







刚学习tensorflow,折腾了这几天,之前一直按照书上的教程训练网络,看那些没玩没了的不断接近于1的准确率,甚是无聊,我一直想将辛辛苦苦训练出来的网络,那些识别率看上去很高的网络,是否能真正用来识别外面导入的图片呢,而不仅仅是那些训练集或者测试集的图片。
之前写过一篇博客是用keras的基于tensorflow的高级API写的,模型的设置、训练、存储、加载都非常简单,其实我还是很喜欢用哪=那个高级API的,不过Tensorflow常用的套路还是需要会的,所以倒腾了这两天,按照书上写的卷积网络的步骤自己去实践,然后结合模型加载部分的代码区加载模型,然后通过OpenCV去导入图片和进行图片的变形,最后实现了对自己手写的图片的识别,还是很开心的。
大家要是不会用OpenCV的话,对于外面导入图片以及图片处理的操作,Tensorflow也提供了相关的工具,我就不展开。
下面就不多废话,直接看代码: (我的工程已经放在我的github上,地址为:https://github.com/MRJTM/Tensorflow_Mnist.git)注意这里的git是小写的,大写是无法访问的
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import os
import cv2
# 屏蔽waring信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
"""------------------加载数据---------------------"""
# 载入数据
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
# 改变数据格式,为了能够输入卷积层
trX = trX.reshape(-1, 28, 28, 1) # -1表示不考虑输入图片的数量,1表示单通道
teX = teX.reshape(-1, 28, 28, 1)
"""------------------构建模型---------------------"""
# 定义输入输出的数据容器
X = tf.placeholder("float", [None, 28, 28, 1])
Y = tf.placeholder("float", [None, 10])
# 定义和初始化权重、dropout参数
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
w1 = init_weights([3, 3, 1, 32]) # 3X3的卷积核,获得32个特征
w2 = init_weights([3, 3, 32, 64]) # 3X3的卷积核,获得64个特征
w3 = init_weights([3, 3, 64, 128]) # 3X3的卷积核,获得128个特征
w4 = init_weights([128 * 4 * 4, 625]) # 从卷积层到全连层
w_o = init_weights([625, 10]) # 从全连层到输出层
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
# 定义模型
def create_model(X, w1, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden):
# 第一组卷积层和pooling层
conv1 = tf.nn.conv2d(X, w1, strides=[1, 1, 1, 1], padding='SAME')
conv1_out = tf.nn.relu(conv1)
pool1 = tf.nn.max_pool(conv1_out, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool1_out = tf.nn.dropout(pool1, p_keep_conv)
# 第二组卷积层和pooling层
conv2 = tf.nn.conv2d(pool1_out, w2, strides=[1, 1, 1, 1], padding='SAME')
conv2_out = tf.nn.relu(conv2)
pool2 = tf.nn.max_pool(conv2_out, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool2_out = tf.nn.dropout(pool2, p_keep_conv)
# 第三组卷积层和pooling层
conv3 = tf.nn.conv2d(pool2_out, w3, strides=[1, 1, 1, 1], padding='SAME')
conv3_out = tf.nn.relu(conv3)
pool3 = tf.nn.max_pool(conv3_out, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool3 = tf.reshape(pool3, [-1, w4.get_shape().as_list()[0]]) # 转化成一维的向量
pool3_out = tf.nn.dropout(pool3, p_keep_conv)
# 全连层
fully_layer = tf.matmul(pool3_out, w4)
fully_layer_out = tf.nn.relu(fully_layer)
fully_layer_out = tf.nn.dropout(fully_layer_out, p_keep_hidden)
# 输出层
out = tf.matmul(fully_layer_out, w_o)
return out
model = create_model(X, w1, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden)
