







JUC 之队列 SynchronousQueue 详解
有人说他是容量为1的阻塞队列,通过阅读源码我们发现这种解释并不算正确,下面是作者给出的解释:
A blocking queue in which each insert operation must wait for a corresponding remove operation by another thread, and vice versa. A synchronous queue does not have any internal capacity, not even a capacity of one.
它是一个阻塞队列,每一个插入操作必须等待另一个线程的移除操作,反之亦然。一个没有容量的阻塞队列,甚至连一个容量也没有。意思就是当一个生产线程(put线程)向队列中放入一条数据,它必须等待一个消费线程(take线程)把数据取走,不然生产线程一直阻塞在那里反之也一样。队列不保存任何数据。
它的内部实现有两个,一个是 TransferStack(栈的方式实现,单向链表实现的栈,先进后出(LIFO)),一个是TransferQueue(链表实现,先进先出(FIFO))。下面我们逐个来分析。
核心成员介绍
abstract static class Transferer<E> {
// 提供数据交换的行为,e == null 代表是 消费线程(也即 take线程),e != null 代表是 生产线程(也即 put线程)
abstract E transfer(E e, boolean timed, long nanos);
}
// 带超时时间的 最大自旋次数,注意 CPU 核心数必须大于 > 1,单核CPU 自旋没有意思,纯属浪费CPU资源
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
// 不带超时时间的最大自旋次数
static final int maxUntimedSpins = maxTimedSpins * 16;
// 如果超时时间小于 1 微秒,让程序进行自旋优化,这是一个经验值,因为线程进入 OS 阻塞和唤醒的时间大于 1 微秒
static final long spinForTimeoutThreshold = 1000L;
TransferQueue 实现
基于单向链表实现的FIFO公平队列,尾插、头拿。
成员介绍
static final class QNode {
volatile QNode next;
volatile Object item; // put线程 item != null; take线程 item == null
volatile Thread waiter; // 当前节点的线程信息
final boolean isData; // 用于标识当前节点是 put线程还是 take线程,true 表示 put线程,false 表示 take线程
}
// 初始化头、尾节点
TransferQueue() {
QNode h = new QNode(null, false); // 伪节点
head = h;
tail = h;
}
// 头结点
transient volatile QNode head;
// 伪节点
transient volatile QNode tail;
//
transient volatile QNode cleanMe;
transfer 方法
它的原理同 Exchanger,只不过这里的 take线程携带的数据是 null ,put线程将数据交换给 take线程,而take线程将null交换给put线程。
通过下述源码我们可以看出队列中阻塞的线程要么全是 put线程,要么全是 take线程。通过 QNode 中的 isData 字段来标识节点的类型,
isData = (e != null) true 表示 put线程,false 表示 take线程。
E transfer(E e, boolean timed, long nanos) {
QNode s = null;
boolean isData = (e != null); // true 表示 put线程,false 表示 take线程
for (;;) {
// 保存头尾节点快照
QNode t = tail;
QNode h = head;
if (t == null || h == null)
continue;
if (h == t || t.isData == isData) { // 队列为空 或 是同一类型的线程,那么入队阻塞等待匹配线程过来匹配交换数据
QNode tn = t.next;
if (t != tail) // 不相等表示 尾结点已经被更新,那么重新获取头尾尝试
continue;
if (tn != null) { // tn 不为 null 代表有其它线程加入了队列,尝试帮助更新 tail 节点
// 更新前判断如果 tail 已更新无需帮助其更新 tail 节点,减少一次无畏的CAS 操作,提升性能
// if (tail == t) UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
advanceTail(t, tn);
continue; // 重新获取头尾尝试
}
if (timed && nanos <= 0) // 如果指定了超时时间,并且超时了,那么退出即可
return null;
