







本篇由本人整理黑盒、白盒、接口测试一系列用例设计方法。
黑盒测试用例设计方法包括等价类划分法、边界值分析法、错误推测法、因果图法、判定表驱动法、正交试验设计法、功能图法、场景图法等。
(一)等价类划分法
定义:等价类划分法是把所有可能输入的数据,即程序的输入域划分策划国内若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。方法是一种重要的、常用的黑盒测试用例设计方法。
等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的,并合理地假定:测试某等价类的代表值就等于对这一类其他值的测试,因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件就可以用少量代表性的测试数据取得较好的测试结果。等价类划分有两种不同的情况:有效等价类和无效等价类。
有效等价类,是指对于程序的规格说明来说是合理的、有意义的输入数据构成的集合。利用有效等价类可检验程序是否实现了规格说明所规定的功能和性能。
无效等价类 指对程序的规格说明是不合理的或无意义的输入数据所构成的集合。对于具体的问题,无效等价类至少应有一个,也可能多个。
划分标准:
1) 完备测试、避免冗余
2) 划分等价类重要的是:集合的划分、划分为互不相交的一组子集,而子集的并是整个集合
3) 并是整个集合:备性
4) 子集互不相交:保证一种形式的无冗余性
5) 同一类中标识(选择)一个测试用例,同一等价类中,往往处理相同,相同处理映射到“相同的执行路径”。
划分方法:
1) 在输入条件规定了取值范围或值的个数的情况下,则可以确立一个有效等价类和两个无效等价类。如:输入值是学生成绩,范围是0~100;
2)在输入条件规定了输入值的集合或者规定了“必须如何”的条件的情况下,可确立一个有效等价类和一个无效等价类:
3)在输入条件是一个布尔量的情况下,可确定一个有效等价类和一个无效等价类。布尔量是一个二值枚举类型, 一个布尔量具有两种状态: true 和 false 。
4)在规定了输入数据的一组值(假定n个),并且程序要对每一个输入值分别处理的情况下,可确立n个有效等价类和一个无效等价类。
例:输入条件说明学历可为:专科、本科、硕士、博士四种之一,则分别取这四种的四个值作为四个有效等价类,另外把四种学历之外的任何学历作为无效等价类。
5)在规定了输入数据必须遵守的规则情况下,可确立一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则);
6)在确知已划分的等价类中各元素在程序处理中的方式不同的情况下,则应在将该等价类进一步的划分为更小的等价类。
转化为测试用例:
在确立了等价类后,可建立等价类表,列出所有划分出的等价类输入条件:有效等价类、无效等价类,然后从划分出的等价类中按以下三个原则设计测试用例:
1)为每一个等价类规定一个唯一的编号;
2)设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖地有效等价类,重复这一步,直到所有的有效等价类都被覆盖为止;
3)设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步,直到所有的无效等价类都被覆盖为止。
实例1:三角形问题
某程序规定:“输入三个整数a、b、c分别作为三边的边长构成三角形。通过程序判定所构成的三角形的类型,当此三角形为一般三角形、等腰三角形、等边三角形时,分别做计算。。。”用等价类划分方法为该程序进行测试用例设计。
分析题目中给出和隐含的对输入条件的要求:
(1)整数 (2)三个数(3)非零数(4)正数
(5)两边之和大于第三边(6)等腰 (7)等边
如果a、b、c满足条件(1)~(4),则输出下列四种情况之一:
1)如果不满足条件(5),则程序输出为“非三角形”
2)如果三条边相等即满足条件(7),则程序输出为“等边三角形”
3)如果只有两条边相等,及满足条件(6),则程序输出为“等腰三角形”
4)如果三条边都不相等,则程序输出为“一般三角形”
列出等价类表并编号

覆盖有效等价类的测试用例:
a b c覆盖等价类号码
3 4 5 (1) (7)
4 4 5 (1)(7) (8)
4 5 5 (1) (7) (9)
5 4 5 (1) (7) (10)
4 4 4 (1) (7) (11)
覆盖无效等价类的测试用例:
覆盖有效等价类的测试用例:
a b c覆盖等价类号码
3 4 5 (1) (7)
4 4 5 (1)(7) (8)
4 5 5 (1) (7) (9)
5 4 5 (1) (7) (10)
4 4 4 (1) (7) (11)
覆盖无效等价类的测试用例:

实例2,NextDate
NextDate函数包含三个变量:month、day、year,函数的输出为输入日期后一天的日期。
例如,输入2006年3月7日,则函数的输出为2006年3月8日。要求输入变量month、day、year均为整数值,并且满足下列条件:
1、1<=month<=12
2、1<=day<=31
3、1812<=year<=2012
1)有效等价类为:
M1={月份:1<=月份<=12}
D1={日期:1<=日期<=31}
Y1={年份:1812<=年<=2012}
2)若条件1~3中任何一个条件失效,则NextDate函数都会产生一个输出,指明相应的变量超出取值范围,比如“month的值不在12范围中”。显然还存在这大量的year、month、day的无效组合,NextDate函数将这些组合作为统一的输出:“无效输入日期”。
其无效等价类为:
M2={月份:月份<1}
M3={月份:月份>12}
D2={日期:日期<1}
D3={日期:日期>31}
Y2={年份:年<1812}
Y3={年份:年>2012}
弱一般等价类测试用例
| 月份 | 日期 | 年 | 预期输出 |
| 6 | 15 | 1912 | 1912年6月16日 |
强一般等价类测试用例同弱一般等价类测试用例
注:弱有单缺陷假设;健壮考虑了无效值。
(一)弱健壮等价类测试
| 用例 | ID | 月份 | 日期 | 年 | 预期输出 |
| WR1 |
| 6 | 15 | 1912 | 1912年6月16日 |
| WR2 |
| 0 | 1 | 1912 | 月份不在1~12中 |
| WR3 |
| 15 | 1 | 1912 | 月份不在1~12中 |
| WR4 |
| 1 | 0 | 1912 | 日期不在1~31中 |
| WR5 |
| 1 | 32 | 1912 | 日期不在1~31中 |
| WR6 |
| 1 | 1 | 1811 | 年不在1812~2012中 |
| WR7 |
| 1 | 1 | 2013 | 年不在1812~2012中 |
(二)强健壮等价类测试
| 用例 | ID | 月份 | 日期 | 年 | 预期输出 |
| SR1 |
| 15 | 1 | 1912 | 月份不在1~12中 |
| SR2 |
| 1 | 32 | 1912 | 日期不在1~31中 |
| SR3 |
| 1 | 1 | 1811 | 年份不在1812~2012中 |
| SR4 |
| 0 | 0 | 1912 | 两个无效一个有效 |
| SR5 |
| 0 | 1 | 1811 | 两个无效一个有效 |
| SR6 |
| 1 | 0 | 1811 | 两个无效一个有效 |
| SR7 |
| 0 | 0 | 1811 | 三个无效 |
(二)边界值分析法
定义:边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。通常边界值分析法是作为对等价类划分法的补充,这种情况下,其测试用例来自等价类的边界。
与等价类区别:
1)边界值分析不是从某等价类中随便挑一个作为代表,而是使这个等价类的每个边界都要作为测试条件。
2)边界值分析不仅考虑输入条件,还要考虑输出空间产生的测试情况。
分析方法:
大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
常见边界值:
1)对16Bit的整数而言,32767和32768是边界
2)屏幕上光标在最左上、最右下位置
3)报表的第一行和最后一行
4)数组元素的第一个和最后一个
5)循环的第0次、第1次和倒数第2次、最后一次
边界值分析:
1)边界值分析使用与等价类划分法相同的划分,只是边界值分析假定错误更多地存在于划分的边界上,因此在等价类的边界上以及两侧的情况设计测试用例。
例:测试计算平方根的函数
输入:实数
输出:实数
规格说明:当输入一个0或比0大的数的时候,返回其正平方根;当输入一个小于0的数时,显示错误信息“平方根非法,输入值小于0”并返回0;库函数printLine可以用来输出错误信息。
2)等价类划分:
i. 可以考虑做出如下划分:
A、输入(i)<0 和(ii)>=0
B、输出(a)>=0和(b)Error
ii. 测试用例有两个
A、输入4,输出2.对应(ii)和(a)。
B、输入10,输出0和错误提示。对应与(i)和(b)
3)边界值分析
划分(ii)的边界为0和最大正实数;划分(i)的边界为最小负实数和0.由此得到一下测试用例:
A、输入{最小负实数}
B、输入{绝对值很小的负数}
C、输入0
D、输入{绝对值很小的正数}
E、输入{最大正实数}
4)通常情况下,软件测试所包含的边界检验有几种类型:数字、字符、位置、重量、大小、速度、方位、尺寸、空间等。
5)相应地,以上类型的边界值应该在:最大/最小、首位/末位、上/下、最快/最慢、最高/最低、最短/最长、空/满等情况下。
6)利用边界值作为测试数据
| 项 | 边界值 | 测试用例的设计思路 |
| 字符 | 起始1个字符/结束+1个字符 | 假设一个文本输入区域允许输入1个到255个字符,输入1个和255个字符作为有效等价类;输入0个和256个字符作为无效等价类,这几个数值都属于边界条件值 |
| 数值 | 最小值1/最大值+1 | 假设某软件的数据输入域要求输入5位的数据值,可以使用10000作为最小值、9999作为最大值;然后使用刚好小于5位和大于5位的数值作为边界条件。 |
| 空间 | 小于空余空间一点/大于满空间一点 | 例如在用U盘存储数据时,使用比剩余磁盘空间大一点(几KB)的文件作为边界条件 |
7)内部边界值分析
在多数情况下,边界值条件是基于应用程序的功能设计而需要考虑的因素,可以从软件的规格说明或常识中得到,也是最终用户可以很容易发现问题的。然而,在测试用例设计过程中,某些边界值条件是不需要呈现给用户的,或者说用户是很难注意到的,但同时确实属于检验范畴内的边界条件,称为内部边界值条件或子边界值条件。
内部边界值条件主要有下面几种:
1)数值的边界值检验:计算机是基于二进制进行工作的,因此,软件的任何数值运算都有一定的范围限制。
| 项 | 范围或值 |
| 位(Bit) | 0或者1 |
| 字节(byte) | 0~255 |
| 字(Word) | 0~65535(单字)或0~4294967295(双字) |
| 千(K) | 1024 |
| 兆(M) | 1048576 |
| 吉(G) | 1073741824 |
2)字符的边界值检验:在计算机软件中,字符也是很重要的表示元素,其中ASCII和Unicode是常见的编码方式。下表中列出了一些常用字符对应的ASCII码值。
| 字符 | ASCII码值 | 字符 | ASCII码值 |
| 空(Null) | 0 | A | 65 |
| 空格(Space) | 32 | a | 97 |
| 斜杠(/) | 47 | z | 122 |
| 0 | 48 | Z | 90 |
| 冒号(:) | 58 | 单引号(’) | 96 |
| @ | 64 |
|
|
3)其它边界值检验:在不同的行业应用领域,依据硬件和软件的标准不同而具有各自特定的边界值。如下列出部分手机相关的边界值:
| 硬件设备 | 范围或值 |
| 手机锂电池电压 | 工作电压:3.6~4.2V; 保护电压:2.5~3V不等 |
| 手机正常使用温度 | -25°C~+60°C |
转化为测试用例:
1) 如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据。
Ø 例如,如果程序的规格说明中规定:"重量在10公斤至50公斤范围内的邮件,其邮费计算公式为……"。作为测试用例,我们应取10及50,还应取10.01,49.99,9.99及50.01等。
2) 如果输入条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据。
Ø 例如,一个输入文件应包括1~255个记录,则测试用例可取1和255,还应取0及256等。
3) 将规则1)和2)应用于输出条件,即设计测试用例使输出值达到边界值及其左右的值。
Ø 例如,某程序的规格说明要求计算出"每月保险金扣除额为0至1165.25元",其测试用例可取0.00及1165.24、还可取一0.01及1165.26等。
Ø 再如一程序属于情报检索系统,要求每次"最少显示1条、最多显示4条情报摘要",这时我们应考虑的测试用例包括1和4,还应包括0和5等。
4) 如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
5) 如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
6) 分析规格说明,找出其它可能的边界条件。
实例1,批阅试卷
现有一个学生标准化考试批阅试卷,产生成绩报告的程序。其规格说明如下:程序的输入文件由一些有80个字符的记录组成,如右图所示,所有记录分为3组:

