






数据结构是计算机存储、组织数据的方式。
数组(Array)
所谓数组,就是一系列数据的集合。
数组的特点是:
- 在内存中,数组是一块连续的区域
- 在数组起始位置处,插入数据和删除数据效率低
插入数据时,待插入位置的元素和他后面的所有元素都需要向后搬移
删除数据时,待删除位置后面的所有元素都需要向前搬移。 - 随机访问效率很高,时间复杂度可以达到O(1)
数组的优点:随机访问性强,查找速度快,时间复杂度是0(1)
数组的缺点:从头部删除、从头部插入的效率低,时间复杂度是o(n),因为需要相应的向前搬移和向后搬移。
链表(ListNode)
所谓链表,链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表特点
-
在内存中,元素的空间可以在任意地方,空间是分散的,不需要连续。
-
链表中的元素有两个属性,一个是元素的值,另一个是指针,此指针标记了下一个元素的地址。
-
查找数据时间效率低,时间复杂度是o(n)
因为链表的空间是分散的,所以不具有随机访问性。
如果需要访问某个位置的数据,需要从第一个数开始找起,依次往后遍历,直到找到待查询的位置。时间复杂度是o(n)
链表的优点:任意位置插入元素和删除元素的速度快
链表的缺点:随机访问效率低,时间复杂度是o(n)
1.基础数据结构:数组
数组是计算机科学中最基本的数据结构之一。如果你用过数组,那么应该知道它就是一个含有数据的列表
let arr = ["apples","bananas", "cucumbers", "dates", "elderberries"]
每项数据在数组中的位置都会用索引的数字来标识

若想了解某个数据结构(例如数组)的性能,得分析程序怎样操作这一数据结构。
一般数据结构都有以下4种操作
读取:查看数据结构中某一位置上的数据。对于数组来说,这意味着查看某个索引所指的数据值。例如,查看索引2上有什么食品,就是一种读取。
查找:从数据结构中找出某个数据值的所在。对于数组来说,这意味着检查其是否包含某个值,如果包含,那么还得给出其索引。例如,检查"dates"是否存在于食品清单之中,给出其对应的索引,就是一种查找
插入:给数据结构增加一个数据值。对于数组来说,这意味着多加一个格子并填入一个值。例如,往购物清单中多加一项"figs",就是一种插入。
删除:从数据结构中移走一个数据值。对于数组来说,这意味着把数组中的某个数据项移走。例如,把购物清单中的"bananas"移走,就是一种删除。
说一下操作在数组上的运行速度
其实操作的速度,并不按时间计算,而是按步数计算
因为,你不可能很绝对地说,某项操作要花5秒。它在某台机器上要跑5秒,但换到一台旧一点的机器,可能就要多于5秒,而换到一台未来的超级计算机,运行时间又将显著缩短。所以,受硬件影响的计时方法,非常不可靠
然而,若按步数来算,则确切得多。如果A操作要5步,B操作要500步,那么我们可以很肯定地说,无论是在什么样的硬件上对比,A都快过B。因此,衡量步数是分析速度的关键。
操作的速度,也常被称为时间复杂度
来看一下4种操作方式在数组上要花多少步
1.1读取
读取,即查看数组中某个索引所指的数据值。
这只要一步就够了,因为计算机本身就有跳到任一索引位置的能力
计算机为什么能一步到位呢?原因如下。
计算机的内存可以被看成一堆格子。下图是一片网格,其中有些格子有数据,有些则是空白。

当程序声明一个数组时,它会先划分出一些连续的空格子以备使用。换句话说,如果你想创建一个包含5个元素的数组,计算机就会找出5个排成一行的空格子,将其当成数组。

索引和内存地址,如下图所示
1.2 查找
对于数组来说,查找就是检查它是否包含某个值,如果包含,还得给出其索引。那么,我们就试试在数组中查找"dates"要用多少步
对于我们人来说,可以一眼就看到这个购物清单上的"dates",并数出它的索引为3。但是,计算机并没有眼睛,它只能一步一步地检查整个数组。
想要查找数组中是否存在某个值,计算机会先从索引0开始,检查其值,如果不匹配,则继续下一个索引,以此类推,直至找到为止。