if (s == null) // 此判断是为了防止在线程首次CASNext失败后重试时重复创建 QNode 节点
s = new QNode(e, isData); // 创建 QNode 节点
if (!t.casNext(null, s)) // 将 s 节点添加到队列中,如果 CAS 失败说明 已经有其它线程加入了队列中,重新获取头尾尝试,
continue;
advanceTail(t, s); // 自我递进 tail 节点
Object x = awaitFulfill(s, e, timed, nanos); // 阻塞等待匹配线程过来进行匹配
if (x == s) { // x == s 表示线程被中断或超时取消了
clean(t, s); // 将 s 节点从队列中移除
return null;
}
// 执行到这一步说明 该节点已经被匹配成功,如果还未从队列中移除,那么更新 head 节点将自己从队列中移除
if (!s.isOffList()) { // return next == this;
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // 匹配过程
QNode m = h.next; // 取出待匹配节点保存在栈上
if (t != tail || m == null || h != head)
continue; // 队列发生了变化,重新获取最新的头尾节点重试
Object x = m.item; // 取出待匹配线程的数据给到 x
if (isData == (x != null) || // 判断 m 节点是否已经被其它线程匹配(如果 m 是 put线程,那么当前线程就是 take线程(isData = false),如果 m 被其它take线程匹配,x 将等于 null; 如果 m 是 take线程,那么 当前线程就是 put线程(isData = true),如果 m 被其它put线程匹配完成,x 将不等于 null)
x == m || // 表示 m 节点已经被取消了
!m.casItem(x, e)) { // CAS 尝试进行匹配
advanceHead(h, m); // 匹配失败,更新 head 重新尝试与队列中其他节点进行匹配
continue;
}
advanceHead(h, m); // 匹配成功,更新 head 节点,并将原 head 从队列中移除(常用手法将其 Next 指向自己,标识自己从链表中断开了)
LockSupport.unpark(m.waiter); // 唤醒阻塞线程
return (x != null) ? (E)x : e;
}
}
}
awaitFulfill 方法
等待匹配线程与之进行匹配过程
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = ((head.next == s) ? // 因为是 FIFO 公平队列,头结点优先进行匹配,所以只有是头结点的时候才能进行自旋优化
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())// 被中断了,取消该节点
// void tryCancel(Object cmp) { UNSAFE.compareAndSwapObject(this, itemOffset, cmp, this);}
s.tryCancel(e);// 将 item 指向 自己,标识节点被取消了
Object x = s.item;
if (x != e)
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e); // 超时了取消
continue;
}
}
if (spins > 0) // 自旋
--spins;
else if (s.waiter == null)
s.waiter = w; // 绑定线程信息,用于阻塞唤醒
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold) // 只有在指定的超时时间 大于 1 微秒的时候才执行 超时阻塞等待操作
LockSupport.parkNanos(this, nanos);
}
}
clean 方法
void clean(QNode pred, QNode s) {
s.waiter = null; // 已经取消了无需在持有线程的引用了
while (pred.next == s) { // 如果你的前一个节点的Next引用不是你自己,那么就意味着你已经从链表中被移除了
QNode h = head;
QNode hn = h.next; //
if (hn != null && hn.isCancelled()) { // 头结点的 next 节点不为空且已经被取消了,那么更新更节点重试(头结点的 next 节点可能就是 你的 前一个节点)
advanceHead(h, hn);
continue;
}
QNode t = tail; // 保存当前伪节点到栈上
if (t == h) return; // 头尾相同表示队列中没有等待线程,其它线程已经将帮你从队列中移除了
QNode tn = t.next;
if (t != tail) // 尾结点发生了变化,重试
continue;
if (tn != null) { // 尾结点的 next 不为空,代表有线程添加到队列中了,但是还没来得及更新 tail 节点,帮助更新tail,然后重试
