






在检测行业数字化转型浪潮中,传统人工报告生成模式已难以满足高效、精准、合规的业务需求。软秦科技推出的 IALab 检测报告生成系统,通过深度融合自然语言处理(NLP)、机器学习(ML)等 AI 技术,构建了一套全流程自动化的报告生成解决方案。本文将从技术架构、核心模块实现及应用效果等方面,解析 IALab 如何突破行业技术瓶颈。
一、行业痛点与技术挑战
检测报告生成面临三大技术难题:
- 多源异构数据处理:理化检测数据、生物指标、仪器日志等数据格式复杂,需高效解析与结构化处理;
- 动态合规标准适配:全球超 500 项检测法规标准频繁更新,需实时关联并校验报告合规性;
- 自然语言生成优化:将检测数据转化为专业报告时,需兼顾逻辑严谨性与行业术语规范性。
二、IALab 技术架构与核心模块
(一)系统架构设计
IALab 采用最新技术架构,核心模块包括:
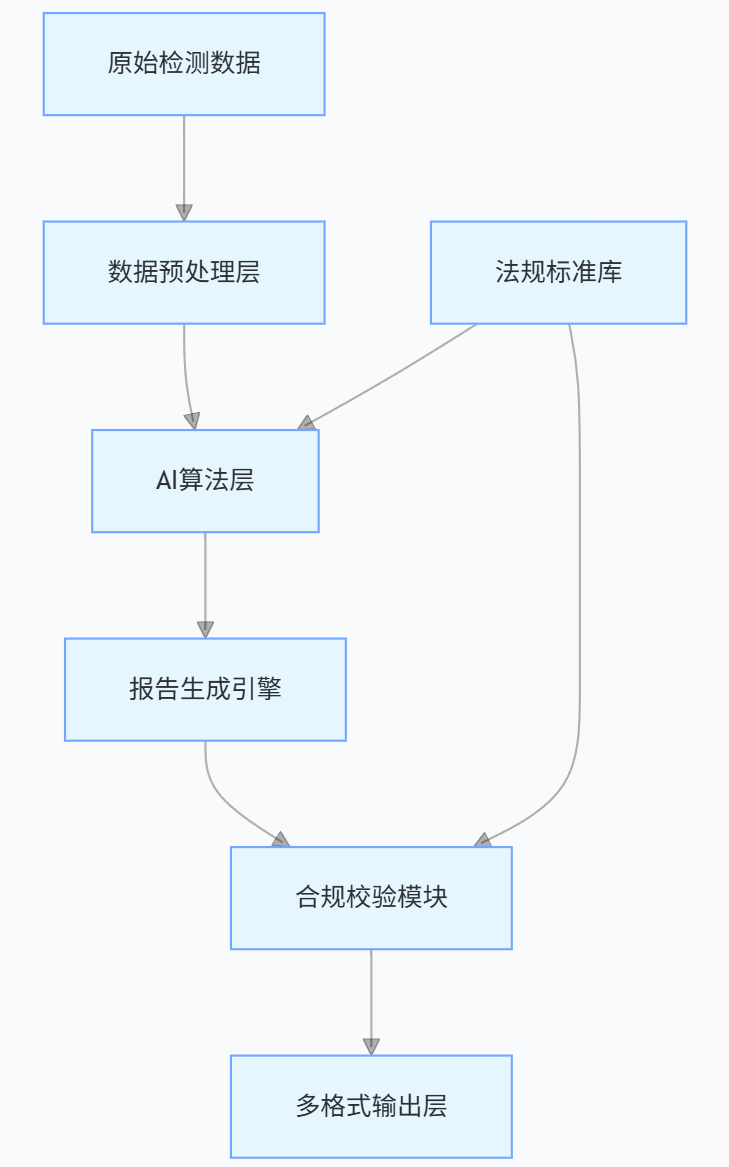
- 数据预处理层:通过 Python 的pandas库清洗、转换数据,使用Apache Spark实现大数据量并行处理;
- AI 算法层:集成 NLP 与 ML 模型,实现数据理解与智能决策;
- 法规标准库:基于Elasticsearch搭建,支持动态更新与高效检索。
(二)核心功能技术实现
1. 智能撰写:基于 NLP 的自动化生成
- 数据解析:采用spaCy库识别检测数据实体(如 “重金属含量”“pH 值”),结合正则表达式提取关键指标;
- 模板匹配:通过BERT模型计算数据与行业模板的语义相似度,自动选择最优模板;
- 文本生成:基于GPT,文心,千问等多种可选大模型微调的生成式模型,将数据转化为专业报告文本。
# 数据解析示例
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("样品A的铅含量为0.5mg/kg,pH值为7.2")
for ent in doc.ents:
print(f"实体: {ent.text},类型: {ent.label_}")2. 自动校验:多维度智能核查系统
- 数据一致性校验:使用Django框架搭建数据比对模块,通过 SQL 语句实现原始数据与报告数据的双向校验;
- 逻辑错误检测:基于规则引擎(如Drools)定义检测逻辑(如 “检测值> 限量值则判定不合格”);
- 术语规范检查:构建行业术语词库,利用FuzzyWuzzy库实现模糊匹配纠错。
3. 合规输出:动态法规智能适配
- 法规关联:通过Neo4j图数据库构建 “标准 - 项目 - 参数” 知识图谱,实现法规快速关联;
- 实时更新:采用Scrapy爬虫框架,结合Redis队列实现法规标准的分布式抓取与版本管理;
- 合规校验:基于PyTorch训练的分类模型,自动识别报告与法规冲突点。
三、技术应用效果与行业价值
(一)性能数据
- 效率提升:单份报告生成时间从人工 4 小时压缩至 30 分钟,效率提升 80%+;
- 错误率降低:自动校验模块使报告错误识别准确率达 99%,返工率下降 90%;
- 合规覆盖率:整合 500 + 法规标准,确保报告 100% 符合目标市场要求。
(二)典型应用场景
- 第三方检测机构:日均处理 200 + 报告,通过分布式部署 IALab 集群实现高并发响应;
- 企业质检部门:与 LIMS 系统通过 API 对接,构建从检测到报告的全链路自动化流程;
- 跨境检测业务:利用法规知识图谱快速适配不同国家 / 地区标准,加速认证周期。
四、未来技术演进方向
IALab 后续将聚焦以下方向优化:
- 多模态数据支持:集成图像识别技术,自动解析检测仪器原始图谱;
- 强化学习应用:通过历史报告反馈优化生成模型,实现自适应迭代;
- 区块链存证:结合智能合约确保报告数据不可篡改与全程可追溯。
随着 AI 技术与检测行业的深度融合,IALab 正推动报告生成从 “人力密集型” 向 “智能自动化” 转型。无论是技术选型、算法优化还是工程实践,IALab 的技术方案都为行业数字化升级提供了可借鉴的范本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