在这个例子中,我们找到"dates"了,它就在索引3那里。因为我们检查了4个格子才找到想要的值,所以这次操作总计是4步。
这种逐个格子去检查的做法,就是最基本的查找方法——线性查找
1.3 插入
往数组里插入一个新元素的速度,取决于你想把它插入到哪个位置上
假设我们想要在末尾插入"figs"。那么只需一步。因为之前说过了,计算机知道数组开头的内存地址,也知道数组包含多少个元素,所以可以算出要插入的内存地址,然后一步跳到那里插入就行了

但在数组开头或中间插入,就另当别论了。这种情况下,我们需要移动其他元素以腾出空间,于是得花费额外的步数
例如往索引2处插入"figs",如下所示。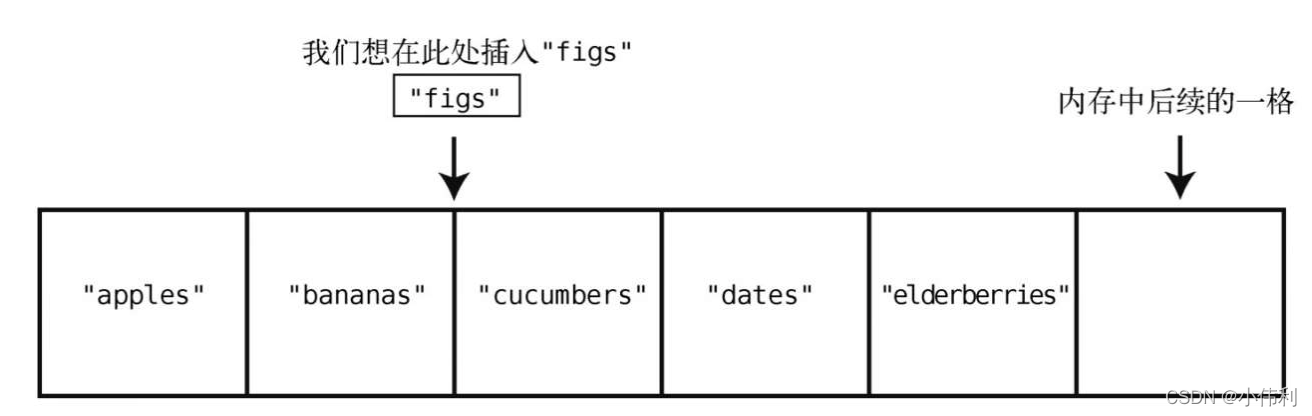
为了达到目的,我们必须先把"cucumbers"、“dates"和"elderberries"往右移,以便空出索引2。而这也不是一步就能移好,因为我们首先要将"elderberries"右移一格,以空出位置给"dates”,然后再将"dates"右移,以空出位置给"cucumbers"
如上所示,整个过程有4步,开始3步都是在移动数据,剩下1步才是真正的插入数据。最低效(花费最多步数)的插入是插入在数组开头。因为这时候需要把数组所有的元素都往右移。于是,一个含有N个元素的数组,其插入数据的最坏情况会花费N + 1步。即插入在数组开头,导致N次移动,加上一次插入。
1.4 删除
数组的删除就是消掉其某个索引上的数据。
我们找回最开始的那个数组,删除索引2上的值,即"cucumbers"。
第1步:删除"cucumbers"。

