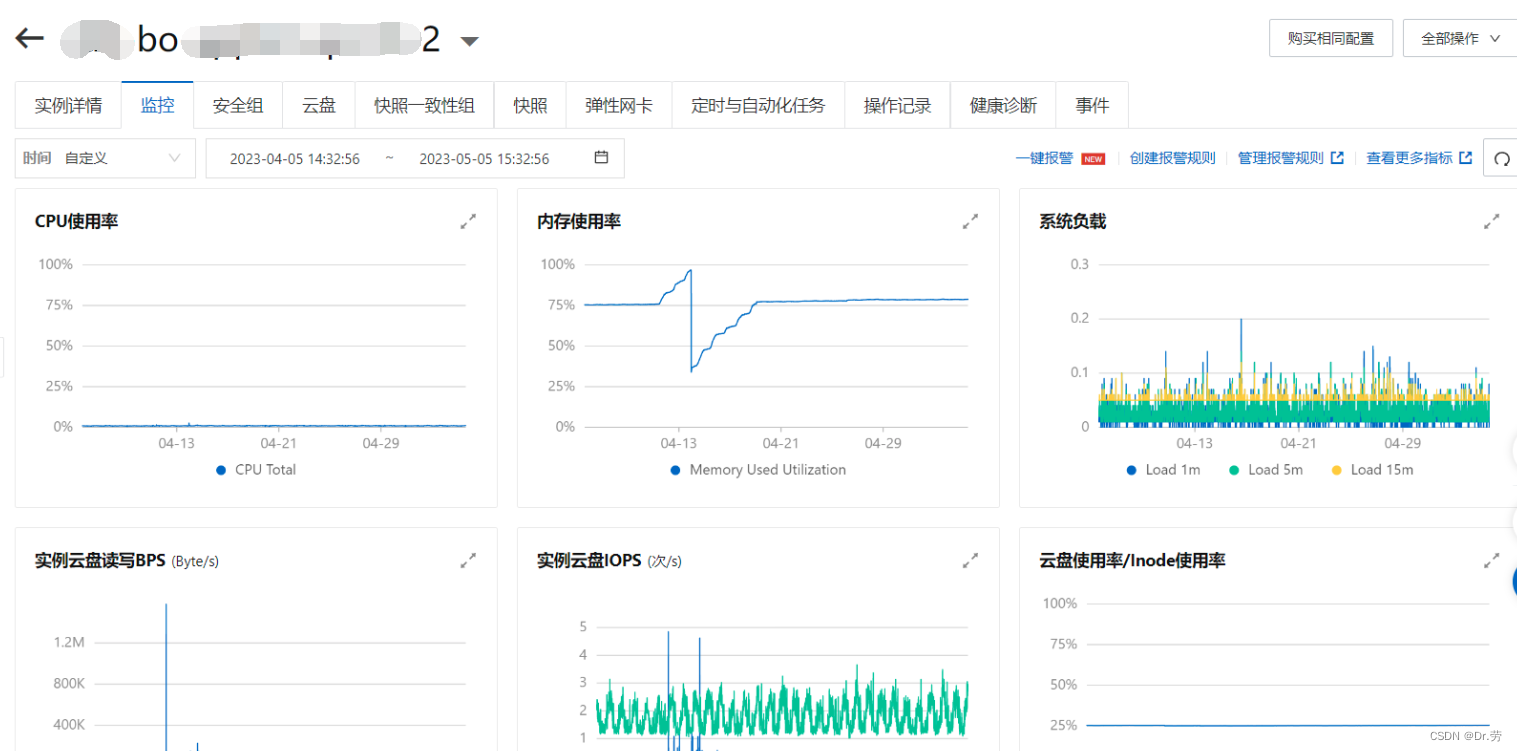
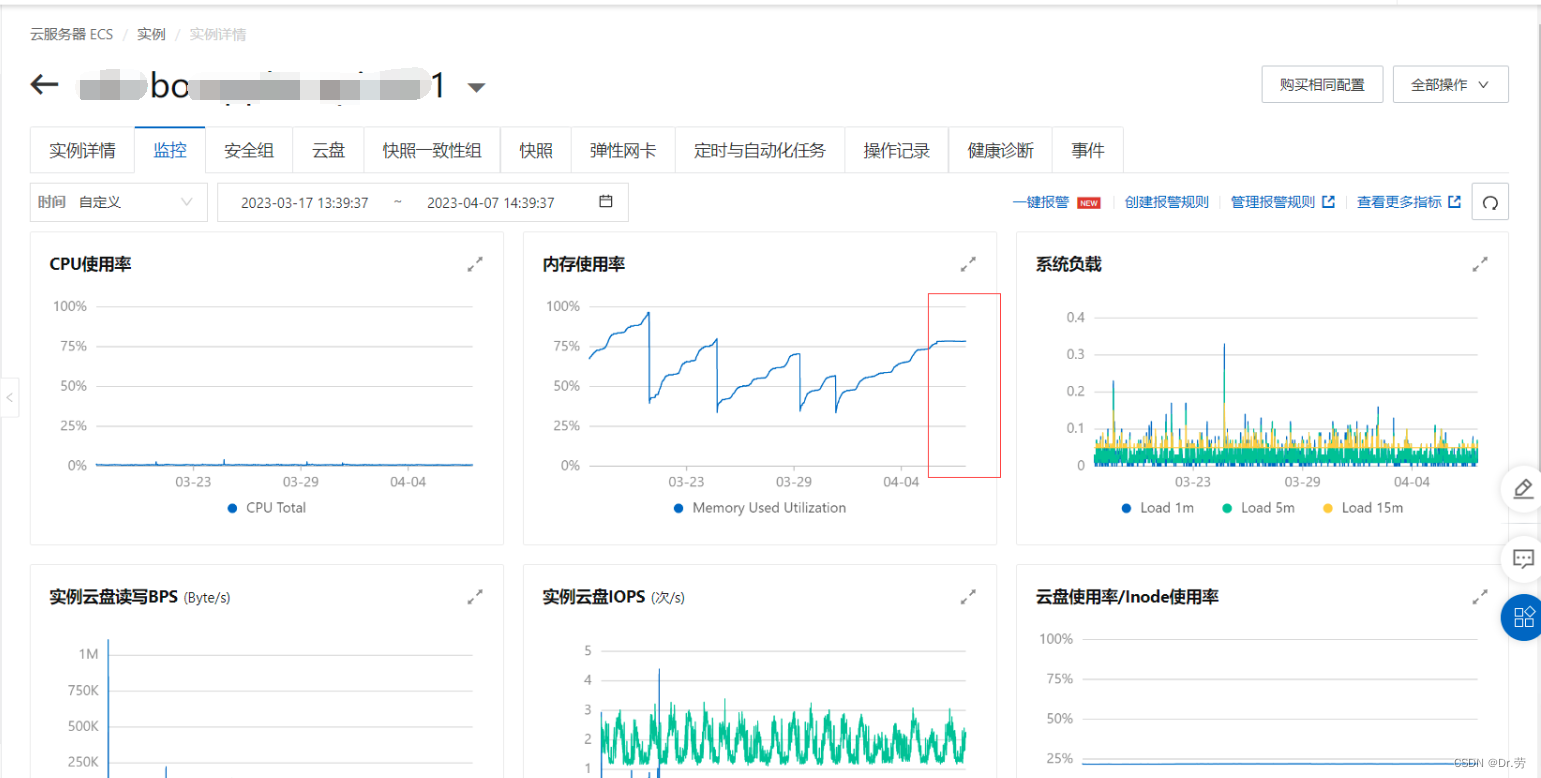
bo1修改前的情况(物理内存一直涨到95+,这里物理内存波浪线是因为我们重启了服务,或者服务上线):

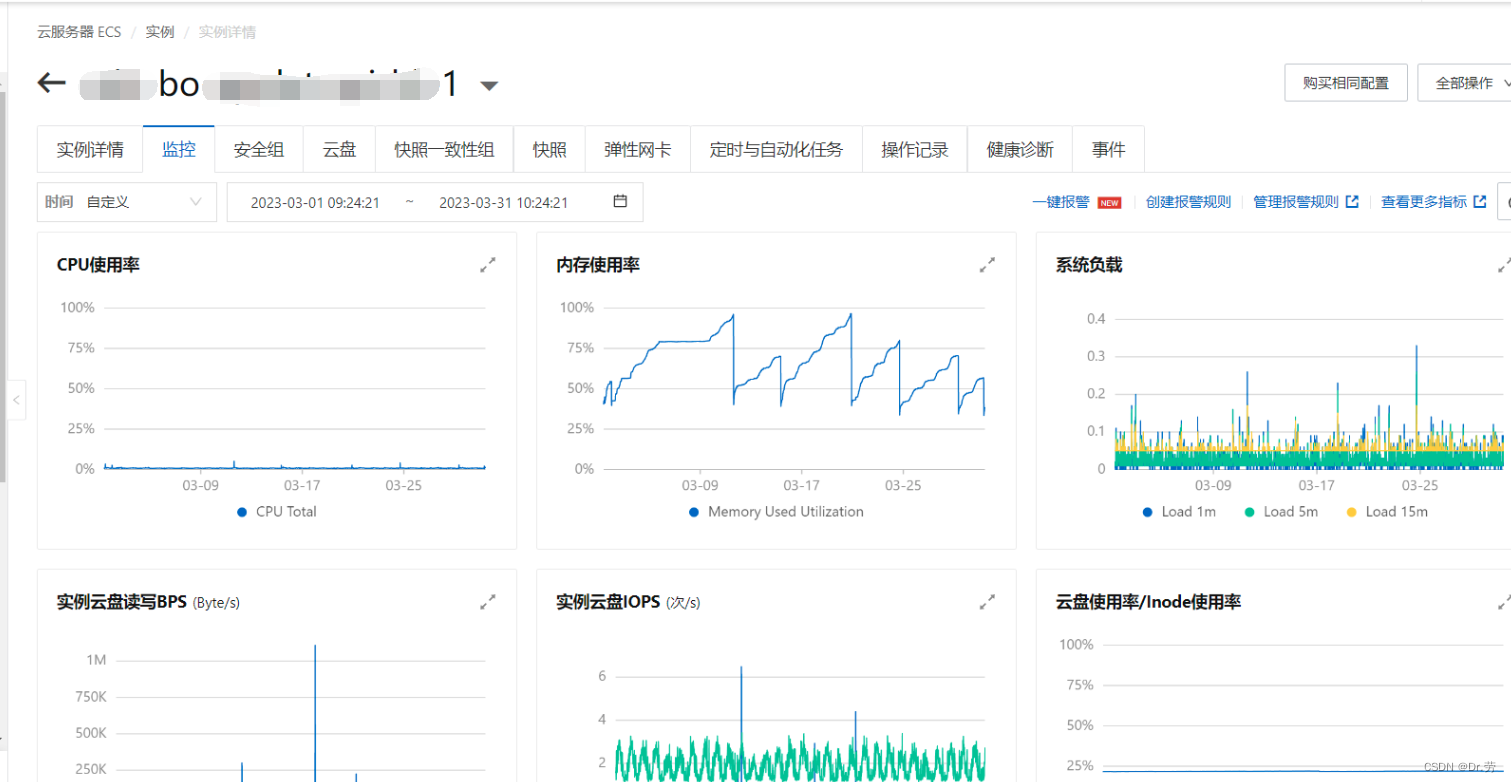
案例二:
其他服务潜在问题
1.可以看到我们base服务的物理内存图 和普罗米修斯的内存图,这个配置就很骚,堆内存配置了6G,年轻代也配置6G,这个服务并发也很大.导致10分钟就young gc一次,每次1S(下图的pause Durations就是gc时间和频率),GC要STW,就会感觉这个服务很卡.也会影响性能。这种骚操作我们可以看到基本无full gc,但是每次young gc都能吃一壶了,因为年轻代对象是朝生夕死的,而且采用的复制算法,由此可见年轻代越大,内存回收得久越慢,所以针对大内存我们应该换g1或者zgc等垃圾收集器,可以局部回收并且控制垃圾手机的时间。
那么我们可以看一下他的物理内存使用情况,也是一条直线,每次掉下去就是重启的时候,然后很快就上升到一条直线,因为访问多.
