






sql优化是一个复杂问题:
一般我们所谓的优化是指两种情况:1. 数据的新增和修改的效率优化; 2.sql查询优化。
现实开发中大部分优化是指sql查询优,慢查询优化的方案五花八门,但就是没有一个,让我照着做,就能解决问题的方案。
那么,我来做一个。
在此之前,想起一个故事:
战国时,魏文王问起扁鹊医术如此高明,是否还有比扁鹊更厉害的医者的时候。
扁鹊答到:“我大哥的医术最好,二哥次之,我的医术最差。”
魏文王问:那为什么,我没有听过你大哥和二哥呢?
扁鹊解释说:大哥能够在病人没有发病之前,根据汤药,将疾病预防;
二哥擅长在病人疾病初始时,便能发现,解决起来也相对容易。
我擅长解决病入膏肓的“恶疾”,故,人人都知我大名;实则,我大哥,二哥的医术在我之上。
现实开发时,其实也能分层三个层面,去处理慢sql的问题:
1. 开发时,根据业务直接写出一个了一个慢sql, 需要优化成正常sql。这个属于"恶疾",最常见,要花心思,下猛药。
2. 在系统用久后,数据量上来了,慢慢发现的慢sql,需要做的是监测。
3. 在做业务前,需求评审做业务时,为了预防慢sql的产生(或者说,让整体的查询效率更高),需要做的是"预防措施"。
扁鹊强调的是预防大于治理,但在慢查询的问题上,解决顽固慢sql,可能比预防慢sql更重要。不过如果有预防慢sql的习惯,反而从整体上,效率会更高。
根据场景,我们拆解下:
一、单个慢sql的解决方案:
一般写出一个慢sql,出于本能,肯定是先查看下该表有没加上索引,毕竟,加索引,包治百病。
于是,点开表结构,看看,哦~,索引也加上了,多表联查的话,每一张表都瞄一眼。嗯~,都加上了。
但,查询还是慢。为啥?
索引加上了,也不一定走了索引,走了索引,索引乱加,也不一定查询就更快,如果索引都加了,都走了,还是慢,咋办?
加索引理论上就能解决了70%的问题,但是顽固慢sql又怎么处理?
(一)怎么加索引
1. 加索引:
出现慢查询,是效率最合理的方式,那么索引怎么加?
(1) 建立索引原则:
1. 定义主键的数据列一定要建立索引。
2. 定义有外键的数据列一定要建立索引。
3. 对于经常查询的数据列最好建立索引。
4. 在非文本类型的数据类型的字段建索引。
5. 经常用在WHERE子句中的数据列,特别是大表的字段,应该建立索引。
6. 经常出现在关键字order by、group by、distinct后面的字段,应建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
7. 所建索引的数目一般不要超过3个,最多不要超过5个。
8. 复合索引遵循最左原则建立(也就是根据多个条件的顺序,建立复合索引)。
这些是原则,也就是对照这即可。
(2) 加了索引,还是慢怎么办?
一般加上索引,查询速度都会有大幅度提升,但是,大部分开发都是在已经加了索引的基础上进行开发的,有的慢sql加了索引也还是会很慢。因为可能索引失效了。
那么怎么判断索引失效了呢?
在开发的时候,当一个sql查询慢的时候,上来啥也不管,就来一个:加上explain看一下;
倒也没错,毕竟explain叫做执行过程。看看sql在执行阶段到底发生了什么,不是挺好的么?
但是使用explain到底要干么?一个explain的结果参数那么多,这些参数是啥意思,又要怎么看?看完后,要又要做什么?
索引加后,查询还是慢,加上explain来诊断一下,其实最主要的目的就是判断:索引是否失效了。
explain对应的参数和使用:
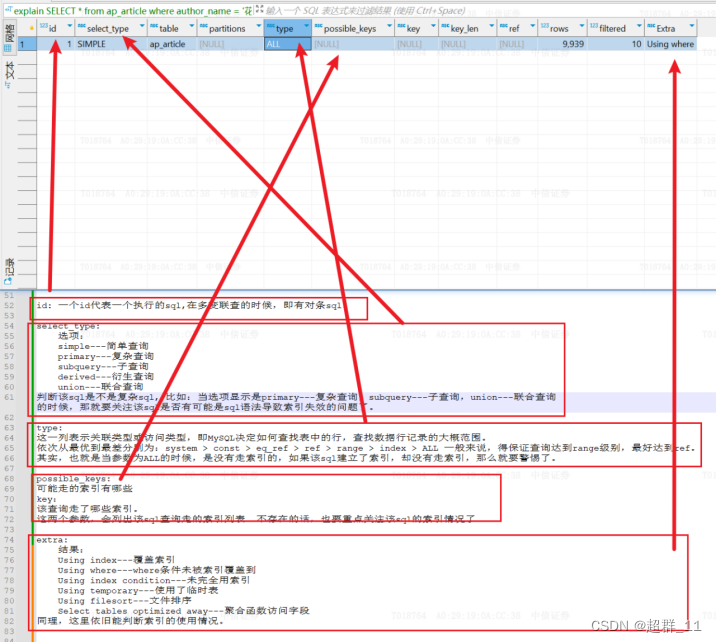
1.
