






本文未配置 yarn和mapredule,只是单纯的hdfs
1. 需要先安装jdk
2. 配置java环境变量
编辑文件
vim /etc/profile在文件的最后添加java环境变量 (输入大写G可以调到文件末尾)
#java
export JAVA_HOME=/usr/local/java/java-se-8u41-ri
export PATH=$PATH:$JAVA_HOME/bin
3. 下载hadoop; 官方下载地址:https://hadoop.apache.org/releases.html
百度云下载hadoop3.1.3:https://pan.baidu.com/s/1IB1tEsMhlMxfU9Y8vqzHiQ?pwd=wjya
历史版本下载,点击如下
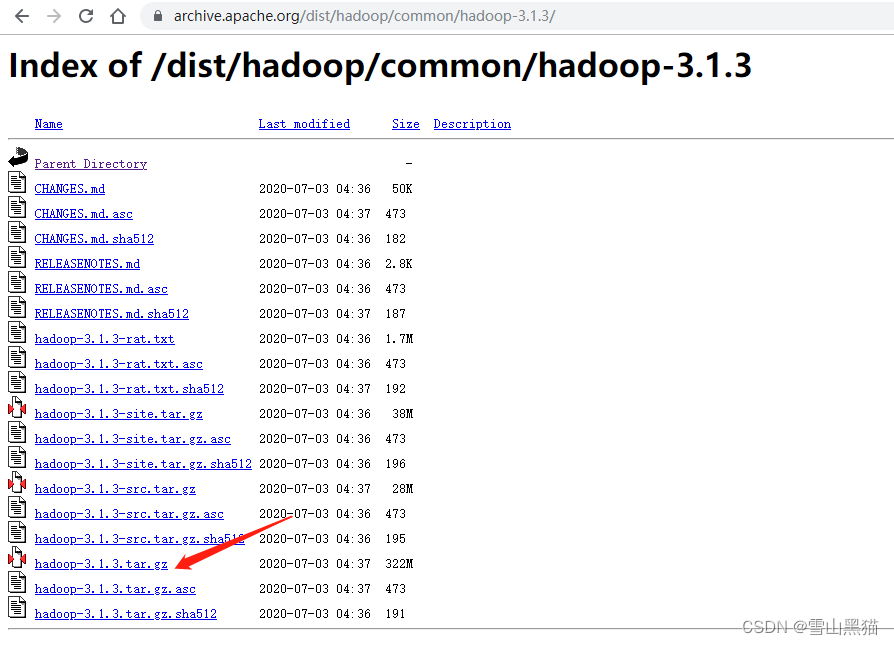
我选择3.1.3版本 (因为3.13版本有window客户端编译的winutils)

点击下载
4. 上传软件到服务器并解压
解压软件
tar -zxvf hadoop-3.1.3.tar.gz 在解压目录创建一个data目录
mkdir data