那么我们8g的服务器我们配置了6g堆内存+128m元空间,已经基本吃完8G服务的物理内存了.如果我们代码中有的代码申请直接内存,估计会堆外内存溢出.
| java -jar -Dfile.encoding=utf-8 -Dserver.port=7101 -Xms6g -Xmx6g -Xmn6g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m -XX:+UseParallelGC -XX:ParallelGCThreads=20 -Xloggc:/data/log/gc/xxx-base-biz-1.0.0.jar/7101/gc.log -XX:+PrintGCDetails -jar /data/.update/xxx-base-biz-1.0.0.jar |
|---|
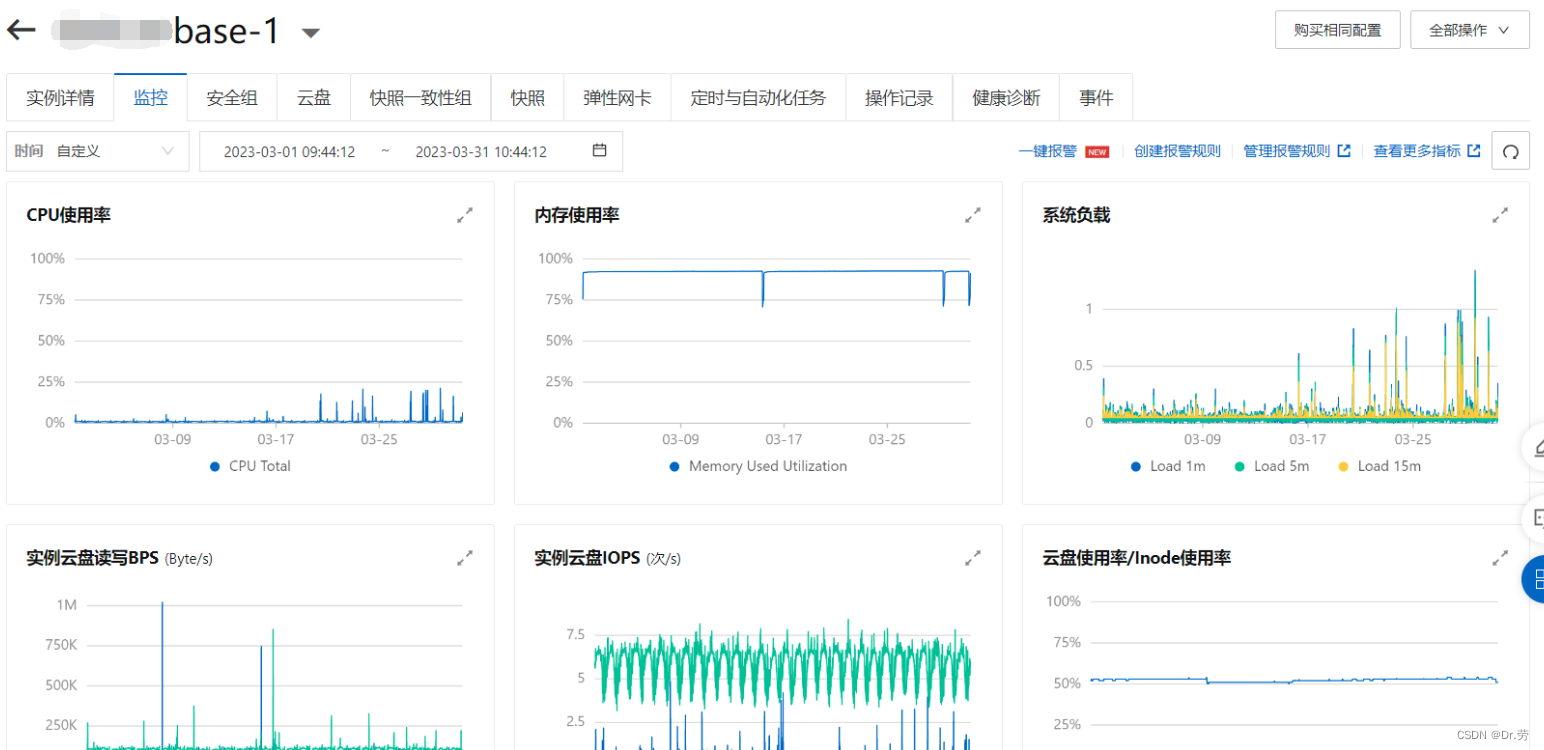

修改后,仅仅删除了Xmn,发现世界都顺畅了,基本无full gc,而且内存占用根本起不来,因为full gc少了,大量垃圾在年轻代被回收,gc时间也从平均1~2s变为几十毫秒,同理cabinet服务也一样。下面的参数其实还应该把Xmx,Xms调小。