1) 标题:这一组只有一个记录,其内容为输出成绩报告的名字。
2) 试卷各题标准答案记录:每个记录均在第80个字符处标以数字"2"。该组的第一个记录的第1至第3个字符为题目编号(取值为1一999)。第10至第59个字符给出第1至第50题的答案(每个合法字符表示一个答案)。该组的第2,第3……个记录相应为第51至第100,第101至第150,…题的答案。
3) 每个学生的答卷描述:该组中每个记录的第80个字符均为数字"3"。每个学生的答卷在若干个记录中给出。如甲的首记录第1至第9字符给出学生姓名及学号,第10至第59字符列出的是甲所做的第1至第50题的答案。若试题数超过50,则第2,第3……纪录分别给出他的第51至第100,第101至第150……题的解答。然后是学生乙的答卷记录。
4) 学生人数不超过200,试题数不超过999。
5) 程序的输出有4个报告:
a)按学号排列的成绩单,列出每个学生的成绩、名次。
b)按学生成绩排序的成绩单。
c)平均分数及标准偏差的报告。
d)试题分析报告。按试题号排序,列出各题学生答对的百分比。
解答:分别考虑输入条件和输出条件,以及边界条件。给出下表所示的输入条件及相应的测试用例。

输出条件及相应的测试用例表。

实例2,三角形的边界问题分析测试用例
在三角形问题描述中,除了要求边长是整数外,没有给出其它的限制条件。在此,我们将三角形每边边长的取范围值设值为[1, 100]。
| 测试用例 | a | b | c | 预期输出 |
| Test1 Test2 Test3 Test4 Test5 | 60 60 60 50 50 | 60 60 60 50 50 | 1 2 60 99 100 | 等腰三角形 等腰三角形 等边三角形 等腰三角形 非三角形 |
| Test6 Test7 Test8 Test9 | 60 60 50 50 | 1 2 99 100 | 60 60 50 50 | 等腰三角形 等腰三角形 等腰三角形 非三角形 |
| Test10 Test11 Test12 Test13 | 1 2 99 100 | 60 60 50 50 | 60 60 50 50 | 等腰三角形 等腰三角形 等腰三角形 非三角形 |
实例3,NextDate函数边界值分析测试用例
在NextDate函数中,隐含规定了变量mouth和变量day的取值范围为1≤mouth≤12和1≤day≤31,并设定变量year的取值范围为1912≤year≤2050。
(三)错误推测法
定义:基于经验和直觉推测程序中所有可能存在的各种错误,从而有针对性的设计测试用例的方法。
基本思想:列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例。
1. 例如,输入数据和输出数据为0的情况;输入表格为空格或输入表格只有一行。这些都是容易发生错误的情况。可选择这些情况下的例子作为测试用例。
2. 例如,前面例子中成绩报告的程序,采用错误推测法还可补充设计一些测试用例:
1) 程序是否把空格作为回答
2) 在回答记录中混有标准答案记录
3) 除了标题记录外,还有一些的记录最后一个字符即不是2也不是3
4) 有两个学生的学号相同
5) 试题数是负数
3. 例如,测试一个对线性表(比如数组)进行排序的程序,可推测列出以下几项需要特别测试的情况:
1) 输入的线性表为空表;
2) 表中只含有一个元素;
3) 输入表中所有元素已排好序;
4) 输入表已按逆序排好;
5) 输入表中部分或全部元素相同。
4. 例如,测试手机终端的通话功能,可以设计各种通话失败的情况来补充测试用例:
1) 无SIM 卡插入时进行呼出(非紧急呼叫)
2) 插入已欠费SIM卡进行呼出
3) 射频器件损坏或无信号区域插入有效SIM卡呼出
4) 网络正常,插入有效SIM卡,呼出无效号码(如1、888、333333、不输入任何号码等)
5) 网络正常,插入有效SIM卡,使用“快速拨号”功能呼出设置无效号码的数字
(四)因果图法
定义:因果图法是一种利用图解法分析输入的各种组合情况,从而设计测试用例的方法,它适合于检查程序输入条件的各种组合情况。
应用:
等价类划分法和边界值分析方法都是着重考虑输入条件,但没有考虑输入条件的各种组合、输入条件之间的相互制约关系。这样虽然各种输入条件可能出错的情况已经测试到了,但多个输入条件组合起来可能出错的情况却被忽视了。
如果在测试时必须考虑输入条件的各种组合,则可能的组合数目将是天文数字,因此必须考虑采用一种适合于描述多种条件的组合、相应产生多个动作的形式来进行测试用例的设计,这就需要利用因果图(逻辑模型)。
1. 因果图介绍
1) 4种符号分别表示了规格说明中向4种因果关系。

2) 因果图中使用了简单的逻辑符号,以直线联接左右结点。左结点表示输入状态(或称原因),右结点表示输出状态(或称结果)。
3) C1表示原因,通常置于图的左部;e1表示结果,通常在图的右部。C1和e1均可取值0或1,0表示某状态不出现,1表示某状态出现。
2. 因果图涉及的概念
1) 关系
Ø 恒等:若c1是1,则e1也是1;否则e1为0。
Ø 非:若c1是1,则e1是0;否则e1是1。
Ø 或:若c1或c2或c3是1,则e1是1;否则e1为0。“或”可有任意个输入。
Ø 与:若c1和c2都是1,则e1为1;否则e1为0。“与”也可有任意个输入。
2) 约束
输入状态相互之间还可能存在某些依赖关系,称为约束。例如,某些输入条件本身不可能同时出现。输出状态之间也往往存在约束。在因果图中,用特定的符号标明这些约束。

