







背景
有数据库A,目标服务器B。现需要将数据库A中的所有表通过一定的转换脚本,以访问目标服务器B的openAPI方式上传到目标服务器B
难点
- 如何通过表读取将数据库中每一行转换成目标服务器B的OpenAPI接口的rquestBody参数
- 如何将每一行的读取到的字段,动态识别并转换。现有的kettle大多数插件都需要指定每一列的字段名称。
- 如何动态的修改每次表读取的表名
{tableName} - 如何避免kettle由于数据量过大产生内存溢出。如:一个表有十万条数据,默认查询会将所有的数据查询到内存中。因此需要将大批量的数据分块处理,如每次处理
{block}条数据,循环的读取表并进行转换。 - 如何实现可持续的同步作业,即:能自动识别哪些数据是已经同步的,那些数据是未同步的。
- 如果将多个不同的表通过同一个job完成数据转换同步
解决方案
- 角色介绍
- 同步脚本配置文件ETLConf.xlsx
- 【转换】配置表信息读取
- 【javaScript脚本】 变量初始化脚本
- 【转换】数据同步脚本
- 【javaScript脚本】 设置前一步执行结果数量
- 【转换】更新配置文件
- 【转换】循环修改变量
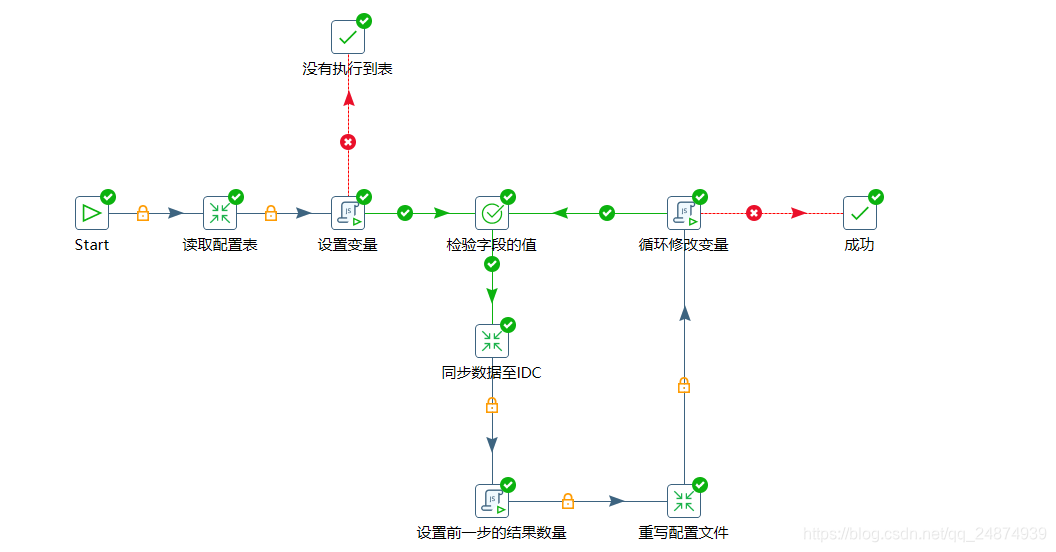
- 整体JOB方案图
其中配置文件如下:
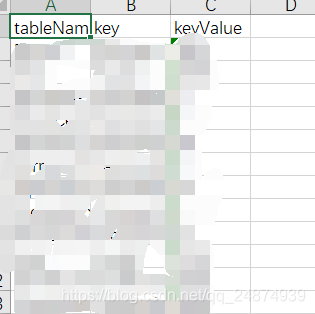
主要三个字段:tableName:表名称,key: 主键字段名称,keyValue主键值。配置文件中每一行数据代表一次循环,操作的表对象是tableName,循环的条件是:数据库中key列值>keyValue。这里也可以换成创建日期,修改日期等。
方案介绍
核心思想是通过kettle的变量去控制整个循环。执行流程如下:
- 读取ETLConf.xlsx中的表配置信息,并在设置变量环节通过javaScript脚本内置方法获取上一个转换的所有结果,将输出的结果转换成json对象保存在变量中,并初始化第一次循环的表名称、表主键、表主键值、循环次数的变量
- 在同步数据转换环节,直接引用父级job中变量,去实现表的动态读取,动态同步转换
- 在同步数据的下一个环节的javaScript中获取同步结果,并设置同步的数量,这个用于切割大批量数据
- 将本次同步的数据id值更新在配置文件中
- 在javaScript中循环修改变量,这一步则是根据条件去决定是否需要更新变量,是继续循环,还是弹出循环
1.读取配置表
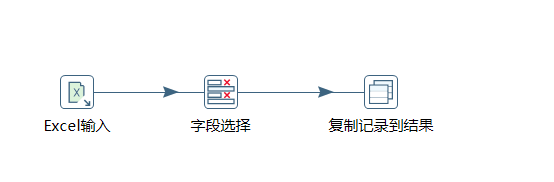
这一步是加载配置文件中的信息,这里使用excel作为配置文件来源,可以替换成其他文本输入插件。最后一定要添加复制记录到结果,这样下一个节点的javaScript才能获取内置对象previous_result
2.设置变量
kettle中的job里面的javaScript和转换中的javaScript是不一样的,而且这个和我们前端的javaScript也不一样,他混合了部分javaScript语法以及java语言进去。具体使用时候一定要结合文档去。
具体脚本代码:
var prevRow=previous_result.getRows();//获取上一个传递的结果
if (prevRow == null &&(prevRow.size()=0))
{
false;
}else{
var transfer=[];
for(var i=0;i<prevRow.size();i++){
var obj={
tableName:""+prevRow.get(i).getString("tableName",""),//注意前面空字符串,不加在json序列化时候会出现toJosn方法找不到的错误提示
key:""+prevRow.get(i).getString("key",""),
keyValue:""+prevRow.get(i).getString("keyValue","0")
};
transfer.push(obj);
}
parent_job.setVariable("size", prevRow.size());//存储执行表的总数量
parent_job.setVariable("i", 0);//循环控制变量
parent_job.setVariable("tableName",prevRow.get(0).getString("tableName",""));//当前循环表名称
parent_job.setVariable("key",prevRow.get(0).getString("key",""));//当前循环主键名称
parent_job.setVariable("keyValue",prevRow.get(0).getString("keyValue","0"));//当前循环的主键值
parent_job.setVariable("transfer",JSON.stringify(transfer));//整个转换的配置文件
true;
}
核心对象是通过previous_result获取到上一个节点的数据,并将这些数据使用json字符串格式保存到parent_job整个job可用的变量中,其中变量i和变量size就是循环条件,类型一个for循环的结构