| java -jar -Dfile.encoding=utf-8 -Dserver.port=7101 -Xms6g -Xmx6g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m -XX:+UseParallelGC -XX:ParallelGCThreads=20 -Xloggc:/data/log/gc/xxx-base-biz-1.0.0.jar/7101/gc.log -XX:+PrintGCDetails -jar /data/.update/xxx-base-biz-1.0.0.jar |
|---|

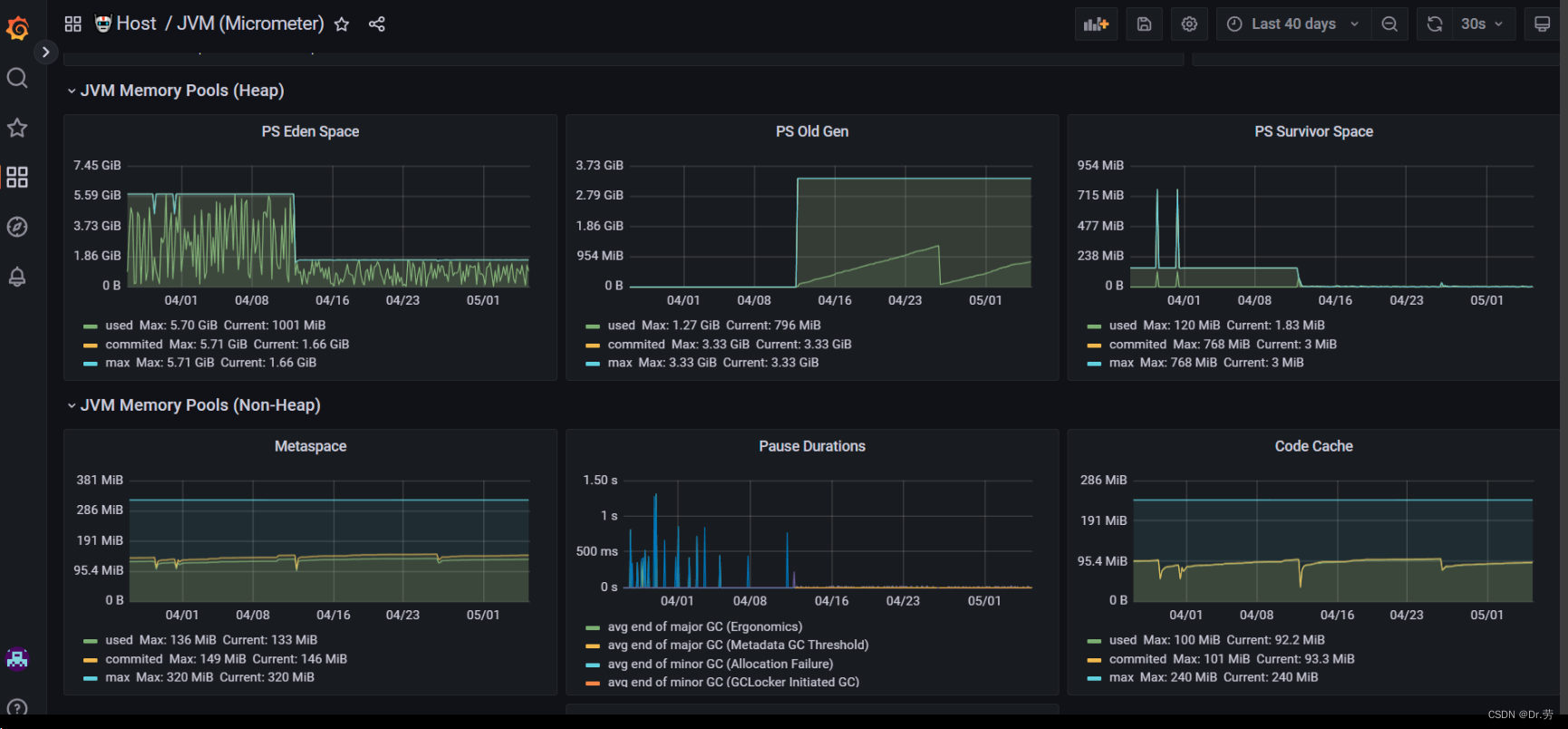
这是我们的cabinet服务,起码800qps/s一直持续,自从我们0413改了jvm配置之后,顺畅了,舒服。


案例三:
新生代和堆内存设置一样的大小,还会有一个问题,这个是测试环境发现的问题,就是不知道哪个人弄的,把新生代和堆设置一模一样,导致项目启动一直full gc,启动时间变为300秒,直到我删除-Xmn的配置之后,才变回80秒。
| 错误事例 java -server -jar -Dfile.encoding=utf-8 -Dserver.port=7201 -Xms256m -Xmx256m -Xmn256m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseParallelGC -XX:ParallelGCThreads=8 -XX:+PrintGCDetails -jar /mnt/data/application/admin/admin-7201.jar 修改后,删除-Xmn java -server -jar -Dfile.encoding=utf-8 -Dserver.port=7201 -Xms256m -Xmx256m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseParallelGC -XX:ParallelGCThreads=8 -XX:+PrintGCDetails -jar /mnt/data/application/admin/admin-7201.jar |
|---|
修改前,admin构建的时候cpu占用率500%,而且特别卡,通过top -Hp和jstack发现,占用cpu特别高的线程是gc线程,如下图
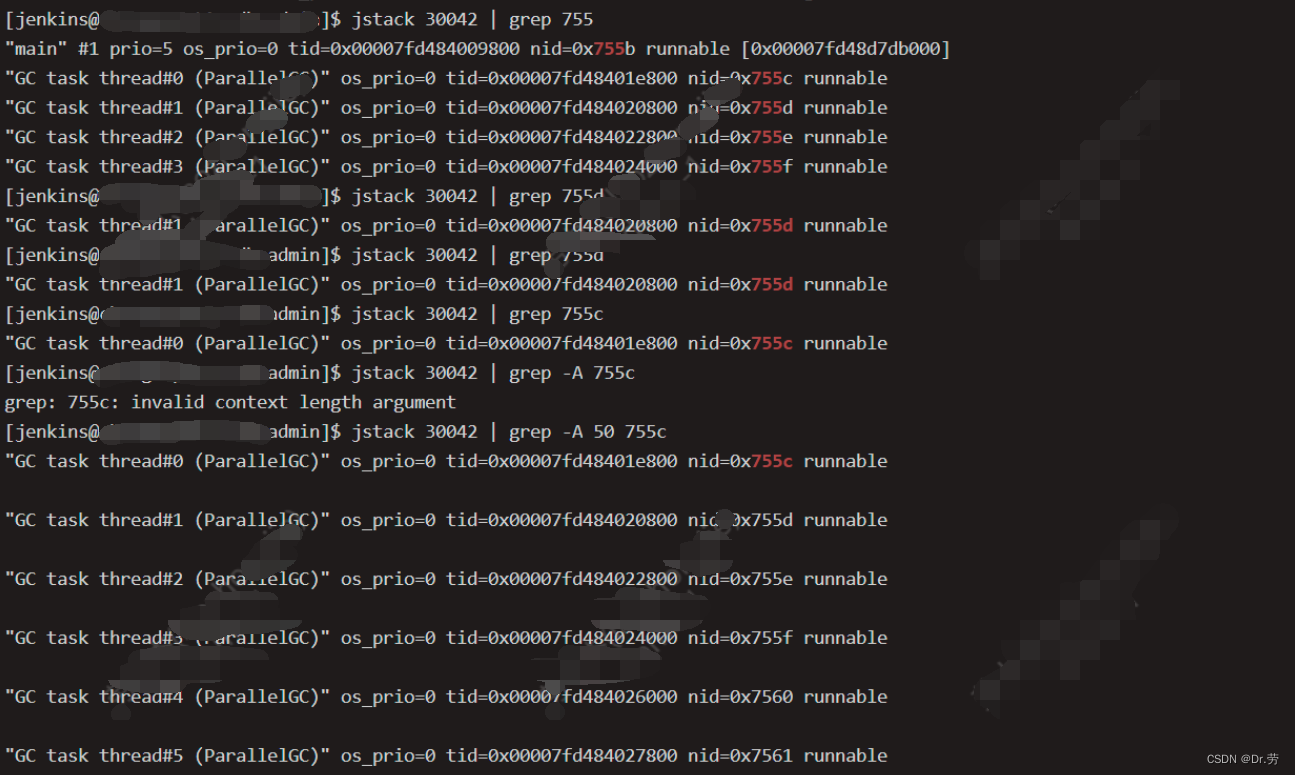
后面是删除-xmn的配置后,项目启动也从300S 掉到80S。

案例四:
一个很老的项目,有时候运行着,运行着直接就挂了,并且导出了内存dump文件,我们借助eclipse的MAT工具来分析内存快照,看哪一个地方内存溢出。
可以看到是一个hashMap占用内存过大,并且keywords指向了
- java.util.HashMap$Node[]
