




文章目录
总结:
注册:服务提供者,上线后会发送个人信息给服务器(包括ip端口等)
发现:调用者上线后会主动获取一次在线服务者列表,并保存本地缓存
心跳:服务都会每5秒发送一次心跳给服务器,服务器3次(15秒),没收到讲标记为不健康。
主动告知:当服务器感知到有服务不健康,会主动推送给调用端最新的列表。
原理图:
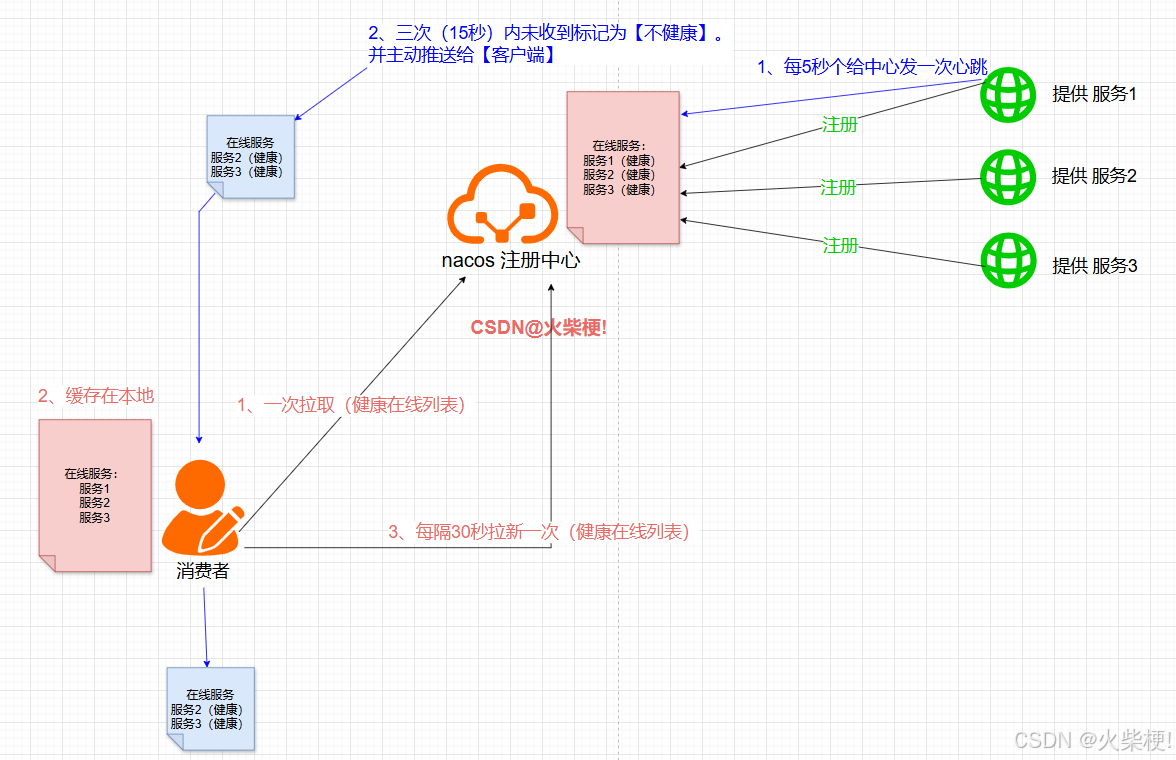
一篇搞懂 Nacos 服务注册与发现:原理、流程与掉线判断
在微服务架构中,“服务注册与发现”是核心基础设施——它解决了“微服务之间如何找到对方”的问题。Nacos(Dynamic Naming and Configuration Service)作为阿里开源的服务治理平台,不仅提供服务注册与发现,还支持配置中心、动态 DNS 等能力,其服务注册与发现模块更是以高可用、高实时性、易扩展的特点被广泛使用。
本文将从核心模型入手,逐层拆解 Nacos 服务注册、服务发现的完整流程,以及“如何判断服务掉线”的底层逻辑,帮你彻底掌握其工作原理。
一、先搞懂 Nacos 的核心模型:服务是怎么“分级存储”的?