虽然删除"cucumbers"好像一步就搞定了,但这带来了新的问题:数组中间空出了一个格子。因为数组中间是不应该有空格的,所以,我们得把"dates"和"elderberries"往左移。
结果,整个删除操作花了3步。其中第1步是真正的删除,剩下的2步是移数据去填空格。
跟插入一样,删除的最坏情况就是删掉数组的第一个元素。因为数组不允许空元素,当索引0空出,那么剩下的所有元素都要往左移去填空
对于含有5个元素的数组,删除第一个元素需要1步,左移剩余的元素需要4步。而对于500个元素的数组,删除第一个元素需要1步,左移剩余的元素需要499步。可以推出,对于含有N个元素的数组,删除操作最多需要N步
当我们知道如何分析数据结构的时间复杂度,那就可以开始探索各种数据结构的性能差异了。
2.大O记法
计算机科学中,大O表示法被用来描述一个算法的性能或复杂度。大O表示法可以用来描述一个算法的最差情况,或者一个算法执行的耗时或占用空间(例如内存或磁盘占用)
大O不关注算法所用的时间,只关注其所用的步数
数组不论多大,读取都只需1步。用大O记法来表示,就是:O(1)
要逐个检查每个格子。在最坏情况下,线性查找所需的步数等于格子数。即如前所述:对于N个元素的数组,线性查找需要花N步。用大O记法来表示,即为:O(N)
二分查找的大O记法是:O(logN)(注意:必须是有序数组)
O(log N)意味着该算法当数据量翻倍时,步数加1
当我们说O(log N)时,其实指的是O(log2N),2N),不过为了方便就省略了2而已

从另一个角度来看,如果要把8个元素不断地分成两半,那么得拆分3次才能拆到只剩1个元素。这正是二分查找所干的事情。它就是不断地将数组拆成两半,直至范围缩小到只剩你要找的那个元素。
简单来说,O(logN)算法的步数等于二分数据直至元素剩余1个的次数。
3.链表
链表是由一组节点组成的集合。每个节点都使用一个对象的引用指向它的后继。指向另一个节点的引用叫做链。
组成链表的格子不是连续的。它们可以分布在内存的各个地方。这种不相邻的格子,就叫作结点。
每个结点除了保存数据,它还保存着链表里的下一结点的内存地址。
这份用来指示下一结点的内存地址的额外数据,被称为链。链表如下图所示。

此例中,我们的链表包含4项数据:“a”、“b”、“c"和"d”。因为每个结点都需要2个格子,头一格用作数据存储,后一格用作指向下一结点的链(最后一个结点的链是null,因为它是终点),所以整体占用了8个格子。
若想使用链表,你只需知道第一个结点在内存的什么位置。因为每个结点都有指向下一结点的链,所以只要有给定的第一个结点,就可以用结点1的链找到结点2,再用结点2的链找到结点3……如此遍历链表的剩余部分。
链表不需要数据在内存地址中连续存储,因此它没有顺序存储结构所具有的缺点,当然它也失去了数组在一块连续空间内随机存取的优点。
单向链表