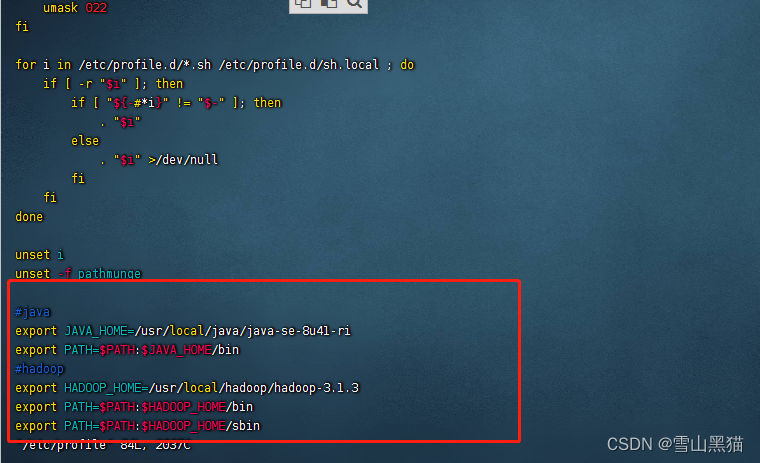
5. 配置hadoop的环境变量
vim /etc/profile#hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin我的配置截图(配置了jdk和hadoop的环境变量)
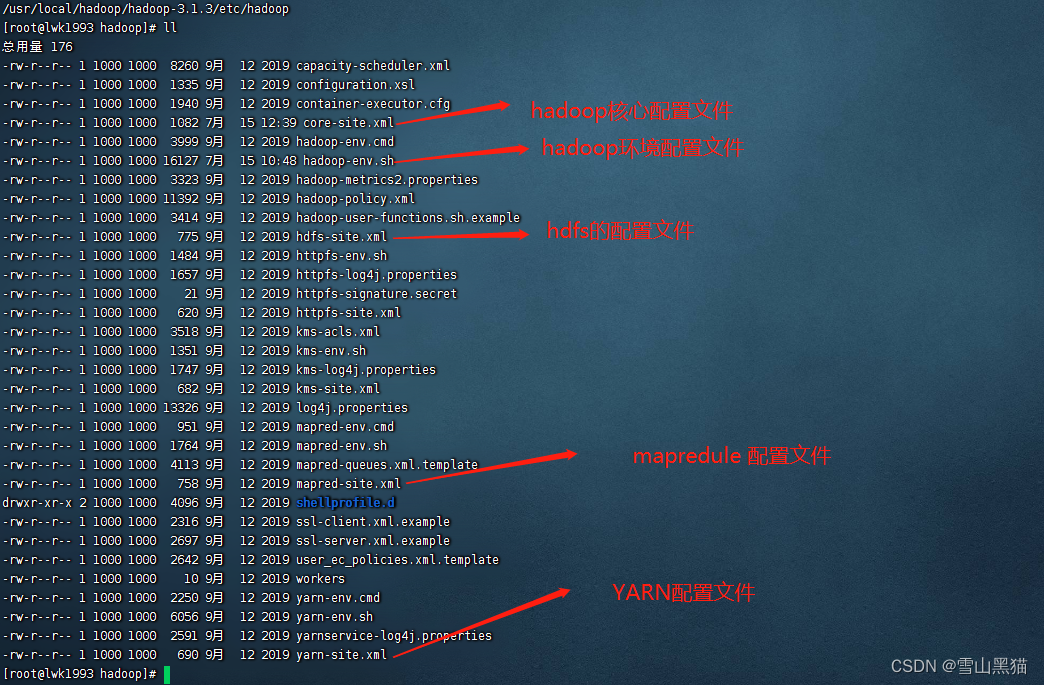
6. hadoop 结构介绍

配置文件介绍(位于hadoop目录/ect/hadoop)
7. hadoop-env.sh 环境配置
vim hadoop-env.sh在文件末尾添加
export JAVA_HOME=/usr/local/java/java-se-8u41-ri
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
JAVA_HOME 写你自己jdk的路径
我的配置截图:

8. core-site.xml 核心配置
vim core-site.xml配置在configuration中
<!-- namenode 访问配置 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<!--hadoop 数据存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>
<!--web访问UI 的用户为root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
fs.defaultFS:代表 namenode 节点使用hdfs 存储格式;在hadoop1机器上,端口号为:8020
hadoop1为在hosts配置的本机别名
vim /etc/hosts 配置 :<本机内网ip> <域名> <别名>
hadoop.tmp.dir:数据存放路径 (手动创建改目录)
hadoop.http.staticuser.user:浏览器访问的web页面,用户为root;防止出现目录权限问题
我的配置截图:

9. hdfs-site.xml 配置 (本此为单机模式、这个文件使用默认配置,未进行任何操作,以下的配置为分布式时)
<!-- namenode web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
<!-- namenode 辅助节点 secondary web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>dfs.namenode.http-address: 配置namenode的web端访问地址;namenode在hadoop1
机器上,这个就是浏览器访问的地址
dfs.namenode.secondary.http-address::配置namenode的辅助节点在hadoop2机器上;为完全分布式准备
在完全分布式中,namenode、secondarynamenode、resourcemanager 部署在不同的机器上
我的配置截图:

10. 配置ssh ,以后完全分布式系统要配置和ssh通信 ,我部署的单机,因为想使用start-dfs.sh脚本启动项目,所有ssh也配置了
生成密钥
ssh-keygen复制公钥到机器上
ssh-copy-id hadoop111 . 格式化文件系统(只可操作一次,初始化文件系统)
hdfs namenode -format12. 启动命令
start-dfs.sh使用 jps 命令查看是否启动成功

停止命令:
stop-dfs.sh13. 浏览器里访问页面: ip:9870 (要关闭防火墙或者开放端口)