- org.crazycake.shiro.RedisSessionDAO.getActiveSessions()Ljava/util/Collection;
- RedisSessionDAO.java:66

原因:直接定位代码,发现是因为这一个开源项目用的Keys命令,然后遍历反序列化成为对象的过程OOM了,有经验的人一眼就看出来了,keys命令对于redis其实是一个很危险的命令,而一下子拿回来太多key,反序列化不就OOM了吗,而且这个功能是用来做分布式Session的,这个Shiro定时任务,每一段时间把所有key拿回来反序列化,而我们的Session设置了无限长,导致redis里面存储的Session越来越多,keys一拿,就OOM了。
解决方案:redis key设置过期时间

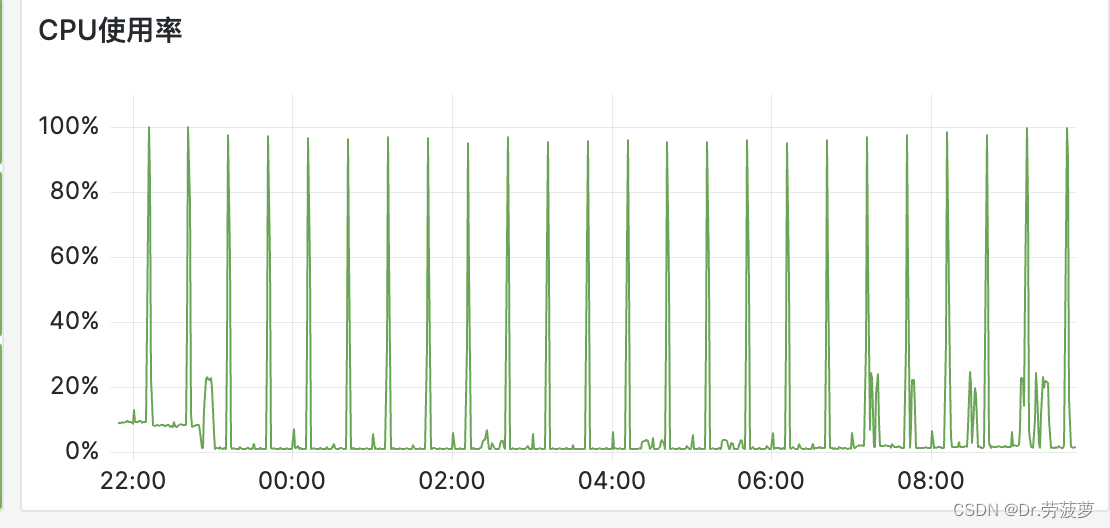
附上cpu的图,这种有频率的不用说肯定就是定时任务导致的.不仅仅业务服务器cpu是这样,redis服务器是这样。再仔细排查了一下原因
1.服务器端:key太多反序列化导致cpu拉高,而且当中有bigkey就更gg,而OOM就是因为反序列化的key又大又多。
2.redis端:因为6.0之前的redis IO是单线程的,所以你big key返回会阻塞其他命令执行,而redis是IO多路复用模型,监听到其他命令事件准备去执行,但是被阻塞了,而其他命令一直请求,一直阻塞,导致cpu暴涨
Big Key的危害?