advanceTail(t, tn);
continue;
}
if (s != t) { // s 不是尾结点,将 s 移除链表
QNode sn = s.next;
// 多线程环境中,线程执行到哪一步CPU时间片用完你无法确定,所以可能你已经被其它线程移除链表,所以增加 sn == s 的判断,如果已经被移除,直接返回即可,无需在进行一次 CAS 操作,浪费性能;如果 s 还未被移除出了出了链表 CAS 尝试移除链表,如果 pred 已经被匹配完成并移除了链表,那么 CAS 也将 执行失败。
if (sn == s || pred.casNext(s, sn))
return;
}
// 执行到这一步说明 pred 节点被移除出了链表
QNode dp = cleanMe; // cleanMe 记录被移除的节点的前一个节点
if (dp != null) { // Try unlinking previous cancelled node
QNode d = dp.next;
QNode dn;
if (d == null || // 如果 d == null 表示 pred 节点是尾结点
d == dp || // 相等 代表该节点已被取消或已与其它线程完成匹配并交换了数据
!d.isCancelled() || // d 节点未取消
(d != t && // d 不是尾结点
(dn = d.next) != null && // 此判断 确保 d 不是尾结点(记住这是多线程并发执行的)
dn != d && // d 节点未被取消
dp.casNext(d, dn)))
casCleanMe(dp, null); // 链表中还有等待节点,清空 cleanMe
if (dp == pred)
return;
} else if (casCleanMe(null, pred)) // 将 pred 节点赋值给 cleanMe,作为一个伪节点存在
return;
}
}
TransferQueue 小结
基于单链表实现的 FIFO 队列,队列中阻塞的节点要么全是 put 线程,要么全是 take 线程,一个阻塞等待另一个线程过来与之进行匹配,否则将一直阻塞在队列中直到被匹配完成退出或阻塞超时退出或被中断退出。在阻塞等待被匹配的过程中,如果你的前一个节点是头结点将会进行自旋优化,尽量避免进入 OS 阻塞。我们还发现作者为了标识节点已被取消,采用了将 节点的 item 设置为 节点 自身,这样其它线程在与之进行匹配 CAS 操作将会失败。通过将 节点的 next 赋值为节点本身,用来标识节点从队列中移除了。
TransferStack 实现
基于栈的方式实现,头插头拿(LIFO,Last In First Out),合理利用了CPU的时间局部性,最新压入栈中的数据依然缓存在 CPU 的 cache 中。
看懂 TransferQueue 的实现原理,在看 TransferStack 的实现应该很容易。下面我们来看看具体实现
成员介绍
static final int REQUEST = 0; // 表示当前节点是 消费者 也即 take 现成
static final int DATA = 1; // 表示当前节点是 生产者 也即 put 现成
static final int FULFILLING = 2; // 表示当前节点正在与后面的节点进行匹配
volatile SNode head;
static final class SNode {
volatile SNode next;
volatile SNode match; // 正在与之进行匹配的节点
volatile Thread waiter;
Object item;
int mode;
}
transfer 方法
与 TransferQueue 不同之处在于 该实现不论你是匹配线程还是待匹配线程都会压入栈顶,匹配线程的模式将被设置为 FULFILLING,表示正在与后面的节点正在进行匹配。当有其它线程发现栈顶节点正在进行匹配,那么当前线程将帮助其完成匹配,然后将这一对匹配线程从栈中弹出。
E transfer(E e, boolean timed, long nanos) {
SNode s = null;
int mode = (e == null) ? REQUEST : DATA; // e 为 NULL 表示消费线程,反之为生产线程
for (;;) {
SNode h = head;
// 头节点为空或新节点与头节点是同一个模式,将其插入栈中
if (h == null || h.mode == mode) {
if (timed && nanos <= 0) { // 如果超时了将其弹出栈中
if (h != null && h.isCancelled()) // match == this
casHead(h, h.next);
else
return null;
}
// 当 头节点为 null 时,创建头节点 赋值给 s ,然后 CAS 更新头节点,CAS 失败重新获取最新头结点重试
// snode 方法,s 已创建时,更新其内容
else if (casHead(h, s = snode(s, e, h, mode))) {
SNode m = awaitFulfill(s, timed, nanos);// 等待匹配线程匹配取走数据,待匹配节点阻塞在该步
if (m == s) { // 相等代表节点已被取消,将其从栈中移除即可
clean(s);
return null;
}