id: 一个id代表一个执行的sql,在多变联查的时候,即有对条sql。
2.
select_type:
选项:
simple---简单查询
primary---复杂查询
subquery---子查询
derived---衍生查询
union---联合查询
判断该sql是不是复杂sql, 比如:当选项显示是primary---复杂查询,subquery---子查询,union---联合查询 的时候,那就要关注该sql是否有可能是sql语法导致索引失效的问题了。
3.
type:
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL 一般来说,得保证查询达到range级别,最好达到ref。
其实,也就是当参数为ALL的时候,是没有走索引的,如果该sql建立了索引,却没有走索引,那么就要警惕了。
4.
possible_keys:
可能走的索引有哪些
key:
该查询走了哪些索引。
这两个参数,会列出该sql查询走的索引列表。不存在的话,也要重点关注该sql的索引情况了。
5.
extra:
结果:
Using index---覆盖索引
Using where---where条件未被索引覆盖到
Using index condition---未完全用索引
Using temporary---使用了临时表
Using filesort---文件排序
Select tables optimized away---聚合函数访问字段
同理,这里依旧能判断索引的使用情况。
其实explain最重要的事情,就是看一个复杂sql的时候,索引的情况和复杂sql的哪些条件会导致索引失效。
参考链接: 《explain参数的作用》
https://blog.csdn.net/qq_41931364/article/details/121848865?ops_request_misc=&request_id=&biz_id=102&utm_term=mysql%E4%B8%ADexplian&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-121848865.142^v96^pc_search_result_base5&spm=1018.2226.3001.4187
大多数慢sql都是多表查询,这几个参数,主要的作用是判断哪些sql有没走索引,哪些sql的具体索引是否失效;已经该sql是否不是一个复杂sql(复杂sql慢查询可能性就比较大了)
说白了,检测几个参数,定位具体sql,具体问题。
最后都会得到两个结果:
第一种就是,索引失效了,那么就可以确定是哪个sql的哪些建立的索引失效了,大致是什么原因失效的。第二种就是,索引没有失效。
那么,索引失效了怎么办?
- 分析索引失效原因,避免失效。
索引失效常见原因:
1.不满足最左前缀原则
2.范围索引列没有放在最后
3.使用了select *
4.索引列上有计算
5.索引列上使用了函数
6.字符类型没加引号
7.用is null和is not null没注意字段是否允许为空
8.like查询左边有%
9.使用or 关键字导致失效
(2)索引失效的常见误区
1.使用not in会导致索引失效
2.使用不等于号会导致索引失效
3.order by索引字段顺序不当导致索引失效
然后根据expain的结果,对症下药,确定哪一条,如何改成正确的sql规范,这个一块就不细讲,毕竟如果能确定问题,百度都能有答案。
参考资料:《索引失效的常见原因》
https://blog.csdn.net/weixin_42039228/article/details/123255722?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170012246416800226591684%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170012246416800226591684&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-6-123255722-null-null.142^v96^pc_search_result_base5&utm_term=mysql%E7%B4%A2%E5%BC%95%E5%A4%B1%E6%95%88&spm=1018.2226.3001.4187
索引失效,本质上还是改变sql的方式让其避免失效。
避免失效,本质还是让sql查询变快,命中索引是一个方法,但是同时在开发的过程中,规范的语法,也能相对带来查询的效率。
规范的sql语法。
1、使用where条件语句限制要查询的数据,避免返回多余的行。where限定的越精准,查询速度越快。
2、尽量避免select *,改使用select 字段名,避免返回多余的列。
3、避免在where 子句中的 “=” 左边进行内置函数、算术运算或其他表达式运算。(设置的字段索引更容易失效)
4、避免在 where 子句中使用 != 或 <> 操作符。(设置的字段索引更容易失效)
5、避免在 where 子句中使用or操作符。
6、where子句中考虑用默认值代替null。(原因:不用is null 或者 is not null 不一定不走索引了,这个跟mysql版本以及查询成本有关。把null值,换成默认值,很多时候让走索引成为可能。)
7、不要在where字句中使用not in。(not in 不走索引,建议使用not exsits 和 left join优化语句。)
8、合理使用exist & in。(in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。如果查询的两个表大小相当,那么用in和exists差别不大,则子查询表大的用exists,子查询表小的用in。)
9、谨慎使用distinct关键字
10、谨慎使用limit。
11、优化like语句:like语句后跟"%%"走不了索引。尽量让字段值在前。
12、避免在查询字段进行二次内置函数、算术运算或其他表达式运算。
其实所谓的sql规范,也包含很多避免索引失效的方法。解决慢sql,其实回到本质也就分成两步。
第一步: 规范书写sql。
第二步: 规范加上索引。
但但但,如果索引没有失效,sql也相对规范,但sql还是慢。怎么办?