Ø 输入条件的约束有以下4类:
· E约束(异):a和b中至多有一个可能为1,即a和b不能同时为1。
· I约束(或):a、b和c中至少有一个必须是1,即 a、b 和c不能同时为0。
· O约束(唯一);a和b必须有一个,且仅有1个为1。
· R约束(要求):a是1时,b必须是1,即不可能a是1时b是0。
Ø 输出条件约束类型
输出条件的约束只有M约束(强制):若结果a是1,则结果b强制为0。
3. 采用因果图法设计测试用例的步骤:
1) 分析软件规格说明描述中,那些是原因(即输入条件或输入条件的等价类),那些是结果(即输出条件),并给每个原因和结果赋予一个标识符。
2) 分析软件规格说明描述中的语义,找出原因与结果之间,原因与原因之间对应的关系,根据这些关系,画出因果图。
3) 由于语法或环境限制,有些原因与原因之间,原因与结果之间的组合情况不可能出现,为表明这些特殊情况,在因果图上用一些记号表明约束或限制条件。
4) 把因果图转换为判定表。
5) 把判定表的每一列拿出来作为依据,设计测试用例。
实例1,字符
某软件规格说明书包含这样的要求:第一列字符必须是A或B,第二列字符必须是一个数字,在此情况下进行文件的修改,但如果第一列字符不正确,则给出信息L;如果第二列字符不是数字,则给出信息M。
解答:
1) 根据题意,原因和结果如下:
原因:
1——第一列字符是A;
2——第一列字符是B;
3——第二列字符是一数字。
结果:
21——修改文件;
22 ——给出信息L;
23——给出信息M。
2) 其对应的因果图如下:
11为中间节点;考虑到原因1和原因2不可能同时为1,因此在因果图上施加E约束。

3) 根据因果图建立判定表。

表中8种情况的左面两列情况中,原因①和原因②同时为1,这是不可能出现的,故应排除这两种情况。表的最下一栏给出了6种情况的测试用例,这是我们所需要的数据。
实例2,自动售货机
有一个处理单价为5角钱的饮料的自动售货机软件测试用例的设计。其规格说明如下:若投入5角钱或1元钱的硬币,押下〖橙汁〗或〖啤酒〗的按钮,则相应的饮料就送出来。若售货机没有零钱找,则一个显示〖零钱找完〗的红灯亮,这时在投入1元硬币并押下按钮后,饮料不送出来而且1元硬币也退出来;若有零钱找,则显示〖零钱找完〗的红灯灭,在送出饮料的同时退还5角硬币。
1) 分析这一段说明,列出原因和结果
原因:
1——售货机有零钱找
2——投入1元硬币
3——投入5角硬币
4——押下橙汁按钮
5——.押下啤酒按钮
结果:
21——售货机〖零钱找完〗灯亮
22——退还1元硬币
23——退还5角硬币
24——送出橙汁饮料
25——送出啤酒饮料
2) 画出因果图,如图所示。所有原因结点列在左边,所有结果结点列在右边。建立中间结点,表示处理的中间状态。中间结点:
11—— 投入1元硬币且押下饮料按钮
12——押下〖橙汁〗或〖啤酒〗的按钮
13——应当找5角零钱并且售货机有零钱找
14——钱已付清

3) 转换成判定表:

4) 在判定表中,阴影部分表示因违反约束条件的不可能出现的情况,删去。第16列与第32列因什么动作也没做,也删去。最后可根据剩下的16列作为确定测试用例的依据。
(五)判定表驱动法
定义:判定表是分析和表达多逻辑条件下执行不同操作的情况的工具。
优点:能够将复杂的问题按照各种可能的情况全部列举出来,简明并避免遗漏。因此,利用判定表能够设计出完整的测试用例集合。在一些数据处理问题当中,某些操作的实施依赖于多个逻辑条件的组合,即:针对不同逻辑条件的组合值,分别执行不同的操作。判定表适合于处理这类问题。
阅读指南,判定表:
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 问题 | 觉得疲倦吗? | Y | Y | Y | Y |
|
|
|
|
| 感兴趣吗? | Y | Y |
|
| Y | Y |
|
| |
| 糊涂吗? | Y |
| Y |
| Y |
| Y |
| |
| 建议 | 重读 |
|
|
|
| Y |
|
|
|
| 继续 |
|
|
|
|
| Y |
|
| |
| 跳下一章 |
|
|
|
|
|
| Y | Y | |
| 休息 | Y | Y | Y | Y |
|
|
|
| |
判定表由四部分组成,如下图:
1) 条件桩(Condition Stub):列出了问题的所有条件。通常认为列出的条件的次序无关紧要。
2) 动作桩(Action Stub):列出了问题规定可能采取的操作。这些操作的排列顺序没有约束。
3) 条件项(Condition Entry):列出针对它左列条件的取值。在所有可能情况下的真假值。
4) 动作项(Action Entry):列出在条件项的各种取值情况下应该采取的动作。
规则及规则合并:
1) 规则:任何一个条件组合的特定取值及其相应要执行的操作称为规则。在判定表中贯穿条件项和动作项的一列就是一条规则。显然判定表中列出多少组条件取值,也就有多少条规则,既条件项和动作项有多少列。
2) 化简:就是规则合并有两条或多条规则具有相同的动作,并且其条件项之间存在着极为相似的关系。
合并举例:
1) 如下图左端,两规则动作项一样,条件项类似,在1、2条件项分别去Y、N时,无论条件3取何值,都执行同一操作。即要执行的动作与条件3无关。于是可合并。“-”表示与取值无关
2) 与上类似,下图中,无关条件项“-”可包含其他条件项取值,具有相同动作的规则可合并。
3)
3) 化简后的读书指南判定表
|
| 1 | 2 | 3 | 4 | |
| 问题 | 觉得疲倦吗? | - | - | Y | N |
| 感兴趣吗? | Y | Y | N | N | |
| 糊涂吗? | Y | N | - | - | |
| 建议 | 重读 | X |
|
|
|
| 继续 |
| X |
|
| |
| 跳下一章 |
|
|
| X | |
| 休息 |
|
| X |
| |
判定表建立步骤:
1) 确定规则的个数。假如有n个条件,每个条件有两个取值(0,1),故2n种规则。
2) 列出所有的条件桩和动作桩
3) 填入条件项
4) 填入动作项,等到初始判定表
5) 简化,合并相似规则(相同动作)
实例1,机器维修
问题要求:“。。。。。。对功率大于50马力的机器,维修记录不全或已运行10以上的机器,应给予优先的维修处理。。。。。。”,这里假定,“维修记录不全”和“优先维修处理”均已在别处有更严格的定义。请建立判定表。
解答:
1、确定规则的个数:这里有3个条件,每个条件有两个取值,故应有2*2*2=8种规则。
2、列出所有的条件桩和动作桩:
| 条件 | 功率大于50马力吗? |
| 维修记录不全吗? | |
| 运行超过10年吗? | |
| 动作 | 进行优先处理 |
3、填入条件项。可从最后1行条件项开始,逐行向上填满。
4、填入动作桩和动作项。这样便得到如下图的初始判定表
|
|
|
|
|
|
|
|
|
|
|
| 条件 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 功率大于50马力吗? | Y | Y | Y | Y | N | N | N | N | |
| 维修记录不全吗? | Y | Y | N | N | Y | Y | N | N | |
| 运行超过10年吗? | Y | N | Y | N | Y | N | Y | N | |
| 工作 | 进行优先处理 | X | X | X |
| X |
| X |
|
| 作其它处理 |
|
|
| X |
| X |
| X |
5、
初始判定表化简。合并相似规则后得到
|
|
|
|
|
|
|
|
| 条件 |
| 1 | 2 | 3 | 4 | 5 |
| 功率大于50马力吗? | Y | Y | Y | N | N | |
| 维修记录不全吗? | Y | N | N | - | - | |
| 运行超过10年吗? | - | Y | N | Y | N | |
| 工作 | 进行优先处理 | X | X |
| X | X |
| 作其它处理 |
|
| X |
| X |
实例2,NextData函数的精简决策表
M1={月份, 每月有30天}
M2={月份, 每月有31天}
M3={月份, 2月} 有29=512条规则
D1={日期,1~28} 12月末31日和其它31
D2={日期,29} 日月份的31日处理不同
D3={日期,30} 平年2月28日处理不同
D4={日期,31} 于2月27日
Y1 ={年:年是闰年}
Y2 ={年:年不是闰年}
改进为:
M1={月份: 每月有30天}
M2={月份: 每月有31天, 12月除外}
M4={月份:12月}
M3={月份: 2月}
D1={日期:1<=日期<=27}
D2={日期:28}
D3={日期:29}
D4={日期:30}
D5={日期:31}
Y1 ={年:年是闰年}
Y2 ={年:年不是闰年}
输入变量间存在大量逻辑关系的NextData决策表