14. 点击进去查看活动节点相关信息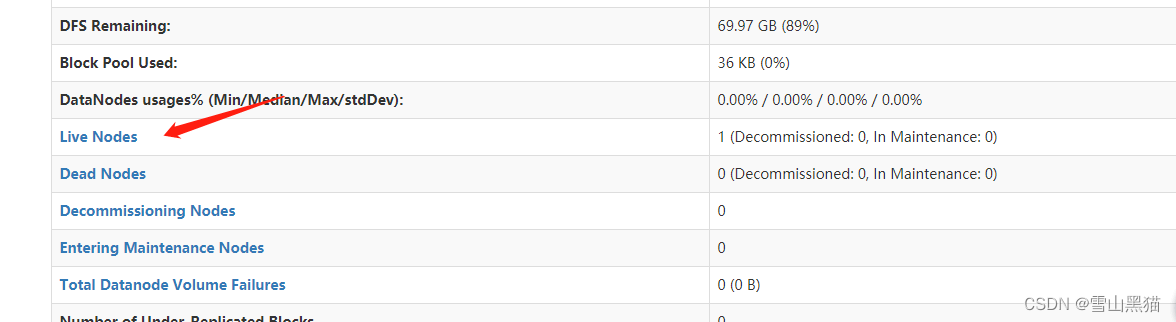
15. 进入操作文件系统的页面
 文件系统界面可以查询,新建目录,上传文件
文件系统界面可以查询,新建目录,上传文件
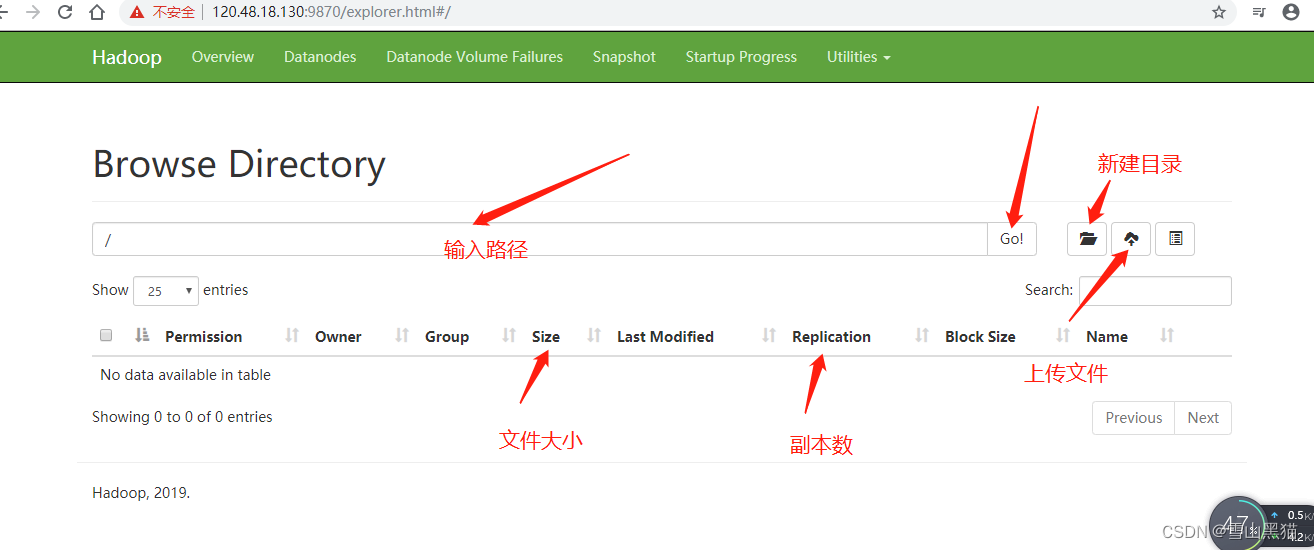

上图显示的lwk1993 为服务器的别名:要在本地hosts配置这个别名,不然下载或者使用java api操作会连接不到;
修改window的hosts文件(java api的项目放到linux ,也需要配置hosts)

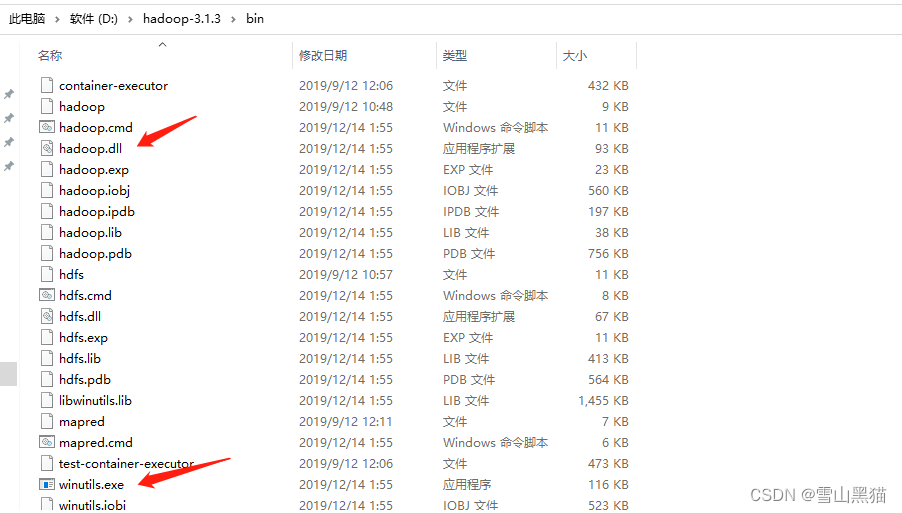
16. JAVA 操作文件系统
hadoop需要先安装客户端,在windows 配置相关环境变量
hadoop客户端需要winutils等,所有在github上下载别人编译好的软件
hadoop3.1.3 window包:https://github.com/s911415/apache-hadoop-3.1.3-winutils
hadoop3.1.3 window包百度云地址:
https://pan.baidu.com/s/1OXeXGTab_qmD7oUIFzWv8g?pwd=71q0
hadoop window包其他版本链接: (或者github 搜索 winutils)
https://github.com/steveloughran/winutils
https://github.com/wangyidong1923/hadoop
只需要bin目录就行
配置环境变量
新建系统变量

