







Oracle数据库
Oracle 体系结构与基本概念
体系结构
Oracle服务器 :是一个数据管理系统(RDBMS),它提供开放的、 全面的、近乎完整的信息管理。由1个数据库和一个(或多个)实例组成。数据库位于硬盘上,实例位于内存中。
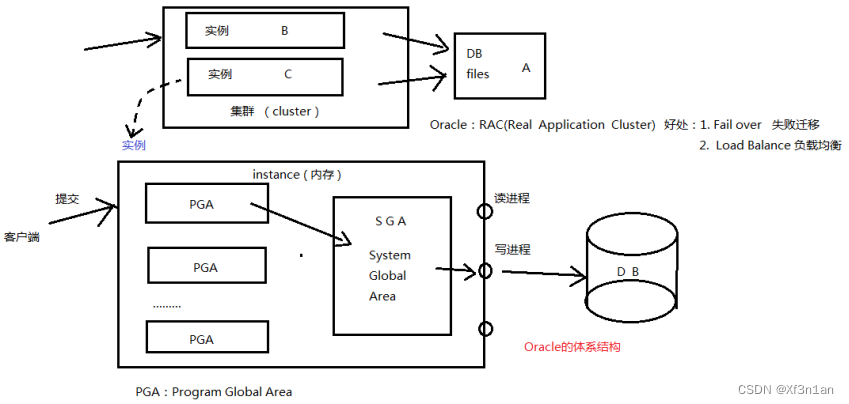
基本概念
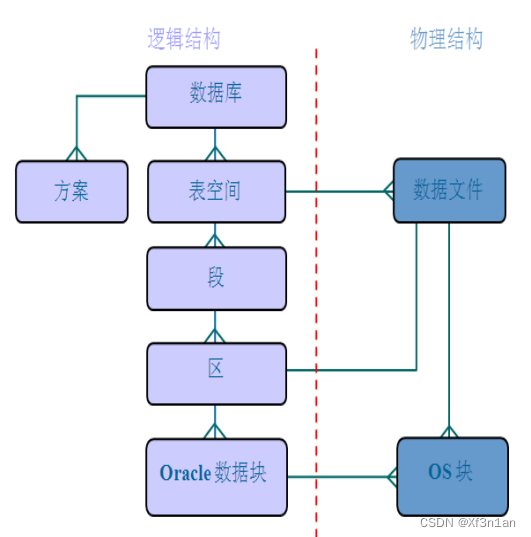
表空间(users)和数据文件
1:n(表空间:数据文件)
逻辑概念:表空间由多个数据文件组成。位于实例上,在内存中。
物理概念:数据文件,位于硬盘之上。(C:\app\Administrator\oradata\orcl目录内后缀为.DBF的文件)
一个表空间可以包含一个或者是多个数据文件。
/home/oracle/app/oradata/orcl
段、区、块

段存在于表空间中;段是区的集合;区是数据块的集合;数据块会被映射到磁盘块。
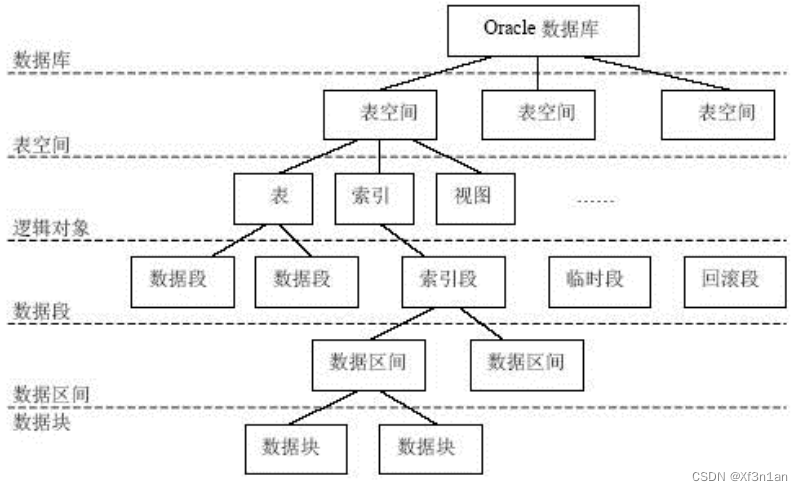
Oracle数据库的基本元素
- 方案schema
方案就是一个集合,包含多个表(tables)、视图(views)、序列(sequences)、存储过程(store procudures)、索引(indexes)、同义词(synonyms)。
oracle中每个用户都对应一个方案,方案名就是用户名。 - 表table
表示存储数据的逻辑容器,类似excel多行多列的表格。表创建的时候要定义它的每一列的列名以及该列的数据类型。(如:name char(10),表示定义列名为name类型为字符串型)
创建表之后才可以往里边添加数据。 - 视图view
从多张表或者其他视图提取出用户所关心数据的一张虚表。 - 存储过程
一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译。 - 序列sequence
是oracle提供的用于产生一系列唯一数字的数据库对象。 - 索引index
用于加快数据的检索,类似于书籍的索引。 - 同义词synonyms
别名的意思,和视图的功能类似。就是一种映射关系。
Oracle数据库启动和关闭
前提条件: 使用Oracle用户登录Linux操作系统
[root@localhost ~]# su - oracle

数据库管理员用户:
用户名:sys
密 码:sys
Oracle数据库启动
第一步: 通过数据库管理员登录Oracle数据库
[oracle@localhost ~]$ sqlplus / as sysdba;

第二步: 启动Oracle数据库
SQL> startup
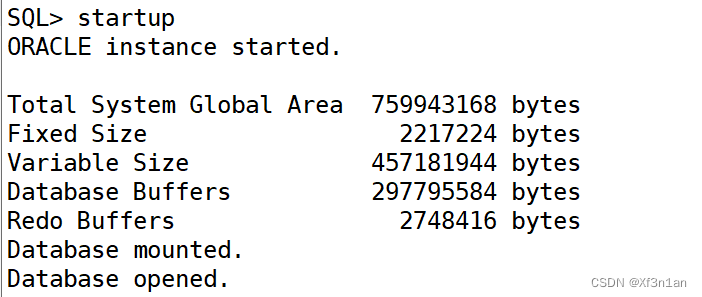
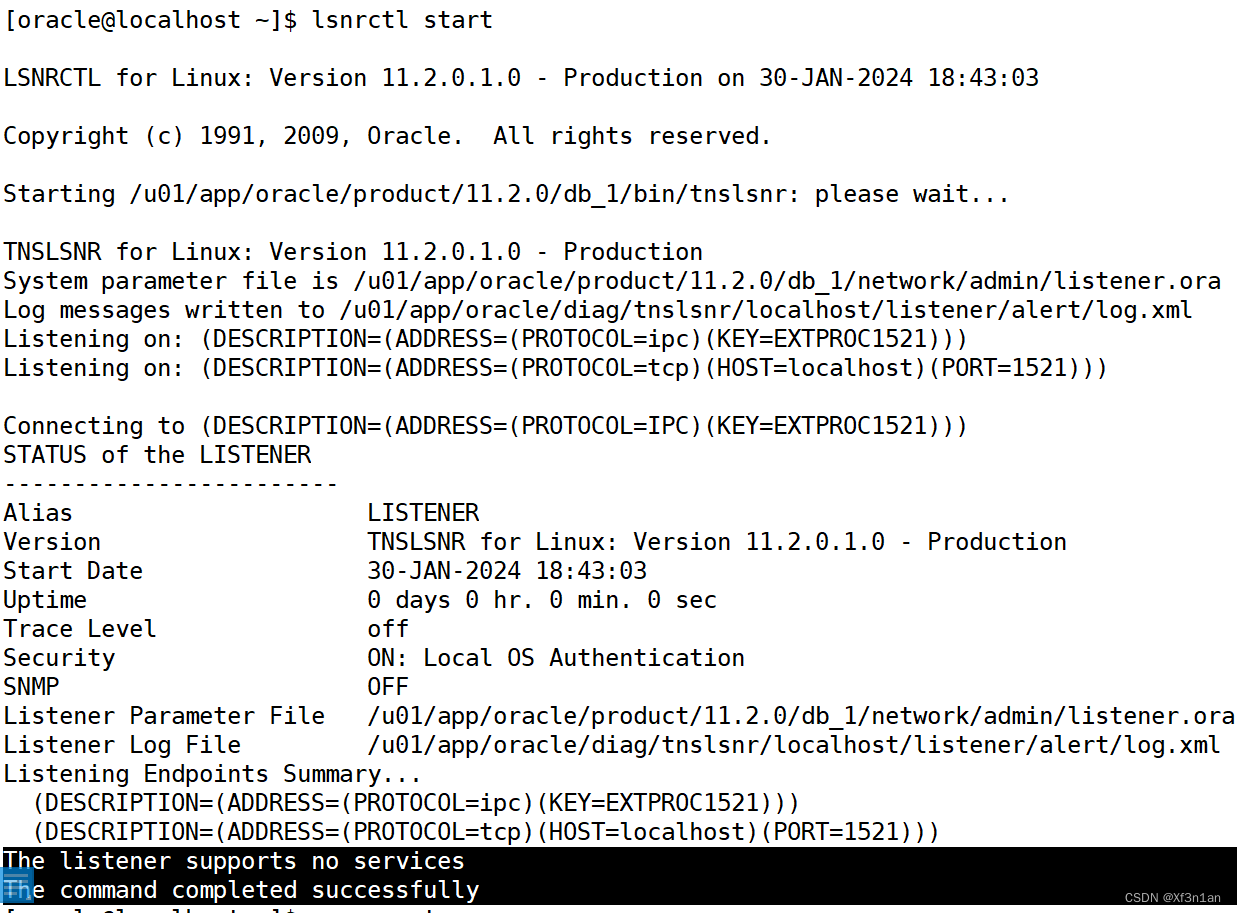
第三步: 启动监听服务
SQL> quit
[oracle@localhost ~]$ lsnrctl start
Oracle数据库关闭
第一步: 通过数据库管理员登录Oracle数据库
[oracle@localhost ~]$ sqlplus / as sysdba;
第二步: 关闭Oracle数据库
SQL> shutdown immediate

第三步: 关闭监听服务
SQL> quit
[oracle@localhost ~]$ lsnrctl stop

Sqlplus
Oracle的sqlplus是与oracle数据库进行交互的客户端工具,借助sqlplus可以查看、修改数据库记录。在sqlplus中,可以运行sqlplus命令与sql语句。
Sqlplus命令是用来修改以及调整sqlplus工具的命令。
Sql语句是用来让服务器执行相关动作的命令。
sqlplus 登录数据库管理系统
前提条件是Oracle数据库必须启动。
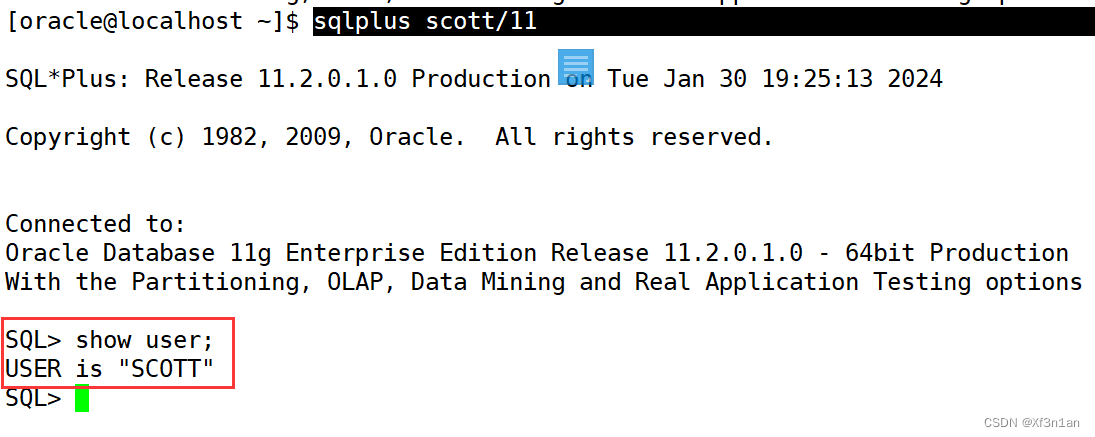
使用sqlplus登录Oracle数据库
sqlplus 用户名/密码
[oracle@localhost ~]$ sqlplus scott/11
远程登录
sqlplus 用户名/密码@//ip/实例名 ↙
远程登录oracle服务器方式,如(sqlplus scott/11@//192.168.161.130/orcl)

解锁用户
[oracle@localhost ~]$ sqlplus / as sysdba;
SQL> alter user scott account unlock;

修改用户密码
[oracle@localhost ~]$ sqlplus / as sysdba;
SQL> alter user scott identified by 11;

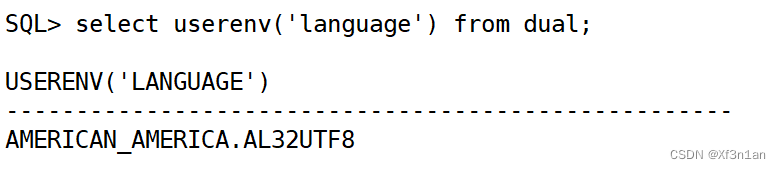
查看当前语言环境
SQL> select userenv('language') from dual;
sqlplus基本操作
前提条件是使用scott用户登录
[oracle@localhost ~]$ sqlplus scott/11
显示当前用户
SQL> show user

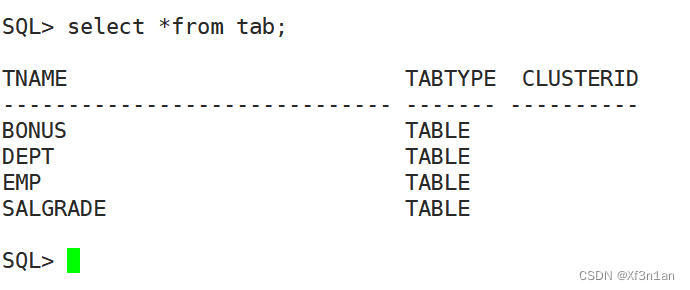
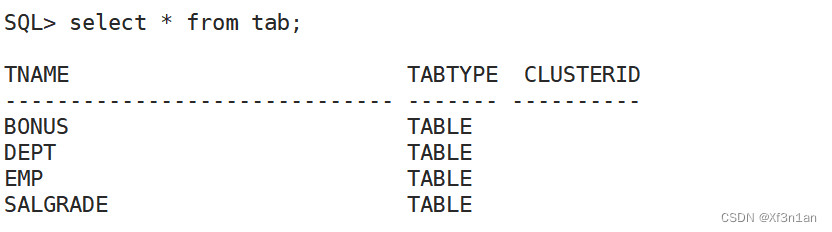
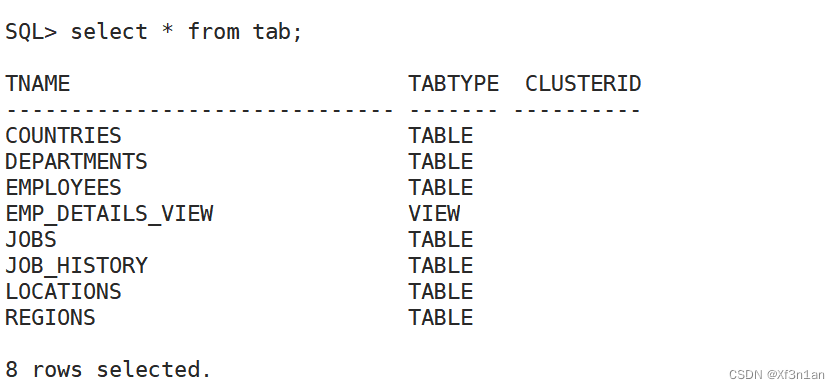
查看当前用户下的表
SQL> select *from tab;
查看员工表的结构
SQL> desc dept;

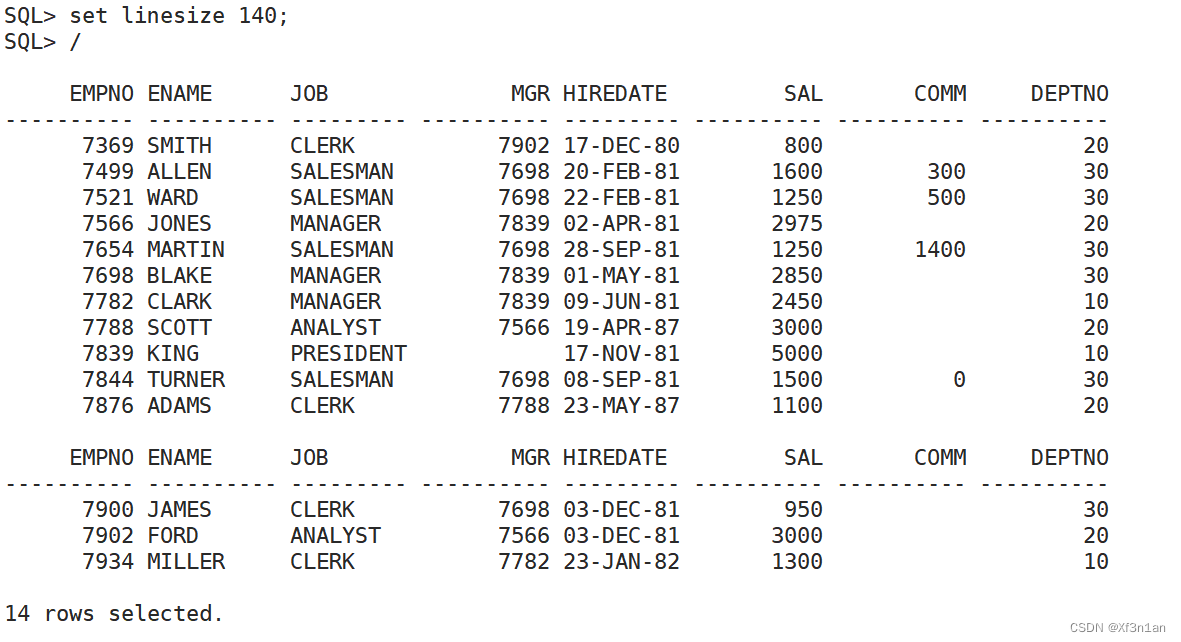
设置行宽
默认显示不好看,因此需要设置行宽。

SQL> set linesize 140;
设置页大小
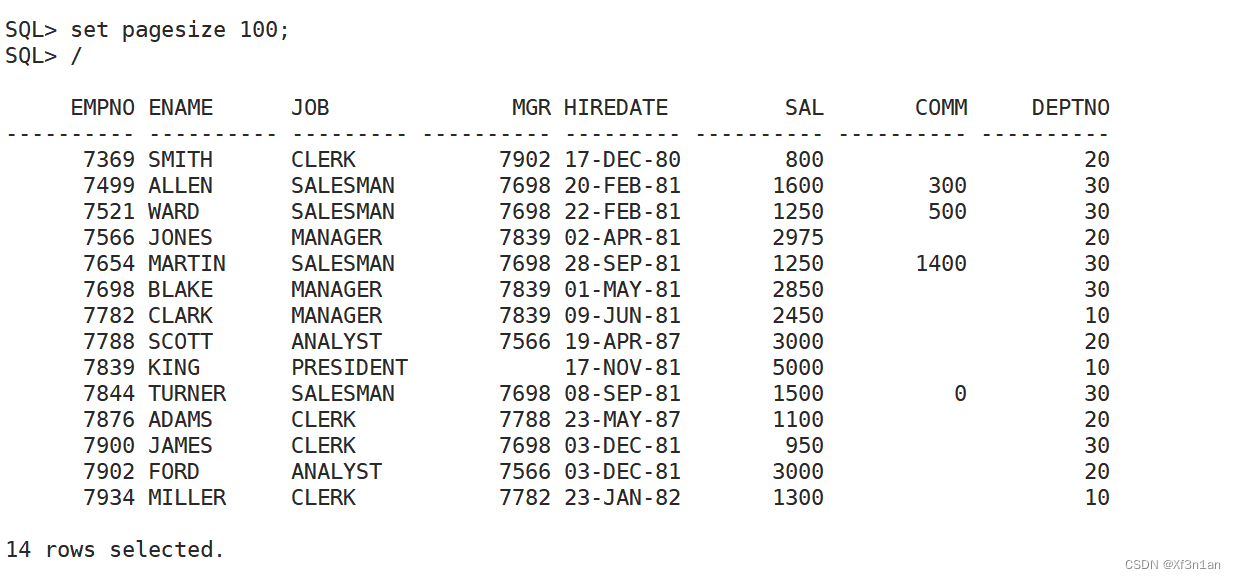
SQL> set pagesize 100;
永久设置行宽、页宽

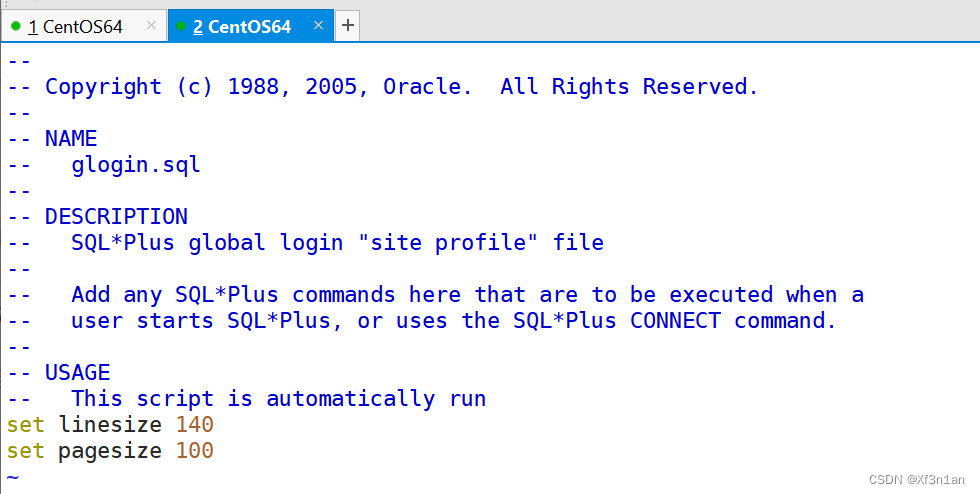
永久设置edit打开为gedit。
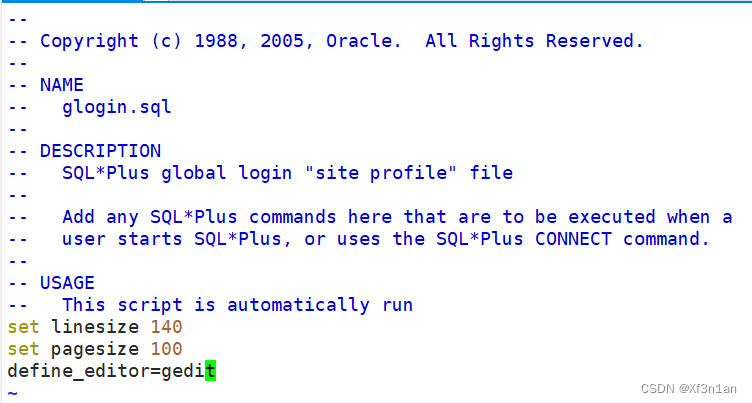
设置员工ename的列宽

SQL> col ename for a6 (a表示字符串)
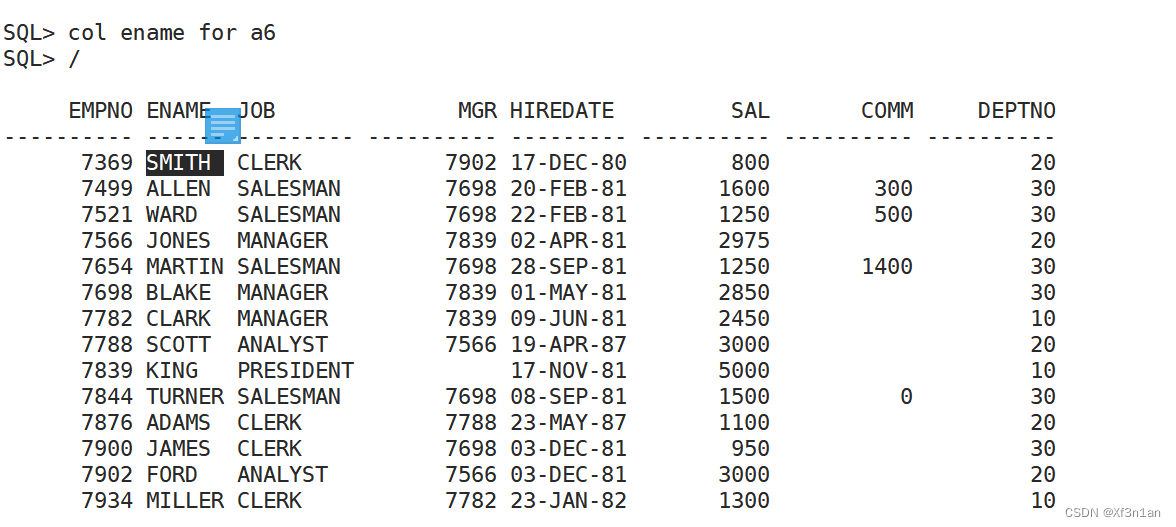
设置薪水的列宽
col sal for 9999(一个9表示一位数字)
Oracle默认方案
安装oracle数据库默认会自动创建scott和hr两个用户以及其方案,这些都是oracle提供给我们学习和练习的数据,我们直接在上边练习就好。
scott方案
业务场景
Scott(斯科特)是一家软件公司的数据分析师,公司为其提供专门的数据库管理账号以及方案。
公司有总裁一名(president)、经理(manager)、店员(clerk)、销售专员(salesman),分析师(analyst)若干。
公司设置有多个部门:会计部(accounting)、研发部(researching)、销售部(sales)。
根据公司业务抽离出的表
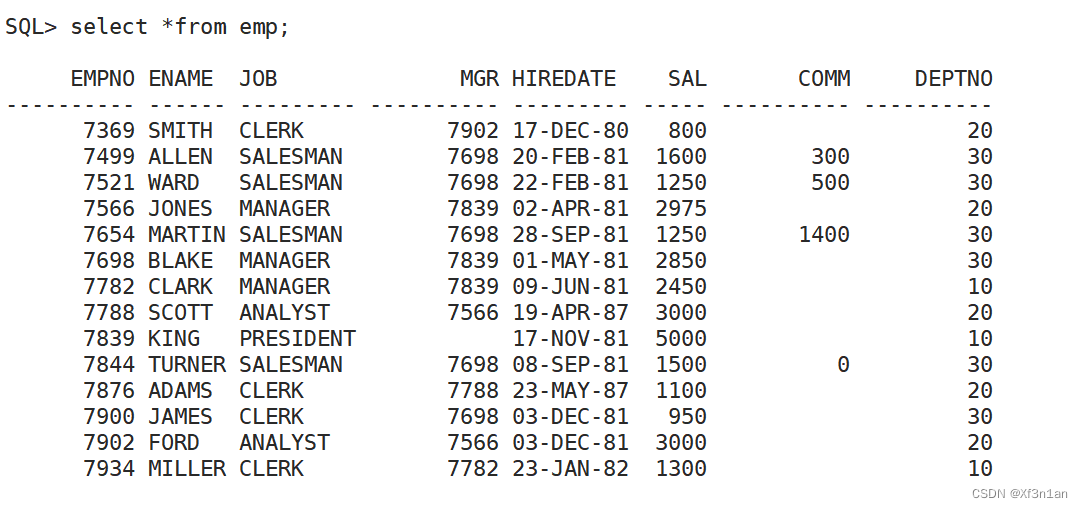
- 员工信息表EMP(Employee)
- 部门表DEPT(Department)
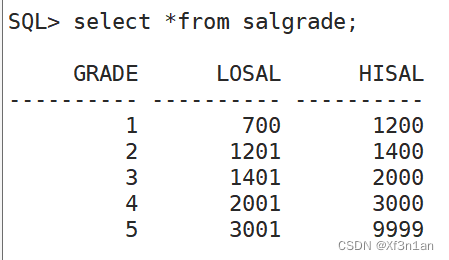
- 工资等级表(SALGRADE)
- 奖金表(BONUS)
grade: 薪水等级
losal: 最低薪水
hisal: 最高薪水
deptno: 部门编号
dname: 部门名称
loc: 部门位置

empno: 员工编号
ename: 员工姓名
job: 员工工种
mgr: 员工上司
hiredate: 雇佣日期
sal: 员工薪水
comm: 员工奖金
deptno: 员工部门编号
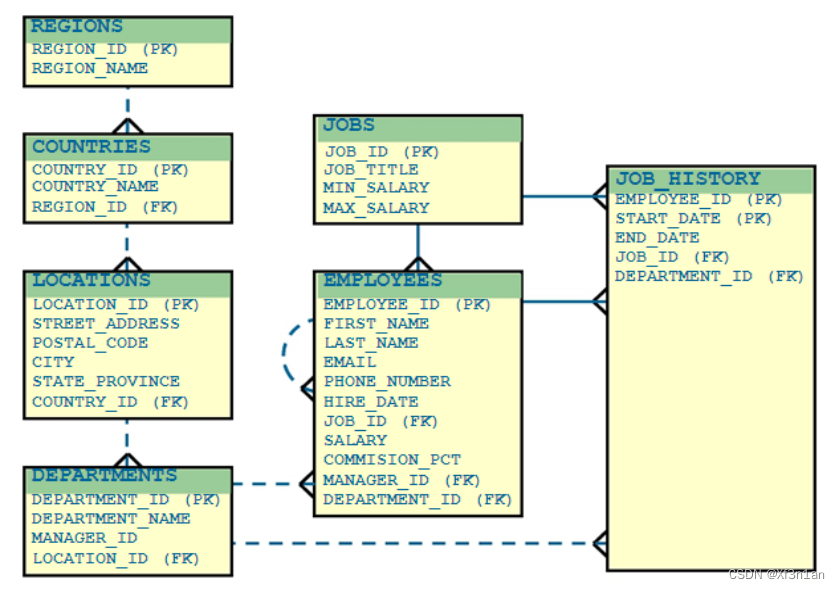
hr方案
SQL
结构化查询语言(Structured Query Language)简称SQL,是对数据库进行增、删、查、改等操作的语言。
SQL 是1986年10 月由美国国家标准局(ANSI)通过的数据库语言美国标准,接着,国际标准化组织(ISO)颁布了SQL正式国际标准。1989年4月,ISO提出了具有完整性特征的SQL89标准,1992年11月又公布了SQL92标准.
各种不同的数据库对SQL语言的支持与标准存在着细微的不同,这是因为,有的产品的开发先于标准的公布,另外,各产品开发商为了达到特殊的性能或新的特性,需要对标准进行扩展。
SQL语言的类型
DML
数据库中,称呼增删改查,为DML语句。(Data Manipulation Language 数据操纵语言),如:
增 insert
删 delete
改 update
查 select
DDL
数据定义语言(Data Definition Language)。如:
create table(创建表)
alter table(修改表)
truncate table(清空表)
drop table(删除表)
create view(视图)
create index(索引)
create sequence(序列)
create synonym(同义词)
DCL
数据控制语言(Data Control Language)。如:
commit(提交)
rollback(回滚)
基本 SELECT 语句
基本语法格式为:

语法描述说明:
花括号{}括起的部分为必填部分。
中括号[]括起来的部分为可选部分。
多种形式的语法用竖线|来表示并列单选,或者的意思。
SQL语句使用注意事项:
- SQL 语言大小写不敏感。
- SQL 可以写在一行或者多行,以分号;作为一条sql语句的结束标志。
- 关键字不能被缩写也不能分行。
- 各子句一般要分行写。
- 使用缩进提高语句的可读性。
查询案例
查询员工号、姓名、薪水
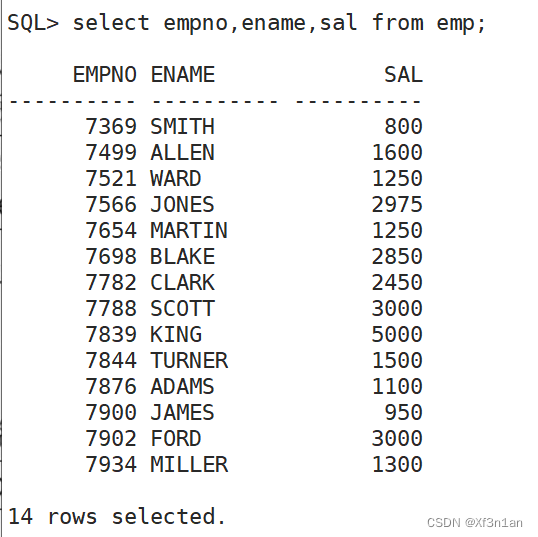
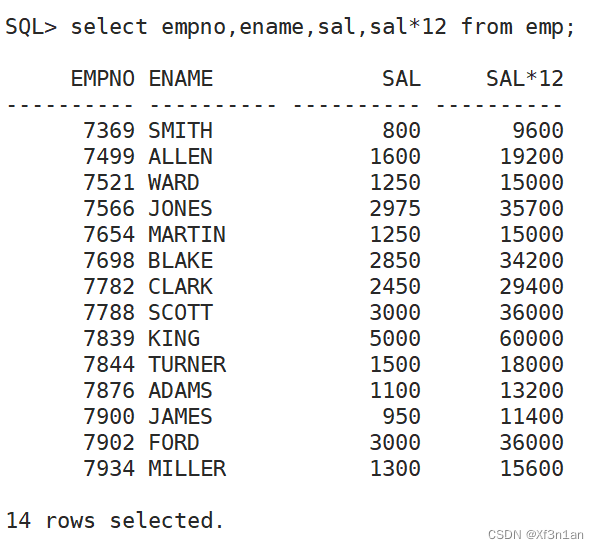
增加查询年薪(使用表达式)
别名:as
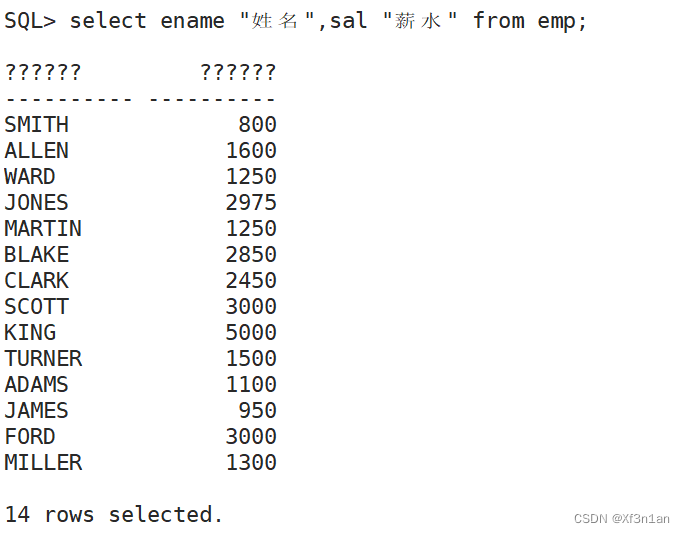
关键字as写不写都没有关系,但是如果别名中有空格,那么一定要加" "。
解决乱码问题,修改系统字符集。
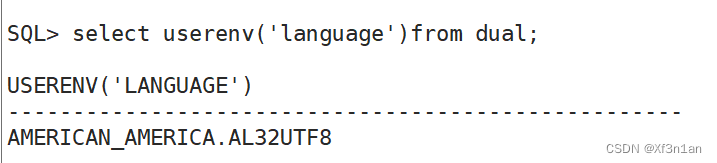
解决方法
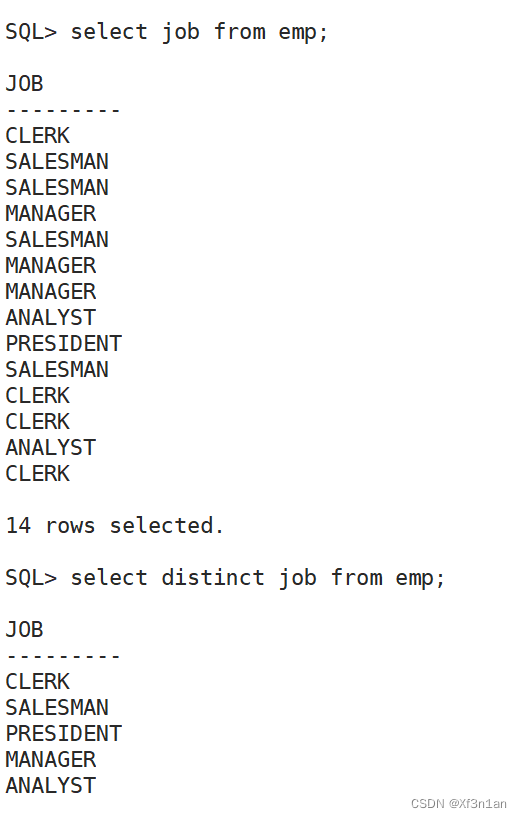
DISTINCT关键字
去除结果集重复的行。
算数运算 + - * / 和 NULL值
- 乘除的优先级高于加减
- 优先级相同时,按照从左至右运算
- 可以使用括号改变优先级
查询: 员工号、姓名、月薪、年薪、奖金、年收入。
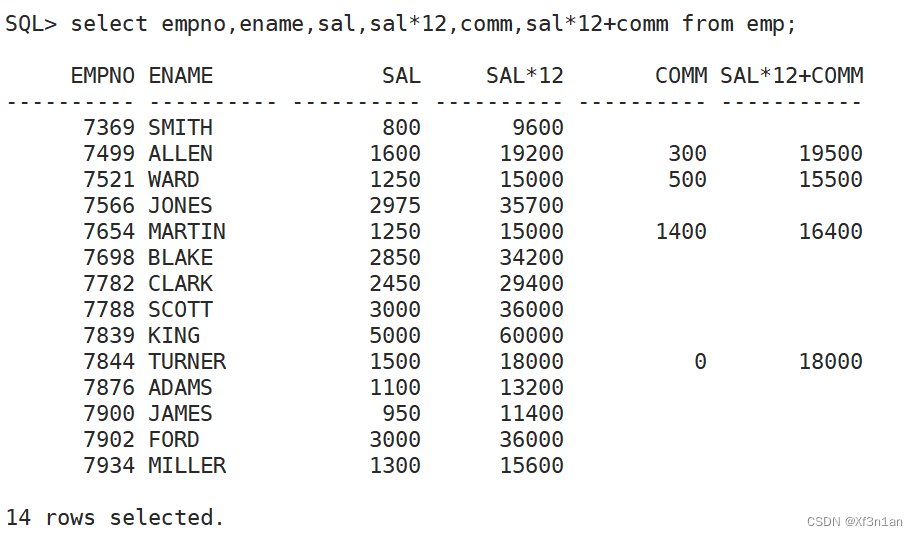
结果不正确。没有奖金的员工,年收入不正确。
NULL值问题:
包含NULL值的表达式都为空。
NULL != NULL
任何算数运算碰到NULL值都变成NULL,任何逻辑运算碰到NULL值都变成假
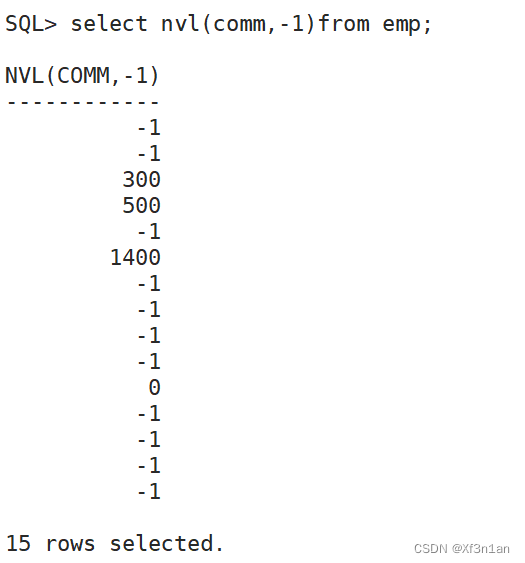
解决:滤空函数:nvl(a, b) 如果a为NULL, 函数返回b。所以:sal * 12 + nvl(comm, 0) 年收入。
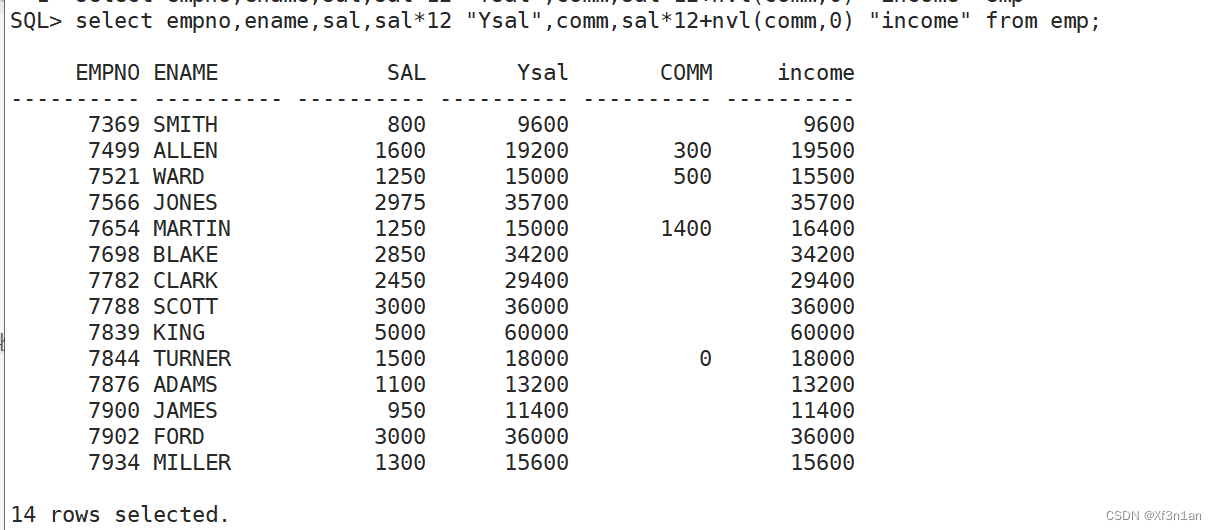
NULL != NULL举例:
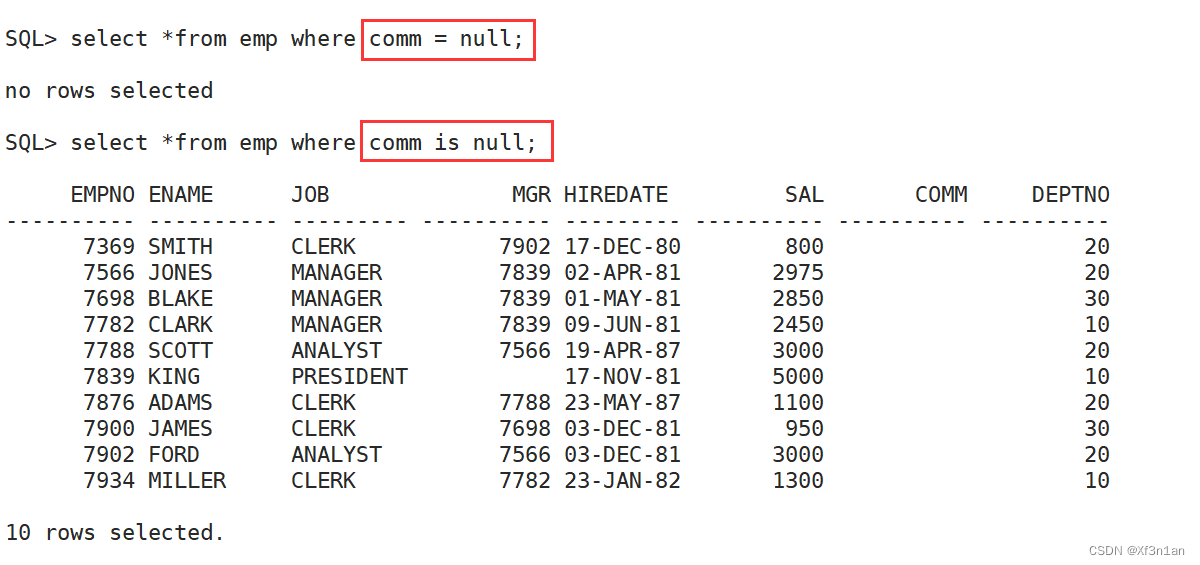
在SQL中,判断一值是否等于另外一值不用“=” 和“!=”而使用is和is not。
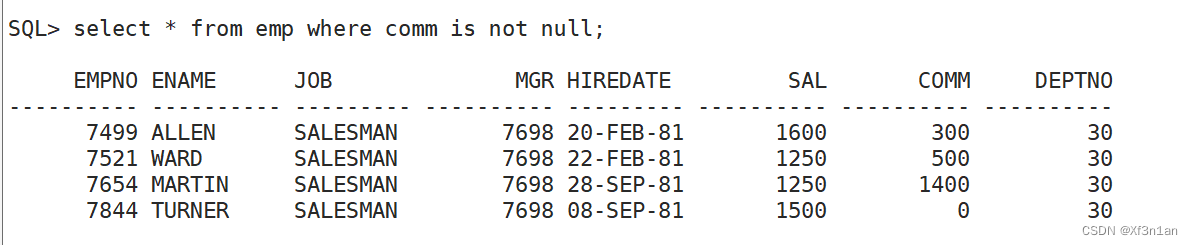
过滤和排序数据
where条件过滤
查询10号部门的员工信息

查询"KING"的信息

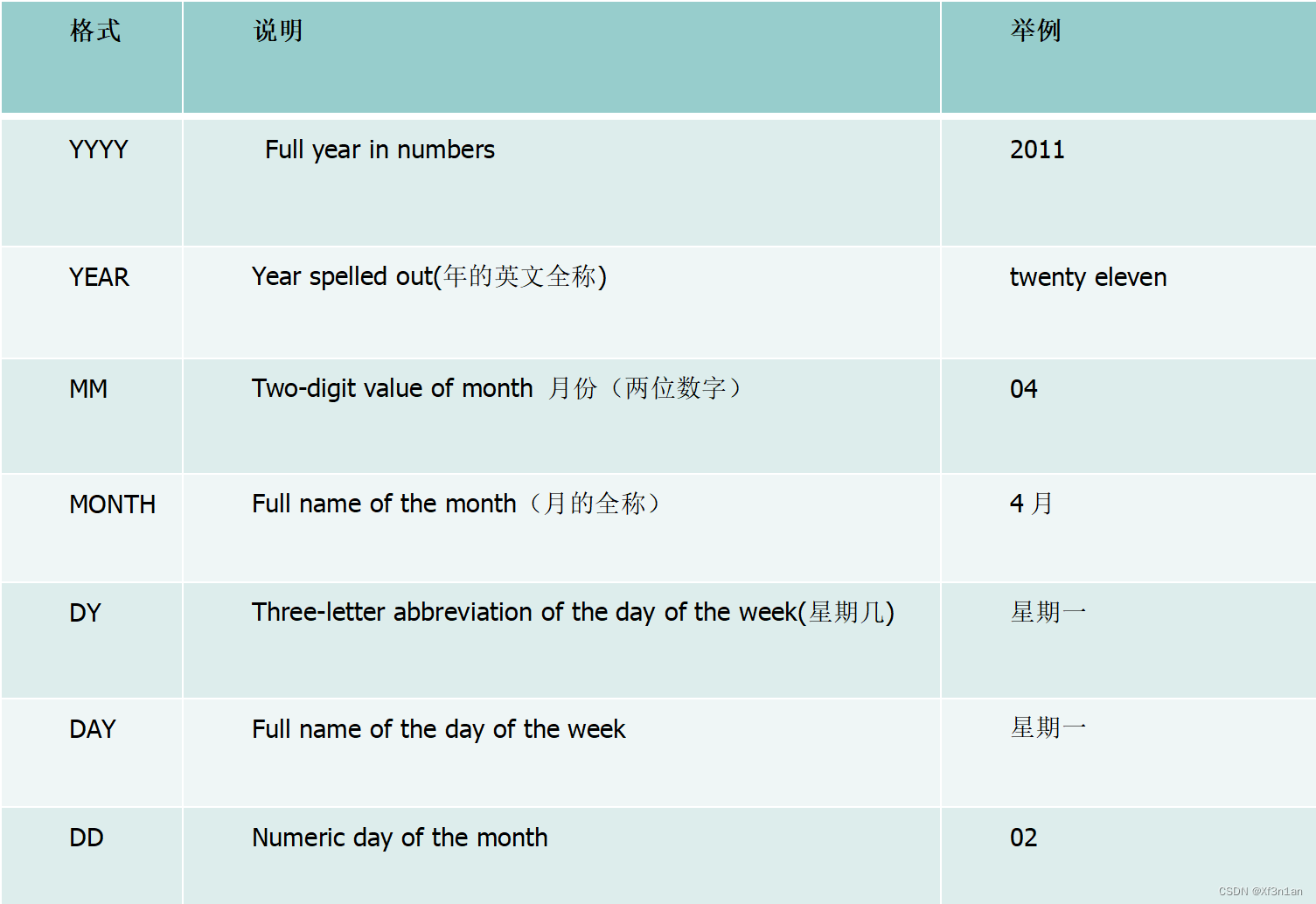
修改系统当前日期格式
查询入职日期为1981年11月17日的员工:

查看系统当前的日期格式:

获取系统当前日期格式:
SQL> select * from v$nls_parameters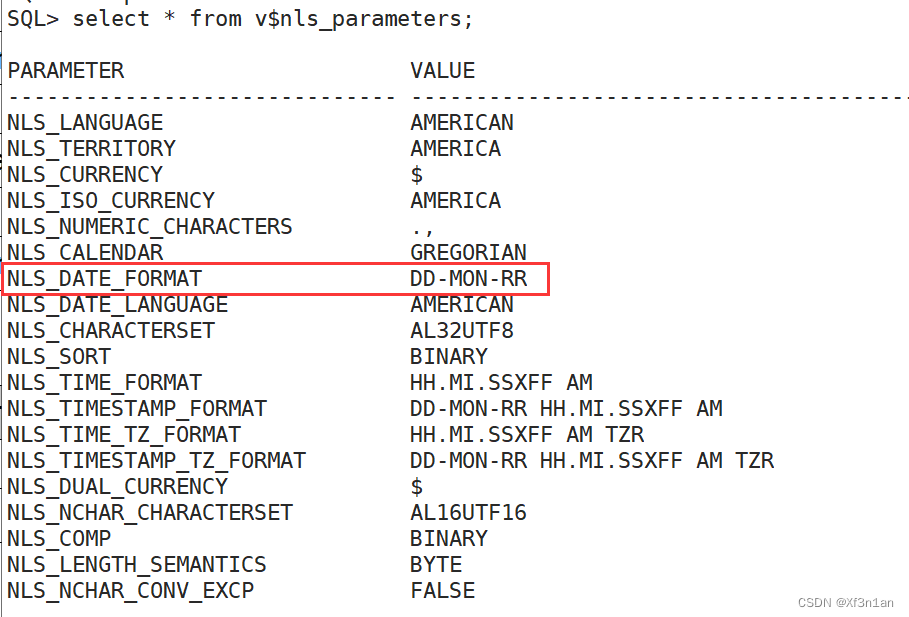
修改日期格式:
SQL> alter session set NLS_DATE_FORMAT = 'yyyy-mm-dd '

再次查询:

改回系统默认格式:SQL> alter session set NLS_DATE_FORMAT = ‘DD-MON-RR’;
比较运算
普通比较运算符:
| = 等于(不是==) | > 大于 |
| >= 大于等于 | < 小于 |
| <= 小于等于 | <> 不等于(也可以是!=) |
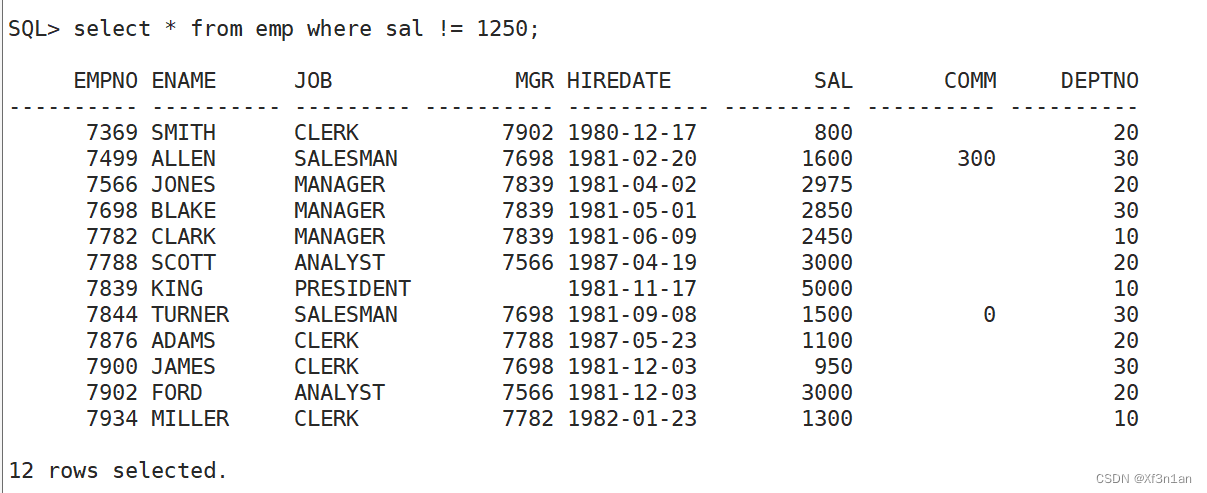
查询薪水不等于1250的员工信息:
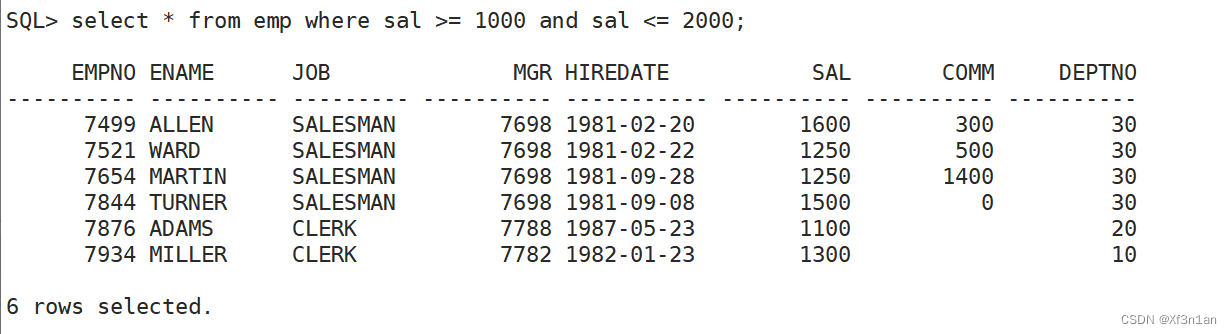
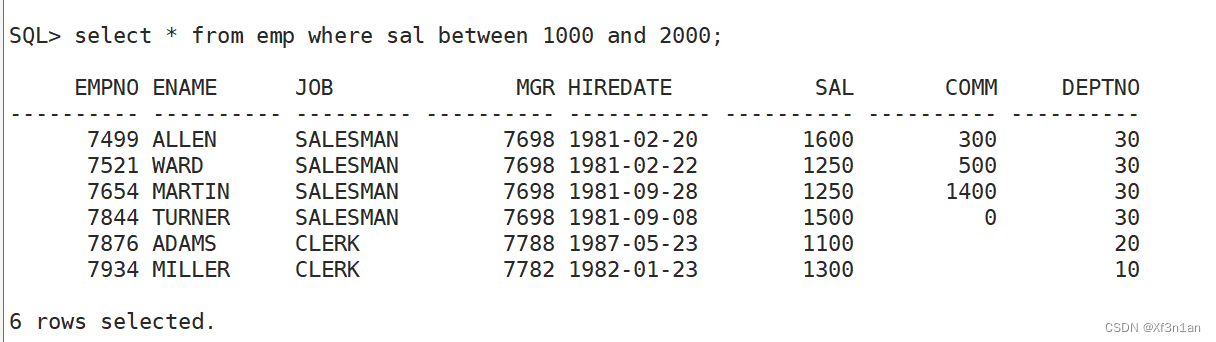
查询工资在1000-2000之间的员工:
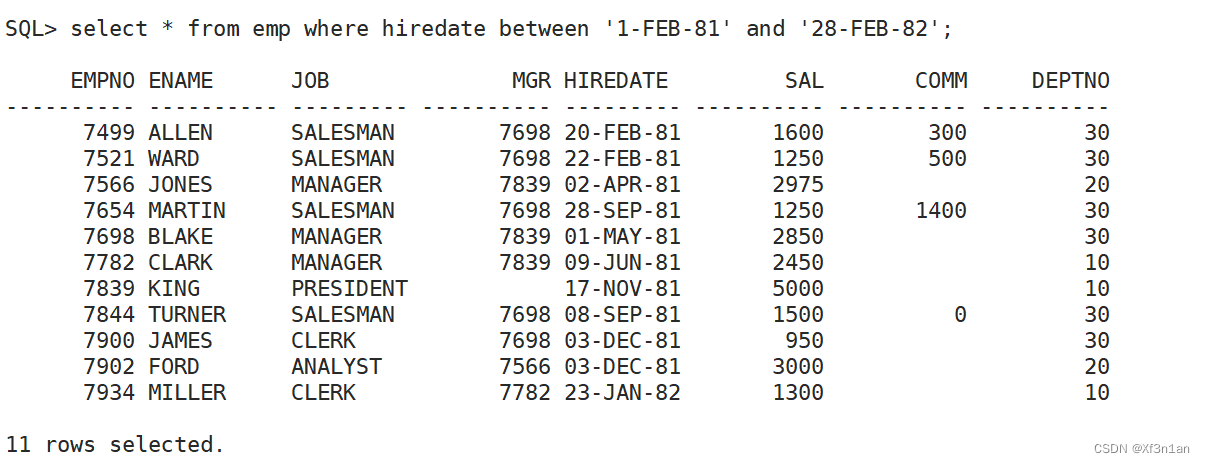
查询81年2月至82年2月入职的员工信息:
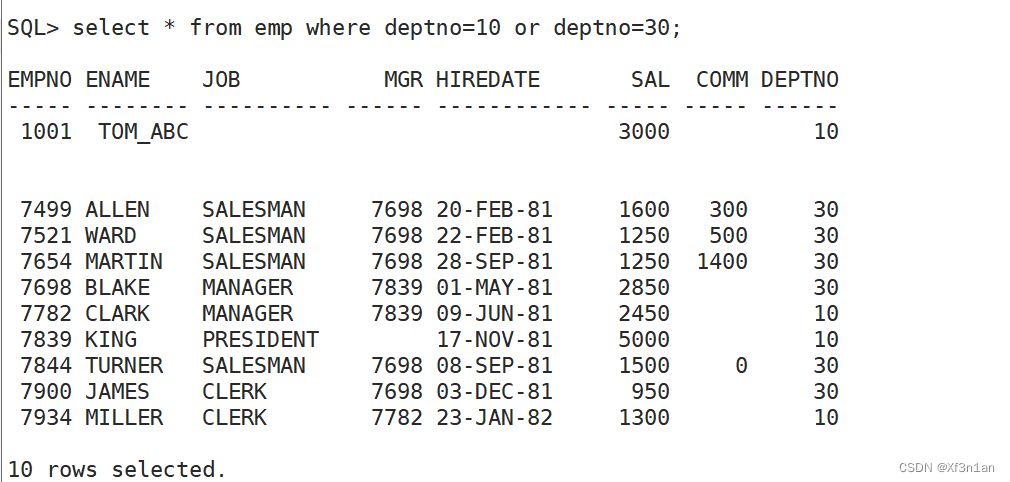
IN:在集合中。(not in 不在集合中)
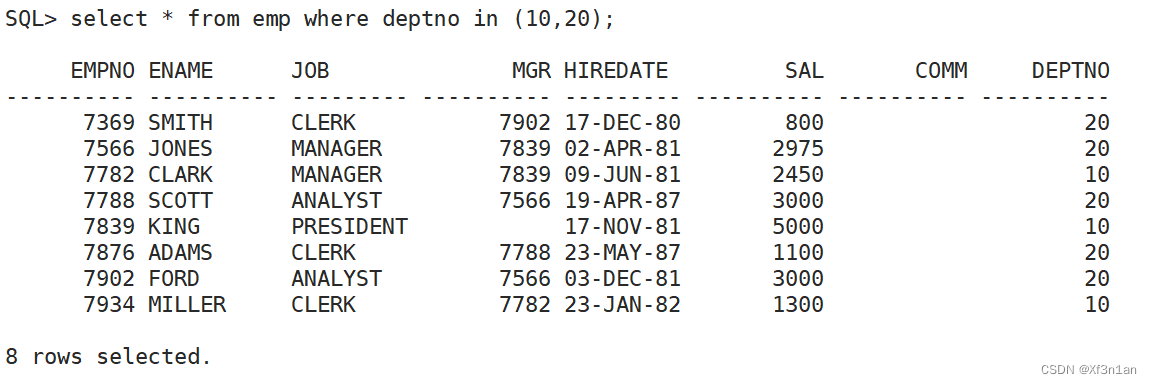
查询部门号为10或20的员工信息:

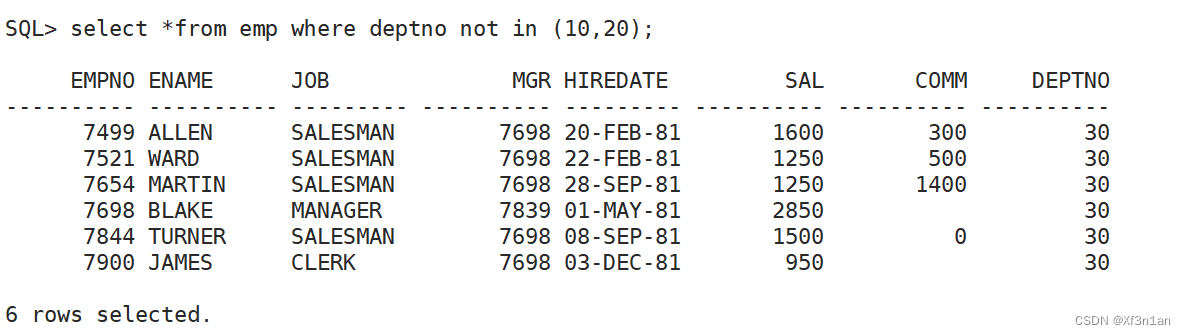
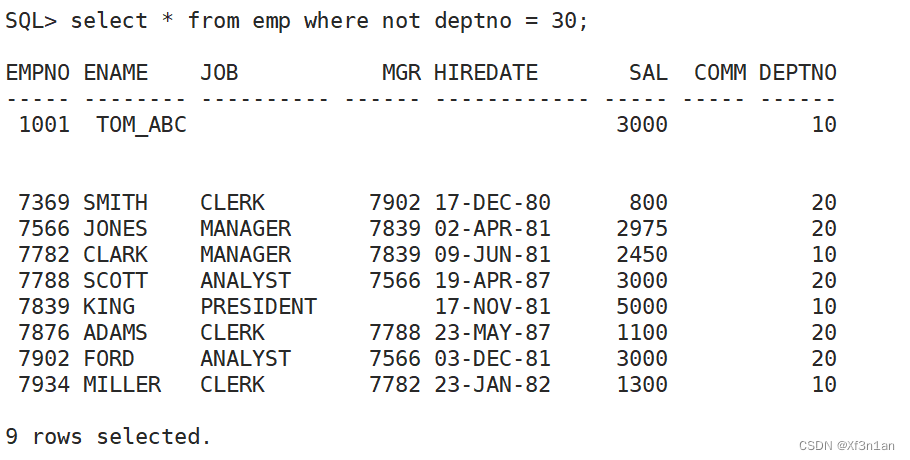
查询部门号不为10或20的员工信息:
like:模糊查询
‘%’匹配任意多个字符。
‘_’匹配一个字符。
查询名字以S开头的员工:

查询名字是4个字的员工:
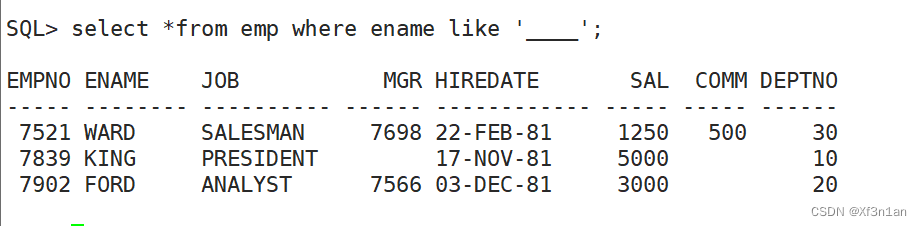
转义字符:
增加测试例子:向表中插入员工:
SQL> insert into emp(empno, ename, sal, deptno) values(1001, ’ TOM_ABC ', 3000, 10)
查询名字中包含_的员工:
SQL> select * from emp where ename like '%\_% ' escape '\';

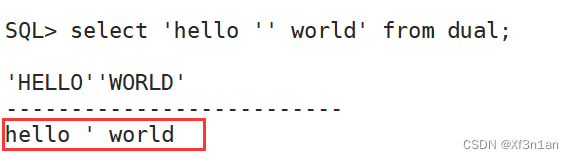
转义单引号本身:
SQL> select 'hello '' world' from dual;
字符串中包含单引号,使用两个单引号来完成转义。
逻辑运算
AND 逻辑与
OR 逻辑或
NOT 逻辑非
如果
……where 表达式1 and 表达式2;
……where 表达式2 and 表达式1;
这两句SQL语句功能一样吗?效率一样吗?
SQL在解析where的时候,是从右至左解析的。
所以and时应该将易假的值放在右侧,or时应该将易真的值放在右侧。

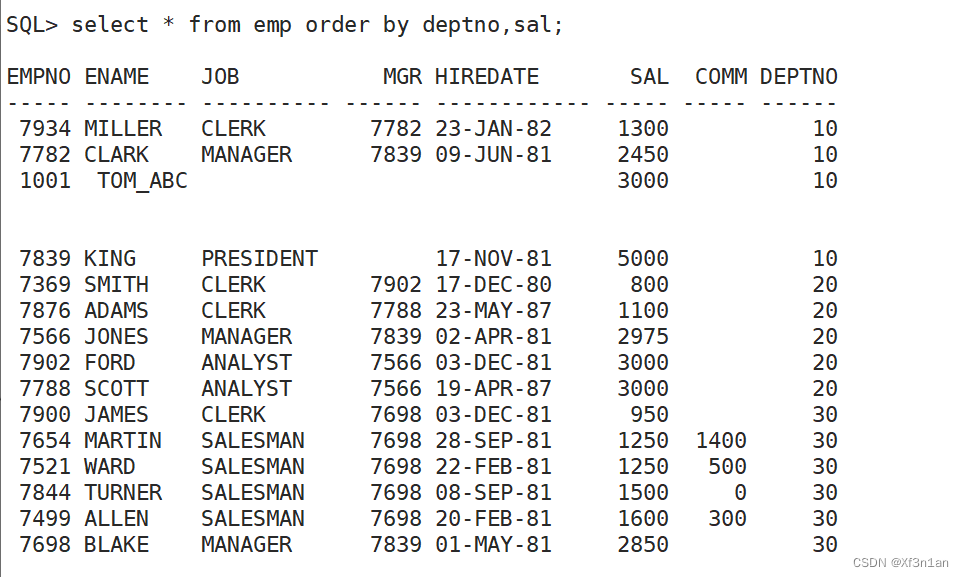
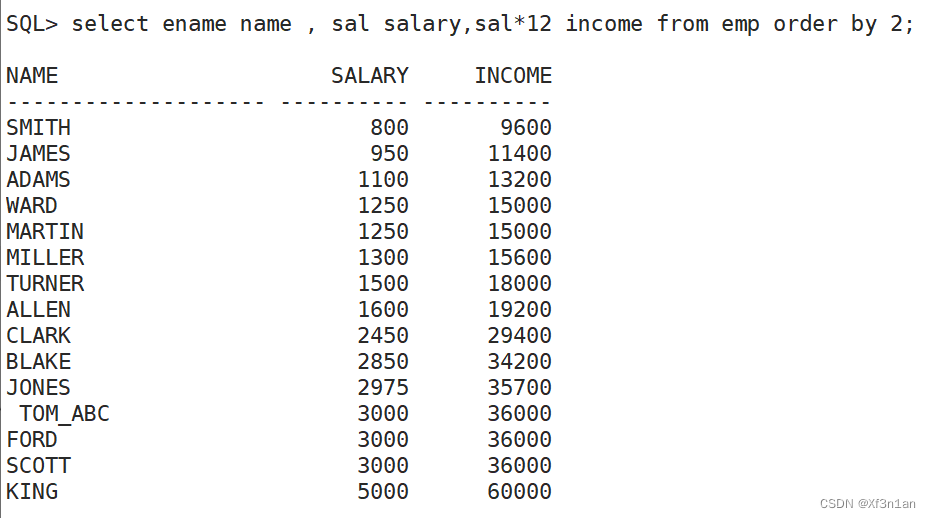
order by 排序
order by + 列名,表达式,别名,序号。 注意:语法要求order by 子句应放在select的结尾。
使用 ORDER BY 子句排序
• ASC(ascend): 升序。默认采用升序方式。
• DESC(descend): 降序
查询员工信息,按月薪排序:
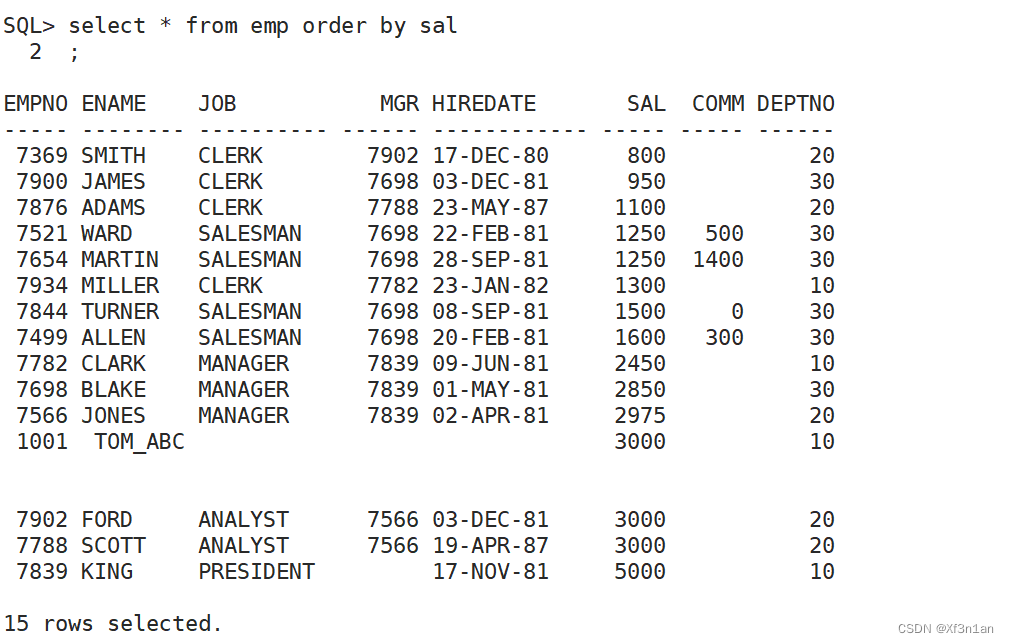
order by后有多列时,列名之间用逗号隔分,order by会同时作用于多列。
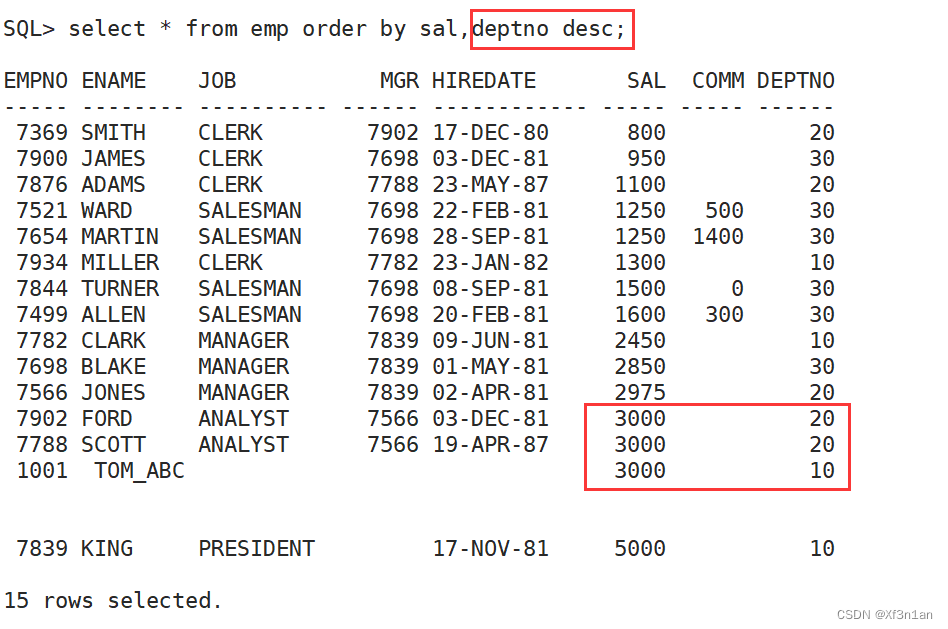
desc 只作用于最近的一列,两列都要降序排,则需要两个desc。即:

order by + 列名,表达式,别名,序号。
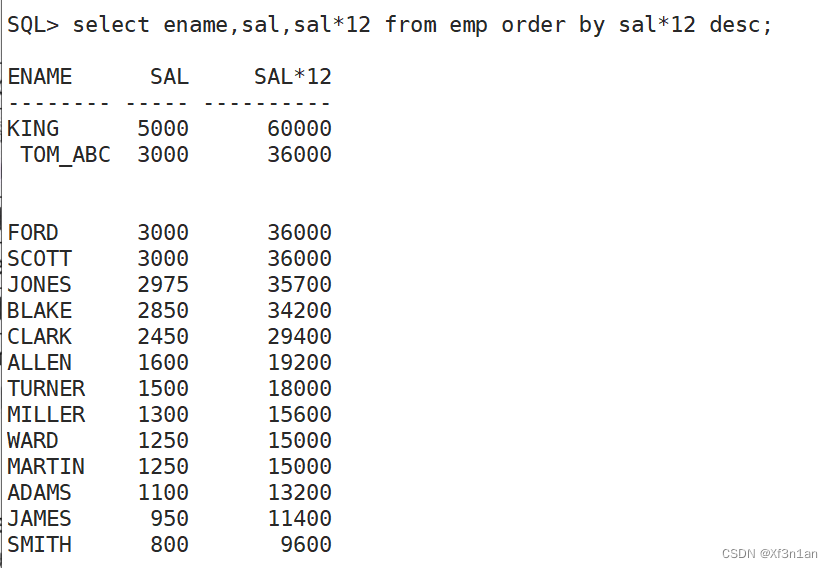
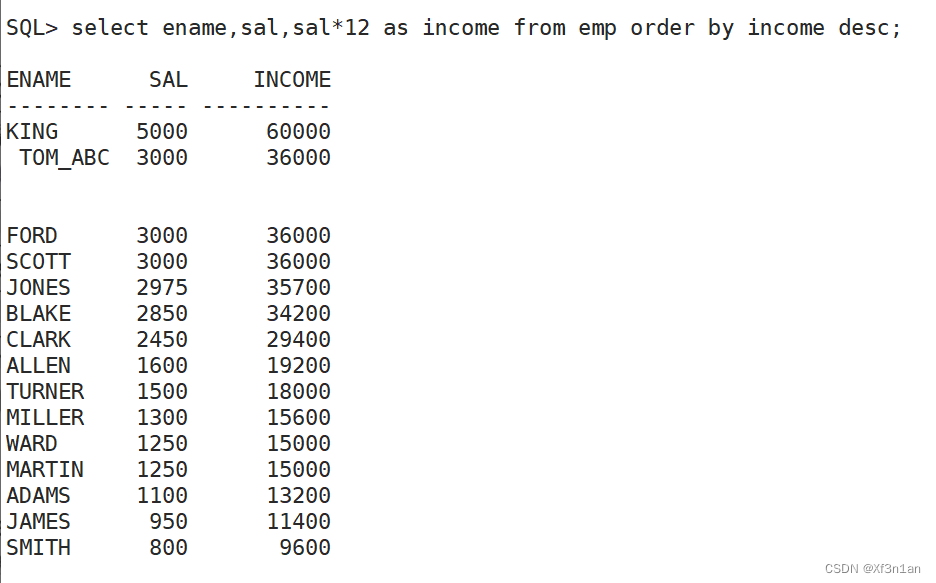
查询员工信息, 按奖金由高到低排序:

结果前面的值为NULL, 数据在后面,如果是一个100页的报表,这样显示肯定不正确。较为人性化的显示应该将空值放在最后, 即:
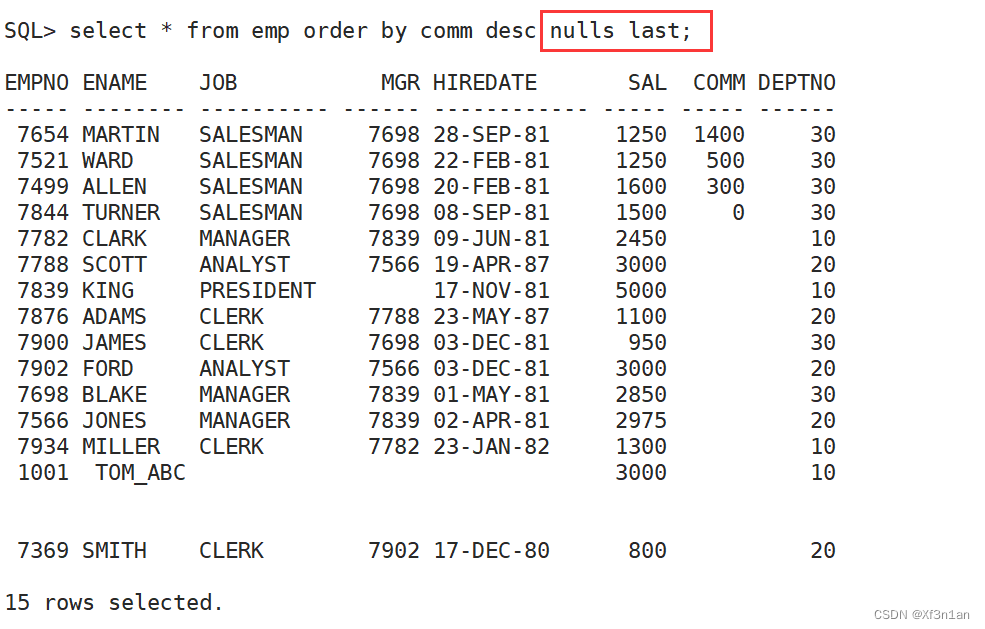
排序的规则
- 可以按照select语句中的列名排序
- 可以按照别名列名排序
- 可以按照select语句中的列名的顺序值排序
- 如果要按照多列进行排序,则规则是先按照第一列排序,如果相同,则按照第二列排序;以此类推
单行函数
单行函数:只对一行数据进行计算,产生一个结果。函数可以没有参数,但必须要有返回值。如:concat、nvl
- 操作数据对象 hello world
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以转换数据类型
- 可以嵌套
- 参数可以是一列或一个值
字符函数
操作对象是字符串。
大致可分为两大类:一类是大小写控制函数,主要有
lower 转小写

upper 转大写

initcap 首字母大写

另一类是字符控制函数:有CONCAT、SUBSTR、LENGTH/LENGTHB、INSTR、LPAD | RPAD、TRIM、REPLACE
concat(a,b):连接字符串a和b,只能连接两个

注意:SQL双引号“”表示别名,使用‘’来表示字符串。
另一种连接字符串的方法,使用||,可以做到多个字符串连接


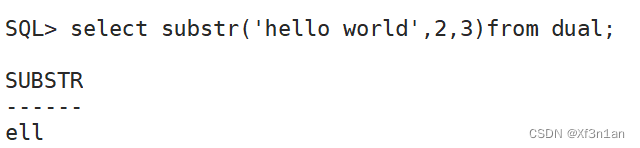
substr(a, b):从a中,第b位开始取(计数从1开始),取到结尾。

substr(a, b, c):从a中,第b位开始,向右取c位。
length:字符数, lengthb:字节数

instr:在母串中查找子串, 找到返回下标,计数从1开始。没有返回0

lpad:左填充,参1:待填充的字符串,参2:填充后字符串的总长度(字节), 参3:填充什么
rpad:右填充。

trim:去掉前后指定的字符


replace:替换


数值函数
ROUND: 四舍五入

TRUNC: 截断

MOD: 求余

时间函数
在Oracle中日期型的数据,既有日期部分,也有时间部分。下一节介绍日期部分。

显示 昨天、今天、明天:

计算员工的工龄:
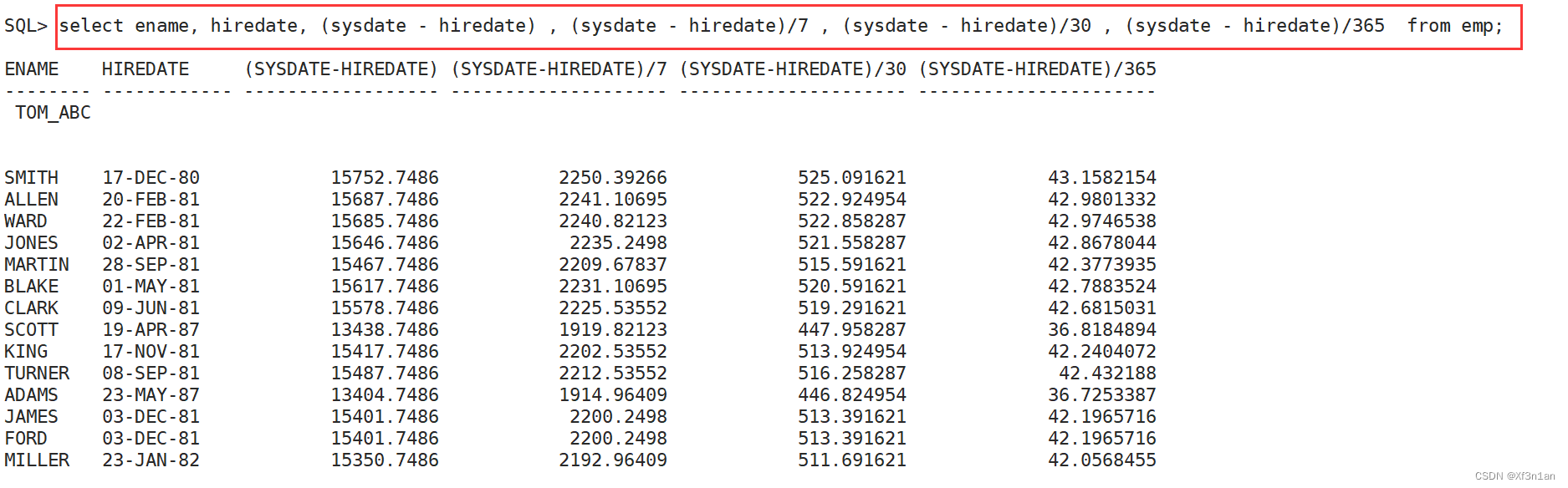
日期函数
上面求取员工工龄的结果不精确,如果想将其算准确,可以使用日期函数来做。
months_between:两个日期值相差的月数(精确值) 跟between…and无关
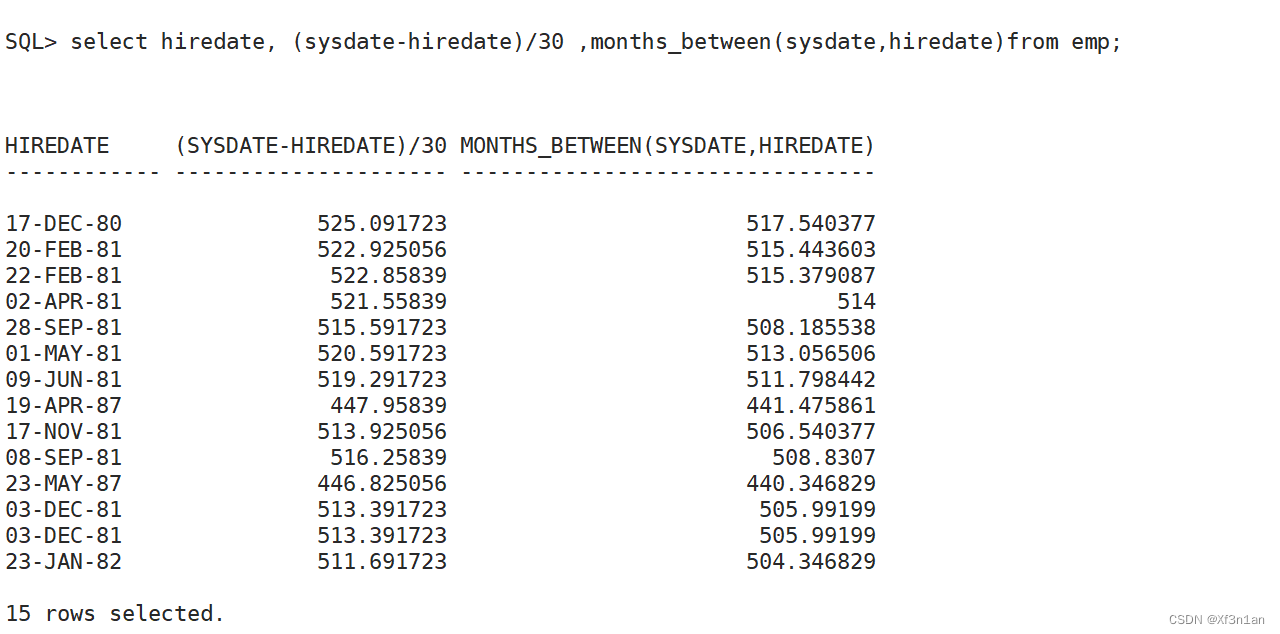
add_months:在某个日期值上,加上多少的月,正数向后计算,负数向前计算。
last_day:日期所在月的最后一天。

next_day:指定日期的下一个日期


转换函数
在不同的数据类型之间完成转换。将“123” 转换为 123。有隐式转换和显式转换之分。
隐式转换:

显式转换:
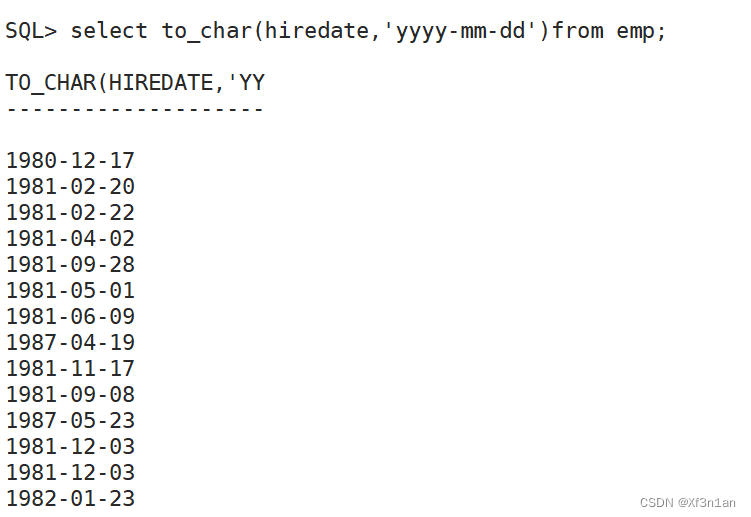
隐式转换的前提条件是:被转换的对象是可以转换的。
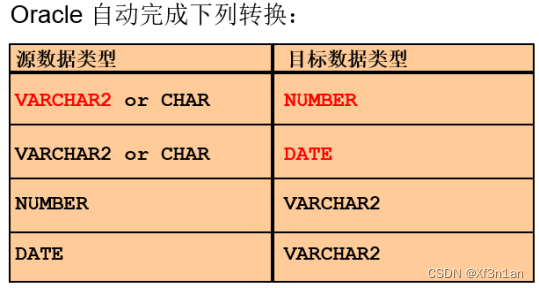
显示转换:借助to_char(数据,格式)、to_number、to_date函数来完成转换。
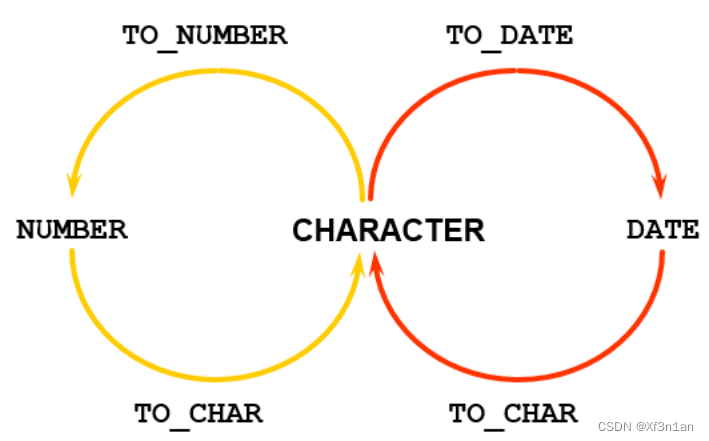

如果隐式转换和显示转换都可以使用,应该首选哪个呢?
SQL优化:如果隐式、显式都可以使用,应该首选显式,这样可以省去Oracle的解析过程。
在固定的格式里加入自定义的格式,是可以的,必须要加“”。

反向操作:已知字符串“2024-2-1 18:30:20 ”转化成日期。

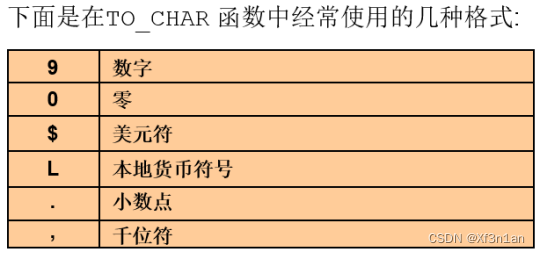
查询员工的薪水:2位小数, 本地货币代码, 千位符
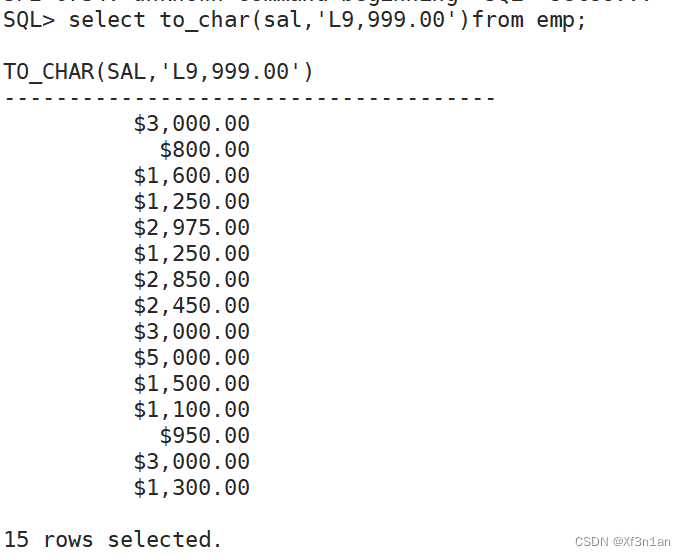
将$2,975.00转化成数字:

通用函数
这些函数适用于任何数据类型,同时也适用于空值:
-
NVL (expr1, expr2)
-
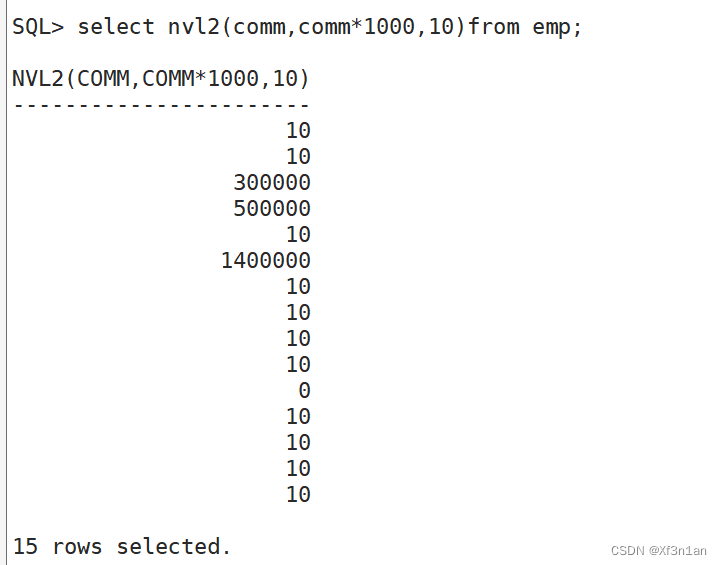
NVL2 (expr1, expr2, expr3)
-
NULLIF (expr1, expr2)
-
COALESCE (expr1, expr2, …, exprn)
nvl2: 是nvl函数的增强版。 nvl2(a, b, c) 当a = null 返回 c, 否则返回b。
nullif: nullif(a, b) 当 a = b 时返回null, 不相等的时候返回a值。

coalesce: coalesce(a, b, c, …, n) 从左向右找参数中第一个不为空的值。

条件表达式
例子:老板打算给员工涨工资, 要求:
总裁(PRESIDENT)涨1000,经理(MANAGER)涨800,其他人涨400。请将涨前、涨后的薪水列出。
但是在SQL中无法实现if else 逻辑。当有这种需求的时候,可以使用case 或者 decode
case: 是一个表达式,其语法为:
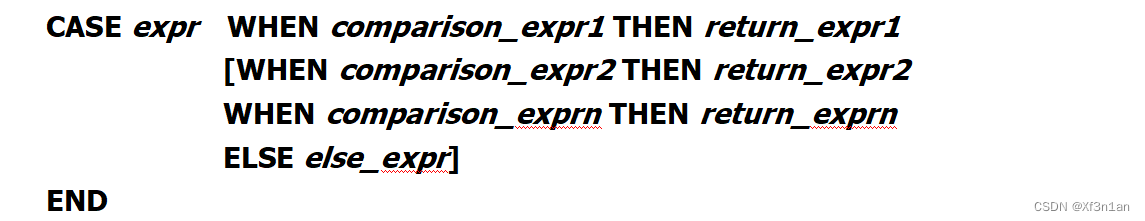

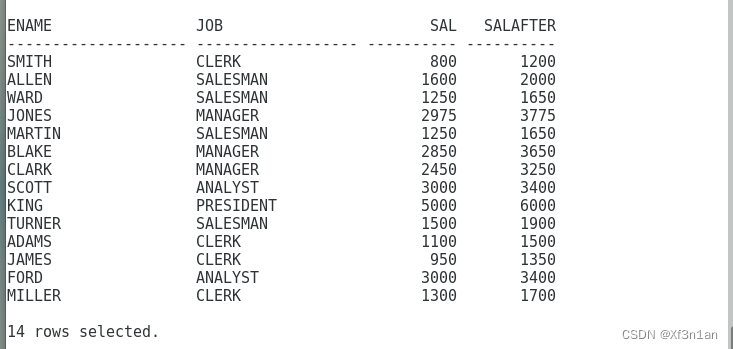
decode:是一个函数,其语法为:


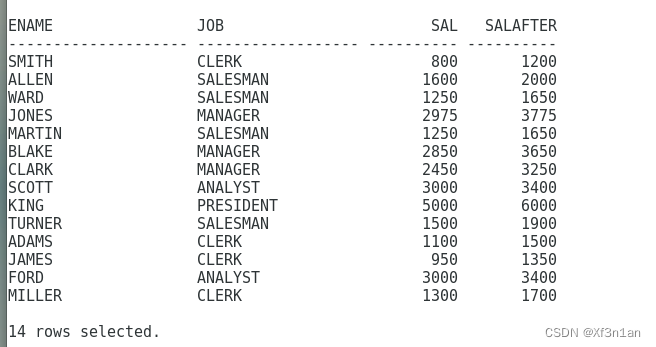
分组函数
分组函数作用于一组数据,并对一组数据返回一个值。
如:AVG、COUNT、MAX、MIN、SUM操作的是一组数据,返回一个结果。
求员工的工资总额:

员工人数:
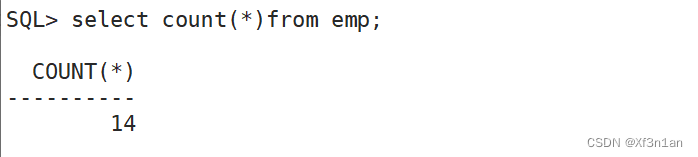
平均工资:

求员工的平均奖金:

☆NULL空值:组函数都有自动滤空功能(忽略空值),所以:

如何屏蔽 组函数 的滤空功能:

但是实际应用中,结果为14和结果为4都有可能对,看问题本身是否要求统计空值。
count函数:求个数,如果要求不重复的个数,使用distinct。
求emp表中的工种:

分组数据
group by
按照group by 后给定的表达式,将from后面的table进行分组。针对每一组,使用组函数。
查询“部门”的平均工资
SQL> select deptno,avg(sal)from emp group by deptno;

上述SQL语句可以抽象成:select a, 组函数(x) from 表 group by a; 这样的格式。
如果select a, b 组函数(x) …… group by 应该怎么写?
注意:在SELECT 列表中所有没有包含在组函数中的列,都必须在group by的后面出现。所以上问应该写成group by a, b;没有b语法就会出错,不会执行SQL语句。但,反之可以。group by a,b,c; c可以不出现在select语句中。
group by后面有多列的情况
SQL> select deptno,job,avg(sal) from emp group by deptno,job order by 1;
因为deptno, job 两列没有在组函数里面,所以必须同时在group by后面。
该SQL的语义:按部门,不同的职位统计平均工资。先按第一列分组,如果第一列相同,再按第二列分组。
所以查询结果中,同一部门中没有重复的职位。
having
使用 HAVING 过滤分组:
- 行已经被分组。
- 使用了组函数。
- 满足HAVING 子句中条件的分组将被显示。
语法:

查询平均薪水大于2000的部门
分析:该问题实际上是在分组的基础上过滤分组。
SQL> select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;

注意:
不能在 WHERE 子句中使用组函数。
可以在 HAVING 子句中使用组函数。
从功能上讲,where和having都是将满足条件的结果进行过滤。但是差别是where子句中不能使用 组函数!
所以上句中的having不可以使用where代替。
求10号部门的平均工资

在子句中没有使用组函数的情况下,where、having都可以,应该怎么选择?
SQL优化: 尽量采用where。
如果有分组的话,where是先过滤再分组,而having是先分组再过滤。当数据量庞大如1亿条,where优势明显。
多表查询
多表查询的过程中其实就会构造多个表的一个笛卡尔积。
笛卡尔积
笛卡尔积就是两个集合的乘积计算,其实跟我们普通的乘法分配律相像,不过是作用于集合:
如果有一个集合M(a,b) 和集合N(c,d) , 那么集合的乘积
M x N = (a,b) x (c,d)= ( a x (c,d), b x (c,d) ) = ( ac,ad,bc,bd)
具体到我们的数据库表如下:
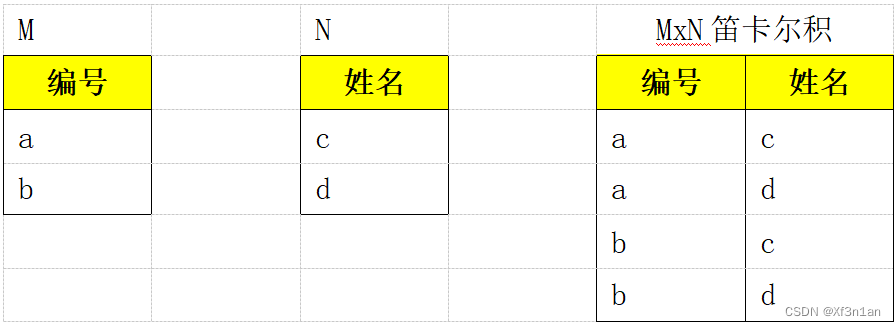
笛卡尔积的行数 = table1的行数 x table2的行数
笛卡尔积的列数 = table1的列数 + table2的列数
比如:
select * from emp,dept; 会得到如下的一个表
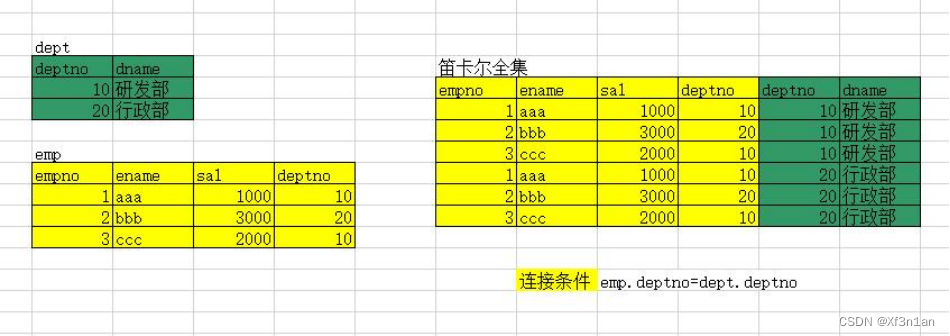
多表查询就是按照给定条件(连接条件),从笛卡尔全集中选出正确的结果。
比如上图理应该两个deptno 相同的数据才是有意义的数据。
根据连接条件的不同可以划分为:等值链接、不等值链接、外链接、自连接 。

等值连接
从概念上,区分等值连接和不等值连接非常简单,只需要辨别where子句后面的条件,是“=”为等值连接。不是“=”为不等值连接。
查询员工信息:员工号 姓名 月薪和部门名称
通常在进行多表查询的时,会给表起一个别名,使用“别名.列名”的方式来获取数据,直接使用“表名.列名”语法上是允许的,但是实际很少这样用。
SQL> select e.empno,e.ename,e.sal,e.deptno,d.dname,d.deptno from emp e , dept d where e.deptno= d.deptno;
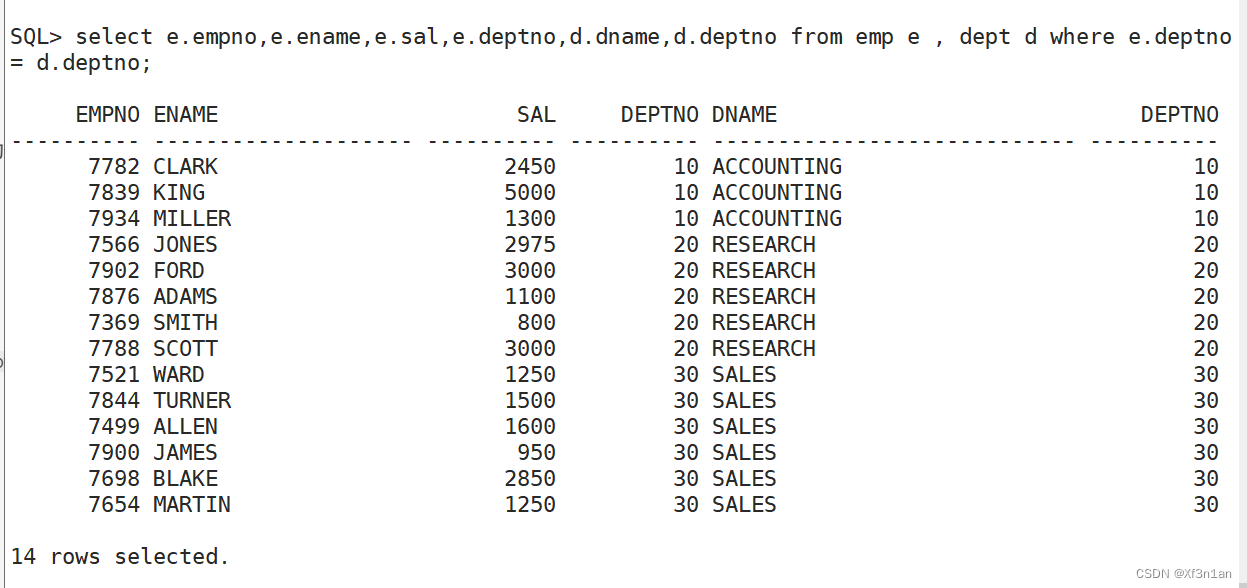
如果:select e.empno, e.ename, e.sal, e.deptno, d.dname, d.deptno from emp e, dept d;
直接得到的是笛卡尔全集。其中有错误结果。所以应该加 where 条件进行过滤。
如果有N个表,where后面的条件至少应该有N-1个。
不等值连接
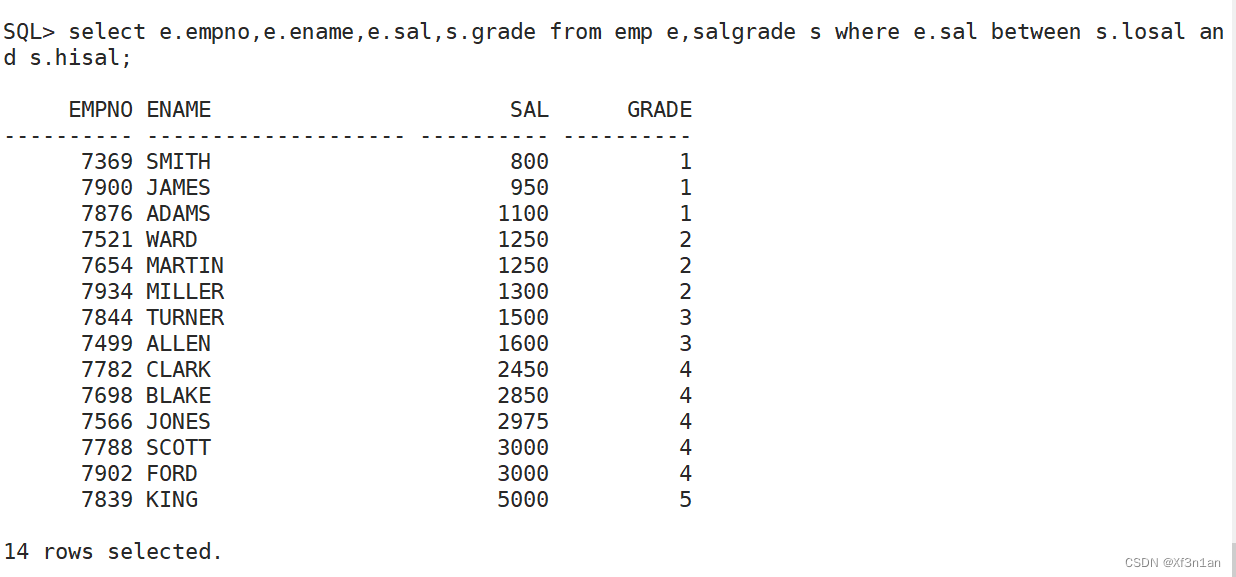
将上面的问题稍微调整下,查询员工信息:员工号 姓名 月薪 和 薪水级别(salgrade表)
分析:
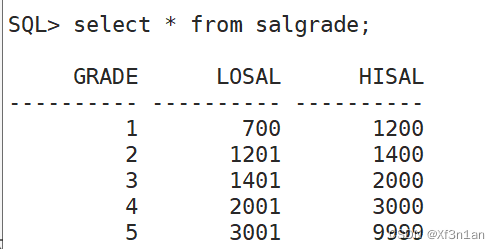
看到员工总的薪水级别,共有5级,员工的薪水级别应该满足 >=当前级别的下限,<=该级别的上限:
SQL> select e.empno,e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;
外连接
按部门统计员工人数,显示如下信息:
部门号 部门名称 人数
分析:
人数:一定是在emp表中,使用count()函数统计emp表中任一非空列均可。
部门名称:在dept表dname中,直接读取即可。
部门号:任意,两张表都有。

注意:由于使用了组函数count(),所以组函数外的d.deptno和d.dname必须放到group by后。
但是select * from dept发现40号部门没有显示出来,原因是40号部门没有员工,where没满足。结果不对,40号部门没有员工,应该在40号部门位置显示0。

我们希望: 在最后的结果中,包含某些对于where条件来说不成立的记录 (外连接的作用)
左外连接:当 where e.deptno=d.deptno 不成立的时候,=左边所表示的信息,仍然被包含。
写法:与叫法相反:where e.deptno=d.deptno(+)
右外连接:当 where e.deptno=d.deptno 不成立的时候,=右边所表示的信息,仍然被包含。
写法:依然与叫法相反:where e.deptno(+)=d.deptno
以上我们希望将没有员工的部门仍然包含到查询的结果当中。因此应该使用外链接的语法。
右外链接写法