3. 用决策表测试法测试以下程序:该程序有三个输入变量month、day、year(month、day和year均为整数值,并且满足:1≤month≤12和1≤day≤31),分别作为输入日期的月份、日、年份,通过程序可以输出该输入日期在日历上隔一天的日期。
例如,输入为2004年11月29日,则该程序的输出为2000年12月1日。
1) 分析各种输入情况,列出为输入变量month、day、year划分的有效等价类。
2) 分析程序规格说明,结合以上等价类划分的情况给出问题规定的可能采取的操作(即列出所有的动作桩)。
3) 根据(1)和(2),画出简化后的决策表。
案例分析如下:
Ø month变量的有效等价类:
M1: {month=4,6,9,11} M2: {month=1,3,5,7,8,10}
M3: {month=12 }M4: {month=2}
Ø day变量的有效等价类:
D1:{1≤day≤26} D2: {day=27} D3: {day=28} D4: {day=29} D5: {day=30} D6: {day=31}
Ø year变量的有效等价类:
Y1: {year是闰年} Y2: {year不是闰年}
4) 考虑各种有效的输入情况,程序中可能采取的操作有以下六种:
a1: day+2 a2: day=2 a3: day=1
a4: month+1 a5: month=1 a6: year+1
4. 判定表在功能测试中的应用
1) 一些软件的功能需求可用判定表表达得非常清楚,在检验程序的功能时判定表也就成为一个不错的工具。如果一个软件的规格说明指出:
Ø 当条件1和条件2满足,并且条件3和条件4不满足,或者当条件1、3和条件4满足时,要执行操作1。
Ø 在任一个条件都不满足时,要执行操作2。
Ø 在条件1不满足,而条件4被满足时,要执行操作3。 根据规格说明得到如下判定表:

这里,判定表只给出了16种规则中的8种。事实上,除这8条以外的一些规则是指当不能满足指定的条件,执行3种操作时,要执行1个默许的操作。在没必要时,判定表通常可略去这些规则。但如果用判定表来设计测试用例,就必须列出这些默许规则(如下表)。
| 规则5 | 规则6 | 规则7 | 规则8 | |
| 条件1 | - | N | Y | Y |
| 条件2 | - | Y | Y | N |
| 条件3 | Y | N | N | N |
| 条件4 | N | N | Y | - |
| 默许操作 | x | x | x | x |
默许的规则
2) 判定表的优点和缺点
Ø 优点:它能把复杂的问题按各种可能的情况一一列举出来,简明而易于理解,也可避免遗漏。
Ø 缺点:不能表达重复执行的动作,例如循环结构。
3) B. Beizer 指出了适合使用判定表设计测试用例的条件:
Ø 规格说明以判定表形式给出,或很容易转换成判定表。
Ø 条件的排列顺序不会也不影响执行哪些操作。
Ø 规则的排列顺序不会也不影响执行哪些操作。
Ø 每当某一规则的条件已经满足,并确定要执行的操作后,不必检验别的规则。
Ø 如果某一规则得到满足要执行多个操作,这些操作的执行顺序无关紧要。
B. Beizer提出这5个必要条件的目的是为了使操作的执行完全依赖于条件的组合。其实对于某些不满足这几条的判定表,同样可以借以设计测试用例,只不过尚需增加其它的测试用例罢了。
(六)正交试验法
定义:从大量的(实验)数据(测试例)中挑选适量的,有代表性的点(例),从而合理地安排实验(测试)的一种科学实验设计方法.类似的方法有:聚类分析方法,因子方法方法等.
利用正交实验设计测试用例的步骤:
1. 提取功能说明,构造因子--状态表
把影响实验指标的条件称为因子.而影响实验因子的条件叫因子的状态.利用正交实验设计方法来设计测试用例时,首先要根据被测试软件的规格说明书找出影响其功能实现的操作对象和外部因素,把他们当作因子,而把各个因子的取值当作状态.对软件需求规格说明中的功能要求进行划分,把整体的概要性的功能要求进行层层分解与展开,分解成具体的有相对独立性的基本的功能要求.这样就可以把被测试软件中所有的因子都确定下来,并为确定个因子的权值提供参考的依据.确定因子与状态是设计测试用例的关键.因此要求尽可能全面的正确的确定取值,以确保测试用例的设计作到完整与有效。
2. 加权筛选,生成因素分析表
对因子与状态的选择可按其重要程度分别加权.可根据各个因子及状态的作用大小,出现频率的大小以及测试的需要,确定权值的大小。
3. 利用正交表构造测试数据集
正交表的推导依据Galois理论(这里省略,需要时可查数理统计方面的教材)。
利用正交实验设计方法设计测试用例,比使用等价类划分,边界值分析,因果图等方法有以下优点:节省测试工作工时;可控制生成的测试用例数量;测试用例具有一定的覆盖率。
(七)功能图法
定义:功能图由状态迁移图和布尔函数组成.状态迁移图用状态和迁移来描述.一个状态指出数据输入的位置(或时间),而迁移则指明状态的改变.同时要依靠判定表或因果图表示的逻辑功能.例,一个简化的自动出纳机ATM的功能图。
应用:
1. 功能图介绍
一个程序的功能说明通常由动态说明和静态说明组成.动态说明描述了输入数据的次序或转移的次序.
静态说明描述了输入条件与输出条件之间的对应关系.对于较复杂的程序,由于存在大量的组合情况,因此,仅用静态说明组成的规格说明对于测试来说往往是不够的.必须用动态说明来补充功能说明.功能图方法是用功能图FD形式化地表示程序的功能说明,并机械地生成功能图的测试用例.
功能图模型由状态迁移图和逻辑功能模型构成.状态迁移图用于表示输入数据序列以及相应的输出数据.在状态迁移图中,由输入数据和当前状态决定输出数据和后续状态.逻辑功能模型用于表示在状态中输入条件和输出条件之间的对应关系.逻辑功能模型只适合于描述静态说明,输出数据仅由输入数据决定.测试用例则是由测试中经过的一系列状态和在每个状态中必须依靠输入/输出数据满足的一对条件组成.功能图方法其实是是一种黑盒白盒混合用例设计方法。
(功能图方法中,要用到逻辑覆盖和路径测试的概念和方法,其属白盒测试方法中 的内容.逻辑覆盖是以程序内部的逻辑结构为基础的测试用例设计方法.该方法要求测试人员对程序的逻辑结构有清楚的了解.由于覆盖测试的目标不同,逻辑覆盖可分为:语句覆盖,判定覆盖,判定-条件覆盖,条件组合覆盖及路径覆盖.下面我们指的逻辑覆盖和路径是功能或系统水平上的,以区别与白盒测试中的程序内部的.)
2. 测试用例生成方法
从功能图生成测试用例,得到的测试用例数是可接受的. 问题的关键的是如何从状态迁移图中选取测试用例. 若用节点代替状态,用弧线代替迁移,则状态迁移图就可转化成一个程序的控制流程图形式.问题就转化为程序的路径测试问题(如白盒测试)问题了.
3. 测试用例生成规则
为了把状态迁移(测试路径)的测试用例与逻辑模型(局部测试用例)的测试用例组合起来,从功能图生成实用的测试用例,须定义下面的规则.在一个结构化的状态迁移(SST)中,定义三种形式的循环:顺序,选择和重复.但分辨一个状态迁移中的所有循环是有困难的.(其表示图形省略)。
4. 从功能图生成测试用例的过程
1) 生成局部测试用例:在每个状态中,从因果图生成局部测试用例.局部测试用例由原因值(输入数据)组合与对应的结果值(输出数据或状态)构成。
2) 测试路径生成:利用上面的规则(三种)生成从初始状态到最后状态的测试路径。
3) 测试用例合成:合成测试路径与功能图中每个状态中的局部测试用例.结果是初始状态到最后状态的一个状态序列,以及每个状态中输入数据与对应输出数据的组合。
5. 测试用例的合成算法:采用条件构造树.
(八)场景图法
定义:现在的软件几乎都是用事件触发来控制流程的,事件触发时的情景便形成了场景,而同一事件不同的触发顺序和处理结果就形成事件流。这种在软件设计方面的思想也可以引入到软件测试中,可以比较生动地描绘出事件触发时的情景,有利于测试设计者设计测试用例,同时使测试用例更容易理解和执行。
应用:
基本流和备选流:如下图所示,图中经过用例的每条路径都用基本流和备选流来表示,直黑线表示基本流,是经过用例的最简单的路径。备选流用不同的色彩表示,一个备选流可能从基本流开始,在某个特定条件下执行,然后重新加入基本流中(如备选流1和3);也可能起源于另一个备选流(如备选流2),或者终止用例而不再重新加入到某个流(如备选流2和4)。