# 定义代价函数、训练方法、预测操作
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=model, labels=Y))
train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
predict_op = tf.argmax(model, 1,name="predict")
# 定义一个saver
saver=tf.train.Saver()
# 定义存储路径
ckpt_dir="./ckpt_dir"
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
"""------------------训练模型或者加载模型进行测试---------------------"""
train_batch_size = 128 # 训练集的mini_batch_size=128
test_batch_size = 256 # 测试集中调用的batch_size=256
epoches = 5 # 迭代周期
with tf.Session() as sess:
"""-------训练模型--------"""
# 初始化所有变量
tf.global_variables_initializer().run()
# 训练操作
# for i in range(epoches):
# train_batch = zip(range(0, len(trX), train_batch_size),
# range(train_batch_size, len(trX) + 1, train_batch_size))
# for start, end in train_batch:
# sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end],
# p_keep_conv: 0.8, p_keep_hidden: 0.5})
# # 每个周期用测试集中随机抽出test_batch_size个图片进行测试
# test_indices = np.arange(len(teX)) # 返回一个array[0,1...len(teX)]
# np.random.shuffle(test_indices) # 打乱这个array
# test_indices = test_indices[0:test_batch_size]
#
# # 获取测试集test_batch_size章图片的的预测结果
# predict_result = sess.run(predict_op, feed_dict={X: teX[test_indices],
# p_keep_conv: 1.0,
# p_keep_hidden: 1.0})
# # 获取真实的标签值
# true_labels = np.argmax(teY[test_indices], axis=1)
#
# # 计算准确率
# accuracy = np.mean(true_labels == predict_result)
# print("epoch", i, ":", accuracy)
#
# # 保存模型
# saver.save(sess,ckpt_dir+"/model.ckpt",global_step=i)
"""-----加载模型,用导入的图片进行测试--------"""
# 载入图片
src = cv2.imread('./Pictures/9.png')
cv2.imshow("待测图片", src)
# 将图片转化为28*28的灰度图
src = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
dst = cv2.resize(src, (28, 28), interpolation=cv2.INTER_CUBIC)
# 将灰度图转化为1*784的能够输入的网络的数组
picture = np.zeros((28, 28))
for i in range(0, 28):
for j in range(0, 28):
picture[i][j] = (255 - dst[i][j])
picture = picture.reshape(1, 28, 28, 1)
# 载入模型
saver.restore(sess,ckpt_dir+"/model.ckpt-4")
# 进行预测
predict_result = sess.run(predict_op, feed_dict={X: picture,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
print("你导入的图片是:",predict_result[0])
cv2.waitKey(20170731)
以上代码注释掉的部分是用来训练的,如果你想先训练,就注释掉"""------加载摸型,用导入的图片进行测试------"""下面的代码,将"""--------训练模型--------""""下面被注释掉的代码取消注释即可,训练会产生一个ckpt_dir的文件夹,里边存放着保存的模型
如果训练好后想测试,那么就把训练部分注释掉,把"""------加载摸型,用导入的图片进行测试-----"""下面的代码取消注释即可
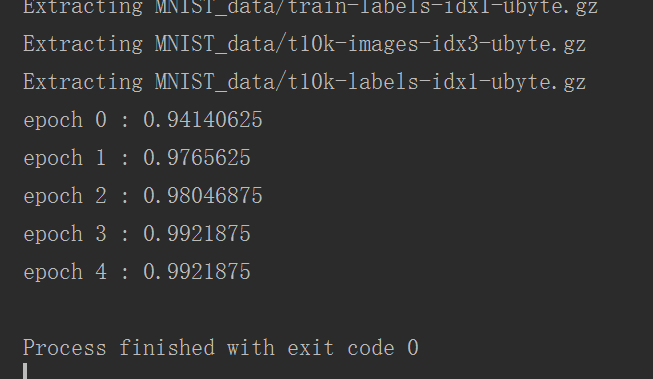
运行现象如下:
训练的时候,因为只有CPU,所以我只跑了5个迭代周期:
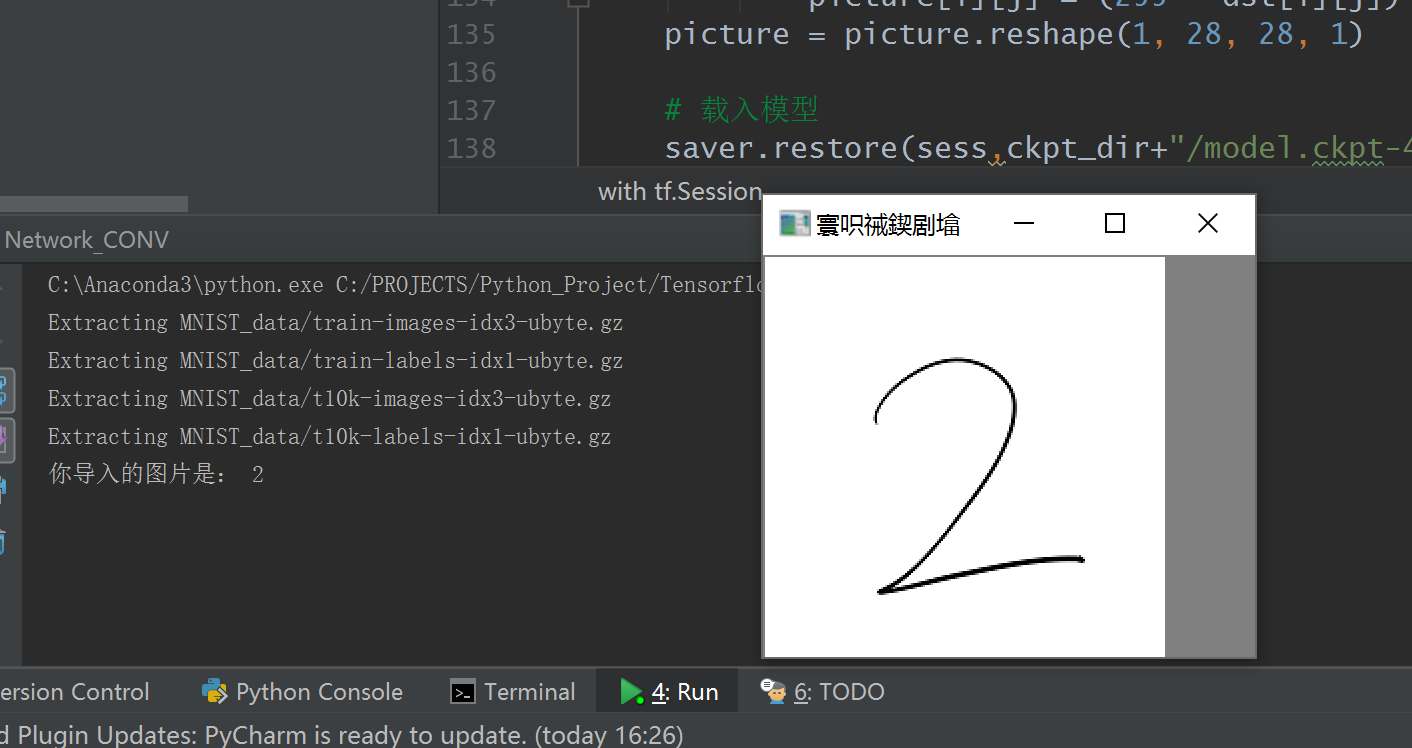
然后测试的时候,我用了一张手写的2去测试,效果如下:















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