在理解流程前,必须先明确 Nacos 对“服务”的定义——它不是简单的“服务名+IP+端口”,而是一套分级存储模型,确保服务在多环境、多集群下的隔离与灵活管理。
Nacos 的服务存储层级从粗到细分为 5 层,核心是「实例(Instance)」,上层结构用于隔离和分组:
Namespace(命名空间) → Group(分组) → Service(服务) → Cluster(集群) → Instance(实例)
| 层级 | 作用说明 | 示例场景 |
|---|---|---|
| Namespace | 最高级隔离,通常用于区分环境(如开发、测试、生产) | 生产环境用 prod-namespace,测试环境用 test-namespace |
| Group | 同一 Namespace 下的服务分组,用于区分业务域(如支付、订单、用户) | 支付相关服务归为 pay-group,订单相关归为 order-group |
| Service | 具体的服务标识,是服务注册与发现的核心粒度,通常用「服务名」唯一标识 | 订单服务名为 order-service,用户服务名为 user-service |
| Cluster | 同一服务下的实例集群,通常对应物理部署集群(如上海集群、北京集群) | order-service 在北京部署的实例归为 bj-cluster,上海归为 sh-cluster |
| Instance | 服务的具体实例(即一个运行中的微服务节点),包含 IP、端口、健康状态等元数据 | order-service 的一个实例:IP=192.168.1.100,Port=8080,权重=10 |
此外,实例(Instance)还有一个关键属性:是否临时实例(Ephemeral),这直接决定了后续“服务掉线判断”的逻辑:
- 临时实例(Ephemeral=true):生命周期与客户端心跳绑定,客户端下线/掉线后,Nacos 会自动删除该实例(适合普通微服务,如 Spring Cloud 应用)。
- 持久化实例(Ephemeral=false):生命周期由用户手动管理,客户端掉线后,Nacos 仅标记为“不健康”,不会自动删除(适合核心服务/第三方服务,如数据库、Redis)。
二、服务注册:微服务如何“告诉”Nacos 自己在线?
服务注册的本质是:服务提供者(Provider)启动后,主动向 Nacos Server 上报自己的实例信息,让 Nacos 记录并管理。
整个流程分为「提供者端」和「Nacos Server 端」两部分,支持 HTTP 和 GRPC 两种协议(GRPC 性能更高,是 Nacos 2.x 的推荐方式)。
2.1 服务注册完整流程(以临时实例为例)
-
提供者初始化与配置加载
服务提供者(如 Spring Cloud 应用)启动时,会加载 Nacos 客户端配置(如 Nacos Server 地址、服务名、Namespace、是否临时实例等),并初始化NacosNamingService客户端对象。 -
构造注册请求
客户端封装实例的核心元数据,生成注册请求:- 核心参数:
serviceName(服务名)、ip(实例 IP)、port(实例端口)、ephemeral(是否临时)、metadata(额外信息,如权重、健康状态、集群名)。
- 核心参数:
-
发送注册请求到 Nacos Server
客户端通过 HTTP/GRPC 协议向 Nacos Server 发送registerInstance请求。- 若为集群部署,客户端会优先选择健康的 Nacos Server 节点(通过内置负载均衡)。
-
Nacos Server 验证与处理
Server 收到请求后,先做合法性校验(如参数是否完整、Namespace/Group 是否存在),然后执行核心逻辑:- 第一步:内存存储
将实例信息存入内存中的「服务注册表」(基于ConcurrentHashMap实现,结构为Namespace → Group → Service → Cluster → InstanceList),确保后续查询的高性能。 - 第二步:持久化存储(可选)
若为持久化实例,或 Nacos 配置了外部数据库(如 MySQL),会将实例信息写入数据库(表config_infoservice_info等),避免 Server 重启后数据丢失;
若为临时实例,默认仅存内存(依赖后续心跳维持,重启后需重新注册)。
- 第一步:内存存储
-
集群数据同步(Server 集群场景)
