







线性表的弊端
线性表的顺序存储,占用的空间地址是连续的,查找方便,但是容易造成内存空间的浪费。插入和删除,需要大规模的移动数据,既不安全速度又慢。链式存储虽然插入删除方便但是由于其空间的不连续,查找速度慢。当我们既要对数据增删又要查询显然线性表已经不能满足我们的需求了。
散列表(hashTable)
散列表的使用分为两步:
- 第一步:使用散列函数将被查找的Key值转换为数组的一个索引,理想情况下不同的key值都能转换为不同的索引值,但是这只是理想情况,很有可能两个Key或者多个Key都会映射为相同的索引值这就需要散列查找的第二步解决散列碰撞冲突
- 第二步:解决散列碰撞: 拉链法,线性探测法
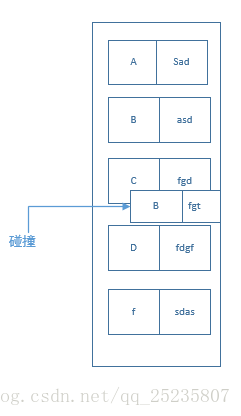
散列函数
散列函数的计算,这个过程会将键值转换为数组的索引,这个散列函数应该易于计算并且能够均匀分布所有的键。这里主要主要介绍两种方法(jdk中)。
- 第一种方法:先计算key的hash值,一个32位int类型数字,和
数组的长度M做取模运算得到的数字一定在M内。 - 第二种方法:先计算key的hash值,一个32位int类型数字,
和数组的长度M-1,做&运算,那么得到的数字一定在M内。
解决散列碰撞
在Java中hashMap解决散列碰撞使用的是拉链法,即将大小为M的数组中的每个元素指向一个 链表,链表的每一个节点都存储了散值为该元素的键值对,这种方法被称为拉链法。
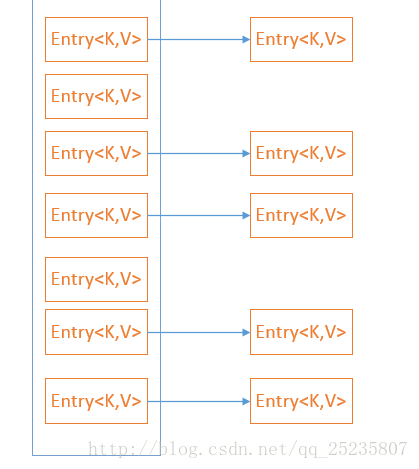
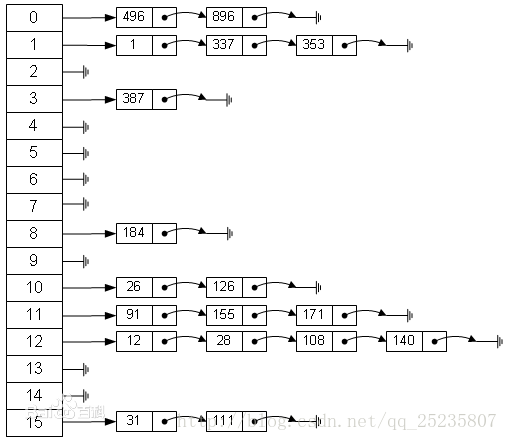
hsahMap源码
//初始容量
static final int DEFAULT_INITIAL_CAPACITY = 16;
//最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子,和扩容相关的
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//散列表,是一个Entry数组
transient Entry<K,V>[] table;
//容器的大小
transient int size;
... public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
//散列表的大小必须是2的N次方幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
}
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}默认的无参构造是初始化一个16个大小的散列表
- Entry保存key,key的hash值,vlaue,和指针
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
。。。。
}- 散列函数
static int indexFor(int h, int length) {
return h & (length-1);
}- 添加元素的方法:put
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);//键为空的时候
int hash = hash(key); //计算key的hash值,32位的int类型
int i = indexFor(hash, table.length);//散列函数,计算通过键计算数组的索引
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//存入的Key值一样,并且hash也相同,新的value覆盖原来的
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加元素
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断是否超出可数组的长度
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//添加null
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加到散列表的第一个位置
addEntry(0, null, value, 0);
return null;
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//添加的是头节点
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
注意的是:hash值相同,Key值不一定相同,Key值相同hash值一定相同,所以在判断key是否存在一定要注意。允许存入key为null,但是一定存放在散列表的第一个位置
- 获得元素的方法get
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
//计算哈希表索引,遍历链表
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- 删除元素
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];//头元素
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)//如果第一个元素就是
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;//向下遍历
}- 再哈希
当哈希表的表空间不足的时候我们就需要对哈希表进行扩容,但是散列表的值不能大于2的30次幂,扩充后的哈希表,由于长度变了所以必须重新使用散列函数计算散列值















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