左外链接写法

自连接
核心,通过表的别名,将同一张表视为多张表。
查询员工信息:xxx的主管是 yyy
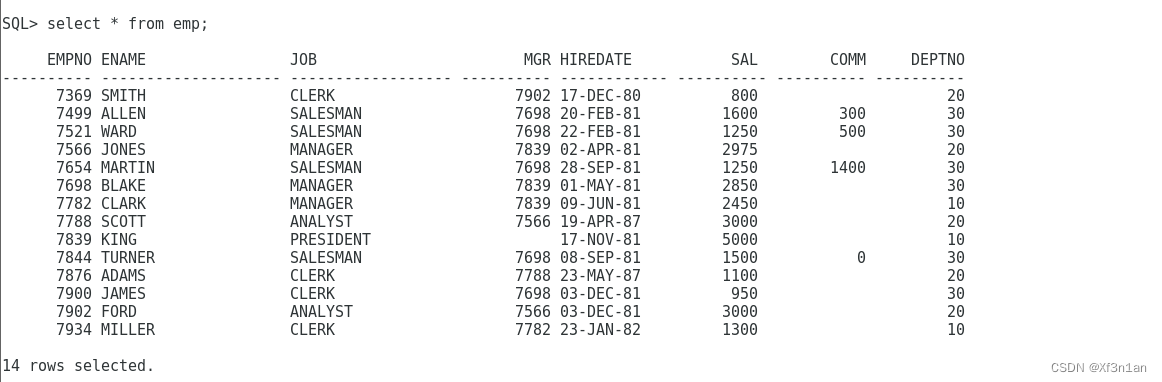
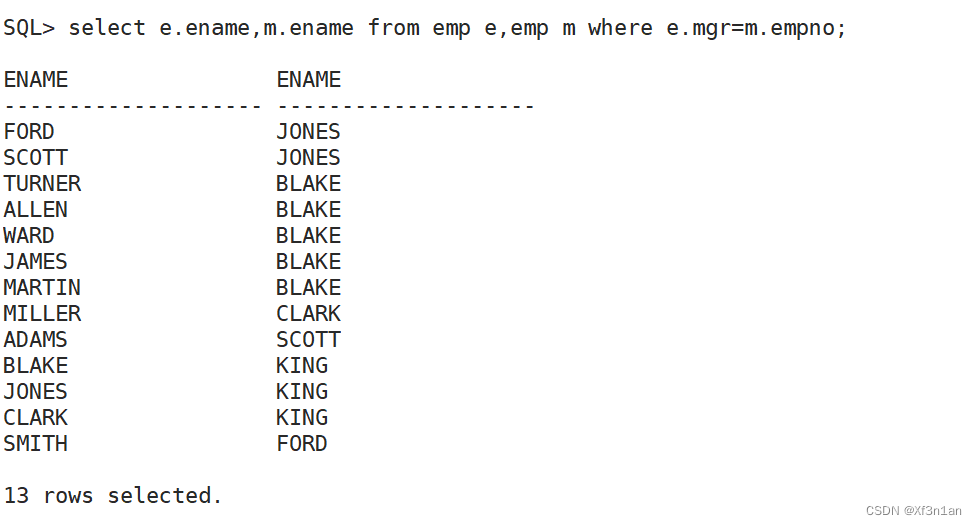
可是观察结果我们发现,老板KING没有,老板KING的上司应该是老板KING。
因此使用左自连接,当条件不满足,=左边所表示的信息,仍然被包含。

子查询
子查询语法很简单,就是select 语句的嵌套使用。
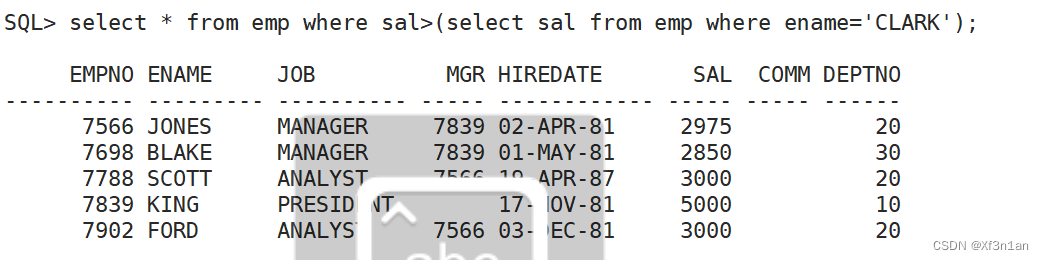
查询工资比SCOTT高的员工信息:
分析:两步即可完成
1.查出SCOTT的工资 SQL> select ename, sal from emp where ename=‘SCOTT’ ,其工资为3000。
2.查询比3000高的员工 SQL> select * from emp where sal>3000
通过两步可以将问题结果得到。子查询,可以将两步合成一步。
——子查询解决的问题:问题本身不能一步求解的情况。

子查询语法格式:

定义子查询需要注意的问题
- 小括号( )
- 主查询和子查询可以是不同表,只要子查询返回的结果主查询可以使用即可
- 可以在主查询的where、select、having、from后都可以放置子查询
- 不可以在主查询的group by后面放置子查询 (SQL语句的语法规范)
- 一般先执行子查询(内查询),再执行主查询(外查询);但是相关子查询除外
- 一般不在子查询中使用order by, 但在Top-N分析问题中,必须使用order by
- 单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
- 子查询中的null值
主、子查询在不同表间进行
查询部门名称是“SALES”的员工信息
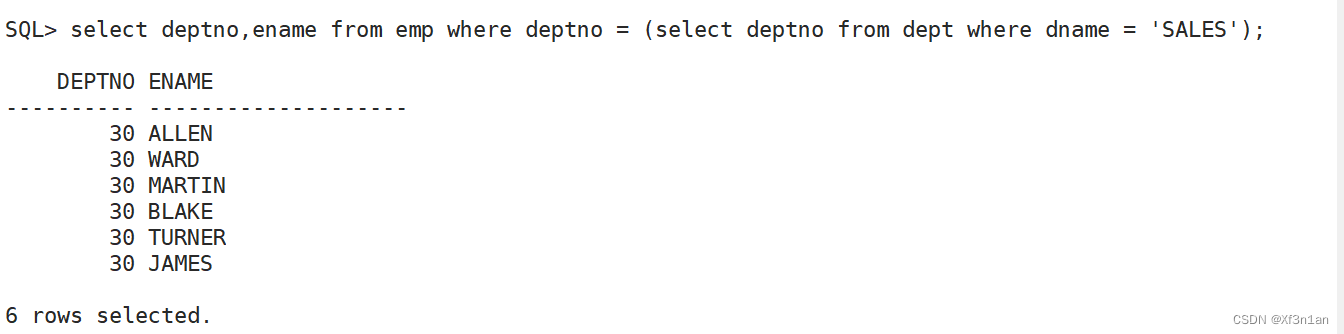
主查询:查询员工信息。select * from emp;
子查询:负责得到部门名称(在dept表中)、部门号对应关系。select deptno from dept where dname=‘SALES’
主查询,查询的是员工表emp,子查询,查询的是部门表dept。是两张不同的表。
将该问题使用“多表查询”解决:

两种方式哪种好呢?
※SQL优化: 理论上,既可以使用子查询,也可以使用多表查询,尽量使用“多表查询”。子查询有2次from,但是还得看数据量,如果数据量比较大,那么做多表查询产生的笛卡尔积也会相当庞大。
不同数据库处理数据的方式不尽相同,如Oracle数据库中,子查询地位比较重要,做了深入的优化。有可能实际看到结果是子查询快于多表查询。
在主查询的where select having from 放置子查询
子查询可以放在select后,但,要求该子查询必须是 单行子查询:(该子查询本身只返回一条记录,2+叫多行子查询)。
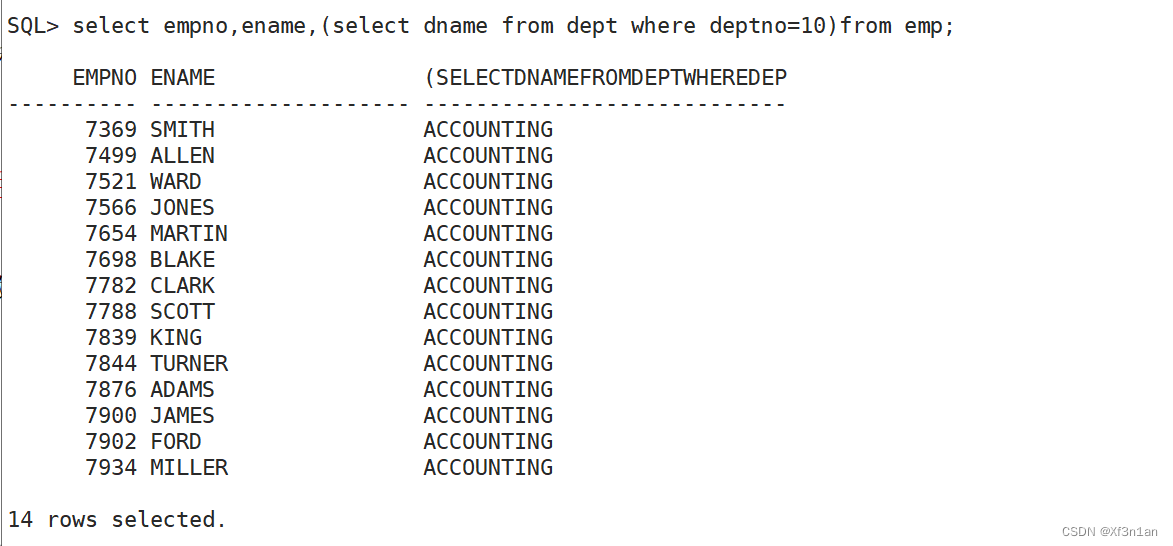


在from后面放置的子查询
表,代表一个数据集合、查询结果(SQL)语句本身也代表一个集合。
查询员工的姓名、薪水和年薪:
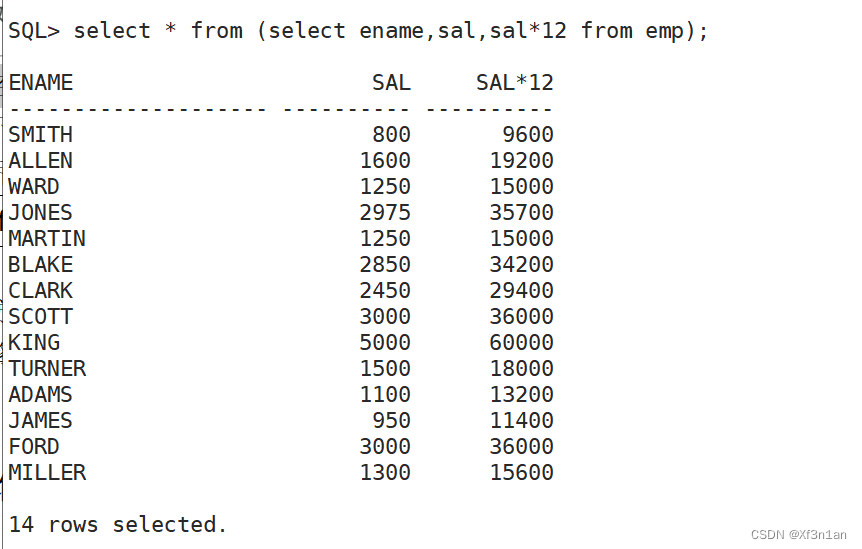
将select 语句放置到from后面,表示将select语句的结果,当成表来看待。这种查询方式在Oracle语句中使用比较频繁。
单行子查询只能使用单行操作符,多行子查询只能使用多行操作符
单行子查询
单行子查询就是该条子查询执行结束时,只返回一条记录(一行数据)。
使用单行操作符:
=、>、>=、<、<=、<>

也可以在having子句中使用:
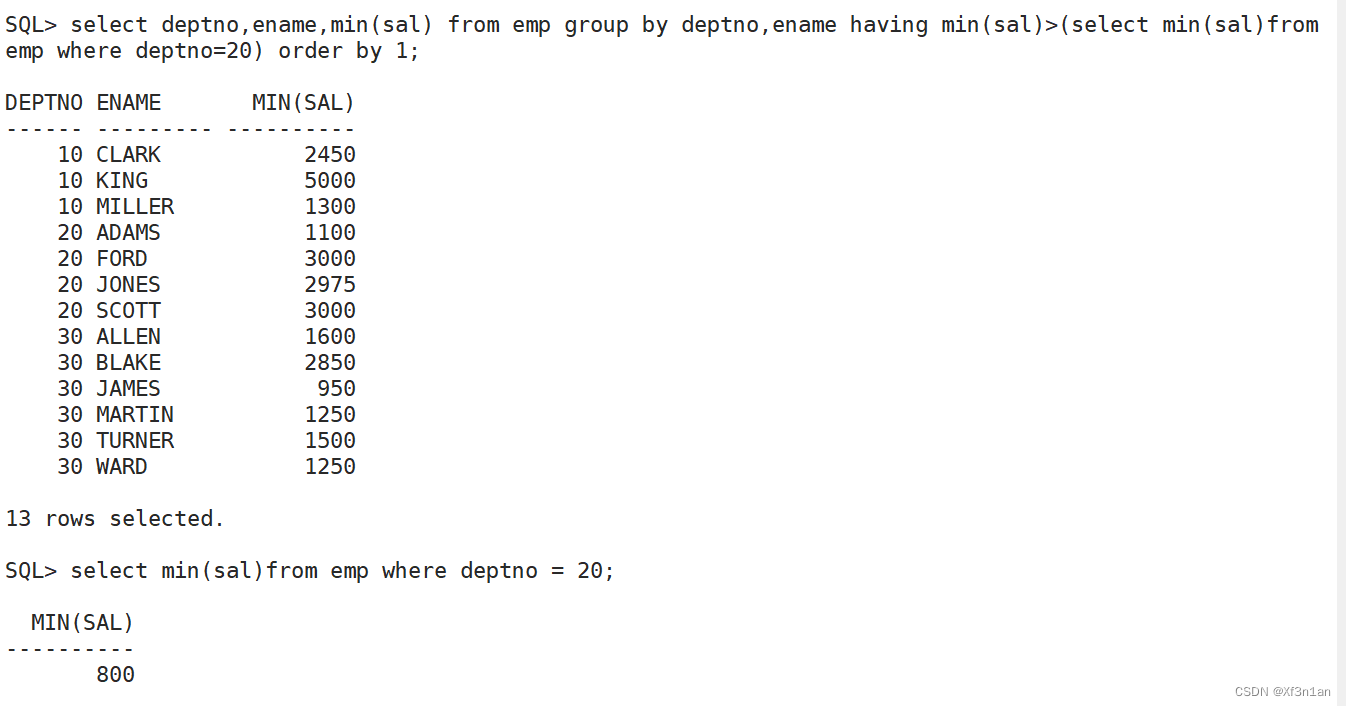
上面的例子告诉我们:
- 单行子查询,只能使用单行操作符(=号、>号等)
- 在一个主查询中可以有多个子查询。
- 子查询里面可以嵌套多层子查询。
- 子查询也可以使用组函数。子查询也是查询语句,适用于前面所有知识。
多行子查询
子查询返回2条记录以上就叫多行。
多行操作符有:
IN:等于列表中的任意一个
ANY :和子查询返回的任意一个值比较
ALL:和子查询返回的所有值比较
IN(表示在集合中):
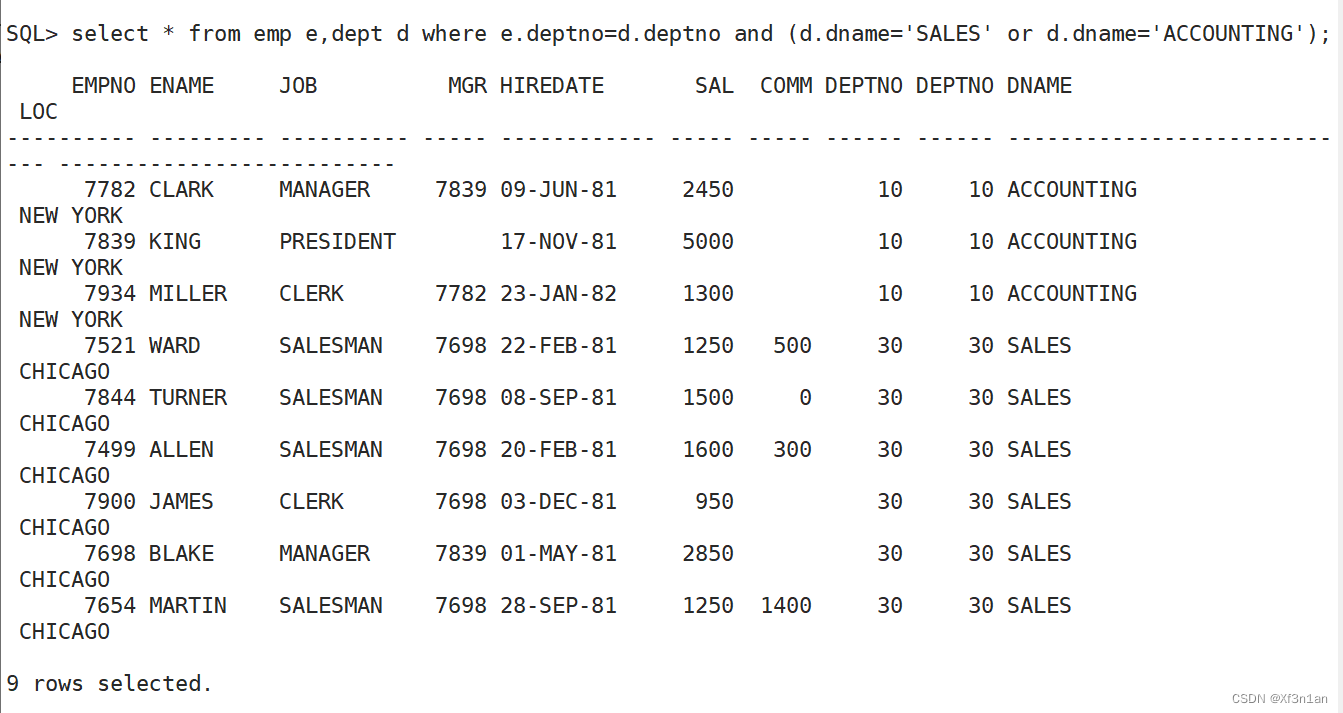
查询部门名称为SALES和ACCOUNTING的员工信息。
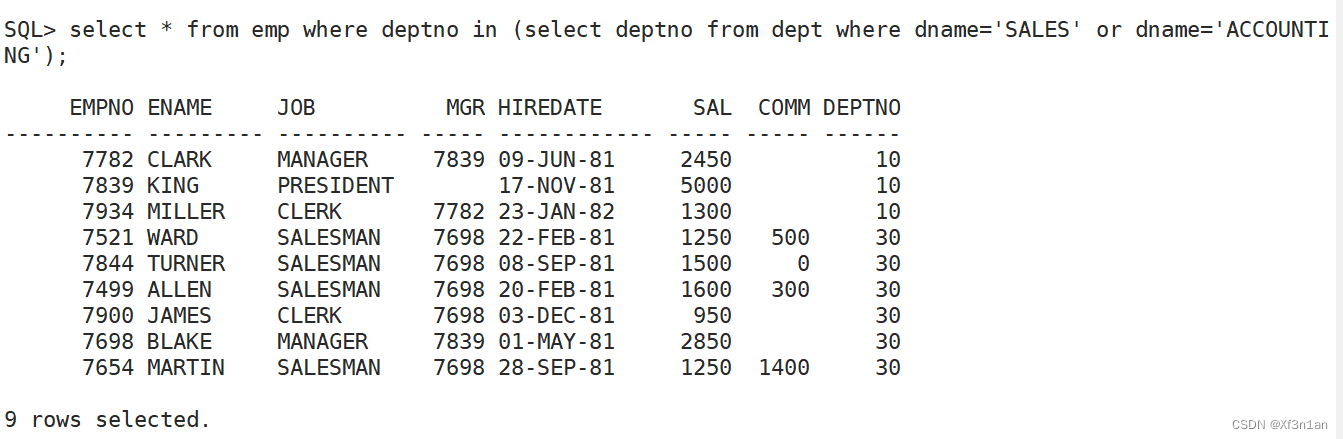
使用 多表查询 来解决该问题:
ANY(表示和集合中的任意一个值比较):
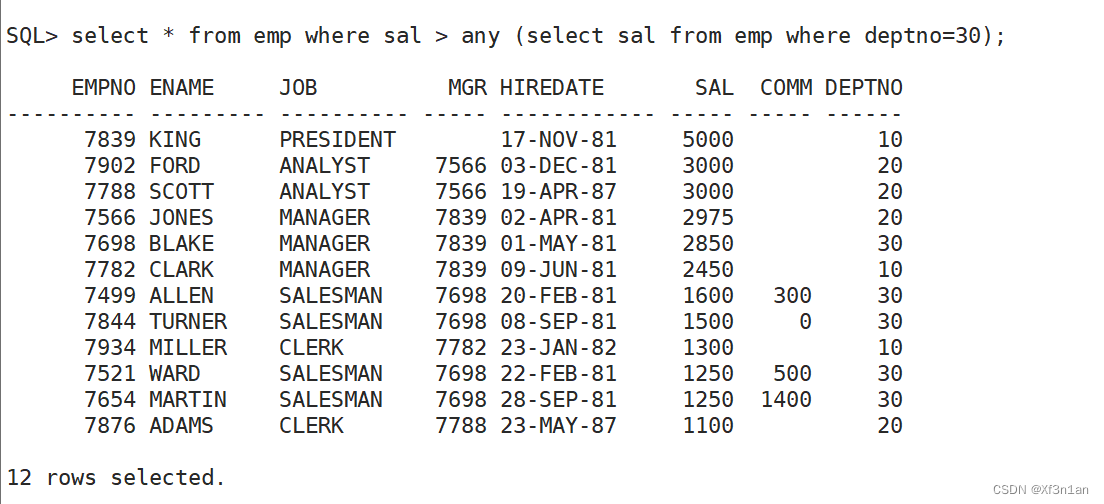
查询薪水比30号部门任意一个员工高的员工信息:
SQL> select * from emp where sal > (select sal from emp where deptno=30); 正确吗?
这样是错的,子句返回多行结果。而‘>’是单行操作符。 ——应该将‘>’替换成‘> any’
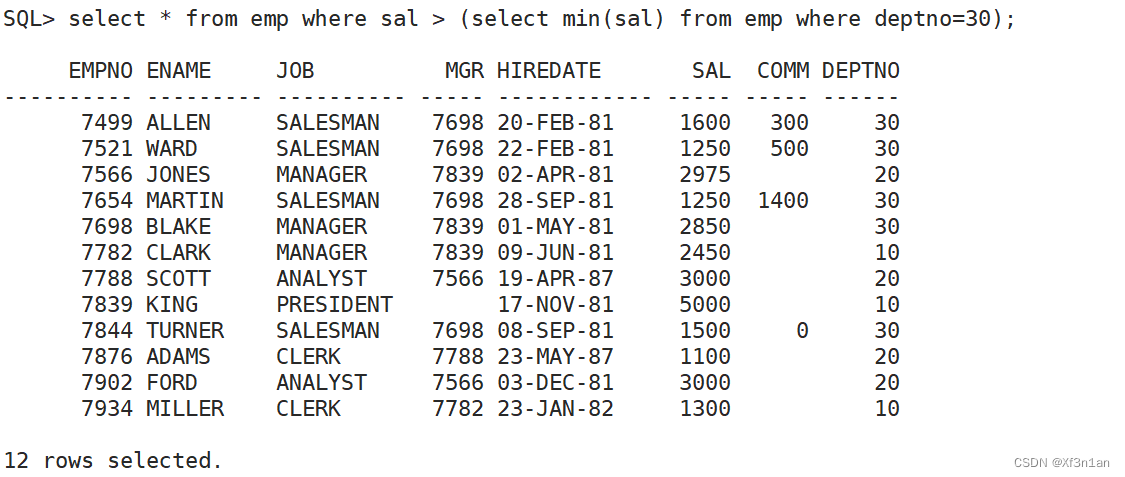
实际上>集合的任意一个值,就是大于集合的最小值。
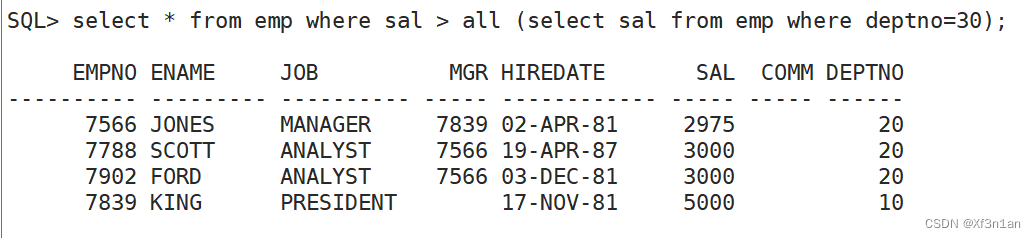
ALL(表示和集合中的所有值比较):
查询薪水比30号部门所有员工高的员工信息。
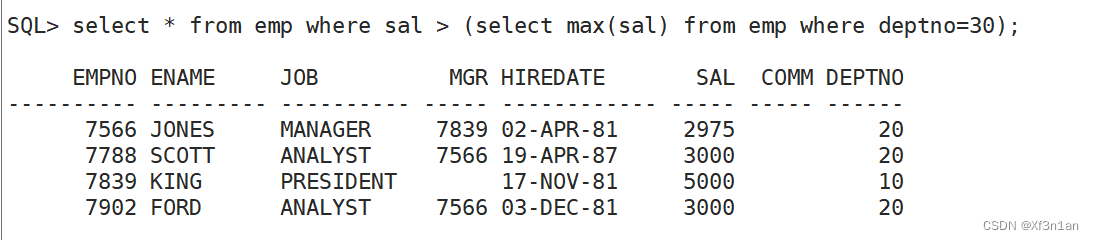
子查询中null
判断一个值等于、不等于空,不能使用=和!=号,而应该使用is 和 not。
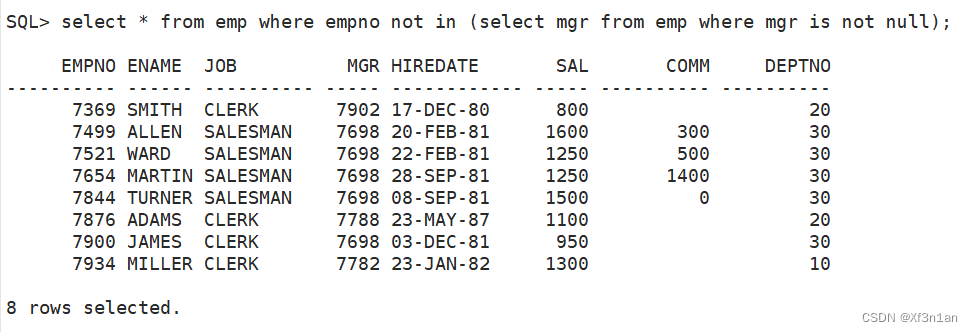
如果集合中有NULL值,不能使用not in。如: not in (10, 20, NULL),但是可以使用in。为什么呢?
例如:a not in(10, 20, NULL) 等价于 (a != 10) and (a != 20) and (a != NULL)
a in (10, 20, NULL) 等价于 (a = 10) or (a = 20) or (a = null)只要有一个为真即为真。
所以子查询中,如果有NULL值,主查询使用where xxx=子查询结果集。永远为假。
先看一个例子:
查询不是上司的员工信息:

在emp表中有列mgr,该列表示该员工的上司的员工号是多少。那么,如果一个员工的员工号在这列中,那么说明这员工是上司。
但是运行没有结果,因为有NULL。

查询是老板的员工信息:只需要将not去掉。
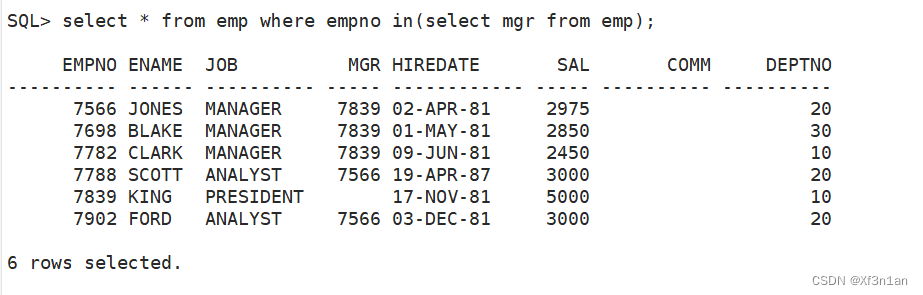
继续,查询不是老板的员工信息。 只要将空值去掉即可。
一般不在子查询中使用order by
一般情况下,子查询使用order by或是不使用order by对主查询来说没有什么意义。子查询的结果给主查询当成集合来使用,所以没有必要将子查询order by。
但,在Top-N分析问题中,必须使用order by。
一般先执行子查询,再执行主查询
含有子查询的SQL语句执行的顺序是,先子后主。
但,相关子查询例外。
集合运算
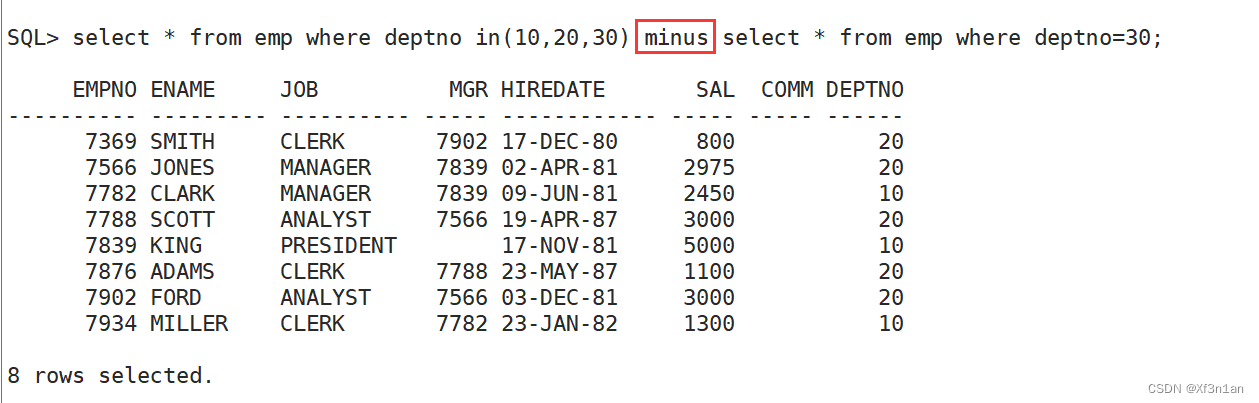
查询部门号是10和20的员工信息
思考有几种方式解决该问题 ?
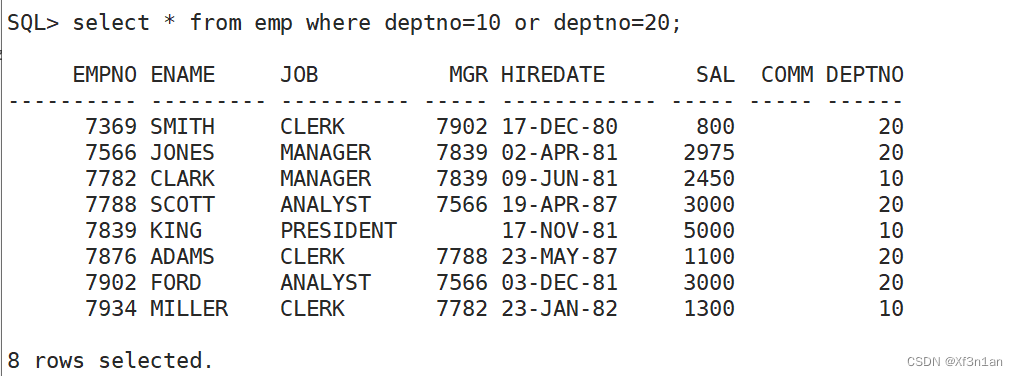
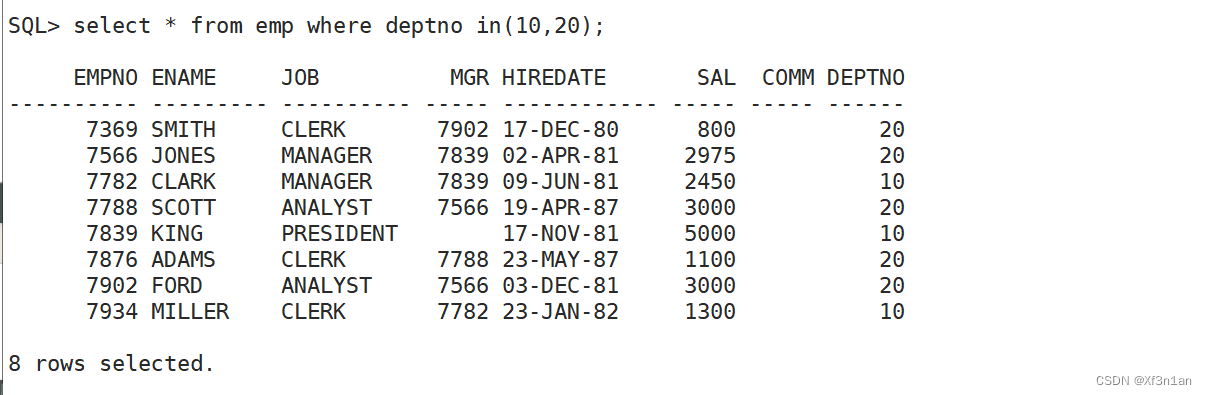
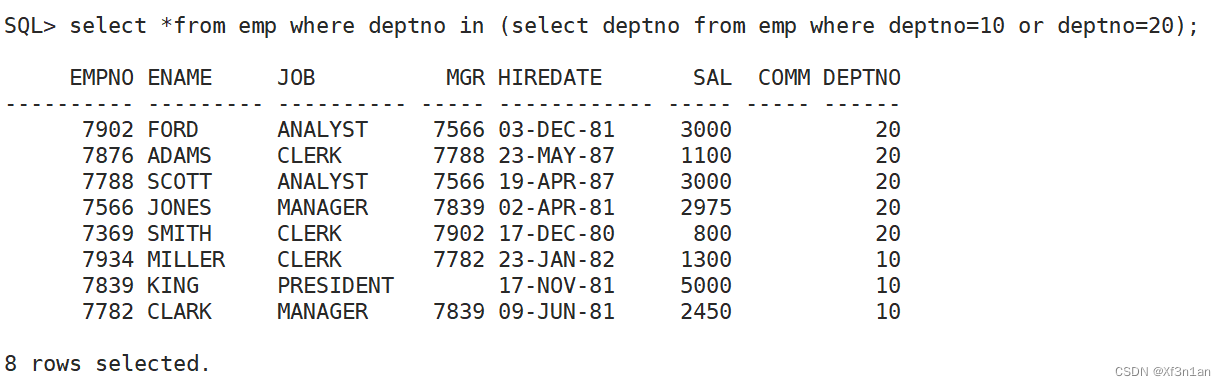
还可以用集合运算
select * from emp where deptno=10 加上
select * from emp where deptno=20
集合运算所操作的对象是两个或者多个集合,而不再是表中的列(select一直在操作表中的列)
集合运算符
集合运算的操作符。A∪B、A∩B、A – B
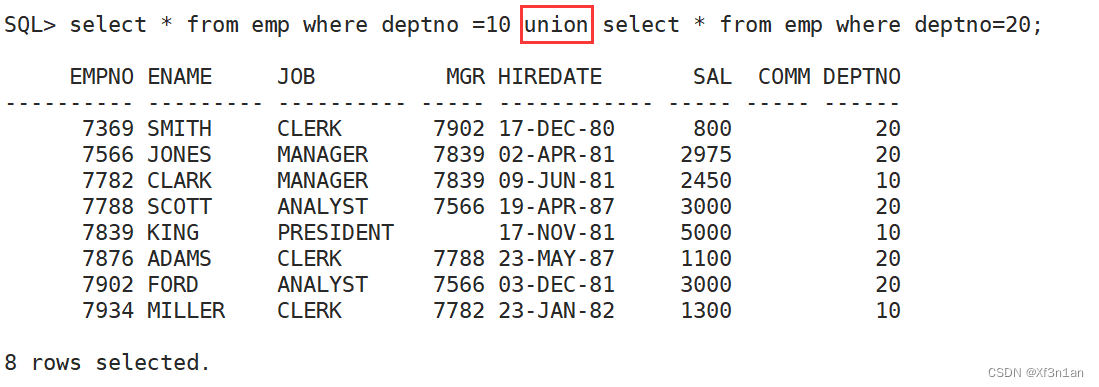
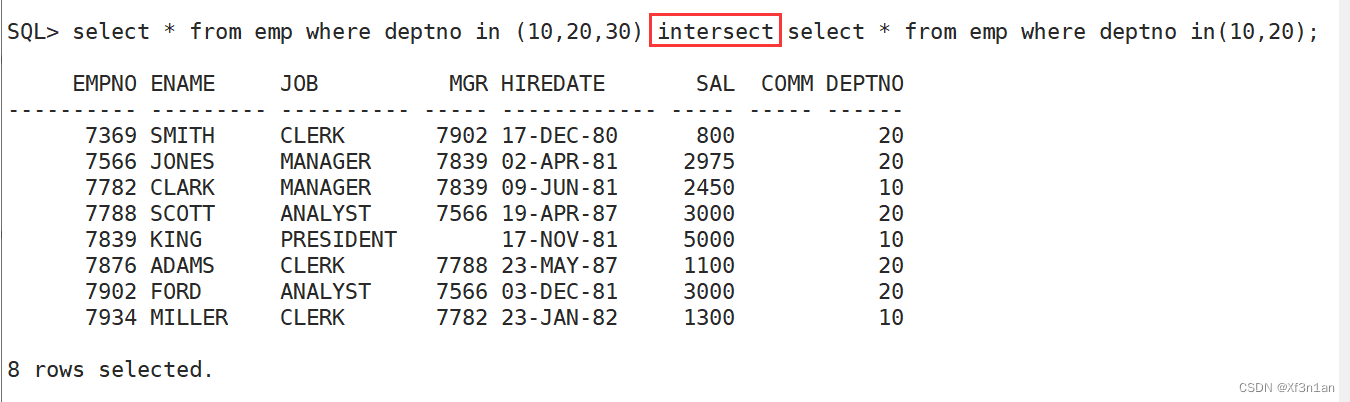
集合运算需要注意的问题
1.参与运算的各个集合必须列数相同,且类型一致。
2.采用第一个集合的表头作为最终使用的表头。 (列名别名也只能在第一个集合上起)
3.可以使用括号()先执行后面的语句。
问题:按照部门统计各部门不同工种的工资情况,要求按如下格式输出:
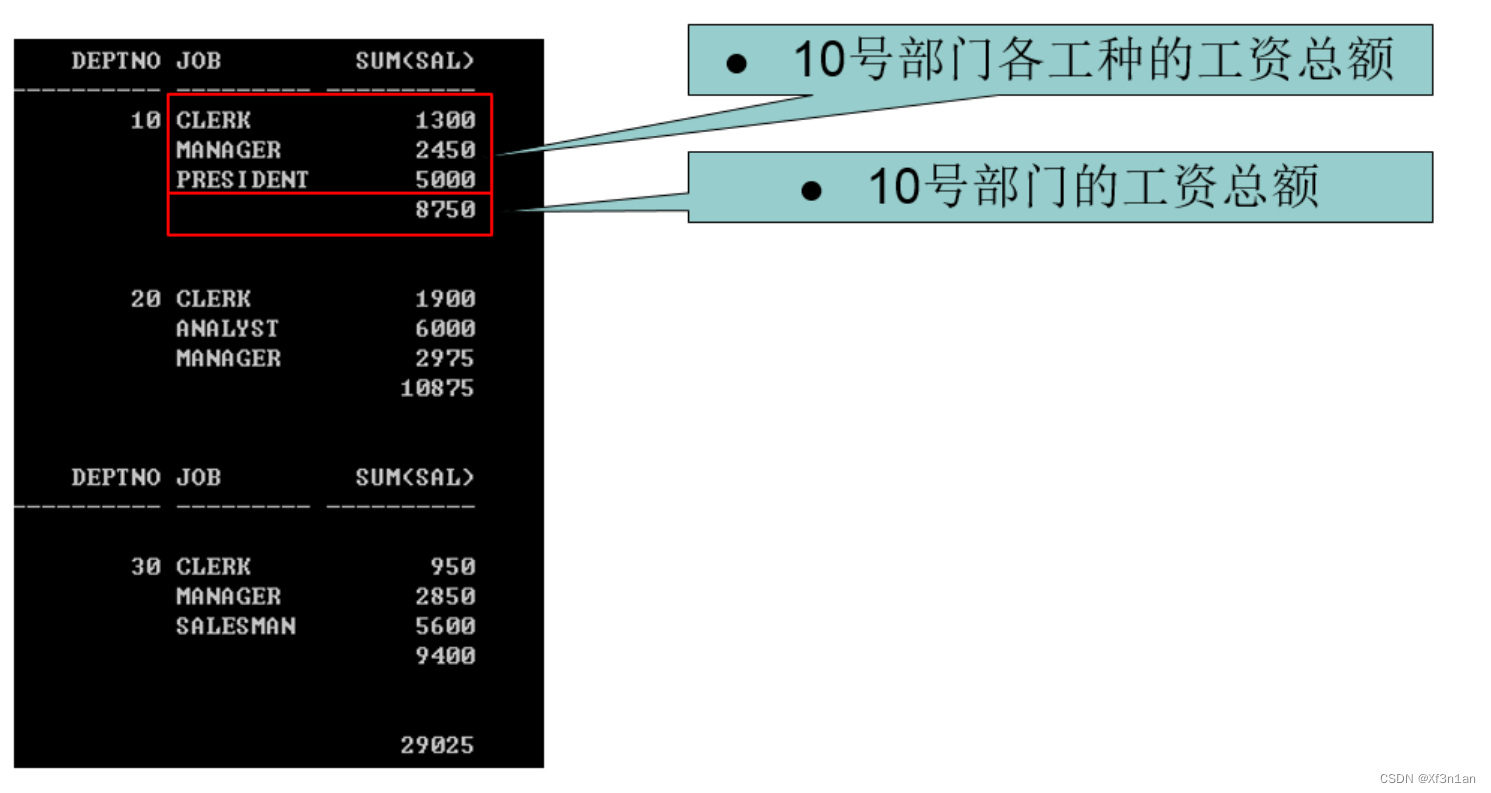
分析:可以看出这里由三个集合组成,分别如下:
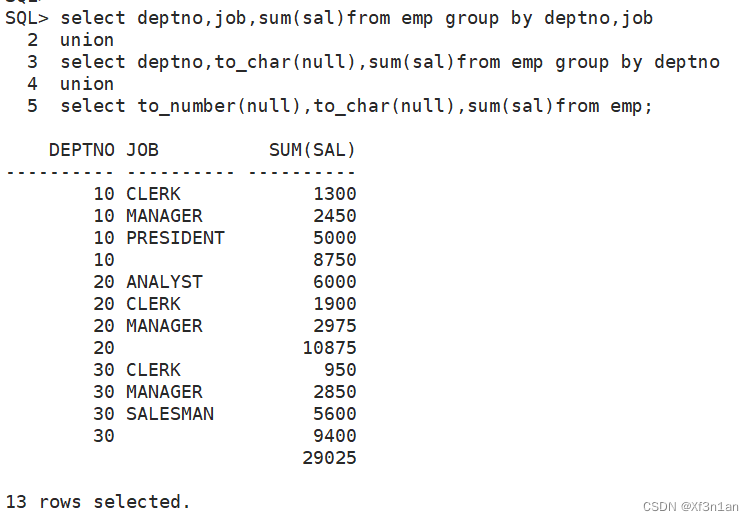
因此我们使用union将三个集合并起来。 但是,参与运算的各个集合必须列数相同,且类型一致。
如果不一致,需要填充成一致。使用null强行占位。
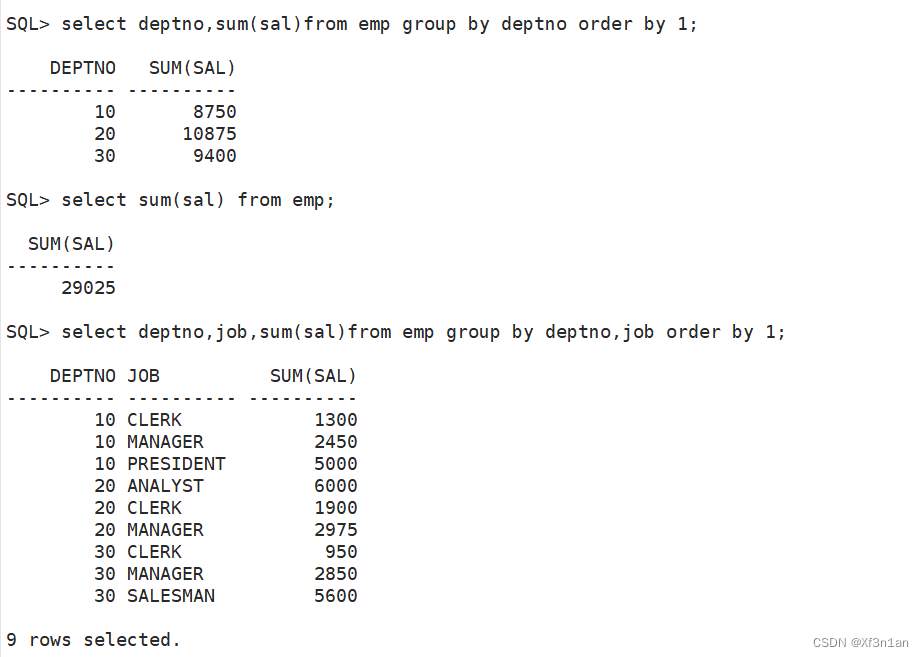
第一部分数据是按照deptno和job进行分组;select 查询deptno、job、sum(sal)
第二部分数据是直接按照deptno分组即可,与job无关;select 只需要查询deptno,sum(sal)
第三部分数据不按照任何条件分组,即group by null;select 查询sum(sal)
如果需要上述图片的显示效果,开启报表显示设置。
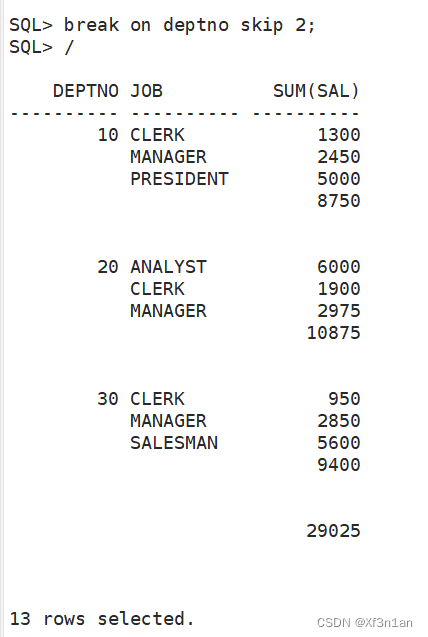
关闭显示效果
break on null
数据处理
插入数据insert
使用 INSERT 语句向表中插入数据。其语法为:

如果:values后面的值,涵盖了表中的所有列,那么table的列名可以省略不写。


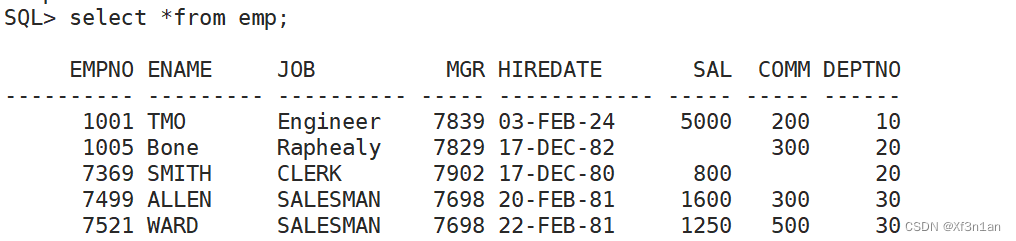
如果:插入的时候没有插入所有的列,就必须显式的写出这些列的名字。

注意:字符串和日期都应该使用 ’ ’ 号引用起来。
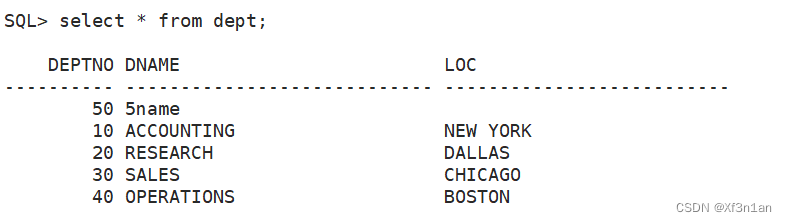
没有写出的列自动填NULL, 这种方式称之为“隐式插入空值”。
“&” 地址符
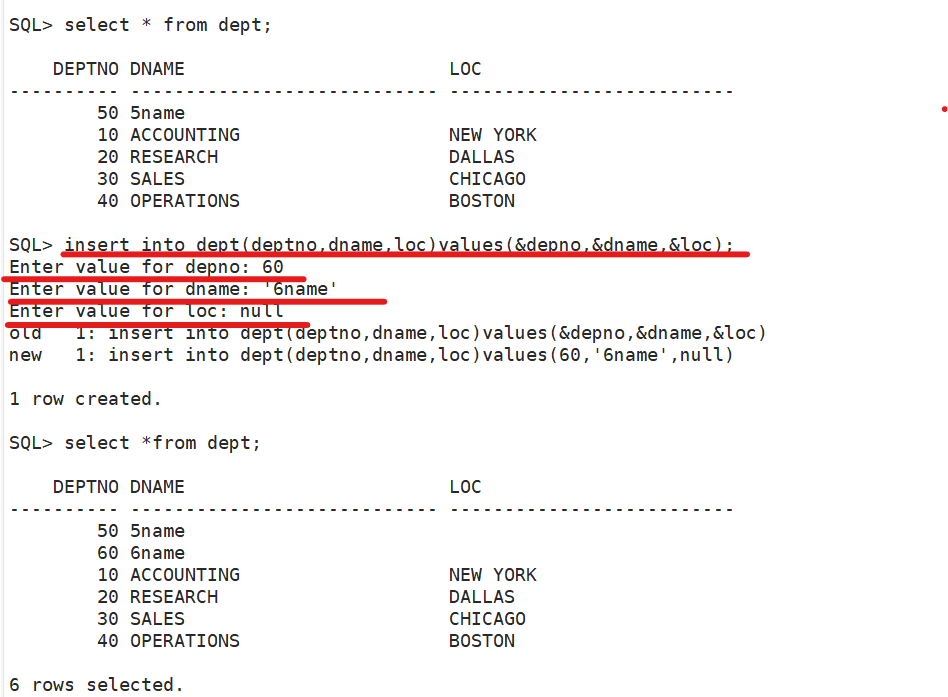
可以在DML的任意一个语句中输入“&”。
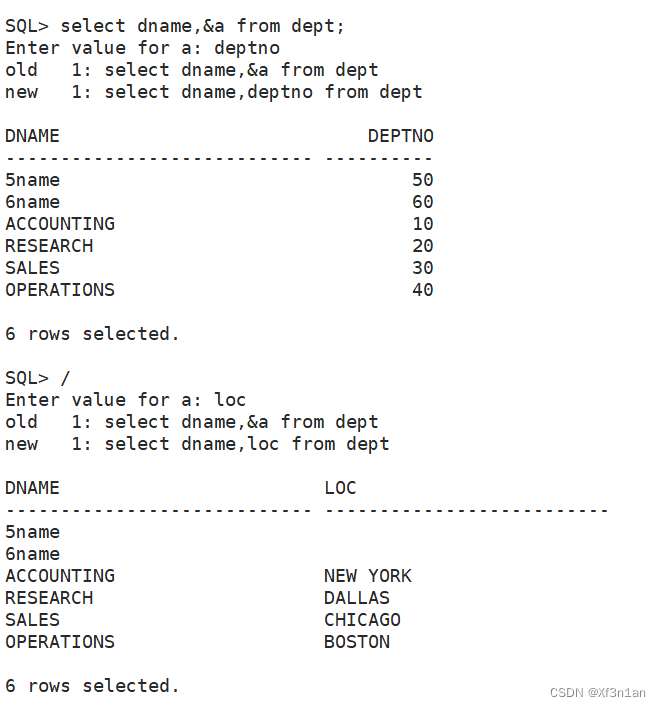
批处理
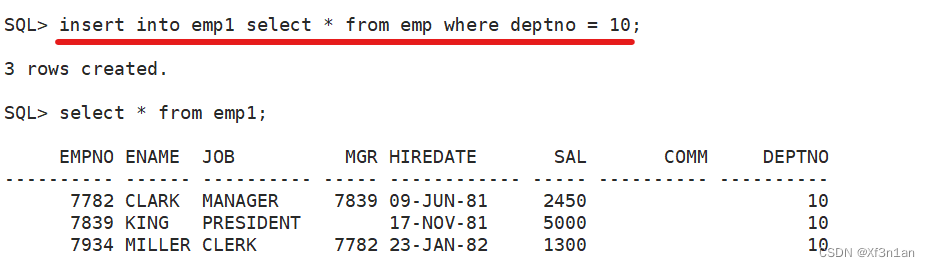
一次插入多条数据。