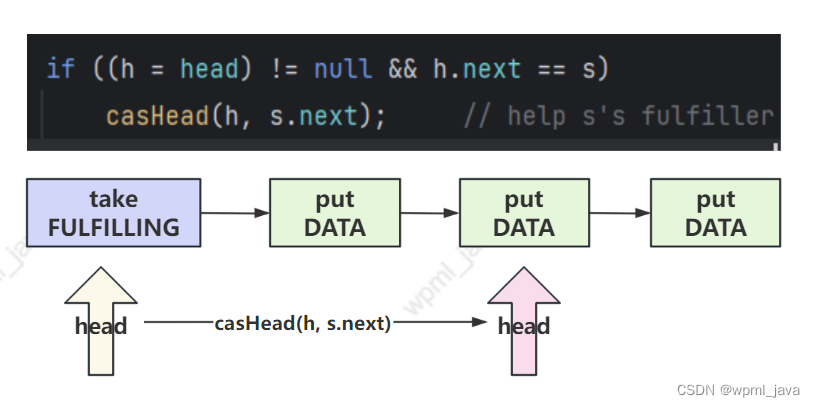
if ((h = head) != null && h.next == s)
casHead(h, s.next); // 更新头结点,如下图
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
// 执行到该if判断表明当前节点与头节点是不同模式,判断头节点是否是正在执行匹配操作的节点,
// 通过 FULFILLING 标志位判断
// 如果头节点为非正在匹配的节点,尝试与其进行匹配
else if (!isFulfilling(h.mode)) {
if (h.isCancelled()) // 节点已取消将其弹出栈中
casHead(h, h.next); // 更新栈顶指针
// 将当前节点以 FULFILLING 模式压入栈中,表示当前节点要与原头节点进行匹配操作
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) {
SNode m = s.next; // m is s's match
// 表示原头节点已被其他匹配线程所匹配,你需要重新获取最新头节点进行再次匹配
if (m == null) {
casHead(s, null); // 将 s 弹出
s = null; // 置空 s,为了在下次循环时重新创建节点,重新入栈进行匹配
break; // restart main loop
}
SNode mn = m.next; // 此时的 m 节点是待匹配节点
if (m.tryMatch(s)) {
casHead(s, mn); // 匹配成功 更新头节点,跳过正在匹配的两个节点
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
s.casNext(m, mn); // 匹配失败,更新s的next节点
}
}
}
// 头节点是 FULFILLING ,帮组其完成匹配操作
else {
SNode m = h.next; // m 被匹配的节点
// m 为null 表示栈中已经没有可匹配的节点了,将 FULFILLING 节点从栈中弹出
// 下次进入循环如果头节点为空,进入队列阻塞等待被匹配
if (m == null)
casHead(h, null);
else {
SNode mn = m.next; // 取出 m 的next节点,用于更新head用
if (m.tryMatch(h)) // 尝试帮助他们进行匹配操作
casHead(h, mn); // 匹配成功,将头节点更新到 mn,跳过前面两个匹配节点
else // 匹配失败,m已被其他线程所匹配,更新头节点的next 指向 mn , 然后重新循环执行
h.casNext(m, mn); // 断开 m 的next链路
}
}
}
}
static SNode snode(SNode s, Object e, SNode next, int mode) {
if (s == null) s = new SNode(e);
s.mode = mode;
s.next = next;
return s;
}
awaitFulfill 方法
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 超时等待,算出绝对时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();// 当前线程
// (h == s || h == null || isFulfilling(h.mode)) ,因为只有头结点才能进行匹配,所以当你的第一个压栈的线程或你正在与后面线程进行匹配,那么进行自旋,避免进入OS阻塞等待
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel(); // 如果被中断直接取消该节点,将 match 指向自己,标识自己被取消了
SNode m = s.match;
if (m != null) // m 可能为自己(节点被取消)或是匹配的节点(匹配成功)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(); // 超时取消节点
continue;
}
}
if (spins > 0) spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null) s.waiter = w;
else if (!timed) LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanos);
}
}
s.tryCancel(); // 超时取消节点
continue;
}
}
if (spins > 0) spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null) s.waiter = w;
else if (!timed) LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold) LockSupport.parkNanos(this, nanos);
}
}














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