单向链表的特点:
用一组任意的内存空间去存储数据元素(这里的内存空间可以是连续的,也可以是不连续的)
每个节点(node)都由数据本身和一个指向后续节点的指针组成
整个链表的存取必须从头指针开始,头指针指向第一个节点
最后一个节点的指针指向空(NULL)
3.1实现一个链表
class Node {
constructor(element) {
this.element = element; //保存节点数据
this.next = null; //指向下一个节点的链接
}
}
class LinkList {
constructor() {
this.head = new Node("head");
}
find(item) {
let currNode = this.head;
while (currNode.element != item) {
currNode = currNode.next;
}
return currNode;
}
/**
*newEle:一个新节点,item:链表的目标节点
*1.查找找到目标节点,将新节点的next指向目标节点的下一个节点
*2.将目标节点的next指向这个新节点
*/
insert(newEle, item) {
let newNode = new Node(newEle);
let currNode = this.find(item);
newNode.next = currNode.next;
currNode.next = newNode;
}
display() {
console.log(this.head);
var currNode = this.head;
while (!(currNode.next == null)) {
console.log(currNode.next.element);
currNode = currNode.next;
}
}
findPrev(item) {
var currNode = this.head;
while (currNode.next !== null && currNode.next.element != item) {
currNode = currNode.next;
}
return currNode;
}
//找到匹配节点的前一个节点,将其next指向当前节点的下一个节点,即删除当前节点
remove(item) {
var prevNode = this.findPrev(item);
if (prevNode.next !== null) {
prevNode.next = prevNode.next.next;
}
}
}
var cities = new LinkList();
cities.insert("北京", "head");
cities.insert("上海", "北京");
cities.insert("深圳", "上海");
cities.insert("广州", "深圳");
cities.display();
cities.remove("广州");
cities.display();
3.2 读取
读取链表中某个索引值的最坏情况,应该是读取最后一个索引。这种情况下,因为计算机得从第一个结点开始,沿着链一直读到最后一个结点,于是需要N步。由于大O记法默认采用最坏情况,所以我们说读取链表的时间复杂度为O(N)。这跟读取数组的O(1)相比,的确是一大劣势。
3.3 查找
链表的查找效率跟数组一样。记住,所谓查找就是从列表中找出某个特定值所在的索引。对于数组和链表来说,它们都是从第一格开始逐个格子地找,直至找到。如果是最坏情况,即所找的值在列表末尾,或完全不在列表里,那就要花O(N)步
3.4 插入
1.在某些情况下,链表的插入跟数组相比,有着明显的优势。回想插入数组的最坏情况:当插入位置为索引0时,因为需要先将插入位置右侧的数据都右移一格,所以会导致 O(N)的时间复杂度。然而,若是往链表的表头进行插入,则只需一步,即O(1)。
2.插入到链表的最后一个结点,要找出倒数第二的结点,得花 N步,因为我们依然只能从第一个结点顺着链往下一个个地找。
你会发现链表的最坏情况和最好情况与数组刚好相反。在链表开头插入很方便,在数组开头插入却很麻烦;在数组的末尾插入是最好情况,在链表的末尾插入却是最坏情况。总结起来如下表所示。

3.5 删除
1.删除跟插入是相似的。如果删除的是链表的第一个结点,那就只要1步:将链表的first_node设置成当前的第二个结点
list.first_node = node2
再回想删除数组的第一个元素时,得把剩余的所有元素左移一格,需要O(N)的时间复杂度。
2.删除链表的最后一个结点,其实际的删除动作只需1步——令倒数第二的结点的链指向null。然而,要找出倒数第二的结点,得花 N步,因为我们依然只能从第一个结点顺着链往下一个个地找。
下面这个表格对比了各种情况下数组和链表删除操作的效率。注意它跟插入效率的表格几乎一模一样。

经过一番分析,链表与数组的性能对比如下所示。

那么哪些场景下适合使用链表呢?
链表通常用在插入和删除比较多的场景,比如记账软件和代办事项等。
而且高效地遍历单个列表并删除其中多个元素,是链表的亮点之一。
假设我们正在写一个整理电子邮件地址的应用,它会删掉列表中无效格式的地址。具体算法是,每次读取一个地址,然后用正则表达式(一种用于识别数据格式的特定模式)来校验其有效性。如果发现该地址无效,就将它从列表中移除。
不管这个列表是数组还是链表,要检查每个元素的话,都得花N步。然而,当要删除邮件地址时,它们的效率却不同,下面我们来验证一下。
用数组的话,每次删除邮件地址,我们就要另外再花 O(N)步去左移后面的数据,以填补删除所产生的空隙。而且还必须完成这些平移才能执行下一次邮件地址的检查。
所以如果存在需要删除的无效地址,那么除了遍历邮件地址的 N步,还得加上 N步乘以无效地址数。
假设每10个地址就有1个是无效的。如果列表包含1000个地址,那么无效的就应该会有100个。于是我们的算法就要花1000步来读取,再加上删除所带来的大约100000步的操作(100个无效地址×N)。
但要是链表的话,每次删除只需1步就好,因为只需改动结点中链的指向,然后就可以继续检查下一邮件地址了。按这种算法去处理1000个邮件地址,只需要1100步(1000步读取和100步删除)。
3.双向链表
尽管从链表的头节点遍历到尾节点很简单,但反过来,从后向前遍历则没那么简单。通过给Node对象增加一个属性,该属性存储指向前驱节点的链接,这样就容易多了。此时向链表插入一个节点需要更多的工作,我们需要指出该节点正确的前驱和后继。但是在从链表中删除节点时,效率提高了,不需要再查找待删除节点的前驱节点了。双向链表的工作原理。