这里where条件写了一个永假值,为了不将emp表的任何数据插入进新表中,只使用emp表的结构。


一次性将emp表中所有十号部门的员工放到新表中。
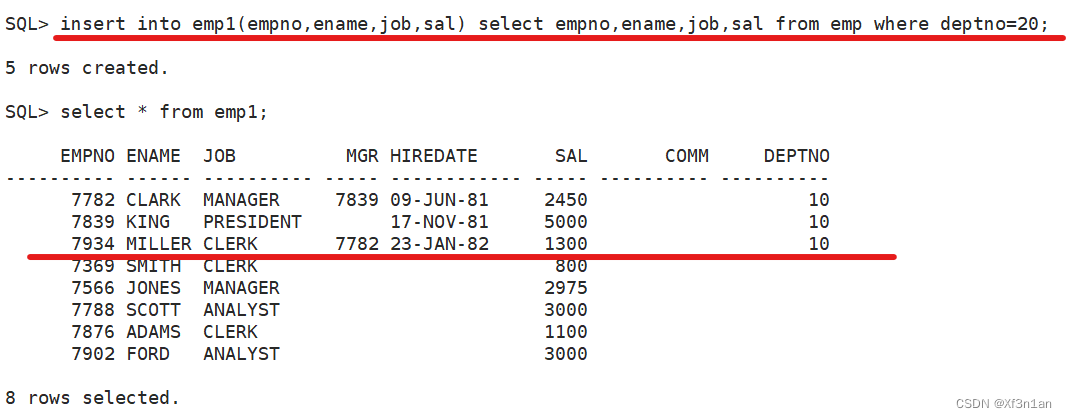
一次性将emp表中的指定列插入到新表中。
更新数据和删除数据
对于更新和删除操作来说,一般会有一个“where”条件,如果没有这限制条件,更新的就是整张表。
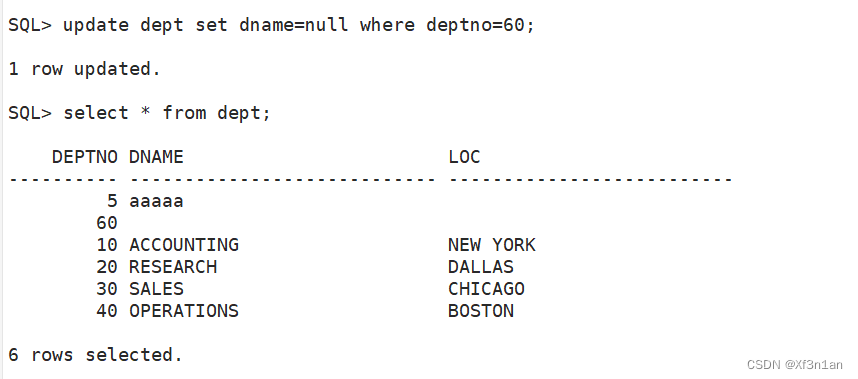
更新数据
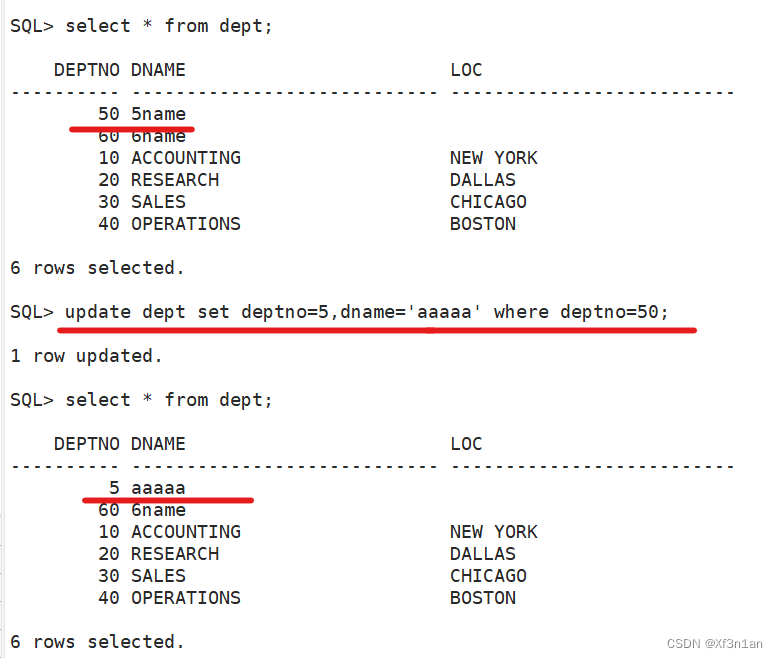
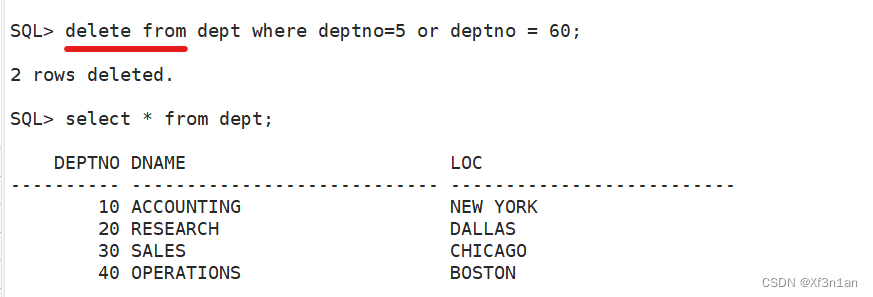
删除数据
事务
数据库事务,是由有限的数据库操作序列组成的逻辑执行单元,这一系列操作要么全部执行,要么全部放弃执行。
数据库事务由以下的部分组成:
一个或多个DML语句
一个 DDL(Data Definition Language – 数据定义语言) 语句
一个 DCL(Data Control Language – 数据控制语言) 语句
事务的特点:要么都成功,要么都不执行。
事务的特性(ACID)
事务4大特性:
- 原子性 (Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。
- 一致性 (Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性 (Isolation):事务的执行不受其他事务的干扰,当数据库被多个客户端并发访问时,隔离它们的操作,防止出现:脏读、幻读、不可重复读。
- 持久性 (Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
事务的起始标志:Oracle中自动开启事务,以DML语句为开启标志。
执行一个增删改查语句,只要没有提交commit和回滚rollback,操作都在一个事务中。
事务的结束标志:提交、回滚都是事务的结束标志。
事务的提交:
显式提交:commit
隐式提交:
1.有DDL语句,如:create table除了创建表之外还会隐式提交Create之前所有没有提交的DML语句。
2.正常退出(exit / quit)
事务的回滚:
显式回滚:rollback
隐式回滚:掉电、宕机、非正常退出。
隔离级别
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
- 脏读: 对于两个事务 T1、T2,T1 读取了已经被 T2 更新但还没有被提交的字段。之后,若 T2 回滚,T1读取的内容就是临时且无效的。
- 不可重复读: 对于两个事务 T1、T2,T1 读取了一个字段,然后 T2 更新了该字段。之后,T1再次读取同一个字段,值就不同了。
- 幻读: 对于两个事务 T1、T2,T1 从一个表中读取了一个字段,然后 T2 在该表中插入了一些新的行。之后,如果 T1 再次读取同一个表,就会多出几行。
数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题.。
一个事务与其他事务隔离的程度称为隔离级别,数据库规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
SQL99定义4种隔离级别:
- Read Uncommitted 读未提交数据。
- Read Commited 读已提交数据。 (Oracle默认)
- Repeatable Read 可重复读。 (MySQL默认)
- Serializable 序列化、串行化。 (查询也要等前一个事务结束)
这4种MySQL都支持
Oracle支持的隔离级别: Read Commited(默认)和 Serializable,以及Oracle自定义的Read Only三种。
Read Only:由于大多数情况下,在事务操作的过程中,不希望别人也来操作,但是如果将别人的隔离级别设置为Serializable(串行),但是单线程会导致数据库的性能太差。是应该允许别人来进行read操作的。
控制事务
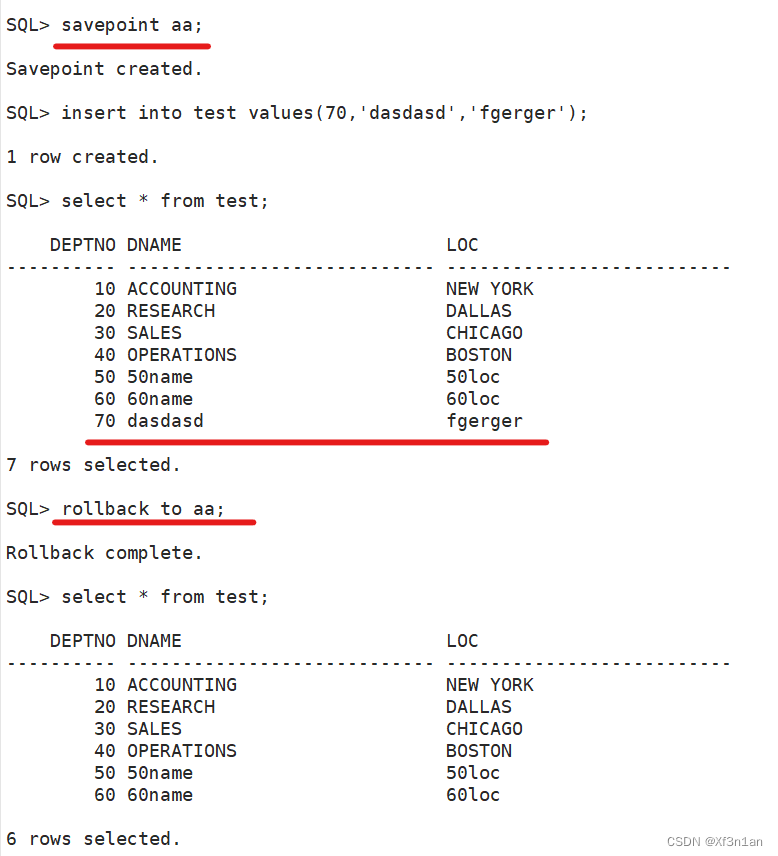
保存点(savepoint):可以防止错误操作影响整个事务,方便进行事务控制。
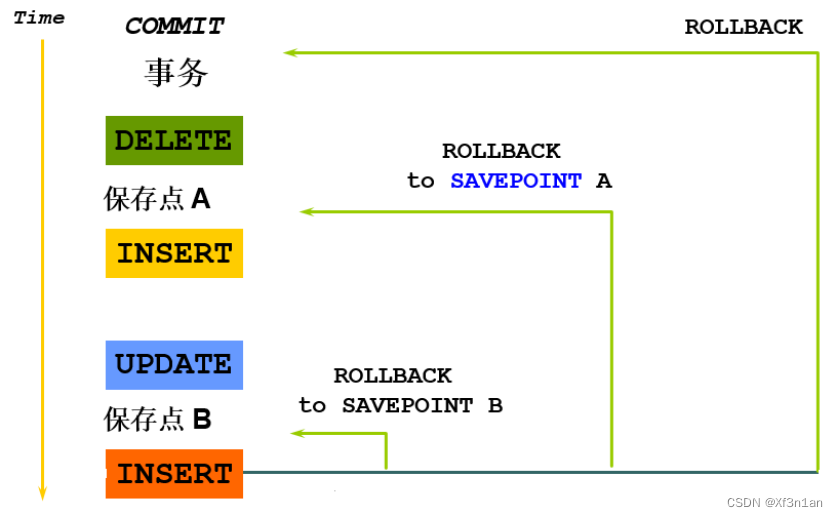
创建保存点:savepoint 保存点名
回滚到保存点:rollback to [savepoint] 保存点名
演示:
创建和管理表
创建表
创建一张表必须具备:1. 能够创建表的权限 2. 存储空间。我们使用的scott/hr用户都具备这两点。
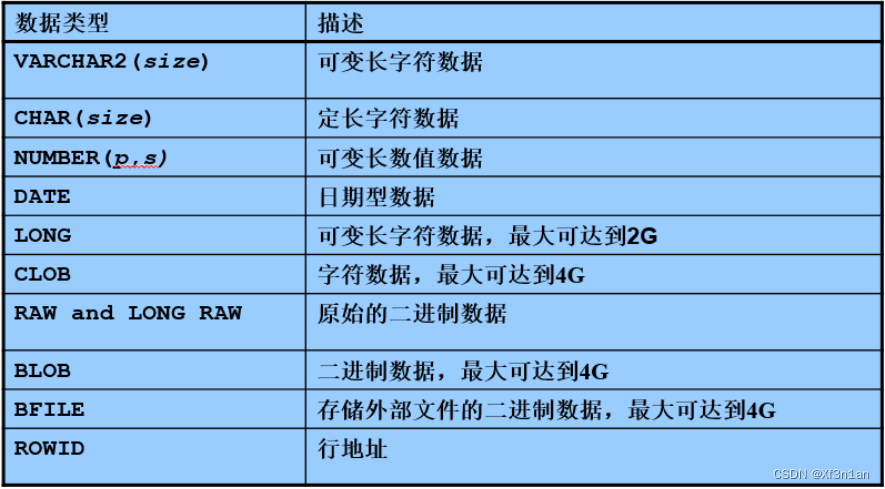
创建表时, 列所使用的数据类型:


rowid:行地址 ——伪列
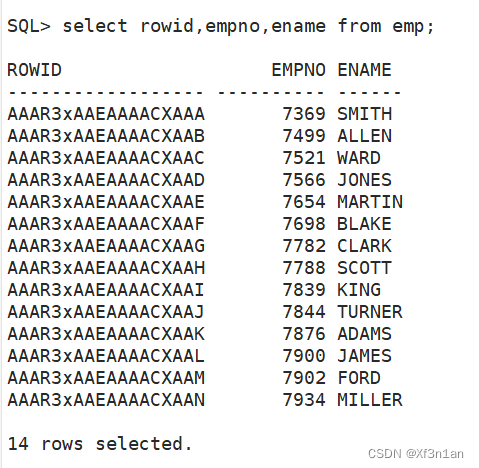
该列存储的是一系列的地址(指针),创建索引用。
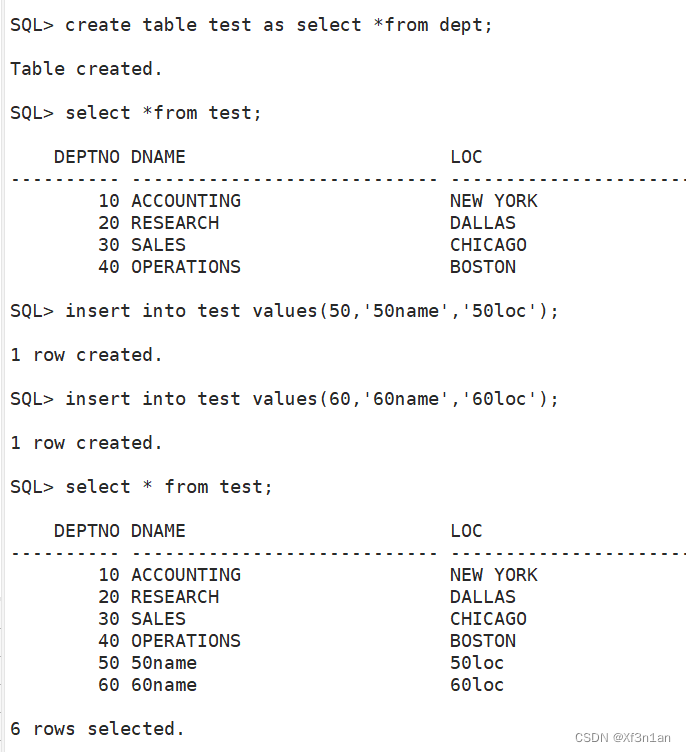
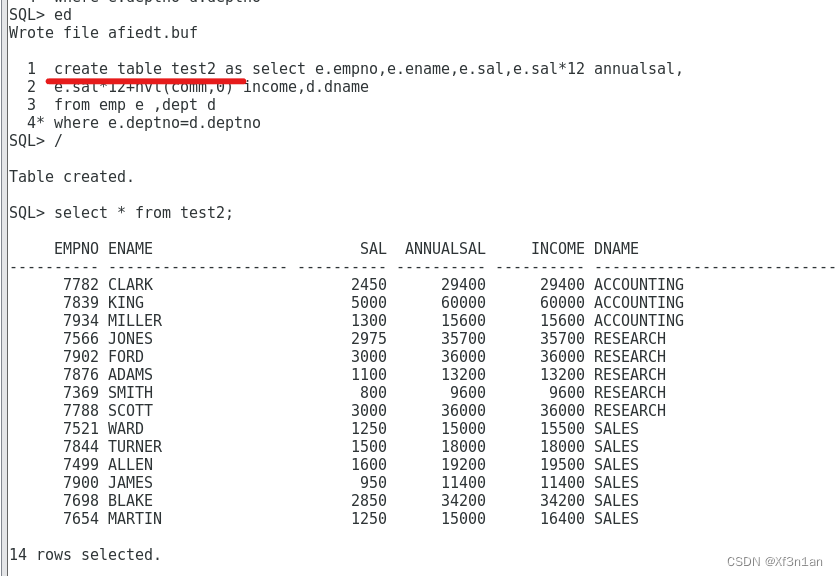
分析之前我们使用过的创建表的语句:
SQL> create table emp1 as select * from emp where 1=2
在这条语句中,“where 1=2”一定为假。所以是不能select到结果的,但是将这条子查询放到Create语句中,可以完成拷贝表结构的效果。最终emp1和emp有相同的结构。
如果,“where”给定的是一个有效的条件,就会在创建表的同时拷贝数据。如:
SQL> create table emp20 as select * from emp where deptno=20
这样emp2在创建之初就有5条数据。
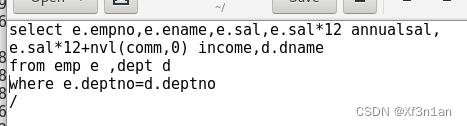
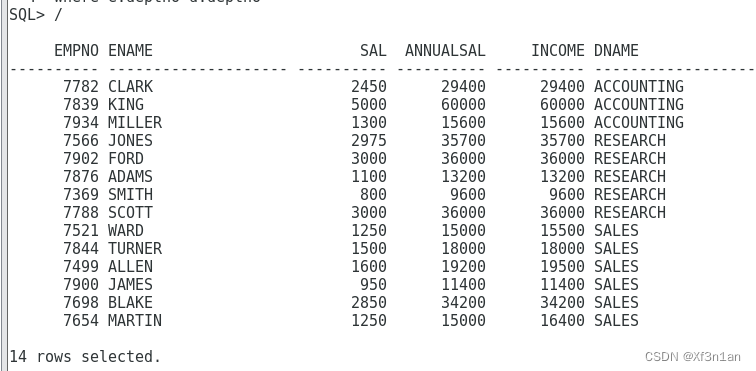
创建一张表,要求包含:员工号 姓名 月薪 年薪 年收入 部门名称。
分析:根据要求,涉及emp和dept两张表(至少有一个where条件),并且要使用表达式来计算年收入和年薪。
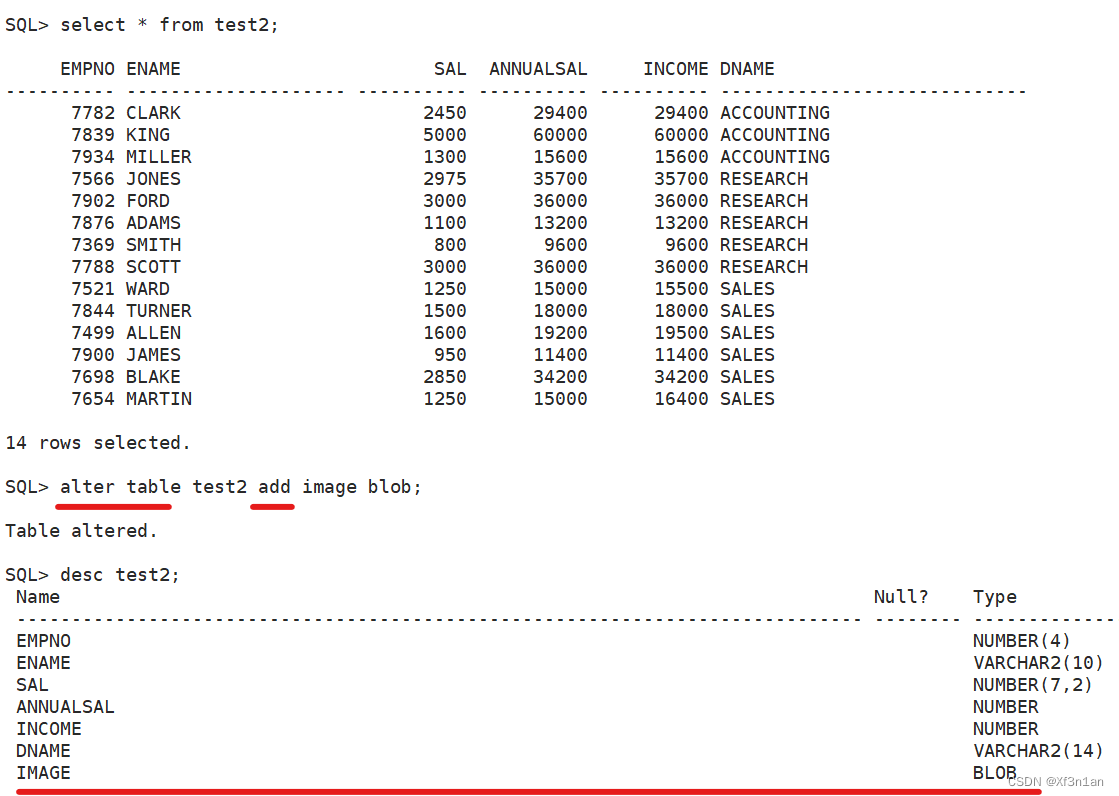
修改表
追加一列
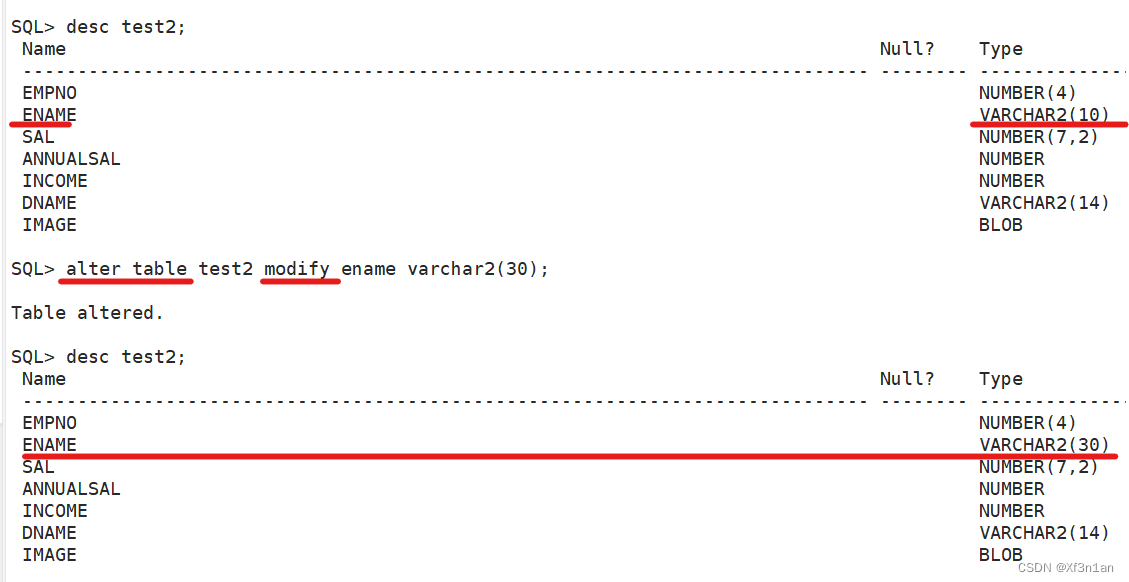
修改一列
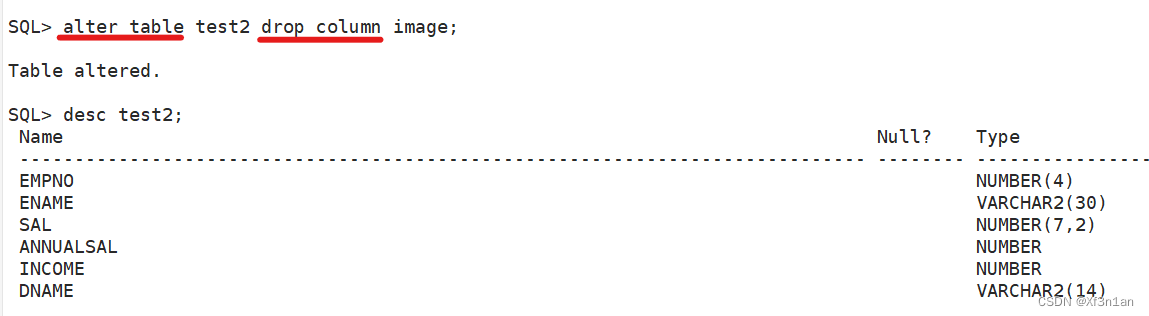
删除一列
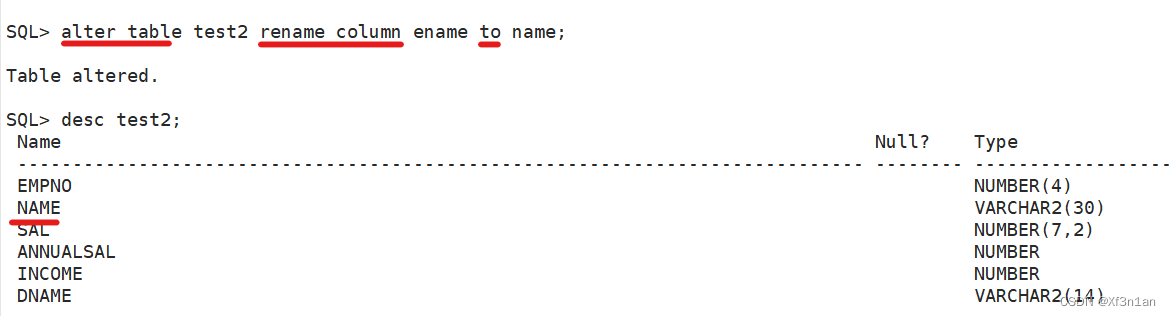
重命名一列
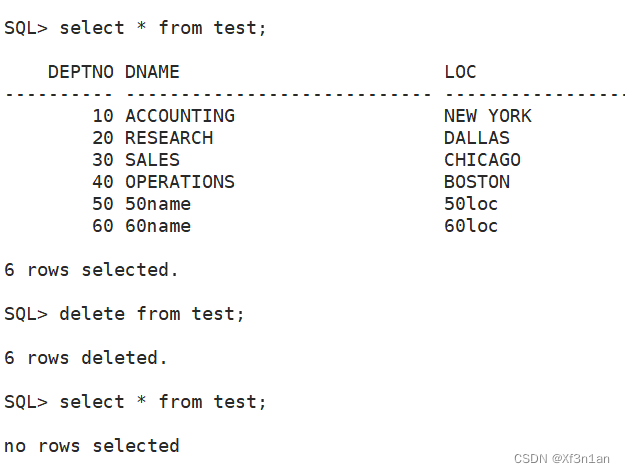
清空表

delete 和 truncate 的区别
delete from table 不加 条件也可以删除清空表。
1.delete 逐条删除表“内容”,truncate 先摧毁表再重建。
(由于delete使用频繁,Oracle对delete优化后delete快于truncate)
2.delete 是DML语句,truncate 是DDL语句。DML语句可以闪回(flashback)和回滚rollback,DDL语句不可以闪回和回滚。
(闪回: 做错了一个操作并且commit了,对应的撤销行为。)
3.由于delete是逐条操作数据,所以delete会产生碎片,truncate不会产生碎片。
(同样是由于Oracle对delete进行了优化,让delete不产生碎片)。两个数据之间的数据被删除,删除的数据——碎片,整理碎片,数据连续,行移动。
4.delete不会释放空间,truncate 会释放空间。用delete删除一张10M的表,空间不会释放。而truncate会。所以当确定表不再使用,应使用truncate。
删除表和重命名表
当表被删除:
数据和结构都被删除。
所有正在运行的相关事务被提交。
所有相关索引被删除。
DROP TABLE 语句不能回滚,但是可以闪回。
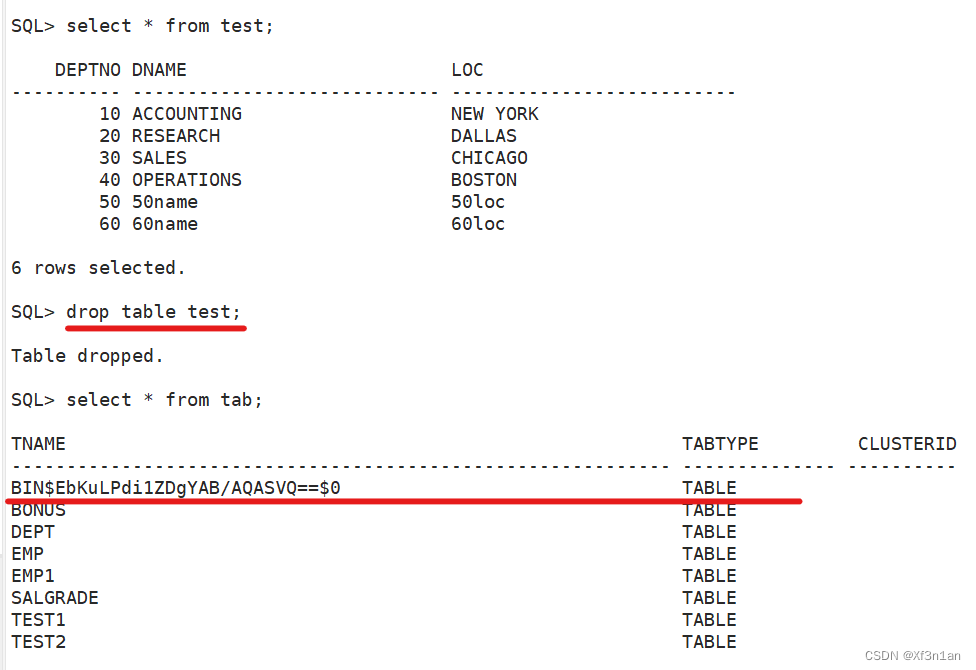
Oracle的回收站:
查看回收站:show recyclebin