其实sql慢也是有前置条件的,比如你多表联查,大概率上肯定是比单表查询慢的,一张表如果数量超过500w条,且字段较多,即使加上索引,也必然查询会相对而言的变慢。
这种主观条件造成的因素,那么就只能寻求其他方法解决了,那么怎么解决。
其实本质也就两张情况:
(1)单表数据量过大。
解决的方案:
- 分库分表。但不建议。
- 建立主从复制。
(这两种方案,又涉及更多的知识点,本篇还是回到sql层面讲)
(2)多表联查,关联表过多。
既然关联的表过多,那么想办法如何把表变少
- 使用存储过程,重新根据库表,洗成一张满足业务的单表(其他方式也可以,本质就是按业务在不影响原有业务的情况建立新的表)。

存储过程只是一种思路,如果有一个业务非常重要,其中一个查询非要解决一个慢查询,一般用这样的方式,可能是本身确实数据量已经到了1000w级别的数据,加索引啥的都没有效果,分库分表的方案代价又高。
那么把其中一张,或者几张表,设计到的业务数据,洗成单表数据量小的情况,也可以解决慢查询的问题。
二、监测SQL方案:
有些慢查询,是慢慢随着数据量增加,慢慢变成为了慢sql。
这些情况,就要有定时的预警系统,检测到慢sql,才能解决慢sql。
- 开启mysql慢查询检测日志:
在mysql中,有记录慢sql的检测日志,只需要开启,就能时实的查看在数据库中有多少慢sql执行时间过长。
1.开启慢查询日志:
set global slow_query_log=on;
2.设置慢查询阈值:
set global long_query_time=3; //(默认10s)
3.确定慢查询日志的文件名和路径
show global variables like 'datadir';
- 查看、修改慢查询阈值(设置的阈值,重启mysql服务后,恢复默认设置)
- 查看监测慢查询
show global variables like '%quer%'; // 查看慢查询信息
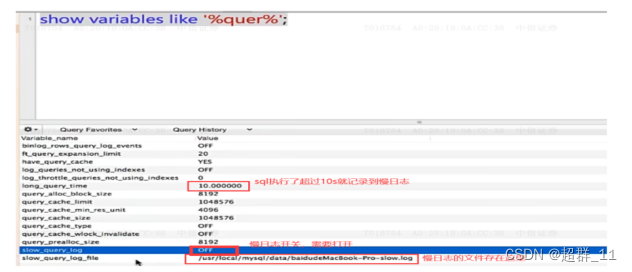
2.修改阈值
set global long_query_time=1;
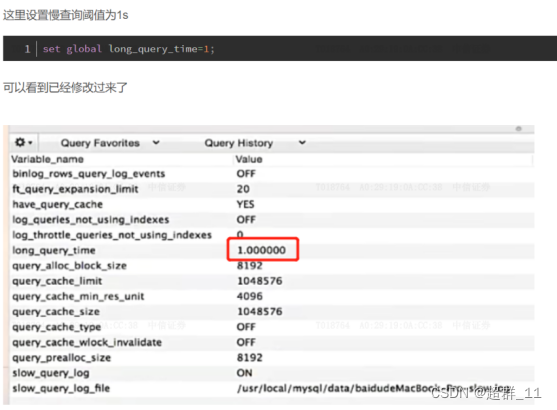
3.查看慢查询次数
show status like '%slow_queries%';// 查看慢查询次数
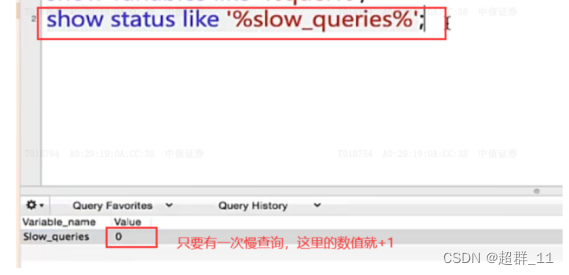
4.查看慢查询日志
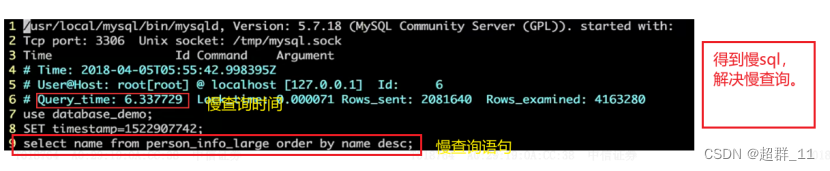 使用mysql的日志监测多少有点鸡肋,一个用户查询时,主要依据的是接口,即使在mysql日志中知道了慢sql,也不一定能确定是哪一个接口,但是这个更像是一个监测的观测站,用于排查。