首当其冲的是要为Node类增加一个prev属性:
class Node {
constructor(element) {
this.element = element; //保存节点数据
this.next = null; //指向下一个节点的链接
this.prev = null;
}
}
双向链表的insert()方法和单向链表的类似,但是需要设置新节点的prev属性,使其指向该节点的前驱。该方法的定义如下:
/**
*newEle:一个新节点,item:链表的目标节点
*1.查找找到目标节点,将新节点的next指向目标节点的下一个节点
*2.将目标节点的next指向这个新节点
*/
insert(newEle, item) {
let newNode = new Node(newEle);
let currNode = this.find(item);
newNode.next = currNode.next;
newNode.prev = currNode;
currNode.next = newNode;
}
双向链表的remove()方法比单向链表的效率更高,因为不需要再查找前驱节点了。首先需要在链表中找出存储待删除数据的节点,然后设置该节点前驱的next属性,使其指向待删除节点的后继;设置该节点后继的prev属性,使其指向待删除节点的前驱。
remove()方法的定义如下:
//找到匹配节点的前一个节点,将其next指向当前节点的下一个节点,即删除当前节点
remove(item) {
var currNode = this.find(item);
if (currNode.next !== null) {
currNode.prev.next = currNode.next;
currNode.next.prev = currNode.prev;
currNode.next = null;
currNode.prev = null;
}
}
为了完成以反序显示链表中元素这类任务,需要给双向链表增加一个工具方法,用来查找最后的节点。findLast()方法找出了链表中的最后一个节点,同时免除了从前往后遍历链表之苦:
findLast() {
var currNode = this.head;
while (currNode.next !== null) {
currNode = currNode.next;
}
return currNode;
}
有了这个工具方法,就可以写一个方法,反序显示双向链表中的元素。dispReverse()方法如下所示:
dispReverse() {
var currNode = this.head;
currNode = this.findLast();
while (currNode.prev !== null) {
console.log("反向:" + currNode.element);
currNode = currNode.prev;
}
}
展示了所有代码
class Node {
constructor(element) {
this.element = element; //保存节点数据
this.next = null; //指向下一个节点的链接
this.prev = null;
}
}
class LinkList {
constructor() {
this.head = new Node("head");
}
find(item) {
let currNode = this.head;
while (currNode.element != item) {
currNode = currNode.next;
}
return currNode;
}
/**
*newEle:一个新节点,item:链表的目标节点
*1.查找找到目标节点,将新节点的next指向目标节点的下一个节点
*2.将目标节点的next指向这个新节点
*/
insert(newEle, item) {
let newNode = new Node(newEle);
let currNode = this.find(item);
newNode.next = currNode.next;
newNode.prev = currNode;
currNode.next = newNode;
}
display() {
console.log(this.head);
var currNode = this.head;
while (!(currNode.next == null)) {
console.log(currNode.next.element);
currNode = currNode.next;
}
}
dispReverse() {
var currNode = this.head;
currNode = this.findLast();
while (currNode.prev !== null) {
console.log("反向:" + currNode.element);
currNode = currNode.prev;
}
}
findLast() {
var currNode = this.head;
while (currNode.next !== null) {
currNode = currNode.next;
}
return currNode;
}
//找到匹配节点的前一个节点,将其next指向当前节点的下一个节点,即删除当前节点
remove(item) {
var currNode = this.find(item);
if (currNode.next !== null) {
currNode.prev.next = currNode.next;
currNode.next.prev = currNode.prev;
currNode.next = null;
currNode.prev = null;
}
}
}
var cities = new LinkList();
cities.insert("北京", "head");
cities.insert("上海", "北京");
cities.insert("深圳", "上海");
cities.insert("广州", "深圳");
cities.display();
cities.remove("广州");
cities.display();
cities.dispReverse();














 1312
1312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