若 Nacos Server 是集群部署,需保证所有节点的服务注册表一致:- 临时实例:采用 Raft 协议同步(强一致性),确保所有节点都能感知到实例的注册状态(避免部分节点漏记实例)。
- 持久化实例:采用 Distro 协议同步(最终一致性),优先保证可用性,允许短暂的数据不一致(后续会自动同步)。
-
返回注册结果给提供者
Server 处理完成后,向客户端返回OK响应,提供者确认注册成功,开始后续的心跳上报(临时实例)。
2.2 临时实例 vs 持久化实例的注册差异
| 对比维度 | 临时实例(Ephemeral=true) | 持久化实例(Ephemeral=false) |
|---|---|---|
| 存储方式 | 仅内存(重启后需重新注册) | 内存+数据库(持久化,重启不丢失) |
| 集群同步协议 | Raft(强一致性) | Distro(最终一致性) |
| 后续依赖 | 必须维持心跳 | 无需心跳(依赖 Server 主动探测) |
三、服务发现:微服务如何“找到”其他服务?
服务发现的本质是:服务消费者(Consumer)通过 Nacos Server 获取目标服务的实例列表,然后基于负载均衡选择一个实例发起调用。
Nacos 提供两种服务发现机制,兼顾“实时性”和“可用性”:主动拉取和主动推送。
3.1 机制 1:主动拉取(Pull)—— 消费者定期查询
主动拉取是“消费者主导”的模式,适合对实时性要求不高的场景,优点是压力分散(无需 Server 维护大量长连接)。
流程步骤:
-
消费者订阅服务
消费者启动时,通过 Nacos 客户端调用subscribe方法,订阅目标服务(需指定serviceName、Namespace、Group)。 -
首次拉取实例列表
客户端向 Nacos Server 发送getAllInstances请求,Server 从内存注册表中筛选出“健康的实例”(过滤不健康实例),返回给消费者。 -
消费者本地缓存
消费者将获取到的实例列表缓存到本地(如ConcurrentHashMap),后续调用服务时直接从本地缓存获取,避免频繁请求 Server,提升可用性(即使 Server 短暂不可用,消费者仍能调用已缓存的实例)。 -
定期拉取更新
消费者启动一个定时任务(默认周期 30 秒,可通过nacos.client.config.pull.interval配置),定期向 Server 拉取最新实例列表,对比本地缓存:- 若实例列表有变化(如新增实例、实例下线),则更新本地缓存;
- 若无变化,不做处理。
3.2 机制 2:主动推送(Push)—— Server 实时通知
主动推送是“Nacos Server 主导”的模式,基于 GRPC 长连接实现,适合对实时性要求高的场景(如秒杀、高频调用服务),优点是实例变化能实时同步给消费者。
流程步骤:
-
建立 GRPC 长连接
消费者订阅服务时,会与 Nacos Server 建立 GRPC 长连接(替代 HTTP 短连接),Server 会记录“消费者-服务”的订阅关系(存入subscriptionMap)。 -
Server 监听实例变化
Nacos Server 内部有一个“实例变更监听器”,当服务实例发生变化(如注册新实例、实例健康状态变更、实例下线)时,监听器会触发通知。 -
Server 主动推送变更
Server 根据subscriptionMap,找到订阅该服务的所有消费者,通过 GRPC 长连接将“实例变更信息”主动推送给消费者。 -
消费者更新本地缓存
消费者收到推送后,立即更新本地缓存,并可触发自定义回调(如重新初始化负载均衡器)。
3.3 两种发现机制的对比
| 对比维度 | 主动拉取(Pull) | 主动推送(Push) |
|---|---|---|
| 实时性 | 较低(延迟取决于拉取周期,默认30s) | 极高(实例变化秒级同步) |
| 网络开销 | 低(定期短连接) | 高(维持长连接,推送频繁时带宽高) |
| Server 压力 | 分散(消费者主动拉取) | 集中(Server 需管理大量长连接) |
| 可用性 | 高(本地缓存兜底) | 较高(长连接断连后需重新建立) |
| 适用场景 | 普通微服务调用 | 实时性要求高的服务(如秒杀) |
3.4 最终调用:负载均衡选择实例
消费者获取实例列表后,会通过 负载均衡策略 选择一个健康实例发起调用(Nacos 客户端内置负载均衡器):
- 默认策略:加权随机(权重越高的实例,被选中的概率越大,可用于流量调控);
- 其他策略:轮询、IP 哈希(需自定义扩展)。
四、服务掉线判断:Nacos 如何知道服务“挂了”?