path配置

17. idea 创建项目
java 项目demo示例:https://gitee.com/xiaokd/hdfs-api
maven依赖:版本要一致
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>java代码:
package com.example.hdfsapi.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import javax.servlet.ServletOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
/**
* @description
* @anthor lwk
* @date 2022/7/15 16:53
*/
@Slf4j
public class HdfsClient {
private static Configuration conf;
private static FileSystem fs;
static {
//设置操作用户root
System.setProperty("HADOOP_USER_NAME", "root");
conf = new Configuration();
//设置namenode
conf.set("fs.defaultFS", "hdfs://120.48.18.130:8020");
//设置datanode使用域名
conf.set("dfs.client.use.datanode.hostname", "true");
}
/**
* 创建目录
*/
public static void createPath(String path) throws IOException {
try {
fs = FileSystem.get(conf);
fs.mkdirs(new Path(path));
}catch (IOException e){
log.info("hdfs创建目录失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 删除目录或文件
* @param path
* @param recursive 目录下为空时, 此值会杯忽略;当目录不为空时,传true会递归删除目录下所有内容;传false,不做任何操作
*/
public static void deletePath(String path, boolean recursive) throws IOException {
try {
fs = FileSystem.get(conf);
fs.delete(new Path(path), true);
}catch (IOException e){
log.info("hdfs删除目录失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 创建文件
* @param path
*/
public static void createFile(String path) throws IOException {
try {
fs = FileSystem.get(conf);
fs.create(new Path(path));
}catch (IOException e){
log.info("hdfs删除目录失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 检查目录或文件是否存在
*/
public static void exists(String path) throws IOException {
try {
fs = FileSystem.get(conf);
fs.exists(new Path(path));
}catch (IOException e){
log.info("hdfs检查文件是否存在失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 上传本地文件
* @param srcPath 原文件路径
* @param dstPath 上传hdfs的路径
*/
public static void uploadLocalFile(String srcPath, String dstPath) throws IOException {
try {
fs = FileSystem.get(conf);
fs.copyFromLocalFile(new Path(srcPath), new Path(dstPath));
}catch (IOException e){
log.info("hdfs上传本地文件失败失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 下载文件到本地
* @param srcPath hdfs的文件路径
* @param dstPath 下载到本地的路径
*/
public static void downloadLocalFile(String srcPath, String dstPath) throws IOException {
try {
fs = FileSystem.get(conf);
fs.copyToLocalFile(new Path(srcPath), new Path(dstPath));
}catch (IOException e){
log.info("hdfs上传本地文件失败失败");
}finally {
if(fs != null){
fs.close();
}
}
}
/**
* 上传文件
*/
public static void uploadFile(String path, InputStream inputStream) throws IOException {
FSDataOutputStream outputStream = null;
try {
fs = FileSystem.get(conf);
//获取输出流
outputStream = fs.create(new Path(path));
//复制流
IOUtils.copyBytes(inputStream, outputStream, conf);
}catch (IOException e){
log.info("上传文件失败");
}finally {
IOUtils.closeStream(inputStream);
IOUtils.closeStream(outputStream);
if(fs != null){
fs.close();
}
}
}
/**
* 下载文件
*/
public static void downFile(String path, OutputStream outputStream) throws IOException {
FSDataInputStream inputStream = null;
try {
fs = FileSystem.get(conf);
//获取输入流
inputStream = fs.open(new Path(path));
//复制流
IOUtils.copyBytes(inputStream, outputStream, conf);
}catch (IOException e){
log.info("上传文件失败");
}finally {
IOUtils.closeStream(inputStream);
IOUtils.closeStream(outputStream);
if(fs != null){
fs.close();
}
}
}
}















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