使用mysql的日志监测多少有点鸡肋,一个用户查询时,主要依据的是接口,即使在mysql日志中知道了慢sql,也不一定能确定是哪一个接口,但是这个更像是一个监测的观测站,用于排查。
实际开发中,监测慢sql,可以使用日志管理系统的方式,记录接口的查询速度来监测慢接口、慢查询。
所以建立一个日志管理系统。可能才更有利于监测慢查询。
三、预防慢sql的预防方案:
防大于治,一流的医生做预防,二流的医生治“恶疾”。要避免查询慢,在表设计、业务规划上,提前做处理也很重要。
落实到具体事情上就是,如何建立一套建表规则。如: 业务如何设计表,表字段如何选择,一些初始索引是否要建立,这些如果提前就建立好规则,那么在数据日益增多的情况时,查询的速度也能有一个托底。
(一)、建表规则:
表设计:
表设计,我们一般是遵循建表三范式,更追求业务在建表上的解耦,也就是表的拆的越来越细。
但是不同的业务也并非是表拆的越细越好;越多的表,也就意味着联表查询越多,那么也就越更可能出现慢查询。
一些指标表,基本上都不是文本类型的数据,反而整合在一张表,效率更高。
所以在业务评审的时候,也可以更多的思考业务,在表的建立上,不拘泥于三范式。
- 关联型业务,避免拆的过细,导致sql开发难度增高,且查询效率变低。
- 梳理出适合建立单表的业务类型。(如:指标表,字典表,城市三级划分,等等)
- 预估业务的数据量,做好数据量过大时的备用方案。
字段规范:
在字段类型上,可做的文章也比较多,除了上面所说的业务建表的思考,在具体的字段规范上,尽量遵循这些原则,也可以提升表的查询效率。
(1)基础
- 表字段建立尽量不超过20个,整表数据量,尽量不超过500w条。
- 主键尽量使用主键自增,避免uuid。
- 货币类型使用DATETIME,避免使用varchar类型。
- 标识数据,尽量int整形,避免使用char。
- 索引
建表初期建立一些基础索引。
1.表的主键和外键: 主键,和被关联的表的条件字段上。
2.选择性较高的字段:也就是内容重复度小的字段。
3.小字段:与字符串相比,整型字段占用的存储空间较少,因此整型较为适合选作索引。
四:sql优化之外
虽然,但是。以上讲的仅是从mysql本身去解决查询慢的问题,如果我们把视角放高一点的话,处理慢查询,方法其实也多种多样。
- 开发上的细节:
比如在开发中:针对数据的传参上

如果,可以让前端带参调用接口,避免在mysql函数或者java自己生成上构建参数。这些细节处理,都可以提升整个接口的查询速度。
2. 把sql优化提升到接口优化:
作为一名用户,他只关心调用接口速度,如果站在优化接口的角度,其实方式方法会更多:
比如可以使用缓存,也可以集成第三方工具es(改变查询方式),也可以使用多线程进行多线程组装;甚至可以跟产品讨论,将单一查询变成分页查询。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