1、阻塞请求
Big Key对应的value较大,我们对其进行读写的时候,需要耗费较长的时间,这样就可能阻塞后续的请求处理。Redis的核心线程是单线程,单线程中请求任务的处理是串行的,前面的任务完不成,后面的任务就处理不了。
2、内存增大
读取Big Key耗费的内存比正常Key会有所增大,如果不断变大,可能会引发OOM(内存溢出),或达到redis的最大内存maxmemory设置值引发写阻塞或重要Key被逐出。
3、阻塞网络
读取单value较大时会占用服务器网卡较多带宽,自身变慢的同时可能会影响该服务器上的其他Redis实例或者应用。
4、影响主从同步、主从切换
删除一个大Key造成主库较长时间的阻塞并引发同步中断或主从切换。
2.JVM如何调优
一般来说JVM默认参数以及足够好了,不需要动(例如我上面一些例子,瞎配置还会出问题,但是仍然可以线上正常运行,偶尔预警一下),只需要加上一些GC和OOM日志再加上初始堆内存和最大堆内存配置为一样即可,而需要优化的情况是FULL GC频繁,并且每次FULL GC的时间比较久,这种情况是需要优化的,单独FULL GC时间比较长也是需要优化的。FULL GC频率一般不超过1天2次,甚至有可能几天才1次FULL GC。除非你的访问用户量大,即使这样,FULL GC频繁但是STW时间不长也是不太需要优化的。
总结一下调优思路:
1.需要收集gc次数和gc的时间,可以通过gc日志,或者普罗米修斯等工具去观察。
2.如果cpu过高需要进行线程dump分析(jstack),看看是否gc线程
3.内存dump这个一般都逃不掉(jmap),分析到底是哪一些对象导致的频繁full gc,因为很多时候都是我们最近提交的代码逻辑导致的,如果是请求量大,gc时间短其实也不太需要管;如果是自己代码有死循环或者大对象,就需要自己去优化。
4.如果以上都做了,那就去看看jvm参数,一般最大堆内存和最小堆内存要一样大,因为内存频繁扩容缩容消耗挺大的,元空间也需要去配置一下,其他参数的话JVM默认配置已经挺好的了,还有一个就是垃圾收集器,如果内存8G或以上最好用CMS或者G1。
5.参数优化或者解释都可以去这里看看 HeapDump | 用户中心
懒人
直接在下面网址在线生成.HeapDump | 用户中心

勤劳的人
以4核8g的服务器为例
| 堆内存 首先是堆内存大小的设置。当我们的机器只有4核8G的时候,堆内存的大小肯定不能太大,一般不建议设置的太大,因为我们需要给机器上的其他应用预留出一部分内容。 所以,我们一般建议都是把JVM的堆内存设置成操作系统内存的一半或4分一,也就是4G。至于初始内存和最大内存,我们这场景中建议设置成一样的。这样可以避免JVM在运行过程中频繁进行内存扩容和收缩操作, 提高应用程序的性能和稳定性。即: -Xms4G -Xmx4G 垃圾收集器选择 所以,我们采用G1作为垃圾收集器: -XX:+UseG1GC 在使用了G1之后,其实他自己是有一套自动的预测和调优机制的。我们只需要通过 -xX:MaxCPauseMillis 参数来设置最大停顿时间就行了。一般建议设置到100-200之间,一般这个时长对用来说基本无感知: XX:MaxGCPauseMillis=209 其次,我们还可以自己调节一些G1的配置,比如设置他的GC线程数,可以先配置4个线程数进行GC,后续根据实际情况再做调整: XX:ParallelgCThreads=4 //设置并行 GC 线程数为 4 -XX:G1NewSizePercent 和 -XX:G1MaxNewSizePercent 分别用于设置年轻代的初始大小和最大大小,它们的默认值分别为 5% 和 60%。针对我们的业务场景,我们其实可以适当的调高一下年轻代的初始大小,5%的比例太小了,我们可以调整到30%. -XX:G1HeapRegionsize=2m: 将 G1 的区域大小设置为 2MB,以提高垃圾回收的效率和精度 -XX:G1NewsizePercent=20: 设置年轻代的初始大小为堆的 20%。 -XX:G1MaxNewsizePercent=50: 设置年轻代的最大大小为堆的 50%. -XX:G10ldcsetRegionThresholdPercent=10: 设置老年代的大小为堆的 10% -XX:G1HeadwastePercent=5: 设置垃圾回收后留下的未使用区域的最大比例为 5%. 添加必要的日志 -XX:MaxGCPauseMillis=100: 最大 GC 停时间为 100毫秒,可以根据实际情况调整 |
|---|
















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