可以看到previous_result.getRows()方法会返回一个集合,而对象RowMetaAndData的主要操作方法如下:

官方对于kettle job的JavaScript描述地址:https://wiki.pentaho.com/pages/viewpage.action?pageId=4358187
javaDoc地址:https://javadoc.pentaho.com/kettle/org/pentaho/di/core/RowMetaAndData.html
随后加入【检查字段的值】插件

给定进入循环的判断条件
3. 同步数据转换
这个模块主要核心是动态读取表,与动态处理表中的字段

查询sql 语句通过变量去控制:
SELECT top ${block}
*
FROM ${tableName} where ${key} > ${keyValue}
这里是sqlServer的语法。block是设置的单次处理的数据量(在job设置的全局变量),tableName、key、keyValue是此次循环的变量。
重点是动态的获取每一列的字段名称和字段的值。这个功能也依赖转换中的javaScript,内容如下:
//Script here
var tables=getVariable("tableName","tableName")//获取parent_job的变量
var key=getVariable("key","key")
var keyValue=getVariable("keyValue","0")
writeToLog("l","-------------beforeValue="+getVariable("keyValue","0"))
var jsons={
"recordFullName":{
"value":tables+"-"+key
}
}
var filedNames= getInputRowMeta().getFieldNames()//getInputRowMeta为该插件的内置方法
for (var i=0;i<getInputRowMeta().size();i++){
var valueMeta= getInputRowMeta().getValueMeta(i);
var fileName=filedNames[i]
var type =valueMeta.getTypeDesc();//获取数据类型
var value =row[i];//数组row为内置对象,i代表索引,如row[0]为改行第一个数据的值
if(value ==null){
continue;
}
//如果字段名和主键名称一致,则更新变量keyValue的值
if(key.equals(fileName)){
value=ltrim(value)
jsons.recordFullName.value=tables+"-"+value
if(str2num(value)>str2num(keyValue)){
writeToLog("l","-------------value="+value)//l为详细信息日志级别
setVariable("keyValue",num2str(value),"p")
}
}
}
//马赛克代码部分
核心思想是利用getInputRowMeta()获取的对象提取出字段名称、字段类型、最后通过变量中的主键名称key识别出该行数据的主键索引i,最后通过内置的数组对象row[i]获取主键的值,并修改到变量中的主键值keyValue
其中内置对象的参考来源:https://help.pentaho.com/Documentation/8.3/Products/Modified_Java_Script_Value
RowMeta对象说明:https://javadoc.pentaho.com/kettle/org/pentaho/di/core/row/RowMeta.html
- 设置前一步的结果数量
这一步主要是将同步后的数据来进行统计,比如block=5000,统计到同步数据转换的输出结果为4000条,则证明这4000条为最后四千条,需要讲tableName指向下一个,进行下一张表的同步操作。
主要代码:
var previous_count=previous_result.getRows().size();
parent_job.setVariable("previous_count",previous_count);
true;
- 重写配置文件
这一步是将同步后的数据后的keyValue更新到配置文件中,保证即使后续发生错误,前面同步处理后的数据也是有记录的

- 循环修改变量
这里是整个job循环的控制逻辑。通过previous_count和block判断当前表数据是否全部被处理,通过i和size完成不同数据表的切换。代码如下:
var list=JSON.parse(parent_job.getVariable("transfer"));//取出变量中配置信息
var size = new Number(parent_job.getVariable("size"));//总循环次数
var i = new Number(parent_job.getVariable("i"));//当前循环表索引
var previous_count=new Number(parent_job.getVariable("previous_count"));//当前同步处理的数据条数
var block_size=new Number(parent_job.getVariable("block"));//每次处理数据的最大数量
//读取到表记录为0
if(previous_count==0){
if(i+1<size){
obj=list[i+1];
parent_job.setVariable("tableName", obj.tableName);
parent_job.setVariable("key", obj.key);
parent_job.setVariable("keyValue", obj.keyValue);
parent_job.setVariable("i",i+1);
parent_job.setVariable("count",0);
true;
}else{
false;
}
}
if(previous_count<block_size){
//跳出循环
if(i+1<size){
obj=list[i+1];
parent_job.setVariable("tableName", obj.tableName);
parent_job.setVariable("key", obj.key);
parent_job.setVariable("keyValue", obj.keyValue);
parent_job.setVariable("i",i+1);
parent_job.setVariable("count",0);
true;
}else{
false;
}
}else{
//继续执行
true;
}
总结
循环调度核心思想就是通过全局变量去保存循环中的变量,并且通过job中的JavaScript脚本去控制循环条件















 2681
2681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