9.3. 实例
1. 例子描述
下图所示是ATM例子的流程示意图。

2. 场景设计:下表所示是生成的场景。
表3-8 场景设计
| 场景1——成功提款 | 基本流 | |
| 场景2——ATM内没有现金 | 基本流 | 备选流2 |
| 场景3——ATM内现金不足 | 基本流 | 备选流3 |
| 场景4——PIN有误(还有输入机会) | 基本流 | 备选流4 |
| 场景5——PIN有误(不再有输入机会) | 基本流 | 备选流4 |
| 场景6——账户不存在/账户类型有误 | 基本流 | 备选流5 |
| 场景7——账户余额不足 | 基本流 | 备选流6 |
注:为方便起见,备选流3和6(场景3和7)内的循环以及循环组合未纳入上表。
3. 用例设计
对于这7个场景中的每一个场景都需要确定测试用例。可以采用矩阵或决策表来确定和管理测试用例。下面显示了一种通用格式,其中各行代表各个测试用例,而各列则代表测试用例的信息。本示例中,对于每个测试用例,存在一个测试用例ID、条件(或说明)、测试用例中涉及的所有数据元素(作为输入或已经存在于数据库中)以及预期结果。
表3-9 测试用例表
| TCID | 场景/条件 | PIN | 账号 | 输入(或选择)的金额 | 账面 金额 | ATM内的金额 | 预期结果 |
| CW1 | 场景1:成功提款 | V | V | V | V | V | 成功提款 |
| CW2 | 场景2:ATM内没有现金 | V | V | V | V | I | 提款选项不可用,用例结束 |
| CW3 | 场景3:ATM内现金不足 | V | V | V | V | I | 警告消息,返回基本流步骤6,输入金额 |
| CW4 | 场景4:PIN有误(还有不止一次输入机会) | I | V | n/a | V | V | 警告消息,返回基本流步骤 4,输入 PIN |
| CW5 | 场景4:PIN有误(还有一次输入机会) | I | V | n/a | V | V | 警告消息,返回基本流步骤 4,输入 PIN |
| CW6 | 场景4:PIN有误(不再有输入机会) | I | V | n/a | V | V | 警告消息,卡予保留,用例结束 |
4. 数据设计
一旦确定了所有的测试用例,则应对这些用例进行复审和验证以确保其准确且适度,并取消多余或等效的测试用例。
测试用例一经认可,就可以确定实际数据值(在测试用例实施矩阵中)并且设定测试数据,如表3-10所示。
表3-10 测试用例表
| TCID | 场景/条件 | PIN | 账号 | 输入(或选择)的金额(元) | 账面 | ATM内的金额(元) | 预期结果 |
| CW1 | 场景1:成功提款 | 4987 | 809-498 | 50.00 | 500.00 | 2 000 | 成功提款。账户余额被更新为450.00 |
| CW2 | 场景2:ATM内没有现金 | 4987 | 809-498 | 100.00 | 500.00 | 0.00 | 提款选项不可用,用例结束 |
| CW3 | 场景3:ATM内现金不足 | 4987 | 809-498 | 100.00 | 500.00 | 70.00 | 警告消息,返回基本流步骤6,输入金额 |
| CW4 | 场景4:PIN有误(还有不止一次输入机会) | 4978 | 809-498 | n/a | 500.00 | 2 000 | 警告消息,返回基本流步骤4,输入PIN |
| CW5 | 场景4:PIN有误(还有一次输入机会) | 4978 | 809-498 | n/a | 500.00 | 2 000 | 警告消息,返回基本流步骤4,输入PIN |
| CW6 | 场景4:PIN有误(不再有输入机会) | 4978 | 809-498 | n/a | 500.00 | 2 000 | 警告消息,卡予保留,用例结束 |
测试用例设计综合策略
1. Myers提出了使用各种测试方法的综合策略:
1) 在任何情况下都必须使用边界值分析方法,经验表明用这种方法设计出测试用例发现程序错误的能力最强。
2) 必要时用等价类划分方法补充一些测试用例。
3) 用错误推测法再追加一些测试用例。
4) 对照程序逻辑,检查已设计出的测试用例的逻辑覆盖程度,如果没有达到要求的覆盖标准,应当再补充足够的测试用例。
5) 如果程序的功能说明中含有输入条件的组合情况,则一开始就可选用因果图法。
2. 测试用例的设计步骤
1) 构造根据设计规格得出的基本功能测试用例;
2) 边界值测试用例;
3) 状态转换测试用例;
4) 错误猜测测试用例;
5) 异常测试用例;
6) 性能测试用例;
7) 压力测试用例。
3. 优化测试用例的方法
1) 利用设计测试用例的8种方法不断的对测试用例进行分解与合并;
2) 采用遗传算法理论进化测试用例;
3) 在测试时利用发散思维构造测试用例;
评论列表
内容很好,借参考,谢谢啦,已关注
支持(0)反对(0)
用你的这篇文章练一下打字,会标明出处的
支持(0)反对(0)
白盒测试常见的用例设计方法有:代码检查法、静态结构分析法、静态质量度量法、逻辑覆盖法、基本路径覆盖测试法、域测试、符号测试。
(一)代码检查法
代码检查包括桌面检查、代码审查和走查等,主要检查代码和设计的一致性,代码对标准的遵循、可读性,代码逻辑表达的正确性,代码结构的合理性等方面;发现违背程序编写标准的问题,程序中不安全、不明确和模糊的部分,找出程序中不可移植部分、违背程序编程风格的内容,包括变量检查、命名和类型审查、程序逻辑审查、程序语法检查和程序结构检查等内容。
代码检查方法:
1、代码检查法
(1)桌面检查:这是一种传统的检查方法,由程序员检查自己编写的程序。程序员在程序通过编译之后,对源程序代码进行分析、检验,并补充相关文档,目的是发现程序中的错误。由于程序员熟悉自己的程序及其程序设计风格,桌面检查由程序员自己进行可以节省很多的检查时间,但应避免主观片面性
(2)代码审查
由若干程序员和测试员组成一个审查小组,通过阅读、讨论和争议,对程序进行静态分析的过程。代码审查分两步:第一步,小组负责人提前把设计规格说明书、控制流程图、程序文本及有关要求、规范等分发给小组成员,作为审查的依据。小组成员在充分阅读这些材料后,进入审查的第二步,召开程序审查会。在会上,首先由程序员逐句简介程序的逻辑。在此过程中,程序员或其他小组成员可以提出问题,展开讨论,审查错误是否存在。实践表明,程序员在讲解过程中能发现许多原来自己没有发现的错误,而讨论和争议则促进了问题的暴露。
在会前,应当给审查小组每个成员准备一份常见错误的清单,把以往所有可能发生的常见错误罗列出来,供与会者对照检查,以提高审查的失效。这个常见的错误清单也成为检查表,它把程序中可能发生的各种错误进行分类,对每一类错误列出尽可能多的典型错误,然后把它们制成表格,供再审查时使用
(3)走查
与代码审查基本相同,分为两步,第一步也是把材料分给走查小组的每个成员,让他们认真研究程序,然后再开会。开会的程序与代码审查不同,不是简单地读程序和对照错误检查表进行检查,而是让与会者“充当”计算机,即首先由测试组成员为所测试程序准备一批有代表性的测试用例,提交给走查小组。走查小组开会,集体扮演计算机角色,让测试用例沿程序的逻辑运行一遍,随时记录程序的踪迹,供分析和讨论用。
人们借助测试用例的媒介作用,对程序的逻辑和功能提出各种疑问,结合问题开展热烈的讨论和争议,能够发现更多的问题。
代码检查应在编译和动态测试之前进行,在检查前,应准备好需求描述文档、程序设计文档、程序的源代码请当、代码编译标准和代码缺陷检查表等。在实际使用中,代码检查能快速找到缺陷,发现30%~70%的逻辑设计和编码缺陷,而且代码检查看到的问题本身而非征兆。但是代码检查非常耗费时间,而且代码检查需要知识和经验的积累。代码检查可以使用测试软件进行自动化测试,以利于提高测试效率,降低劳动强度,或者使用人工进行测试,以充分发挥人力的逻辑思维能力
2、代码检查项目
变量交叉引用表;标号的交叉引用表;检查子程序、宏、函数;等价性检查;常量检查;标准检查;风格检查;比较控制流;选择、激活路径;补充文档
根据检查项目可以编制代码规则、规范和检查表等作为测试用例,如编码规范、代码检查规范、缺陷检查表等
3、编码规范
编码规范是指程序编写过程中必须遵循的规则,一般会详细制定代码的语法规则、语法格式等
4、代码检查规范
在代码检查中,需要依据被测软件的特点,选用适当的标准与规则规范。在使用测试软件进行自动化代码检查时,测试工具一般会内置许多的编码规则。在自动化测试基础上使用桌面检查、代码走查、代码审查等人工检查的方法仔细检查程序的结构、逻辑等方面的缺陷
5、缺陷检查表
在进行人工代码检查时,代码缺陷检查表是我们用到的测试用例。
代码缺陷检查表中一般包括容易出错的地方和在以往的工作中遇到的典型错误
(二)静态结构分析法
程序的结构形式是白盒测试的主要依据。研究表明程序员38%的时间花费在理解软件系统上,因为代码以文本格式被写入多重文件中,这是很难阅读理解的,需要其它一些东西来帮助人们阅读理解,如各种图表等,而静态结构分析满足了这样的需求。
在静态结构分析中,测试者通过使用测试工具分析程序源代码的系统结构、数据结构、内部控制逻辑等内部结构,生成函数调用关系图、模块控制流图、内部文件调用关系图、子程序表、宏和函数参数表等各类图形图标,可以清晰地标识整个软件系统的组成结构,使其便于阅读和理解,然后可以通过分析这些图标,检查软件有没有存在缺陷或错误。
其中函数调用关系图通过应用程序中各函数之间的调用关系展示了系统的结构。通过查看函数调用关系图,可以检查函数之间的调用关系是否符合要求,是否存在递归调用,函数的调用曾是是否过深,有没有存在独立的没有被调用的函数。从而可以发现系统是否存在结构缺陷,发现哪些函数是重要的,哪些是次要的,需要使用什么级别的覆盖要求......
模块控制流图是与程序流程图相类似的由许多节点和连接节点的边组成的一种图形,其中一个节点代表一条语句或数条语句,边代表节点间控制流向,它显示了一个函数的内部逻辑结构。模块控制流图可以直观地反映出一个函数的内部逻辑结构,通过检查这些模块控制流图,能够很快发现软件的错误与缺陷
(三)静态质量度量法
根据ISO/IEC 9126质量模型作为基础,我们可以构造质量度量模型,用于评估软件的各个方面。该模型从上到下分为3层:质量因素(Factors)、分类标准(Criteria)和度量规则(metrics)。其中质量因素对应ISO 9126质量模型的质量特性,分类标准对应ISO 9126质量模型的子特性,度量规则用于规范软件的各种行为属性。以下例子按照可维护性进行分析。
1、度量规则
度量规则使用了代码行数、注释频度等参数度量软件的各种行为属性
2、分类标准
软件的可维护性采用以下四个分类标准来评估:可分析性(ANALYZABILITY)、可修改性(CHANGEABILITY)、稳定性(STABILITY)、可测性(TESTABILITY)。每个分类标准由一系列度量规则组成,各个规则分配一个权重,由规则的取值与权重值计算出每个分类标准的取值。
function_TESTABILITY_DRCT_CALLS+LEVL+PATH+PARA
3、质量因素
质量因素的取值与分类标准的计算方式类似:依据各分类标准取值组合权重方法计算.
function_MAINTAINABILITY=function_ANALYZABILITY
+function_CHANGEABILITY
+function_ATABILITY
+function_TESTABILITY
(四)逻辑覆盖法
逻辑覆盖是以程序内部的逻辑结构为基础的设计测试用例的技术。
根据覆盖目标的不同和覆盖源程序语句的详尽程度,逻辑覆盖又可分为:
1. 语句覆盖(SC)
2. 判定覆盖(DC)
3. 条件覆盖(CC)
4. 条件/判定覆盖(CC)
5. 条件组合覆盖(MCC)
6. 修正判定条件覆盖(MCDC)
7. 点覆盖
8. 边覆盖
9. 路径覆盖
几种逻辑覆盖标准发现错误的能力呈由弱至强的变化。
下面我们来逐一举例详解:
1语句覆盖(SC):
语句覆盖是指选择足够的测试用例,使得运行这些测试用例时,被测程序的每一个语句至少执行一次,其覆盖标准无法发现判定中逻辑运算的错误.
我们看下面的被测试代码:
int foo(int a, int b)
{
return a / b;
}
假如我们的测试人员编写如下测试案例:
TeseCase: a = 10, b = 5
测试人员的测试结果会告诉你,他的代码覆盖率达到了100%,并且所有测试案例都通过了。然而遗憾的是,我们的语句覆盖率达到了所谓的100%,但是却没有发现最简单的 Bug,比如,当我让b=0时,会抛出一个除零异常。
简言之,语句覆盖,就是设计若干个测试用例,运行被测程序,使得每一可执行语句至少执行一次。这里的“若干个”,意味着使用测试用例越少越好。
语句覆盖率的公式可以表示如下:
语句覆盖率=可执行的语句总数/被评价到的语句数量 x 100%
2判定覆盖(DC)
判定覆盖是设计足够多的测试用例,使得程序中的每一个判断至少获得一次“真”和一次“假”,即使得程序流程图中的每一个真假分支至少被执行一次。
但若程序中的判定是有几个条件联合构成时,它未必能发现每个条件的错误。
例:
int a,b;
if(a || b)
执行语句1
else
执行语句2
要达到这段程序的判断覆盖,我们采用测试用例:
1)a = true , b = false;
2)a = false, b = false
3条件覆盖(CC)
条件覆盖是指选择足够的测试用例,使得运行这些测试用例时,判定中每个条件的所有可能结果至少出现一次,但未必能覆盖全部分支.
例:
int a,b;
if(a || b)
执行语句1
else
执行语句2
要达到这段程序的条件覆盖,我们采用测试用例:
1)a = true , b = false ;
2)a = false, b = true
4判定/条件覆盖(CDC)
判定/条件覆盖是使判定中每个条件的所有可能结果至少出现一次,并且每个判定本身的所有可能结果也至少出现一次。
例:
int a,b;
if(a || b)
执行语句1
else
执行语句2
要达到这段程序的判定/条件覆盖,我们采用测试用例:
1)a = true , b = true;
2)a = false, b = false
5条件组合覆盖(MCC)
选择足够的测试用例,使得每个判定中条件的各种可能组合都至少出现一次。显然,满足“条件组合覆盖”的测试用例是一定满足“判定覆盖”、“条件覆盖”和“判定/条件覆盖”的。
例:
int a,b;
if(a || b)
执行语句1
else
执行语句2
要达到这段程序的判定/条件覆盖,我们采用测试用例:
1)a = true , b = true;
2)a = false, b = false
3)a = true, b = false
4)a = false, b = ture
6修正判定条件覆盖(MC/DC)
MC/DC首先要求实现条件覆盖、判定覆盖,在此基础上,对于每一个条件C,要求存在符合以下条件的两次计算:
1)条件C所在判定内的所有条件,除条件C外,其他条件的取值完全相同;
2)条件C的取值相反;
3)判定的计算结果相反。
核心意思是每个条件都要独立影响判定结果。为什么说“两次计算”,而不是“两个用例”呢?当循环中有判定时,一个用例下同一判定可能被计算多次,每次的条件值和判定值也可能不同,因此,一个用例就可能完成循环中判定的MC/DC。
MC/DC是条件组合覆盖的子集。条件组合覆盖要求覆盖判定中所有条件取值的所有可能组合,需要大量的测试用例,实用性较差。MC/DC具有条件组合覆盖的优势,同时大幅减少用例数。满足MC/DC的用例数下界为条件数+1,上界为条件数的两倍,例如,判定中有三个条件,条件组合覆盖需要8个用例,而MC/DC需要的用例数为4至6个。如果判定中条件很多,用例数的差别将非常大,例如,判定中有10个条件,条件组合覆盖需要1024个用例,而MC/DC只需要11至20个用例。
下面是MC/DC的示例:
代码:
int func(BOOL A, BOOL B, BOOL C)
{
if(A && (B || C))
return 1;
return 0;
}
用例:

对于条件A,用例1和用例2,A取值相反,B和C相同,判定结果分别为1和0;
对于条件B,用例1和用例3,B取值相反,A和C相同,判定结果分别为1和0;
对于条件C,用例3和用例4,C取值相反,A和B相同,判定结果分别为0和1。
9路径覆盖(PC)
MC/DC被称为“最严格的标准”,但这种说法是将条件组合覆盖和路径覆盖排除在外为基础的。MC/DC显然不如条件组合覆盖严格,但是条件组合覆盖需要太多用例,实际应用中难以做到,所以排除,那么,路径覆盖是否也难以做到?使用先进的工具,对于一般的代码,实现路径覆盖还是可能的。另外,路径代表了从函数入口到出口的所有可能的代码组合,这些组合会不会出问题?只有路径覆盖能发现,这与MC/DC侧重于判定内的条件的组合关系是完全不同的。
MC/DC与路径覆盖的侧重点不同,两者都有其优势和局限性,如果组合起来,优势互补,形成“MC/DC-路径覆盖”,就是真正意义上的“最严格的标准”了。
有些程序,路径数量可能大得惊人,可用以下规则和方法减少路径数量:
计算路径时,不考虑循环的次数,将循环结构视为循环体“至少执行一次”和“从不执行”两个分支;
不考虑条件的计算结果只考虑判定的计算结果,条件间的组合关系由条件覆盖、C/DC和MC/DC负责;
一个分支如果不可达,通过该分支的所有路径也不可达,可以让工具自动排除;
当代码很复杂时,理想的处置方式是将部分代码独立为函数,如果做不到,可以让工具来模拟,即在逻辑结构图中,将部分代码临时屏蔽,被屏蔽的代码视为一个函数调用。交替屏蔽可以既减少路径数量,又保证路径覆盖的效果。
对于一般复杂度的代码,采用以上规则和方法后,路径数量和用例数量可以维持在一个现实可覆盖的的范围内。
路径覆盖的主要缺陷是:不相关的逻辑块会组合出大量没有意义的路径。一个函数的路径,可能达到几万条甚至几百万条。如果路径超过100条,通常路径覆盖就没有意义了。对于一般企业来说,建议用MC/DC作为统一的覆盖标准,只有特别关键的代码,才要求完成“MC/DC-路径覆盖”。
路径覆盖要求设计足够多的测试用例,在白盒测试法中,覆盖程度最高的就是路径覆盖,因为其覆盖程序中所有可能的路径。
对于比较简单的小程序来说,实现路径覆盖是可能的,但是如果程序中出现了多个判断和多个循环,可能的路径数目将会急剧增长,以致实现路径覆盖是几乎不可能的。
(五)基本路径测试法
基本路径测试法是在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例的方法。
设计出的测试用例要保证在测试中程序的语句覆盖100%,条件覆盖100%。
在程序控制流图的基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例。包括以下4个步骤和一个工具方法:
1.程序的控制流图:描述程序控制流的一种图示方法。
2.程序圈复杂度:McCabe复杂性度量。从程序的环路复杂性可导出程序基本路径集合中的独立路径条数,这是确定程序中每个可执行语句至少执行一次所必须的测试用例数目的上界。
3.导出测试用例:根据圈复杂度和程序结构设计用例数据输入和预期结果。
4.准备测试用例:确保基本路径集中的每一条路径的执行。
工具方法:
图形矩阵:是在基本路径测试中起辅助作用的软件工具,利用它可以实现自动地确定一个基本路径集。
程序的控制流图:描述程序控制流的一种图示方法。
圆圈称为控制流图的一个结点,表示一个或多个无分支的语句或源程序语句
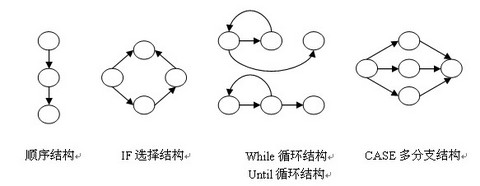
流图只有二种图形符号:
图中的每一个圆称为流图的结点,代表一条或多条语句。
流图中的箭头称为边或连接,代表控制流
任何过程设计都要被翻译成控制流图。
如何根据程序流程图画出控制流程图?
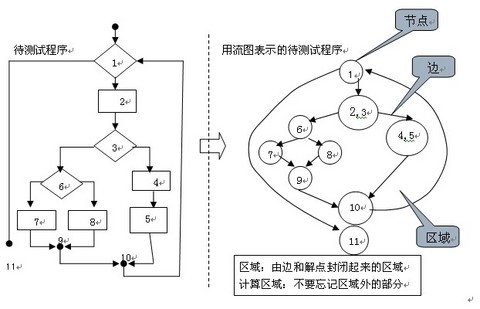
在将程序流程图简化成控制流图时,应注意:
1)在选择或多分支结构中,分支的汇聚处应有一个汇聚结点。
2)边和结点圈定的范围叫做区域,当对区域计数时,图形外的区域也应记为一个区域。
如下图所示
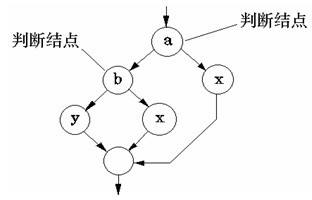
3)如果判断中的条件表达式是由一个或多个逻辑运算符 (OR, AND, NAND, NOR)连接的复合条件表达式,则需要改为一系列只有单条件的嵌套的判断。
例如:
1 if a or b
2 x
3 else
4 y
对应的逻辑为:
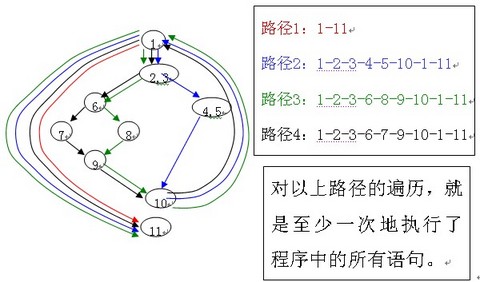
独立路径:至少沿一条新的边移动的路径
基本路径测试法的步骤:
第一步:画出控制流图
流程图用来描述程序控制结构。可将流程图映射到一个相应的流图(假设流程图的菱形决定框中不包含复合条件)。在流图中,每一个圆,称为流图的结点,代表一个或多个语句。一个处理方框序列和一个菱形决测框可被映射为一个结点,流图中的箭头,称为边或连接,代表控制流,类似于流程图中的箭头。一条边必须终止于一个结点,即使该结点并不代表任何语句(例如:if-else-then结构)。由边和结点限定的范围称为区域。计算区域时应包括图外部的范围。
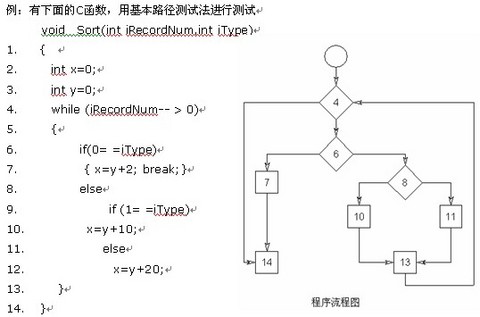
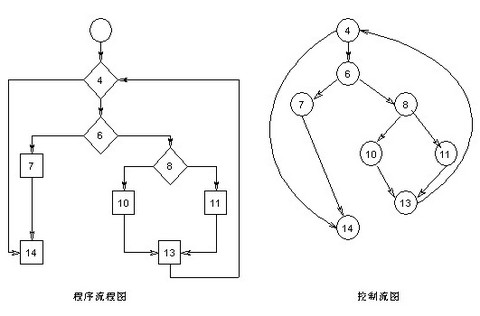
画出其程序流程图和对应的控制流图如下
第二步:计算圈复杂度
圈复杂度是一种为程序逻辑复杂性提供定量测度的软件度量,将该度量用于计算程序的基本的独立路径数目,为确保所有语句至少执行一次的测试数量的上界。独立路径必须包含一条在定义之前不曾用到的边。
有以下三种方法计算圈复杂度:
流图中区域的数量对应于环型的复杂性;
给定流图G的圈复杂度V(G),定义为V(G)=E-N+2,E是流图中边的数量,N是流图中结点的数量;
给定流图G的圈复杂度V(G),定义为V(G)=P+1,P是流图G中判定结点的数量。
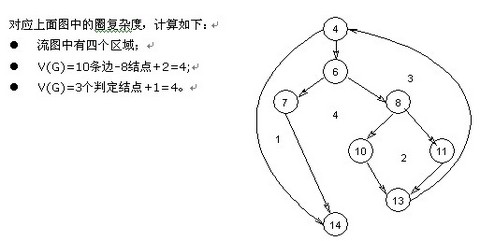
第三步:导出测试用例
根据上面的计算方法,可得出四个独立的路径。(一条独立路径是指,和其他的独立路径相比,至少引入一个新处理语句或一个新判断的程序通路。V(G)值正好等于该程序的独立路径的条数。)
ü路径1:4-14
ü路径2:4-6-7-14
ü路径3:4-6-8-10-13-4-14
ü路径4:4-6-8-11-13-4-14
根据上面的独立路径,去设计输入数据,使程序分别执行到上面四条路径。
o第四步:准备测试用例
为了确保基本路径集中的每一条路径的执行,根据判断结点给出的条件,选择适当的数据以保证某一条路径可以被测试到,满足上面例子基本路径集的测试用例是:

举例说明:
例:下例程序流程图描述了最多输入50个值(以–1作为输入结束标志),计算其中有效的学生分数的个数、总分数和平均值。
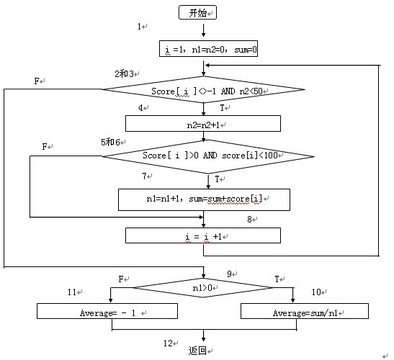
步骤1:导出过程的流图。
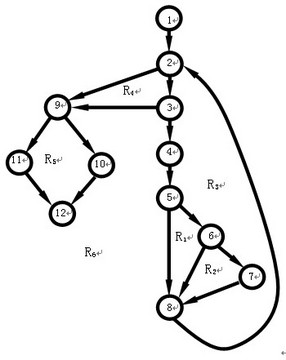
步骤2:确定环形复杂性度量V(G):
1)V(G)= 6 (个区域)
2)V(G)=E–N+2=16–12+2=6
其中E为流图中的边数,N为结点数;
3)V(G)=P+1=5+1=6
其中P为谓词结点的个数。在流图中,结点2、3、5、6、9是谓词结点。
步骤3:确定基本路径集合(即独立路径集合)。于是可确定6条独立的路径:
路径1:1-2-9-10-12
路径2:1-2-9-11-12
路径3:1-2-3-9-10-12
路径4:1-2-3-4-5-8-2…
路径5:1-2-3-4-5-6-8-2…
路径6:1-2-3-4-5-6-7-8-2…
步骤4:为每一条独立路径各设计一组测试用例,以便强迫程序沿着该路径至少执行一次。
1)路径1(1-2-9-10-12)的测试用例:
score[k]=有效分数值,当k < i ;
score[i]=–1, 2≤i≤50;
期望结果:根据输入的有效分数算出正确的分数个数n1、总分sum和平均分average。
2)路径2(1-2-9-11-12)的测试用例:
score[ 1 ]= – 1 ;
期望的结果:average = – 1,其他量保持初值。
3)路径3(1-2-3-9-10-12)的测试用例:
输入多于50个有效分数,即试图处理51个分数,要求前51个为有效分数;
期望结果:n1=50、且算出正确的总分和平均分。
4)路径4(1-2-3-4-5-8-2…)的测试用例:
score[i]=有效分数,当i<50;
score[k]<0, k< i ;
期望结果:根据输入的有效分数算出正确的分数个数n1、总分sum和平均分average。
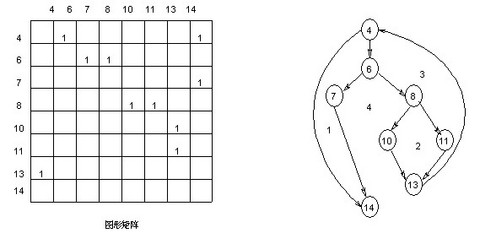
连接权为“1”表示存在一个连接,在图中如果一行有两个或更多的元素“1”,则这行所代表的结点一定是一个判定结点,通过连接矩阵中有两个以上(包括两个)元素为“1”的个数,就可以得到确定该图圈复杂度的另一种算法。
(六)域测试法
域测试是一种基于程序结构的测试方法,基于对程序输入空间(域)的分析,选择测试点进行测试。
域测试主要测试如下错误:
1)域错误:程序的控制流存在错误,对于某一特定的输入可能执行的是一条错误路径,这种错误称为路径错误,也叫做域错误。
2)计算型错误:对于特定输入执行的路径正确,但赋值语句的错误导致输出结果错误,称为计算型错误。
3)丢失路径错误:由于程序中的某处少了一个判定谓词而引起的丢失路径错误。
(七)符号测试
符号测试的基本思想是允许程序的输入不仅仅是具体的数值数据,而且包括符号值,符号值可以是基本的符号变量值,也可以是符号变量值的表达式。
接口测试用例实际
设计思路
1) 优先级--针对所有接口
1、暴露在外面的接口,因为通常该接口会给第三方调用;
2、供系统内部调用的核心功能接口;
3、供系统内部调用非核心功能接口;
2) 优先级--针对单个接口
1、正向用例优先测试,逆向用例次之(通常情况,非绝对);
2、是否满足前提条件 > 是否携带默认参值参数 > 参数是否必填 > 参数之间是否存在关联 > 参数数据类型限制 >参数数据类型自身的数据范围值限制
3) 设计分析
通常,设计接口测试用例需要考虑以下几个方面:
1、是否满足前提条件
有些接口需要满足前置条件,才可成功获取数据。常见的,需要登陆Token。
逆向用例:
针对是否满足前置条件(假设为n个条件),设计0~n条用例
2、是否携带默认值参数
正向用例:
带默认值的参数都不填写、不传参,必填参数都填写正确且存在的“常规”值,其它不填写,设计1条用例;
3、业务规则、功能需求
这里根据实际情况,结合接口参数说明,可能需要设计n条正向用例和逆向用例
5、参数是否必填
逆向用例:
针对每个必填参数,都设计1条参数值为空的逆向用例
4、参数之间是否存在关联
有些参数彼此之间存在相互制约的关系
逆向用例:
根据实际情况,可能需要设计0~n条用例
5、参数数据类型限制
逆向用例:
针对每个参数都设计1条参数值类型不符的逆向用例
6、参数数据类型自身的数据范围值限制
正向用例:
针对所有参数,设计1条每个参数的参数值在数据范围内为最大值的正向用例
逆向用例:
针对每个参数(假设n个),设计n条每个参数的参数值都超出数据范围最大值的逆向用例
针对每个参数(假设n个),设计n条每个参数的参数值都小于数据范围最小值的逆向用例
以上几个方面考虑全的话,基本可以做到如下几个方面的覆盖:
主流程测试用例:正常的主流程功能校验;
分支流测试用例:正常的分支流功能校验。
异常流测试用例:异常容错校验
4) 编写描述
尽量逻辑化,这样方便后续的维护
5) 实践操作
接口样例
获取订单列表接口(多条件)
获取店铺指定期间的所有订单列表(多种条件组合),默认根据日期倒序排序。
接口方向
客户端 -> 服务端
接口协议
接口地址:$xxx_Home/xxx/鉴权前缀/xxxxx/getAllOrderList
接口协议:JSON
HTTP请求方式:GET
消息请求
字段列表如下:
| 字段名 | 数据类型 | 默认值 | 必填项 | 备注 |
| shopId | int |
| 是 | 商铺编号 |
| token | string |
| 条件 | 设备令牌。Token鉴权方式必填 |
| dateType | int | 1 | 否 | 订单查询时间字段。 1:下单时间(order_time) 2:订单完成时间(order_finish_time) 3:结算时间(shop_settle_time) |
| startDate | date |
| 是 | 查询日期 |
| endDate | Date |
| 否 | 查询结束日期。 |
| orderStatus | String |
| 否 | 订单状态。 不填表示所有状态 多个状态之间以英文逗号分割 0:已预定 1:已开单 2:派送中 3:已完成(原已结帐) 4:退单中 5:已退单 8:自助下单 9:待确认 |
| orderTransactionType | Int |
| 否 | 订单交易状态。 不填表示所有。 1:未完成, 2:已完成(3:已完成, 5:已退单) |
| payType | int |
| 否 | 支付方式。 不填表示所有。 1:现金 2:POS 3:线上 |
| cashierId | int |
| 否 | 收银员 |
| billerId | int |
| 否 | 导购员 |
| pNo | int |
| 否 | 页码,从第1页开始,默认为1 |
| pSize | int |
| 否 | 每页记录数,默认为10 |
消息请求样例:
?shopId=1111111111&token=123411nmk515155&queryDate=2015-10-10
消息响应
字段元素如下:
| 字段名 | 数据类型 | 默认值 | 必填项 | 备注 |
| orderTotalPriceTotal | double |
| 是 | 实收金额合计(已完成的合计) |
| platformTotalIncomePriceTotal | double |
| 是 | 平台服务费合计 |
| cashPayTotal | double |
| 否 | 现金支付(已完成的合计) |
| posPayTotal | double |
| 否 | POS支付(已完成的合计) |
| onLinePayTotal | double |
| 否 | 线上支付(已完成的合计) |
| lst | object |
| 是 | 明细列表 |
明细列表对象字段元素定义:
| 字段名 | 数据类型 | 默认值 | 必填项 | 备注 |
| orderId | string |
| 是 | 订单ID |
| orderTitle | string |
| 是 | 订单标题 |
| mobile | string |
| 否 | 会员账号,如果是会员则显示手机号,为空时表示“非会员” |
| settlePrice | double |
| 是 | 交易金额 |
| orderTime | datetime |
| 是 | 下单时间 |
| serviceAmount | double |
| 是 | 平台服务费 |
| Status | Int |
| 是 | 订单状态。 0:已预定 1:已开单 2:派送中 3:已完成(原已结帐) 4:退单中 5:已退单 8:自助下单 9:待确认 |
| cashPay | double |
| 否 | 现金支付 |
| posPay | double |
| 否 | POS支付 |
| onLinePay | double |
| 否 | 线上支付 |
成功时,返回JSON数据包:
{
"code": 0,
"msg": "查询订单列表成功!",
"data": {
"pNo": 1,
"rCount": 5,
"orderTotalPriceTotal": 23.3,
"platformTotalIncomePriceTotal": 0,
"lst": [
{
"orderTitle": "kouxiangtang",
"settlePrice": 15.89,
"cashTotal": 15.89,
"posTotal": 0,
"onLineTotal": 0,
"orderTime": "2015-09-29 13:44:26",
"orderId": "12345679282015092913440268141",
"mobile": "13424183952"
},
{
"orderTitle": "红塔山",
"settlePrice": 7.5,
"cashTotal": 7.5,
"posTotal": 0,
"onLineTotal": 0,
"orderTime": "2015-09-29 11:37:58",
"orderId": "12345679282015092911370588273"
}
]
}
}
用例设计