服务掉线的本质是“实例不可用”,Nacos 通过 健康检查(Health Check) 机制判断实例状态,核心逻辑与“实例类型(临时/持久化)”强相关。
4.1 核心逻辑:健康检查的两种模式
Nacos 针对临时实例和持久化实例,设计了完全不同的健康检查方案,确保“不误判、不漏判”。
模式 1:临时实例 → 客户端主动心跳(Beat Check)
临时实例的生命周期依赖“客户端心跳”——只要客户端还在发心跳,Nacos 就认为实例健康;一旦心跳中断,就判定为掉线。
完整流程:
-
客户端定期发送心跳
临时实例注册成功后,客户端会启动定时任务(默认周期 5 秒,可通过nacos.client.naming.beat.interval配置),向 Nacos Server 发送beat心跳请求,携带实例的serviceName、ip、port等信息。 -
Server 更新心跳时间
Server 收到心跳后,会更新内存注册表中该实例的「最后心跳时间(lastBeatTime)」,并标记实例状态为「健康(HEALTHY)」。 -
Server 心跳检查线程监控
Nacos Server 启动一个“心跳检查线程”(默认周期 15 秒,可通过nacos.naming.health.check.heartbeat.interval配置),定期扫描所有临时实例:- 第一步:标记不健康
若实例的「当前时间 - lastBeatTime」> 不健康阈值(默认 15 秒,即 3 次没收到心跳),则将实例状态标记为「不健康(UNHEALTHY)」,并同步到集群其他节点。 - 第二步:删除实例(掉线处理)
若实例的「当前时间 - lastBeatTime」> 实例删除阈值(默认 90 秒,即 18 次没收到心跳),则判定实例“已掉线”,从内存注册表中删除该实例,并触发“实例下线通知”(推送给订阅该服务的消费者)。
注意:若客户端正常下线(如执行
shutdown命令),会主动向 Server 发送deregisterInstance请求,Server 会立即删除实例,无需等待心跳超时。 - 第一步:标记不健康
模式 2:持久化实例 → Server 主动探测(Probe Check)
持久化实例不依赖客户端心跳(避免因客户端网络波动误判),而是由 Nacos Server 主动发起探测,判断实例是否可用。
完整流程:
-
Server 配置探测规则
管理员可在 Nacos 控制台为持久化实例配置探测方式(默认是 TCP 探测,也支持 HTTP/HTTPs 探测):- TCP 探测:Server 尝试与实例的 IP:Port 建立 TCP 连接,能连接则认为健康;
- HTTP 探测:Server 向实例的指定 URL(如
/actuator/health)发送 GET 请求,返回 200 则认为健康。
-
Server 定期发起探测
Server 启动“主动探测线程”(默认周期 20 秒,可通过nacos.naming.health.check.timeout配置),对所有持久化实例执行探测。 -
判断健康状态并处理
- 若探测成功:标记实例为「健康(HEALTHY)」;
- 若探测失败(如连接超时、返回非 200):连续失败达到阈值(默认 3 次)后,标记实例为「不健康(UNHEALTHY)」,并推送给消费者(消费者会过滤不健康实例);
- 关键差异:持久化实例即使长期不健康,Nacos 也不会自动删除,需管理员手动在控制台执行“删除实例”操作(避免核心服务被误删)。
4.2 健康检查核心参数配置表
| 参数名 | 作用说明 | 默认值 | 适用实例类型 |
|---|---|---|---|
nacos.client.naming.beat.interval | 客户端心跳周期 | 5 秒 | 临时实例 |