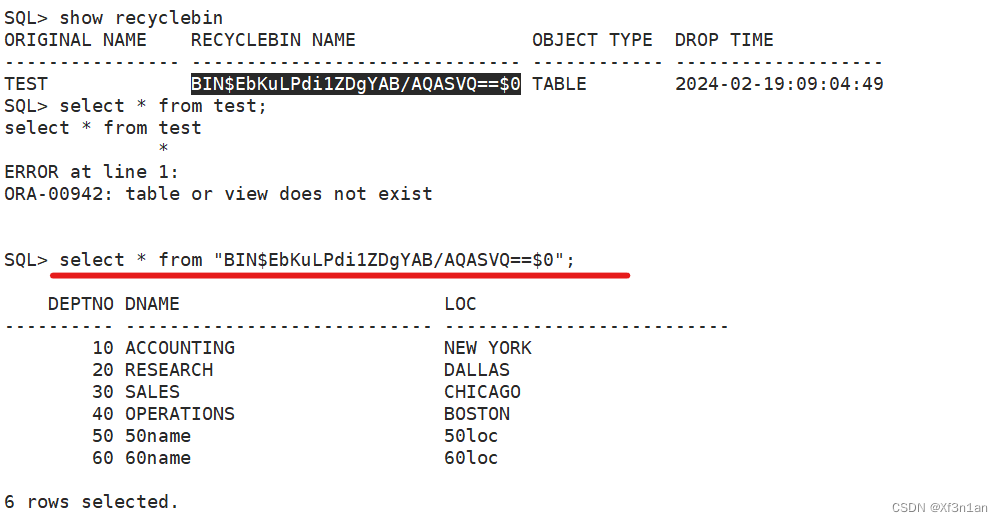
清空回收站:purge recyclebin

重命名表
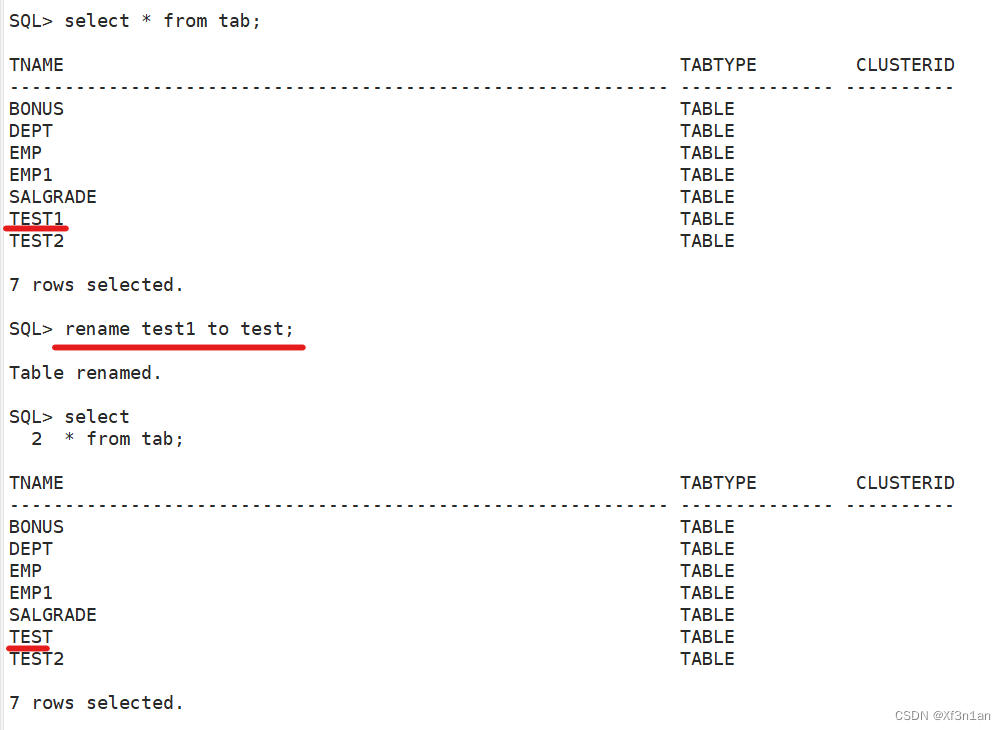
约束
约束的种类
- Not NULL:非空约束
例如:人的名字不允许为空 - Unique:唯一性约束
例如:手机号不允许为空 - Check:检查性约束
例如:人的性别只能为男或女 - Primary Key:主键约束
主键是唯一标识表中某一行数据的列,主键约束隐含Not null + Unique。
一个表只能有一个主键,但是主键可以是某一列,也可以是多列组成表的主键,比如说可以用员工名和部门号两列组成emp表的主键。将某两个列作为主键必须用表级约束。
constraint 约束名 primary key (列1,列2) - Foreign Key:外键约束
例如:部门表dept和员工表emp,不应该存在不属于任何一个部门的员工。
这时外键用来约束两张表的关系。
一个表(子表)的外键必须是其他某个表(父表)的具有唯一约束的列(一般都用主键),子表外键的值必须满足能在父表的列中存在,或者为NULL。
这里边就涉及到一个问题,就是是父表的键值被删除,这时候子表里边的外键值应该怎么办?有以下三种方案:
不允许删除(restrict默认)
子表里边的数据跟着删除(cascade)
子表里边的数据设置为空(set null)
多数情况下,使用SET NULL方法,防止子表列被删除,数据出错。
所以这里边也涉及到删除表的时候的顺序:
(1)先将子表的内容删除,然后再删除父表。
(2)将子表外键一列设置为NULL值,断开引用关系,然后删除父表。
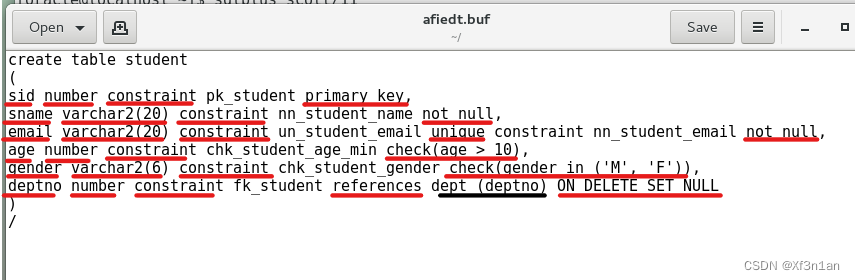
约束举例
create table student
(
sid number constraint pk_student primary key, --学生Id主键约束
sname varchar2(20) constraint nn_student_name not null,--学生姓名非空约束
email varchar2(20) constraint un_student_email unique --学生邮件唯一约束
constraint nn_student_email not null, --同时邮件可再设非空,没有“,”
age number constraint chk_student_age_min check(age > 10), --学生年龄设置check约束
gender varchar2(6) constraint chk_student_gender check(gender in ('男', '女')),
deptno number constraint fk_student references dept (deptno) ON DELETE SET NULL
)
在定义学生deptno列的时候,引用部门表的部门号一列作为外键,同时使用references设置级联操作
——当删除dept表的deptno的时候,将student表的deptno置空。

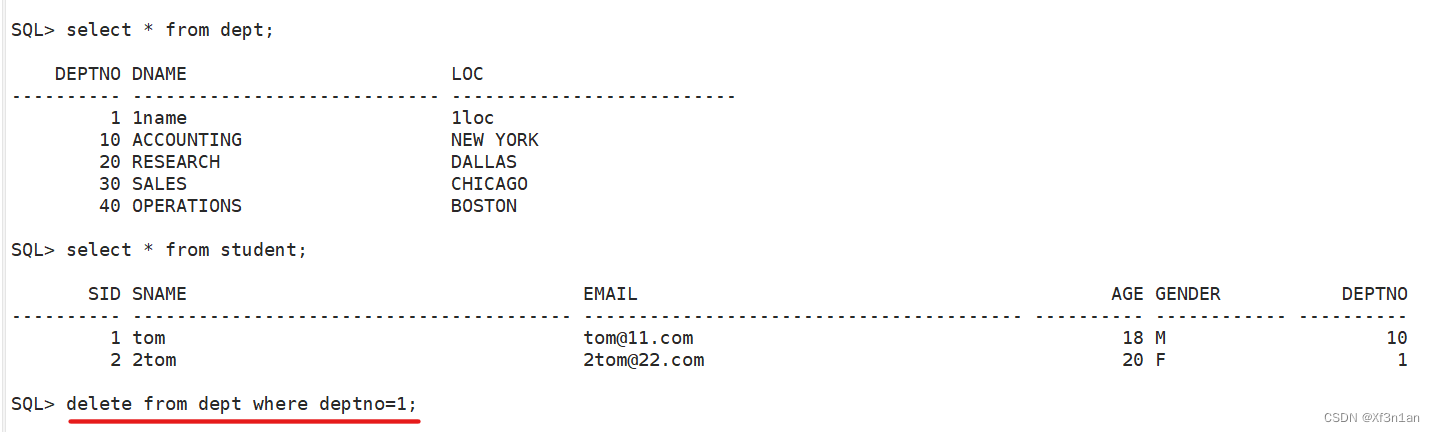
1.主键唯一性约束


2.姓名非空约束

3.外键约束

4.主表删除影响子表外键

视图
常见数据库对象——视图:从表中抽出的逻辑上相关的数据集合。
通俗来说,可以把视图看成是虚拟的表,只是一个查询语句的结果。
所以:
- 视图基于表。
- 视图是逻辑概念。
- 视图本身没有数据。
创建视图
创建语法与创建表类似,不过这里边定义换成了子查询。
比如说创建一个视图,用来查看员工的收入、年收入的信息:
因为创建视图需要“create view”的权限。默认scott用户没有该种权限。
添加步骤:
1.使用管理员登陆:sqlplus / as sysdba;

2.给scott用户增加权限: SQL> grant create view to scott;

3.创建视图。

4.视图的操作和表的操作完全一样。
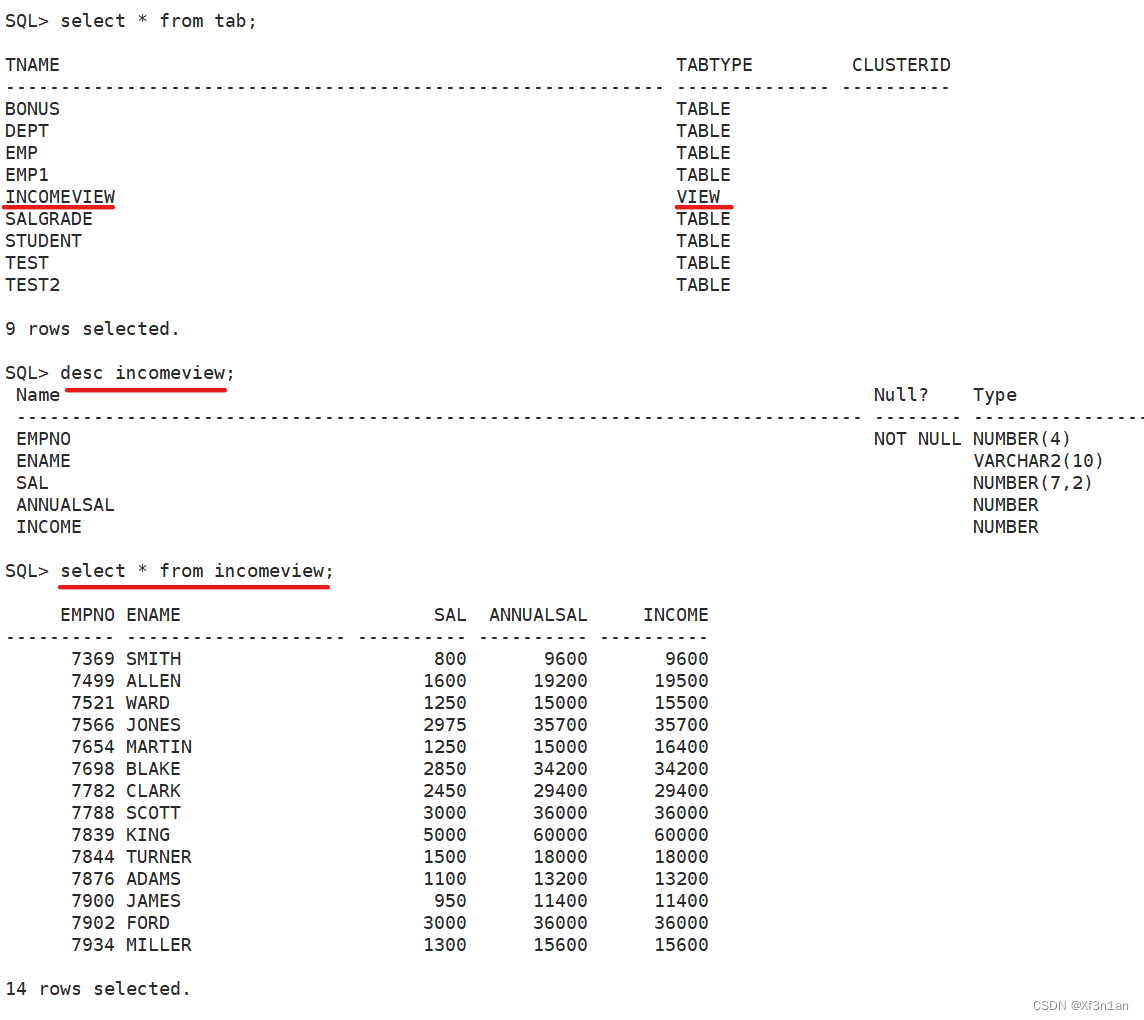
视图的优点
1.简化复杂查询:
原来分组、多表、子查询等可以用一条select * from xxxview代替。
视图可以看做是表的复杂的SQL一种封装。
2.限制数据访问:
只看视图的结构和数据是无法清楚视图是怎样得来的。可以限制数据的访问。
注意:
1.视图不能提高性能
2.不建议通过视图对表进行修改。
创建视图细节

视图只能创建、删除、替换。(不能修改,修改即替换replace)
如:刚刚创建的incomeview,其他语句不变,将create一行改写成:
SQL> create or replace view incomeview 视图不存在则创建、存在则替换。
as
select…… from…..where…..
with read only 可以将视图设为只读视图。
总结一句话:不通过视图做insert、update、delete操作。因为视图提供的目的就是为了简化查询。
删除视图:SQL> drop view testview

序列
可以理解成数组:默认,从[1]开始,缓存长度[20] [1, 2, 3, 4, 5, 6, …, 20] 在内存中。
由于序列是被保存在内存中,访问内存的速率要高于访问硬盘的速率。所以序列可以提高效率。
序列的使用
- 初始状态下:指针指向1前面的位置。欲取出第一个值,应该将指针向后移动。每取出一个值指针都向后移。
- 常常用序列来指定表中的主键。
- 创建序列:create sequence myseq 来创建一个序列。

NOCACHE表示没有缓存,一次不产生20个,而只产生一个。
创建序列


序列的属性
每个序列都有两个属性nextval和currval。
NextVal 必须在CurrVal之前被指定。因为初始状态下,CurrVal指向1前面的位置,无值。
对于新创建的序列使用SQL> select myseq.currval from dual 出错。


使用序列给tmp表创建主键tid:
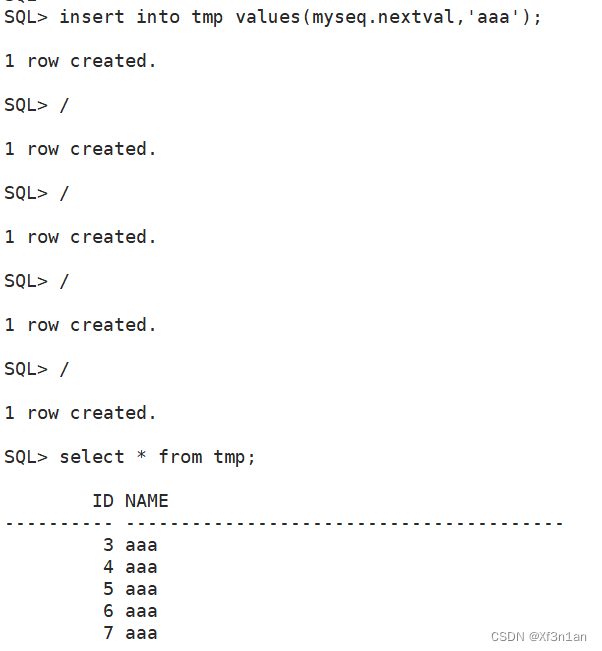

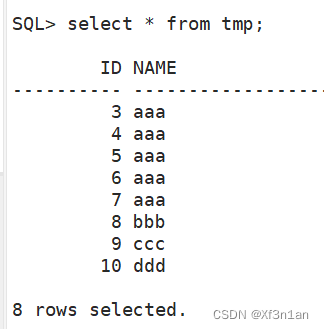
查询序列的属性:SQL> select * from user_sequences; user_sequences为数据字典视图。

使用序列需要注意的问题
- 序列是公有对象,所以多张表同时使用序列,会造成主键不连续。
- 回滚也可能造成主键不连续。 如:多次调用insert操作使用序列创建主键。但是当执行了rollback后再次使用insert借助序列创建主键的时候,nextval不会随着回滚操作回退。
- 掉电等原因,也可能造成不连续。由于代表序列的数组保存在内存中,断电的时候内存的内容丢失。恢复供电时候,序列直接从21开始。
索引
索引,相当于书的目录,提高数据检索速度。提高效率(视图不可以提高效率)。
- 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中。
- 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度。
- 索引一旦建立, Oracle 管理系统会对其进行自动维护, 而且由 Oracle 管理系统决定何时使用索引. 用户不用在查询语句中指定使用哪个索引。
- 在删除一个表时, 所有基于该表的索引会自动被删除。
- 通过指针加速 Oracle 服务器的查询速度。
- 通过快速定位数据的方法,减少磁盘 I/O。
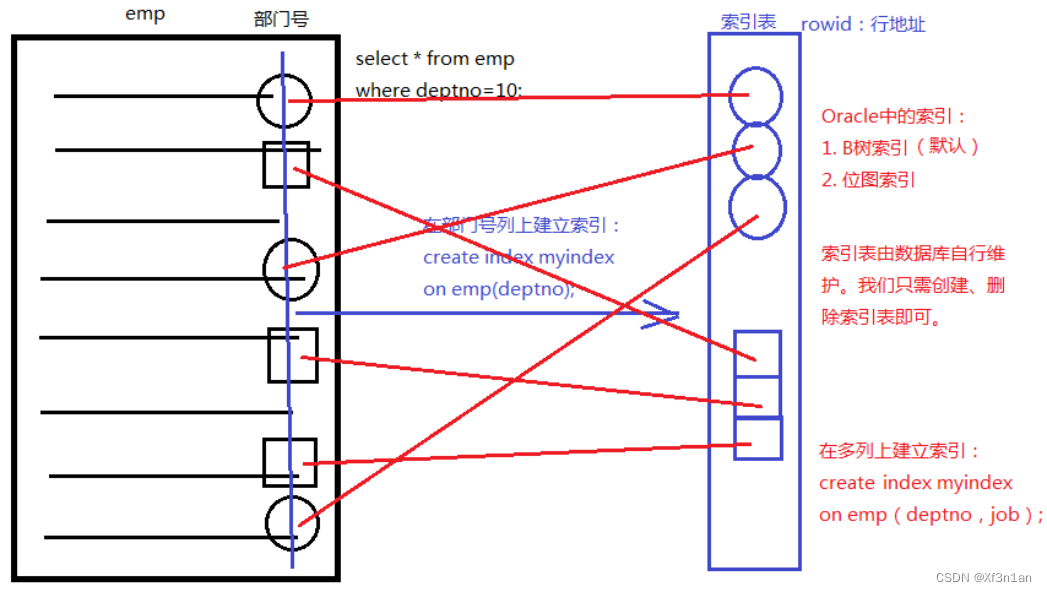
上图中:
1.emp表中保存数据,其中包含部门号列。有10号部门、20号部门员工。
2. 当 select * from emp where deptno=10 的时候。由于10号部门员工不连续,没规律,为了提高访问速度,可以在数据库中,依照rowid给deptno列建立索引。
SQL> create index myindex on emp(deptno)

这样就建立了“索引表”。可以通过rowid保存的行地址快速的找到表中数据。即使表中数据不连续。
3. 建立了索引以后,如果再执行select语句的时候,会先检查表上是否有索引表。如果有,可以通过有规律的rowid找到不联系的数据。
4. Oracle的数据库中,索引有B树索引(默认)和 位图索引两种。
5. 使用create index 索引表名 on 表名(列名1, 列名2…);来创建索引表。由数据库自动进行维护。
使用主键查询数据最快速,因为主键本身就是“索引”,所以检索比较快。
删除索引:SQL> drop index myindex;

索引使用的场景
以下情况可以创建索引:
列中数据值分布范围很广。
列经常在 WHERE 子句或连接条件中出现。
表经常被访问而且数据量很大。
下列情况不要创建索引:
表很小。
列不经常作为连接条件或出现在WHERE子句中。
查询的结果集占到表的95%及以上的数据。
表经常更新。
synonym同义词
就是指表的别名。
如:scott用户想访问hr用户下的表employees。默认是不能访问的。需要hr用户为scott用户授权:
SQL> grant select on employees to scott;
hr用户为scott用户开放了employees表的查询权限。
这时scott用户就可以使用select语句,来查询hr用户下的employees表的信息了。

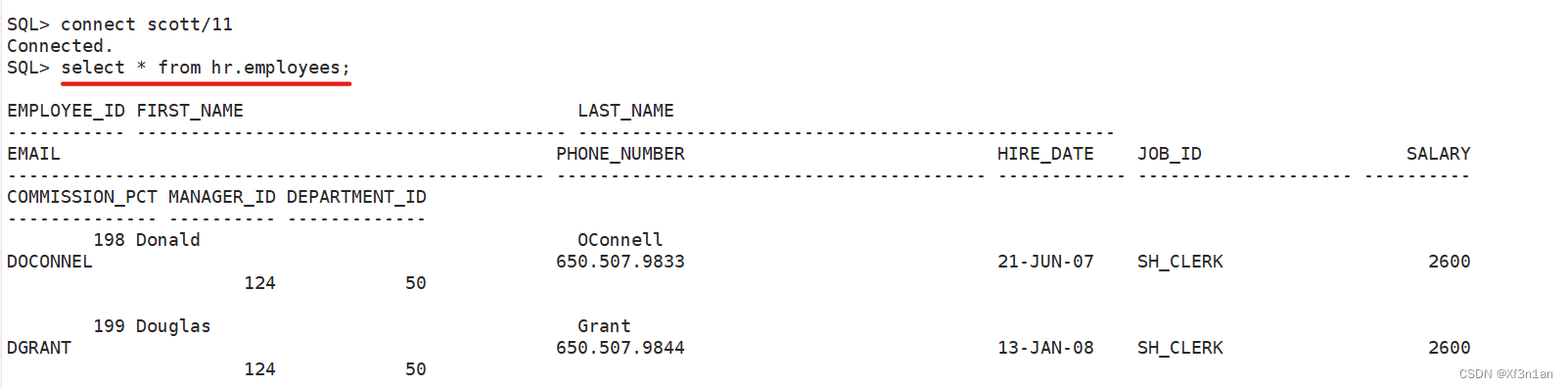
hr.employees名字过长,为了方便操作,scott用户为它重设别名:
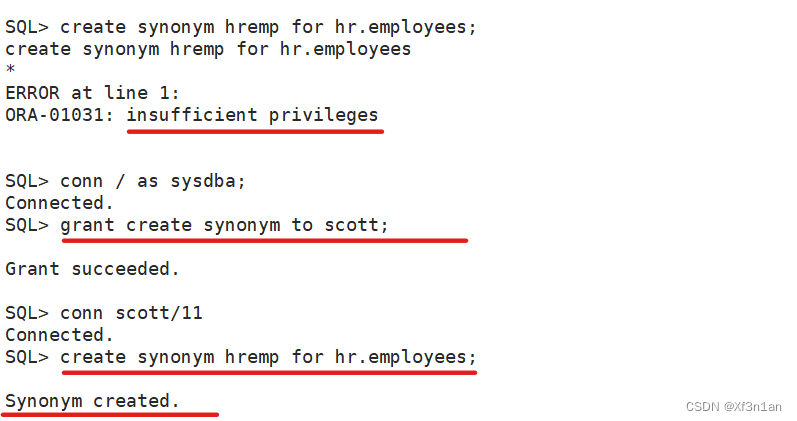
如有权限限制,那么切换管理员登录,给scott用户添加设置同义词权限。
SQL和sqlplus
这里边我们要注意的是,我们之前运行的SQL命令都在sqlplus上执行,但是其实sqlplus除了运行SQL命令外,还支持运行sqlplus自身的命令,这些命令是客户端命令,服务端是不会拿到并运行的。
SQL → 语言,关键字不能缩写,在sqlplus中都得带分号执行。这里边就包括我们之前学的DML、DDL、DCL语句。
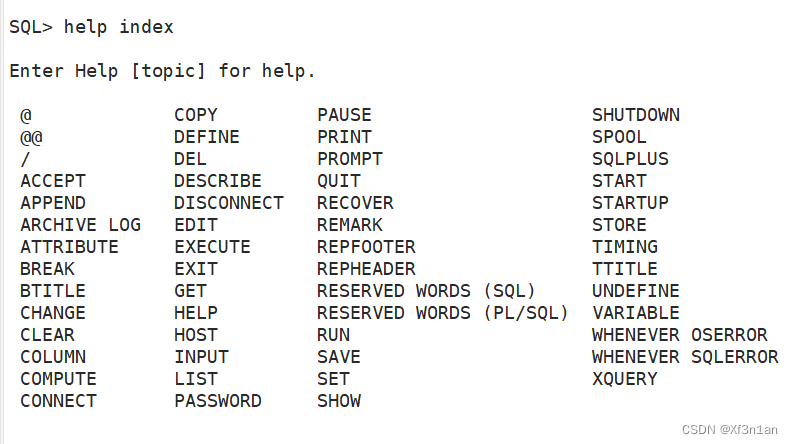
sqlplus → Oracle提供的工具,可在里面执行SQL语句,它配有自己的命令(ed、c、set、col) 特点是缩写关键字。
这里我们只要能够区分哪些是SQL,哪些sqlplus命令就行,最简单的方法就是在sqlplus中使用help index命令,就可以列出sqlplus的命令:














 5348
5348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