存在问题:
如上,还没写完就有40几条用例了,要是接口参数再多点,接口数量再增加点,工作量可想而知,所以,问题来了,咋办呢?
个人见解:
1、根据接口的使用对象(外部,系统内部),有选择的去、留部分用例
2、根据接口的是否核心接口,有选择的去、留部分用例
3、根据参数说明,及实际情况,有选择的去、留部分用例
实例:
上例这个接口,是供app、商铺后台调用的,且为系统内部调用,所以,以下用例可酌情略去:
test-E-按商铺id查询-商铺id非int型
test-E-按设备token查询-token非string类型
test-E-按订单时间类型查询-时间类型非int型
test-E-按起始日期查询-时间类型非date型
test-E-按结束日期查询-时间类型非date型
test-E-按订单状态查询-订单状态非string类型
test-E-按交易状态查询-交易状态非int型
test-E-按支付方式查询-支付方式非int值
test-E-按收银员查询-收银员id非int值
test-E-按导购员查询-导购员id非int值
test-E-按页码查询-页码非int值
理由:
这个接口是给其它开发于系统内部调用的,开发过程中,开发者肯定需要调用这些接口,如果类型错了,他们也就获取不到预期的数据,这些错误,他们肯定可以发现,所以,他们传递的参数值一般能保证类型正确。
test-N-按参数类型最大值查询 所有参数
test-E-按商铺id查询-商铺id超过类型范围值
test-E-按订单状态查询-订单状态值超过类型最大值
test-E-按交易状态查询-交易状态值超过int类型最大值
略去的用例部分(参数值超过类型最大值)
理由:
1、内部调用,参数值不是外部手动输入的,输入数据长度、值大小可控,当然如果数据一直增长,那再大的类型可能都无法保证不超出,比如自动增长的商铺id
2、部分参数的参数值是自定义的,比如 订单时间类型,就那几种,除非传错了,不然不可能超出范围
最后简化后的用例数差不多28条,如果是手工测试,对于正向用例,根据等价类原理,可以制造一条数据,覆盖多条用例,当然,也可以冗余处理,即一条用例一条数据,这样的好处就是每次的验证点比较单一一点,比较有针对性。

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