nacos.naming.health.check.heartbeat.interval | Server 心跳检查周期 | 15 秒 | 临时实例 |
nacos.naming.ip.delete.timeout | 临时实例删除阈值(心跳超时) | 90 秒 | 临时实例 |
nacos.naming.health.check.timeout | Server 主动探测周期 | 20 秒 | 持久化实例 |
nacos.naming.health.check.retry | 主动探测失败重试次数 | 3 次 | 持久化实例 |
五、关键补充:Nacos 服务治理的“高可用”保障
除了核心流程,Nacos 还通过以下机制确保服务注册与发现的高可用:
-
Server 集群部署
至少部署 3 个 Nacos Server 节点,通过 Raft 协议选举 Leader 节点,避免单点故障——即使部分节点下线,剩余节点仍能提供服务。 -
数据一致性策略
- 临时实例用 Raft 强一致性:确保所有节点对实例状态的判断一致,避免“部分节点认为实例在线,部分认为下线”;
- 持久化实例用 Distro 最终一致性:优先保证服务可用,允许短暂的数据不一致,后续通过后台任务同步。
-
客户端容错
- 本地缓存:消费者缓存实例列表,即使 Nacos Server 不可用,仍能基于缓存调用服务;
- 失败重试:客户端调用 Server 失败时,会自动重试其他健康节点(内置负载均衡)。
六、总结:Nacos 服务注册与发现的完整链路
把前面的流程串起来,就是一条完整的“服务治理链路”:
- 服务注册:提供者启动 → 上报实例信息到 Nacos Server → Server 存储(内存+持久化)并集群同步 → 返回注册成功。
- 服务发现:消费者启动 → 订阅服务 → 建立 GRPC 长连接(或定期拉取)→ 获取实例列表并本地缓存 → 负载均衡选择实例调用。
- 健康检查:
- 临时实例:客户端发心跳 → Server 监控心跳 → 超时标记不健康/删除实例;
- 持久化实例:Server 主动探测 → 失败标记不健康 → 手动删除实例。
- 状态同步:实例状态变化(健康→不健康、下线)→ Server 推送给订阅的消费者 → 消费者更新本地缓存。
附录:常见问题与解决方案
| 问题场景 | 可能原因 | 解决方案 |
|---|---|---|
| 服务注册成功,但消费者看不到 | 1. Namespace/Group 配置不一致;2. 实例未健康 | 1. 核对消费者与提供者的 Namespace/Group;2. 检查实例健康状态 |
| 临时实例频繁被误删 | 1. 心跳周期过长;2. 网络波动导致心跳丢失 | 1. 调小心跳周期(如 3 秒);2. 检查网络稳定性,增加重试 |
| 服务发现实时性差 | 1. 仅用主动拉取,周期过长;2. GRPC 连接断连 | 1. 启用 GRPC 推送;2. 调小拉取周期(如 10 秒) |
| 持久化实例不健康但删不掉 | 持久化实例默认不自动删除 | 1. 修复实例后等待 Server 重新探测;2. 控制台手动删除 |
通过以上内容,相信你已完全掌握 Nacos 服务注册与发现的核心原理——从模型到流程,从健康检查到高可用保障,每一步都清晰可见。在实际使用中,只需根据业务场景选择“临时/持久化实例”,并合理调优心跳、探测参数,就能充分发挥 Nacos 的服务治理能力。
如果文章对你有一点点帮助,欢迎【点赞、留言、+ 关注】,
您的关注是我持续创作的重要动力!有问题欢迎随时交流!多一个朋友多一条路!

















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









