






uptime 查负载
uptime
另外还有一个参数 -V(大写),是用来查询版本的
procps是一个实用程序包,主要包括ps top kill等程序主要用来显示与控制一些系统信息,进程状态之类的内容。
以下显示输入uptime的信息:
04:03:58 up 10 days, 13:19, 1 user, load average: 0.54, 0.40, 0.20
- 当前时间 04:03:58
- 系统已运行的时间 10 days, 13:19
- 当前在线用户 1 user
- 平均负载:0.54, 0.40, 0.20,最近1分钟、5分钟、15分钟系统的负载
cat /proc/loadavg
最直接查看系统平均负载命令
root@Slyar.com:~# cat /proc/loadavg 0.10 0.06 0.01 1/72 29632
除了前3个数字表示平均进程数量外,后面的1个分数,分母表示系统进程总数,分子表示正在运行的进程数;最后一个数字表示最近运行的进程ID
何为系统负载呢?
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
一般来说,每个CPU内核当前活动进程数不大于3,则系统运行表现良好!当然这里说的是每个cpu内核,也就是如果你的主机是四核cpu的话,那么只要uptime最后输出的一串字符数值小于12即表示系统负载不是很严重.当然如果达到20,那就表示当前系统负载非常严重,估计打开执行web脚本非常缓慢.
free 内存状态
free -m

Mem为物理内存的容量。
Swap为虚拟内存的容量。
total为总容量。
used为已用容量。
free为空闲容量。
shared为共享容量。
buff/cache为缓冲及缓存的容量。
avaiable为真正可用容量。
一般swap used的值最好不要超过20%。
df 查磁盘使用率
df -h
统计内存最高的进程:
ps aux | grep -v PID | sort -rn -k 4 | head
统计CPU使用率最高的进程:
ps aux | grep -v PID | sort -rn -k 3 | head
僵尸进程:
ps aux | grep defunct | grep -v grep
硬件故障分析:
1.检查磁盘使用量:服务器硬盘是否已满。
2.是否开启了swap交换模式(si/so)。
3.CPU使用情况:占用高CPU时间片的是系统进程还是用户进程。
查看CPU和内存信息:
iostat查看磁盘,CPU信息
显示所有设备负载情况
|
|
|
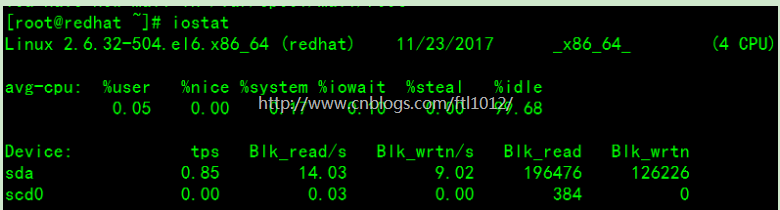
说明:
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈
如果%idle值高,表示CPU较空闲
如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
cpu属性值说明:
tps:该设备每秒的传输次数
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read: 读取的总数据量;
kB_wrtn:写入的总数量数据量;
定时显示所有信息
| 1 2 |
|
显示指定磁盘信息
| 1 |
|
显示tty和Cpu信息
| 1 |
|
以M为单位显示所有信息
| 1 |
|
查看设备使用率(%util)、响应时间(await)
| 1 2 3 |
|

说明:
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
%util: 一秒中有百分之多少的时间用于 I/O
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
查看cpu状态
| 1 |
|

vmstat 虚拟内存统计
1、命令简介
vmstat(Virtual Memory Statistics 虚拟内存统计) 命令用来显示Linux系统虚拟内存状态,也可以报告关于进程、内存、I/O等系统整体运行状态。
2、用法

vmstat [-a] [-n] [-t] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
3、选项
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
4、示例
示例1:vmstat 命令说明

Procs(进程)
| r: | 运行队列中进程数量,这个值也可以判断是否需要增加CPU。(长期大于1) |
| b | 等待IO的进程数量。 |
Memory(内存)
| swpd | 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 |
| free | 空闲物理内存大小。 |
| buff | 用作缓冲的内存大小。 |
| cache | 用作缓存的内存大小,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。 |
Swap
| si | 每秒从交换区写到内存的大小,由磁盘调入内存。 |
| so | 每秒写入交换区的内存大小,由内存调入磁盘。 |
注意:内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。因为linux总是先把内存用光
IO
| bi | 每秒读取的块数 |
| bo | 每秒写入的块数 |
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
system(系统)
| in | 每秒中断数,包括时钟中断。 |
| cs | 每秒上下文切换数。 |
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。
CPU(以百分比表示)
| us | 用户进程执行时间百分比(user time) us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 |
| sy: | 内核系统进程执行时间百分比(system time) sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 |
| wa | IO等待时间百分比 wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 |
| id | 空闲时间百分比 |
实例2:vmstat –a 显示活跃和非活跃内存,显示增加了inact和active列,

示例3: vmstat -s 查看内存使用的详细信息
[root@oracledb ~]# vmstat -s
3922280 total memory
1294648 used memory
705808 active memory
398728 inactive memory
2627632 free memory
132816 buffer memory
802932 swap cache
8339448 total swap
0 used swap
8339448 free swap
2162 non-nice user cpu ticks
46 nice user cpu ticks
3257 system cpu ticks
3015131 idle cpu ticks
1685 IO-wait cpu ticks
582 IRQ cpu ticks
269 softirq cpu ticks
0 stolen cpu ticks
935206 pages paged in
43585 pages paged out
0 pages swapped in
0 pages swapped out
532677 interrupts
656731 CPU context switches
1461999263 boot time
5706 forks
示例4: vmstat -d 查看磁盘的读/写
[root@oracledb ~]# vmstat -d
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
ram0 0 0 0 0 0 0 0 0 0 0
ram1 0 0 0 0 0 0 0 0 0 0
ram2 0 0 0 0 0 0 0 0 0 0
ram3 0 0 0 0 0 0 0 0 0 0
ram4 0 0 0 0 0 0 0 0 0 0
ram5 0 0 0 0 0 0 0 0 0 0
ram6 0 0 0 0 0 0 0 0 0 0
ram7 0 0 0 0 0 0 0 0 0 0
ram8 0 0 0 0 0 0 0 0 0 0
ram9 0 0 0 0 0 0 0 0 0 0
ram10 0 0 0 0 0 0 0 0 0 0
ram11 0 0 0 0 0 0 0 0 0 0
ram12 0 0 0 0 0 0 0 0 0 0
ram13 0 0 0 0 0 0 0 0 0 0
ram14 0 0 0 0 0 0 0 0 0 0
ram15 0 0 0 0 0 0 0 0 0 0
loop0 0 0 0 0 0 0 0 0 0 0
loop1 0 0 0 0 0 0 0 0 0 0
loop2 0 0 0 0 0 0 0 0 0 0
loop3 0 0 0 0 0 0 0 0 0 0
loop4 0 0 0 0 0 0 0 0 0 0
loop5 0 0 0 0 0 0 0 0 0 0
loop6 0 0 0 0 0 0 0 0 0 0
loop7 0 0 0 0 0 0 0 0 0 0
sr0 0 0 0 0 0 0 0 0 0 0
sda 26814 24219 1867212 35021 3238 7679 87202 8343 0 22
示例5: 查看/dev/sda1磁盘的读/写
[root@oracledb ~]# vmstat -p /dev/sda1
sda1 reads read sectors writes requested writes
666 5466 7 50















 1252
1252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









