







由于python GIL的存在,让python 多线程很鸡肋,很多时候如果有并发的需求,则选择多进程来实现,但是多进程是很消耗资源的,而且进程之间不能资源共享,而且还会受到机器CPU核心数目的限制,因此在特定场景下针对不同需求会有一些取舍。传闻对于IO密集性的操作,比如,处理多个http 的请求,其实python多线程是完全可以发挥作用的,这种方式比多进程要高效的多(还好有高级python开发的好基友指点,不然一直认为python多线程就是废材,真外行了,在此贴出他的私人博客 https://www.longxyun.com/ )。为了验证这一伟大结论,特此设计一个对比实验
- 创建一个简单Flask服务
import time
from flask import Flask
app = Flask(__name__)
@app.route("/", methods=["GET"])
def func():
time.sleep(2) # 模拟服务需要2秒后响应过程
return "GET"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5555)- 多线程访问脚本
import time
import requests
from threading import Thread
url = "http://127.0.0.1:5555/"
res_list = []
t_list = []
def func(x):
print("Thread: {}".format(x))
res_list.append(requests.get(url))
if __name__ == '__main__':
# 开启10个线程
s = time.time()
for i in range(10):
t = Thread(target=func, args=(i,))
t_list.append(t)
t.start()
for t in t_list:
t.join()
print("MAIN processing")
for r in res_list:
print(r.text)
print(time.time() - s)- 多进程访问脚本
import time
import requests
from multiprocessing.pool import Pool
url = "http://127.0.0.1:5555/"
def func(x):
print("Processing: {}".format(x))
return requests.get(url)
if __name__ == '__main__':
s = time.time()
p = Pool()
res = p.map(func, [i for i in range(10)])
p.close()
p.join()
print("MAIN processing")
for r in res:
print(r.text)
print(time.time() - s)- 运行结果
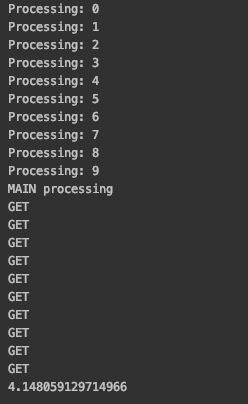
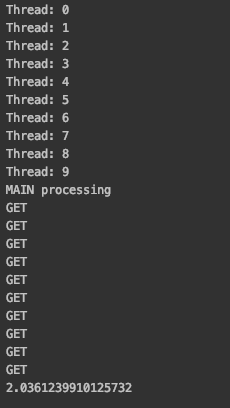
如图所示,当启动多个请求数目大于CPU核数时(我本机是4核心),多线程消耗时间明显好于多进程,因为本身是IO操作,没有高强度计算,也不会连续使用CPU,仅仅是一个指令的触发操作,因此在请求这个指令触发一瞬间,执行过程已经交给网络传输了,而与此同时线程已经切换到了下一个线程,所以当把启动线程增加到100个时候,时间依旧会接近2秒,因为线程切换也会有开销,所以不可能完全等于2秒。
综上所述,实践是检验真理的唯一标准!















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









